Automated fact-checking of climate claims with large language models

Introduction
In the era of digital information abundance, the endeavor to counter climate misinformation has found a promising ally in artificial intelligence (AI). Research shows that engaging with an AI chatbot on climate change can significantly align public perception with scientific consensus1, highlighting the importance of ensuring that the large language models (LLMs) underpinning these systems are accurate and trustworthy. Therefore, we ask how well we can embed scientific consensus into automated fact-checking. To this end, we developed Climinator—an acronym for CLImate Mediator for INformed Analysis and Transparent Objective Reasoning. Climinator evaluates the veracity of climate statements and improves its verdicts with evidence-based and scientifically credible reasoning and references to relevant literature. Our vision is to use AI to catalyze a well-informed global climate dialog, enrich public discourse with scientific insights, and foster a more informed society ready to engage with climate challenges. Climinator serves as a first step in this direction.
Platforms like Climate Feedback and Skeptical Science have made commendable efforts to involve climate scientists in volunteering their expertise and providing an essential service in addressing climate misinformation. These scientists voluntarily dedicate their time to giving concise science-based evaluations, including references, and delivering a final verdict on disputed claims. Despite their valuable contributions, these efforts face significant challenges, including scalability and actuality. Hence, their impact is limited by the sheer volume of misinformation and skepticism in digital media, worsened by misinformation spreading more rapidly and widely than factual information2.
As a response, automated fact-checking3,4 aims to debunk misinformation at scale using natural language processing methods. While automated fact-checking tools have improved, they struggle with complex claims due to a lack of detailed reasoning5,6,7, particularly in the domain of climate change8. To address this problem, we introduce an advanced framework that overcomes these limitations by integrating LLMs within a Mediator-Advocate model. Although recent work has explored the aggregation of different viewpoints using LLMs to build a general consensus9, we address real-world claim complexities and evidence controversies in a novel way10,11,12. In particular, we introduce separate “Advocates,” each drawing on a distinct text corpus to represent a specific viewpoint, while a “Mediator” either asks follow-up questions or synthesizes these perspectives into a cohesive and balanced final assessment.
Our methodology is grounded in the deliberation literature13,14 and aligns with more modern interpretations of automated fact-checking that tend toward a deliberation setting15. It includes generating questions and answers given a claim and trustworthy evidence for fact-checking16. Real-life implementations of such methods can be seen in the Twitter17 community notes, providing additional context for Tweets. Viewing Climinator in this light, we consider the Advocates as contributors to these notes.
Our main result demonstrates our framework’s capacity to significantly enhance the efficacy of fact-checking, surpassing the capabilities of a single LLM in isolation. Climinator improves the verification of climate claims by integrating different scientific points of view. In particular, we highlight Climinator’s performance in verifying claims from the Climate Feedback dataset, achieving a binary classification accuracy exceeding 96%. Moreover, by providing explanations and source references, Climinator delivers verdicts with apparent justification, potentially enhancing user trust.
Results
As explained in the Methods section, the Climinator framework employs a Mediator-Advocate mechanism, where advocates represent perspectives derived from specific text sources, including the IPCC (Intergovernmental Panel on Climate Change), WMO (World Meteorological Organization), AbsCC (abstracts of scientific literature on climate change), and 1000S (a corpus of abstracts authored by the top 1000 climate scientists). In addition to these advocates, GPT-4o acts as a general-purpose advocate. For our robustness analysis, we add an adversarial advocate, the NIPCC (Non-Governmental International Panel on Climate Change), representing contrarian views often associated with climate denial. The Mediator synthesizes all advocate outputs, potentially triggering additional debating rounds to deliver a balanced, transparent final judgment.
We define four classification levels, each distinguished by the number of categories (see Fig. 3). Level 1 has 12 fine-grained categories (e.g., “correct_but,” “flawed_reasoning”) corresponding to the original classification of Climate Feedback. It represents our highest level of detail. Level 2 merges these into five broader classes (e.g., “very high credibility” through “very low credibility”). Level 3 further combines them into three classes (“high credibility,” “neutral credibility,” “low credibility”). Level 4 is the coarsest level, using only two categories, “credible” and “not credible.” This hierarchical setup lets us capture subtle differences where needed (Level 1). Yet, it also provides simpler classifications (Level 4) for tasks requiring less granularity.
