An algorithm based on lightweight semantic features for ancient mural element object detection

Introduction
Murals specifically refer to paintings on walls or floors, and they have been found in both archaeological sites and tombs. The ancient murals unearthed in China are precious world cultural heritage1. The ancient murals unearthed in China cover a rich and diverse range of content, vividly depicting stories about the lives of royal nobility and common people, as well as tales of heavenly deities and urban legends. They also feature natural landscapes such as mountains, rivers, the sun, moon, and stars, along with animals and plants like birds, flowers, insects, and fish2. Murals have a long history in China, with rich and diverse content, making them extremely valuable visual materials for studying ancient society. They record information about various aspects such as customs, social conditions, and religious beliefs from different eras throughout history’s continuous evolution and development. Additionally, they provide abundant visual materials for research in fields such as religion, history, geography, art, customs, and clothing, holding significant research value that can assist archaeologists and cultural researchers in better studying history and humanities3.
Important elements on murals mainly include figures, vehicles, flowers, birds, and auspicious clouds. Utilizing computer vision methods for target detection of these elements on murals can enhance the understanding and study of these artworks, thereby aiding in the protection and preservation of this precious cultural heritage4. The elements on ancient murals often reflect the social life, religious beliefs, and artistic styles of the time. By detecting these target elements, we can more accurately identify and interpret the content represented in the murals, thereby gaining a deeper understanding of the historical, cultural, and artistic value behind them5. Through the detection and analysis of object elements on murals, valuable physical materials can be provided for historical and artistic research, promoting the development of related academic fields6. At the same time, these detection results can also be used for educational displays, enhancing public awareness and understanding of cultural heritage preservation. Moreover, since ancient murals often face natural threats such as weathering and erosion, detecting the object elements on the murals provides a scientific basis for studying the mechanisms of mural deterioration and for protection and restoration efforts, ensuring that these precious cultural heritage items are preserved7.
The object detection algorithms based on computer vision can automatically learn and extract feature information of targets in images, rapidly identify and locate elements in murals, such as figures, animals, patterns, etc., and accurately recognize minute details and complex elements within the murals8. These methods do not require direct contact with the murals, and instead, acquire mural images through image acquisition devices (such as cameras, scanners, etc.), thus avoiding physical damage to the murals, making them particularly suitable for precious and fragile mural relics9. Furthermore, through continuous learning and training, the models can adapt to the characteristics of murals of different styles and eras, enhancing the flexibility and versatility of detection10. Additionally, by employing object detection methods based on computer vision, damaged sections or potential risk areas in murals can be promptly identified, providing robust data support and reference for cultural relics protection and restoration work11.
However, computer vision-based mural element object detection still confronts a series of issues and challenges. There are considerable difficulties in acquiring and annotating mural element object detection datasets12. Regarding dataset acquisition, murals, as cultural heritage, are often subject to stringent protection measures, making it difficult to obtain high-quality mural image data13. Many murals are located in remote areas or restricted sites, further complicating data collection. High-resolution, clear image data is essential for mural element object detection to ensure accuracy14. However, due to factors such as aging and poor preservation conditions, some murals may experience fading, blurring, or damage, leading to degraded image quality that does not meet detection requirements.
In terms of mural element annotation, the complexity and diversity of mural elements, including figures, animals, patterns, etc., as they may overlap or occlude each other. This necessitates annotators possessing professional art and historical knowledge to accurately delineate the boundaries and categories of each element15. Additionally, maintaining annotation consistency across large datasets is challenging, as different annotators may have subjective differences in defining and categorizing mural elements, resulting in inconsistent annotation results16. Moreover, even within the same category, mural elements can exhibit significant morphological differences due to factors such as drawing styles, eras, and preservation conditions17. This requires models to learn and recognize more diverse features, increasing the complexity of feature extraction. To capture these diverse features, deep learning models may require deeper network structures and more parameters to extract and distinguish subtle feature differences, which increases model parameters and computational complexity18.
For Ancient Chinese murals, extracting semantic features and contextual information during element object detection can help deep models better understand and identify target elements. However, due to significant differences in drawing styles, eras, and colors among murals, there are considerable challenges in extracting semantic features and contextual information for mural element detection19. The diversity of mural drawing styles across different historical periods and regions requires feature extraction methods to adapt to these variations and accurately capture the unique semantic features of each style20. The varying preservation conditions due to aging also pose a challenge, as some murals may become blurred due to prolonged weathering and fading, making it difficult to identify original clear semantic features and contextual information21.