In our main experiment, we initially used advocates representing reputable sources and dropped the NIPCC. Figure 1 illustrates the performance of various models in terms of their accuracy in classifying Climate Feedback claims for different grouping levels. The solid bars represent the performance of the models when “not enough information” verdicts are included in the classification process. These cases reflect scenarios where the LLMs explicitly acknowledge insufficient information to make a confident claim verdict. This forced admission ensures transparency and reflects real-world situations where incomplete data does not allow the model to draw a definitive conclusion. The bars with the transparent top-ups indicate the performance metrics calculated after we filtered out the “not enough information” verdicts. By doing so, we isolate the system’s ability to classify only claims for which adequate evidence exists in their text sources.

The Climinator (CLIM) systems incorporate a blend of RAG Advocates (IPCC, WMO, AbsCC, and 1000S) and GPT-4o as non-RAG Advocates.
For the original classification (Level 1) and after filtering out the “not enough information” verdicts, GPT-4o achieves an accuracy of 31.1%, while Climinator (CLIM) achieves 34.5%. At Level 2, an even more notable gap emerges, with GPT-4o achieving an accuracy of 56.5% compared to Climinator’s 72.7%. This substantial difference of over 16 percentage points highlights Climinator’s ability to handle more detailed classification tasks. This improvement can be attributed to Climinator’s reliance on trusted RAG advocates, such as IPCC and WMO, which provide structured, evidence-backed context for decision-making. In contrast, GPT-4o, as a general-purpose model, appears to struggle with intermediate classification tiers that require domain-specific knowledge. Hence, while GPT-4o performs comparably to Climinator at the coarsest classification level (Level 4), Climinator demonstrates a clear advantage as the classification expands to more detailed levels (Levels 1–3).
Table 1 compares Climinator and GPT- 4o across multiple levels of classification details, revealing several striking patterns. At the most detailed level (Level 1), Climinator demonstrates superior recall (0.197 vs. 0.202 for GPT-4o) and a macro F1-score of 0.176 compared to GPT-4o’s 0.155. Notably, the weighted F1-score for GPT-4o (0.272) outperforms Climinator (0.257), suggesting that while GPT-4o favors precision in high-support classes, it struggles with smaller or underrepresented classes, as evidenced by zero F1-scores in categories like “mostly accurate” and “unsupported.”
At Level 2, where claims are grouped into broader credibility classes, Climinator significantly outperforms GPT-4o with an F1-score of 0.727 compared to 0.585. This improvement is driven by Climinator’s high precision (0.902) and recall (0.815) for “very low credibility,” yielding an F1-score of 0.856. GPT-4o, while maintaining strong precision (0.929) for the same class, suffers from lower recall (0.634), indicating its tendency to misclassify claims in the least credible tier. Similarly, Climinator’s higher F1 scores for the remaining classes highlight its ability to capture the nuances within less prominent classes.
Lastly, moving to Level 3, Climinator achieves near-perfect performance for “low credibility,” with precision and recall at 0.980, resulting in an F1-score of 0.980. GPT-4o, while also performing well (F1-score of 0.973), shows slightly lower recall (0.966), which may result in missed classifications for low-credibility claims. For the “high credibility” tier, Climinator again shows a slight advantage in F1-score (0.857 vs. 0.828), reinforcing its consistent performance across all levels of classification tiers.
At Level 4, both models achieve strong results, but Climinator edges ahead in the “credible” category with an F1-score of 0.812 compared to GPT-4o’s 0.765, driven by superior precision (0.812 vs. 0.722). This reflects Climinator’s ability to minimize false positives.
The results in Table 1 underscore two key insights. First, Climinator demonstrates exceptional adaptability across different levels of classification details, consistently balancing precision and recall, which is critical for real-world applications with unbalanced data sets. Second, the performance of GPT-4o, characterized by higher precision but reduced recall, highlights the tradeoffs inherent in general-purpose LLMs. These LLMs are usually designed to be more conservative to avoid hallucinations and off-target outputs. Hence, they use more cautious language in borderline situations, increasing precision at the cost of a lower recall. We note, however, that a few categories in our dataset have fewer than ten samples, so any conclusions drawn for these specific classes must be treated with caution. Despite this limitation, our findings support the benefit of our approach, especially as the complexity of claim classification increases.