In this paper, we have established a large-scale target detection dataset for ancient murals excavated in China. The murals date from the Qin and Han dynasties (221 BC – 220 AD) to the Ming and Qing dynasties (1368 – 1912 AD), spanning over 2,200 years. We have excavated more than 500 tombs and sites featuring murals, primarily distributed across more than 20 provinces and cities including Henan, Shaanxi, Shanxi, and Shandong, collecting a total of 2,358 mural images. In this dataset, we labeled six categories: male, female, beast, flower, bird, and cloud, with a total of 11,790 labeled samples. This dataset provides significant academic and application value for subsequent research. Furthermore, we have developed an adaptive random erasure data augmentation algorithm tailored to the characteristics of the ancient Chinese mural dataset, which can extract element target features even with partial information missing. This is beneficial for better handling cases of partial information loss in murals due to age, preservation conditions, and other factors. Additionally, we have established a lightweight multi-scale feature extraction backbone network that significantly reduces the number of parameters and computational load while ensuring the accuracy of feature element extraction. Moreover, to enhance the model’s ability to extract mural element features, we have developed a semantic feature enhancement model for mural elements that improves the model’s understanding and detection accuracy through residual attention and contextual information.
The main contributions of this paper are as follows:
-
1.
Unique Dataset Contribution: We have curated an unprecedented large-scale dataset dedicated to object detection in ancient murals excavated in China. Unlike previous works, this dataset boasts a broad temporal span, geographical distribution, and stylistic diversity, encompassing a vast array of meticulously labeled samples. This comprehensive resource serves as a cornerstone for advancing research on ancient Chinese murals, offering invaluable insights and references that were previously unavailable.
-
2.
Innovative Data Augmentation Technique: Addressing the specific challenges posed by defects in the dataset of ancient excavated murals, we introduce an adaptive random erasing data augmentation algorithm. This novel approach enhances the model’s ability to learn and recognize defective mural object features by augmenting the labeled sample pool, thereby filling a critical gap in existing methodologies.
-
3.
Efficient Multi-Scale Feature Extraction: We propose a lightweight multi-scale feature extraction backbone network tailored for mural elements. This network not only effectively captures features of targets of varying sizes but also significantly reduces computational complexity and parameter count compared to traditional approaches. This efficiency makes it well-suited for real-world applications and resource-constrained environments.
-
4.
Advanced Semantic Feature Extraction Model: Furthermore, we develop a semantic feature extraction model that leverages contextual information and residual attention to derive semantic insights from mural elements. This model represents a significant leap forward in detection accuracy for mural element targets, as it incorporates sophisticated mechanisms to refine and enrich the semantic understanding of the elements, distinguishing our work from previous efforts in this domain.
Related work
Mural Dataset and Image Data Augmentation Algorithm
Ancient murals are a precious cultural heritage of humanity, however, due to historical and natural reasons, the preservation conditions of these murals vary significantly, with some being severely damaged and the images blurred. Therefore, there is an urgent need for professionals in this field to protect these ancient murals. Utilizing virtual simulation and digital technology for the virtual restoration and reconstruction of murals can realistically showcase their original appearance, avoiding physical damage to the murals. This approach is particularly suitable for the virtual restoration of precious and fragile mural artifacts. In recent years, scholars have conducted extensive research in this area, achieving a series of results in fields such as the establishment of ancient mural datasets, virtual restoration of murals, defect detection in murals, and target detection of mural elements.
In the MuralDiff22 algorithm, the authors created an ancient mural defect detection dataset, which provides pixel-level annotations for defect categories such as cracks, peelings, stains, and others present in the murals, thereby offering a reliable basis for subsequent mural restoration. Wang et al.23 selected 2,780 undamaged images from the Thangka mural dataset and virtually restored the Thangka murals using a stroke-based mask generation method. In the DunHuangStitch algorithm24, the authors constructed two datasets for the digital stitching of Dunhuang murals, leveraging a progressive regression image alignment network and a feature difference reconstruction stitching network to achieve this. In RPTK125, the authors established the RPTK1 (Religious Portrait Thangka Version 1) dataset for detecting categories such as headwear, clothing, and religious tools. However, the aforementioned ancient mural datasets are primarily used for mural defect detection, virtual stitching, and target detection of element categories in specific scenarios. They are limited in terms of the number of datasets and the distribution of ages, and they also lack detection and semantic analysis of important elements in ancient murals. In this paper, we establish a large-scale target detection dataset for elements in ancient Chinese murals, which boasts a wide coverage of geographical regions and historical periods, and a rich number of labeled samples. This dataset provides important research materials for subsequent studies and conservation efforts related to ancient Chinese murals.
Data augmentation plays a crucial role in enhancing the robustness and generalization capabilities of computer vision models. In recent years, relevant scholars have conducted extensive research in this area and achieved a series of results. In SPGC26, the authors proposed a data augmentation algorithm based on shape priors, which stylizes data by generating shape information. This algorithm improved the detection performance of models on remote sensing object datasets. In ref. 27, the authors utilized a context model to establish a prior knowledge-based instance segmentation object mixing data augmentation algorithm, which employs convolutional neural networks to predict whether image regions are suitable for data mixing enhancement, and it is capable of achieving performance improvements in tasks such as object detection and instance segmentation. In the AutoPedestrian algorithm28, the authors conducted pedestrian detection by automatically searching for optimal data augmentation strategies and loss functions, which defined the augmentation strategies and loss functions as probabilistic distribution problems with different hyper-parameters and utilized a cyclic scheme of importance sampling for optimization. In29, the authors proposed a mixed background data augmentation method to enhance the generalization ability of the model and adopted a partially mixed-stage network to improve the accuracy of object detection in surveillance videos.
Lightweight feature extraction backbone network
Lightweight networks significantly reduce the computational load of models by optimizing the network structure and employing efficient convolutions, achieving good performance even with limited computational resources. In object detection models, the introduction of multi-scale feature extraction models allows for the integration of targets of different sizes, enabling precise predictions for targets of various scales. In recent years, researchers have combined lightweight backbone networks with multi-scale feature extraction models for object detection tasks in various scenarios, significantly lowering the computational load while maintaining high prediction accuracy. In the algorithm SAMNet30, the authors propose a stereo multi-scale attention model to adaptively fuse features of various scales, a lightweight model is adopted in the feature extraction backbone network, which significantly reduces the computational complexity and the number of parameters of the model while maintaining the accuracy of object detection. In ref. 31, the authors propose a lightweight multi-scale contextual semantic information feature extraction model for object segmentation, which captures multi-scale semantic information through a lightweight feature pyramid module and uses a boundary fusion module to propagate pixel features, demonstrating significant advantages on semantic segmentation datasets. In ref. 32, the authors propose a road crack detection model based on segmentation exchange convolution, which divides feature maps into different resolutions to filter out redundant information and employs a multi-scale feature exchange model to promote the fusion of cross-stage features, thereby constructing a lightweight and high-precision crack defect detection algorithm.
In ref. 33, the authors design a lightweight multi-scale cross-modal remote sensing image retrieval model, which obtains text features through lightweight group convolution and captures multi-scale information of remote sensing images during encoding. In Lite-FENet34, the authors propose a lightweight multi-scale feature enhancement network for object segmentation on small sample datasets, which enhances the interactive fusion of multi-scale features while maintaining feature discriminability with a lower computational load. In SwinWave-SR35, the authors propose a multi-scale lightweight underwater image super-resolution enhancement model based on the Swin transformer, which utilizes a wavelet transformation module to avoid information loss during downsampling and employs self-attention learning to retain key information while reducing computational costs. In ADMNet36, the authors propose an attention-guided multi-scale lightweight salient object detection model, which utilizes a multi-scale perception module to obtain different contextual features and employs a dual attention module to filter out interference information, thereby enabling deep features to focus more on salient regions. In PolypSeg+37, the authors propose a lightweight context-aware network for detecting colorectal polyp targets, which utilizes a lightweight attention adaptive context module to eliminate background noise and perform feature fusion.