In our main experiment, there was only one instance where a debate occurred, which is unsurprising, given the alignment of the text sources we used. The only claim that triggered a debate was “more than 75 percent of the rainforest is losing resilience, and more than half of the rainforest could be converted into a savanna in a matter of decades.” Empirical evidence18 strongly supports the assertion regarding resilience loss, demonstrating that more than three-quarters of the Amazon rainforest has been showing declining recovery from ecological disturbances since the early 2000s. However, the second component of the claim that more than half of the rainforest could transition to savanna within decades remains speculative, relying on many assumptions.
For this claim, all Advocates except IPCC and AbsCC determined there was “Not Enough Information” to fully assess the claim, citing the lack of specific data in their reviewed sources. The IPCC initially deemed the claim “unsupported,” referencing uncertainty surrounding the specific figures and timelines. AbsCC delivered a “correct_but” verdict in the first round, acknowledging the robust evidence for resilience loss while highlighting that the timeframe and scale of savanna conversion lack precise quantification.
This discrepancy triggered follow-up questions from the Moderator. The IPCC was asked to clarify the specific evidence or lack thereof that led to its assessment. This prompted a revision to “correct_but,” as the IPCC acknowledged external studies provided by the AbsCC Advocate. Similarly, AbsCC was asked to provide more detail on the evidence supporting resilience loss and to elaborate on the uncertainties surrounding the timeframe and extent of savanna conversion. The debating round eventually led to a convergence to a “correct_but” verdict, where Climinator recognizes the strong support for resilience loss and the speculative nature of savanna conversion. This debate exemplifies the importance of transparency in communicating scientific uncertainty, especially when claims carry significant implications for global conservation policies.
To test the robustness of Climinator, we propose the integration of an adversarial Advocate designed to embody the stance of climate-change denial. This approach mirrors the real-world discourse more accurately and provides a robust use case for testing the system’s resilience and adaptability in navigating complex, polarized debates. Using the reports of the NIPCC, we construct an RAG model, termed the NIPCC Advocate, designed to reflect the climate denial perspective. We modified the Moderator’s prompt to avoid potential biases favoring climate science. In essence, we force the model to strictly mediate between the advocates, precluding its internal knowledge from creating a biased viewpoint.
Incorporating the NIPCC advocate into the analysis of Climate Feedback claims reveals that the advocate’s contrarian perspective significantly increases the frequency of debates triggered by the Mediator. A total of 18 claims are now debated, with 12 resolved after a single round, four requiring a second round, and two extending to a third. Table 2 presents the results. The NIPCC advocate performs poorly at all levels, reflecting its design as a climate denial representation, misaligned with the scientific consensus.
In contrast, Climinator exhibits strong resilience in the presence of the adversarial advocate at all classification levels. For the original classes, accuracy marginally improves from 0.345 (without the NIPCC advocate) to 0.3658. This indicates that the debates triggered by the NIPCC’s input may help Climinator at the most detailed classification level. At Level 2, accuracy decreases slightly from 0.727 to 0.7134, reflecting the increased complexity introduced by the adversarial advocate’s contrarian stance. However, at Levels 3 and 4, Climinator achieves near-identical performance compared to its baseline, with accuracies of 0.9573 and 0.9634, respectively.
These results underscore the system’s robustness and highlight the effectiveness of class aggregation in mitigating adversarial noise. By triggering debates, the NIPCC advocate indirectly enhances Climinator’s deliberative process at a more detailed classification. This demonstrates that Climinator remains reliable in classifying claims aligned with scientific consensus, even when challenged by adversarial perspectives. Section 3 of the Supplementary Information provides a detailed discussion of the debating process for a particular claim.
Discussion
Our findings from the Climinator study highlight the advantages of the innovative Mediator-Advocate debate framework. It facilitates deeper analysis of climate-related claims compared to approaches focusing solely on scaling up model sizes, as seen in other domains like medicine19. In Climinator, the structured debate mechanism, where specialized Advocates present arguments to a central Mediator, enables the model to synthesize multiple viewpoints and provide a balanced, evidence-based assessment of factual versus misleading information.
The effectiveness of Climinator stems from its grounding in different climate science sources. The model’s outputs result from a transparent process incorporating multiple scientific views, making Climinator highly applicable, especially in climate policymaking and education, where precision and ethical responsibility are vital.
In policymaking, Climinator could be integrated into decision-support systems to assist in verifying climate-related claims. For example, government agencies and regulatory bodies could use the system to evaluate claims from industry reports or public figures, ensuring that policies are informed by accurate, up-to-date scientific evidence. A practical scenario might involve fact-checking climate-related claims in policy debates or assessing the likely impact of competing policy proposals, such as carbon taxation or renewable energy subsidies. This would provide decision-makers with clear, evidence-based insights, enabling more informed and responsible policy choices.
In educational contexts, Climinator can improve climate literacy through interactive learning modules. For example, students could use the system to fact-check climate claims presented in media or textbooks, gaining a deeper understanding of the scientific method and critical thinking. Furthermore, Climinator could be used in structured classroom debates, where students submit competing climate claims for evaluation, and the system provides reasoned verdicts based on scientific evidence. These applications foster critical thinking and equip students to navigate future complex environmental issues.
While Climinator marks an advancement in AI-assisted climate discourse, it faces several limitations that highlight areas for future research and development. One key challenge is the tool’s reliance on potentially outdated information due to the rapidly evolving nature of climate science. Future iterations could benefit from a mechanism to continuously update the knowledge base with the latest scientific publications and news. Furthermore, the scope and quality of sources from which Climinator retrieves information may not fully capture the breadth of relevant and emerging scientific data, particularly those behind paywalls. Expanding the range of reliable sources to include more scientific journals, reports, and datasets will enhance the tool’s comprehensiveness. Moreover, there is potential for expanding Climinator into a multimodal debating system by integrating various data input forms, such as images, graphs, and videos, alongside textual information. This would provide a richer and more informative platform for climate science communication, making information more accessible and understandable to a broader audience.
In addition, our current framework’s reliance on GPT-4o poses challenges for transparency and consistency. Hence, transitioning to open-source language models specifically trained for climate science fact-checking tasks could enhance transparency and allow continuous improvements and customization.
Although our system demonstrated robustness to prompt variations, further sensitivity analysis involving a broader range of hyperparameter configurations would provide deeper insights into model behavior. Recent work20 on domain-specific retrieval has shown that precise relevance definitions and targeted fine-tuning can significantly improve retrieval-augmented generation systems. Incorporating such approaches could mitigate potential performance bottlenecks in future system iterations.
Lastly, our study uses Climate Feedback annotations as the ground truth, relying on the expertise of climate scientists to provide accurate classifications. While this resource is among the most reliable for climate claim verification, expert opinions may vary. Questioning these annotations would involve an independent and in-depth review that is beyond the scope of this paper. Future work might consider alternative datasets or methods to validate expert assessments further, ensuring an even more robust fact-checking framework. An interesting dataset can be found on the Skeptical Science website. However, these claims are not as systematically annotated as those of Climate Feedback. Also, many claims on Skeptical Science already have a counterpart on Climate Feedback. We leave the exploration of that dataset for future research.
Methods
Pipeline
Figure 2 depicts the operational flow of the Climinator framework. Specialized LLMs, hereafter referred to as Advocates, are at the core of the proposed approach. Each Advocate examines the claim against a curated corpus of texts. The general GPT-4o model21 serves as one Advocate, while other Advocates consist of retrieval-augmented generation (RAG) systems22,23,24 with GPT-4o as the underlying LLM. These systems draw exclusively from predefined scientific and trusted repositories and ensure that LLM responses are grounded in credible sources, such as e.g., the IPCC AR6 reports. Each of the Advocates is grounded on one particular text corpus and delivers a verdict informed by its respective data sources, prompted to provide evidence-based rationales. The second role is the Mediator. This system part evaluates the agreements of the Advocates and initializes additional discussion rounds upon disagreements.
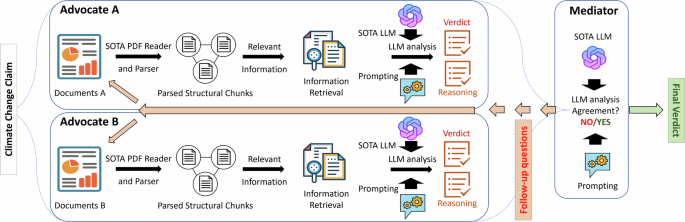
CLIMINATOR framework: An LLM-based framework within a Mediator- Advocate system to assess the veracity of climate-related claims.