Semantic feature enhancement model
The semantic feature enhancement model plays an important role in object detection algorithms by improving feature representation capability, enhancing object recognition ability, reducing background noise interference, optimizing the feature fusion process, and increasing detection accuracy and efficiency. In ref. 38, the authors propose a covert object detection model based on weakly supervised semantic feature enhancement. This model learns the semantic information of objects of different sizes by constructing a multi-scale weakly supervised feature optimization network, which strengthens the representation capability of object semantic features while suppressing background noise. In SFSANet39, the authors present a remote sensing object detection algorithm that leverages semantic information fusion and adaptive scaling, enriching semantic information through a semantic fusion module and suppressing background noise with a spatial attention module, thereby proving its effectiveness on publicly available remote sensing datasets. In the ContrastZSD40, the authors propose a zero-shot object detection algorithm based on a semantic-guided contrastive network, this algorithm utilizes real labels and category similarity information to learn semantic information, demonstrating the effectiveness of the proposed zero-shot object detection algorithm on public datasets. In ref. 41, the authors introduce an aero-engine blade surface defect detection algorithm grounded in a cross-layer semantic guidance network, which harnesses deep semantic information to steer shallow feature layers for the identification of minute defect targets.
In SCFNet42, the authors propose a Semantic Correction and Focus Network for high-resolution remote sensing image object detection, this algorithm employs a local correction module to acquire global similarity features and utilizes a focus module to enhance the semantic information of targets, the effectiveness of the proposed algorithm is validated on publicly available remote sensing object datasets. In43, the authors investigate unsupervised adaptation without source data for video object detection and propose a Mean Teacher-based Spatio-Temporal Alternating Refinement method, which enhances the accuracy of object detection in adverse scenarios. In DSCA44, the authors introduce a domain adaptive object detection algorithm based on a dual semantic alignment model, this algorithm utilizes contextual information to align the target semantic information between the source and target domains, achieving precise object detection in challenging weather conditions for autonomous driving scenarios.
Method
This paper achieves efficient and accurate detection of ancient mural elements excavated from China in complex and challenging scenarios. Firstly, to address issues such as fading, peeling, and damage present in the mural dataset, we establish an adaptive random erasing data augmentation algorithm. This algorithm enhances the detection model’s ability to learn and recognize features of defective mural targets by randomly erasing certain regions. Additionally, we construct a lightweight multi-scale feature extraction backbone network for mural elements, which excels at effectively extracting features from targets with significant size differences, its lightweight design greatly reduces the computational burden and the number of parameters in the model. Moreover, we also develop a target semantic feature extraction model for ancient Chinese mural elements. This model utilizes residual attention and contextual information to capture the semantic features of mural elements, thereby effectively improving the detection accuracy of mural element targets.
Dataset of ancient mural unearthed in China
Murals specifically refer to artworks painted on walls or floors, and such paintings have been discovered in both ruins and tombs. Since the Qin and Han dynasties and beyond, the abundant discovery of ancient Chinese murals has become an important part of archaeological research. Since the 1920s, with the continuous deepening of archaeological work, many important murals have been found, most of which are excavated from tombs, while a few are found in palace and temple ruins. The ancient murals unearthed in China are rich in content and vivid in imagery, serving not only as witnesses to history but also as invaluable materials for studying ancient social life. Whether it is the life scenes of royalty and commoners, the stories of celestial myths and urban legends, the natural landscapes such as mountains, rivers, the sun, the moon, and stars, or the lively forms of birds, beasts, flowers, birds, fish, and insects, they have all been preserved through the exquisite skills of ancient painters, presenting themselves to us across the ages. Research on the elements in these murals not only helps us gain a deeper understanding of the ancient society’s appearance but also reveals the ancient people’s aesthetic concepts, living customs, and changes in the natural environment, thus possessing extremely important academic value.
In this paper, we have constructed a target detection dataset of ancient mural elements excavated from China. This dataset has included murals from 577 tombs and archaeological sites, which are widely distributed across 23 provinces and municipalities, including Henan, Shaanxi, Shanxi, and Shandong. A total of 2358 mural images have been collected, and the dataset has covered a broad area, which are rich in resources and highly representative.
Our dataset originates from the valuable collections of numerous archaeological sites and museums, encompassing murals directly excavated from archaeological discoveries, murals displayed in museums, and mural images sourced from historical documents. To ensure the diversity and representativeness of the data, we specifically selected murals spanning different historical periods and geographical regions, covering various dynasties from the Qin and Han dynasties to the Ming and Qing dynasties. Furthermore, we collaborated with multiple archaeological research institutions, such as the Henan Ancient Mural Museum, to obtain first-hand archaeological excavation materials and mural images. The images in the dataset have been meticulously screened and preprocessed to guarantee their quality and representativeness. We employed high-resolution image acquisition technology to preserve as much detail and characteristic features of the murals as possible. Additionally, we performed image processing such as noise reduction and contrast enhancement to improve the clarity and readability of the images. In terms of representativeness, we ensured that the dataset contains various types of mural elements, such as figures, animals, plants, and architectures, to comprehensively reflect the rich content of ancient Chinese murals. When constructing the dataset, we fully considered the diversity and complexity of the data to enhance the generalization capability of the model. By incorporating mural images from different historical periods and geographical regions, we can train a more robust and generalized model that can recognize and process various types and styles of mural elements. Furthermore, we further increased the diversity of the data through data augmentation techniques (such as rotation, scaling, flipping, etc.) to improve the generalization performance of the model.