The algorithm (see Algorithm 1) starts to assess climate claim C through a collaborative assessment involving Advocates and a Mediator. The Advocates aim to produce an array AC comprising their verdict, the rationale, and the relevant references. This initial evaluation phase ensures an analysis that leverages different datasets to form a preliminary judgment. The arrays AC, reflecting the different perspectives inherent to each Advocate’s text corpus, are consolidated by the Mediator LLM, synthesizing these findings into a final judgment. However, the Mediator may also spot disagreements between the Advocates. In this case, the Mediator poses follow-up questions F to the Advocates and facilitates a more profound examination by broadcasting the collected verdicts, rationales, and references AC to all Advocates. This dialog generates a new set of answers AF for the Mediator, facilitating the resolution of discrepancies and bolstering the collective insight into C. This iterative discourse can span multiple rounds, eventually leading to a final verdict Vf ∈ V, representing a consensus or the most credible judgment based on the collective insights and analyses Advocates provided. This verdict and a detailed reasoning overview by the Mediator and Advocates are presented to the user, offering a thorough, evidence-based assessment of climate claim C. For the user, this clarifies the claim’s validity and enriches their understanding of the underlying scientific principles and evidence. With this knowledge, users can make informed decisions, discuss climate change in a scientific way, and advocate for evidence-based policies.
Data
Our analysis relies on two types of data: authoritative text sources for the RAG systems and a curated collection of claims, ideally accompanied by expert annotations.
Algorithm 1:
Climinator Framework: Iterative Mediator Assessment of Advocates
Require: Initial climate claim C ∈ C
Ensure: Final verdict Vf ∈ V with reasoning overview AC
1: Initiate analysis for claim C using LLM
2: Advocates ← {General GPT-4, RAG systems on T }
3: for each Advocate in Advocates do
4:Examine C against a curated corpus of texts
5: AC = {Verdict, Rationale, References} ← Advocate.Assess(C, T)
6: end for
7: Mediator collects verdicts and assesses reasoning
8: while Mediator requires further clarification do
9:Mediator poses follow-up questions F to Advocates
10:Provide Advocates with all other Advocates’ answers AC
11:for each Advocate do
12:Advocate reassesses their text corpus T with new information, given F
13:Update AF = {Verdict, Rationale, References} based on reassessment
14:end for
15:Mediator re-evaluates Advocates’ updated responses
16: end while
17: if Moderator identifies a consensus, then
18:Vf ← Mediator synthesizes a final verdict with detailed reasoning
19: else
20:Vf ← Mediator determines the most credible verdict based on the depth of reasoning
21: end if
22: Final verdict Vf ∈ V for claim C includes an overview of Mediator’s and Advocates’ reasoning
To define the text sources for the RAG systems, we selected trusted and authoritative datasets that provide comprehensive coverage of climate science. Specifically, we incorporated insights from the IPCC, including the Summary for Policymakers from its three Working Groups, detailed chapters, technical summaries, and the IPCC Synthesis Report 2023. These sources ensure a robust foundation of scientifically validated information for our fact-checking framework. These documents are available on the IPCC website, with direct links to each group’s reports: Working Group I, Working Group II, and Working Group III. Furthermore, our research used reports from the WMO, including the 2022 State of Climate Services on Energy, the Global Annual to Decadal Climate Update for 2023 and 2023–2027, and regional climate assessments for Asia, the South-West Pacific, and Africa. These reports are available at the WMO library under the following URLs: the 2022 State of Climate Services: Energy, the Global Annual to Decadal Climate Update, the State of the Climate in Asia 2022, the State of the Climate in South-West Pacific 2021, and the State of the Climate in Africa 2021. Furthermore, our dataset includes abstracts of scientific literature on climate change, indexed on the Web of Science from 2015 to 2022, totaling 290,000 abstracts. We also considered the Reuters list of the world’s top climate scientists, which ranks 1000 academics according to their influence on the climate science community. We used climate-related abstracts from this group from 2015 to 2022 (see Reuters’ website). For our robustness check, we incorporate publications from the Non-Governmental International Panel on Climate Change (NIPCC), which present a climate-denial perspective by emphasizing natural factors in climate change and critiquing the methodologies and conclusions of the IPCC. These reports, which lack peer review and are disseminated by the Heartland Institute, are accessible at CCR-II Physical Science and Full Book PDF.
Lastly, to construct a robust dataset of climate-related claims with expert annotations, we use Climate Feedback, a nonpartisan, non-profit organization dedicated to science education. From their website, we collect 170 annotated claims. Climate Feedback employs a community approach to fact-checking and crowd-sourcing evaluations from a network of scientists with relevant expertise. Each claim is reviewed by multiple scientists, who provide detailed annotations and verdicts based on current scientific understanding. To ensure consistency and transparency, Climate Feedback provides publicly available guidelines that outline the framework for claim-level reviews, assisting scientists in their assessments (see https://climatefeedback.org/claimreviews-framework/). This process, characterized by its transparency, assists us in the formulation of an appropriate prompting framework for our Advocates and the Mediator.
To illustrate the nuances involved in providing a verdict to climate-related claims, we give a typical example from the Climate Feedback dataset in Table 3, which was annotated as mostly accurate on Climate Feedback.
A typical review process on Climate Feedback involves a climate scientist who, after a thorough examination, provides an assessment backed by scientific evidence and references to peer-reviewed literature. For the claim in Table 3, the reviewing scientist supports the claim’s accuracy regarding the resilience loss in over 75 percent of the Amazon rainforest since the early 2000s. However, it is noted that the forecasted transition to a savanna-like state should not be interpreted as a complete transformation but rather as a shift towards an ecosystem with lower tree species diversity and reduced carbon storage capacity, distinguishing it from a true savanna ecosystem. This example underlines the complexity of fact-checking such claims and the importance of expert analysis in discerning the subtle distinctions and contextualizing the claim within the broader climate change discourse and relevant scientific facts. Thus, the Climate Feedback dataset is a challenging testbed for automatically interpreting and categorizing such claims.
Claim classification
For claim classification, we adopt the Climate Feedback framework with 12 different categories, as shown in Fig. 3. They range from “correct” and “accurate,” indicating very high credibility, to “misleading” and “incorrect”, reflecting very low credibility. This classification system is key to assessing the credibility of climate statements and organizing how we evaluate their trustworthiness. Rather than relying on a simple correct/incorrect distinction, it offers multiple classification levels illuminating where and how a statement might deviate from accuracy. This multi-tiered approach can strengthen scientific inquiry and policy-making by highlighting the reasons behind discrepancies, enabling more informed decisions. We provide a detailed discussion of the classification strategy in Section 1 of the Supplementary Information. Moreover, in Section 2 of the Supplementary Information, we provide the full list of claims and the verdicts from Climate Feedback and Climinator.

The first step merges these verdicts into five credibility-based classes (Level 2), then reduces them further into three categories (Level 3), and finally combines them into two (Level 4).
We acknowledge the importance of a detailed classification system, e.g., for academic research or climate policy development, where distinctions between labels like “mostly accurate” and “correct but” are valuable. However, a simplified approach is often more effective for practical applications, especially those aimed at public participation. For that reason, we consolidate certain categories to streamline the evaluation process. For instance, both “misleading” and “unsupported” claims contribute to public misinformation, albeit through different mechanisms. A “misleading” claim may use technically correct information to convey a false impression, while an “unsupported” claim lacks necessary evidence. Despite these differences, both types of claims do not provide reliable information and can lead to confusion. Grouping them under a unified label (“Low Credibility”, Level 2 in Fig. 3) reflects their shared potential to mislead the public, facilitating quicker and more precise judgments in a binary classification system. The first grouping step aligns with Climate Feedback’s annotation guidelines for scientists, while the next two steps in Fig. 3 are based on our reasoning and, hence, debatable.
As Fig. 4 illustrates, the distribution of claims is highly skewed. Most of the claims are classified as having low or very low credibility, with a significant portion falling into the categories of “incorrect” and “in- accurate.” This indicates a predominance of claims that do not align with scientific consensus, as represented by the red bars. The green bars represent the claims considered credible. These are significantly fewer in number. The inset in the figure consolidates these verdicts into two broader categories: “credible” and “not credible.” This simplified view shows that only a small fraction of claims are ultimately deemed credible (18/170), compared to the overwhelming majority categorized as not credible (152/170).

The green bars represent claims classified as credible, while the red bars denote those deemed not credible. The inset groups these classifications into two categories: “credible” and “not credible,” highlighting the predominance of claims lacking credibility.
Computer code
Climinator relies on capable LLMs as its backbone21 and retrieval-augmented language modeling22,23,24, which can be used to integrate trustworthy and up-to-date information about climate change into these models25. It also aligns with the work investigating the effectiveness of AI system aggregation26,27. All our code will be released on Github. Moreover, our prompting is provided in Section 4 of the Supplementary Information to this article.



Responses