During the construction process, we have meticulously annotated the images in the dataset, specifically marking six categories: male, female, beast, flower, bird, and cloud. The total number of annotated samples has reached 11790, and these labeled categories reflect the majority of element types found in the murals, providing a sufficient quantity of sample annotations. The dataset of ancient mural elements created in this paper has been made public on GitHub, and the download link is referenced in (https://github.com/jiaquanshen/Murals-Elements-Target-Detection). Figure 1 has shown examples of different element categories established in the dataset.

Sample of mural element categories (a) Male (b) Female (c) Beast (d) Flower (e) Bird (f) Cloud.
The element category samples shown in Fig. 1 depict relatively simple scenes with well-preserved murals. However, the majority of ancient murals, having endured thousands of years, often exhibit fading, peeling, and damage, resulting in blurred features of target elements in the images that are difficult to accurately identify. Furthermore, ancient Chinese murals are rich and diverse in content, encompassing elements such as humans, animals, plants, and natural scenery, with each element manifesting itself in various forms across different periods and regions. Additionally, ancient Chinese murals frequently feature small and occluded targets within large and complex scenes, all of which pose significant difficulties and challenges to the detection of mural element targets. Figure 2 illustrates challenging scenarios encountered in the detection of ancient mural element targets.

Challenging Scenarios in Ancient Mural (a) Fading (b) Peeling (c) Damage (d) Missing part (e) Complex Scenes (f) Small Objects.
Adaptive random region erasing augmentation model
In this paper, we propose an adaptive random region erasing mural image augmentation model that simulates scenarios such as occlusion and damage that mural images may encounter in real-world applications. This model enhances the deep model’s understanding and recognition capabilities for mural images. During the training process, the model adaptively and randomly selects regions in the image to set their pixel values to a solid color, thereby forcing the model to learn more comprehensive feature representations instead of relying solely on feature regions within the image. Unlike previous methods that passively extract features of defective targets, the approach proposed in this paper actively and randomly generates defective regions, thereby forcing the model to learn the features of incomplete element targets and subsequently improving the accuracy of element target detection.
In the mural element target detection task, deep models primarily focus on the information within the bounding boxes during training and detection. Therefore, in the proposed adaptive random region erasing image augmentation model, the key areas of focus are the target bounding boxes and their surrounding regions in the training data. To this end, the proposed adaptive random erasing mural image augmentation model includes the following three design principles. 1) Include areas surrounding the labeled target and within the target. This principle aims to enhance the model’s contextual awareness by erasing regions around the target bounding box. In object detection, the contextual information surrounding the target is crucial for accurately identifying and localizing the target. By randomly erasing these regions, the model is forced to learn to infer the presence and location of the target from the remaining, potentially incomplete information, thereby improving its generalization ability and robustness. 2) Avoid erasing significant regions of the target. This principle aims to prevent excessive disruption to the core features of the target, ensuring that the model can still learn sufficient target features from the remaining information. If significant regions of the target are erased, the key features contained in those areas will be lost, which may make it difficult for the model to recognize the target. 3) The aspect ratio of the erased area’s bounding box should be close to that of the original labeled target. This principle aims to maintain the consistency in shape between the erased area and the target bounding box, reducing disruption to the overall structure and layout of the image. When the shape of the erased area is similar to that of the target, the model is better able to infer the content and location of the erased area from the remaining image information.
During the training process, as shown in Fig. 3, the adaptive random region erasing model randomly selects a point (P({P}_{x},{P}_{y})) on the target’s bounding box. Then, the ({P}_{x}) point extends randomly a distance of (a) to the left and a distance of (b) to the right. Similarly, the ({P}_{y}) point extends randomly a distance of (d) upward and a distance of (c) downward.
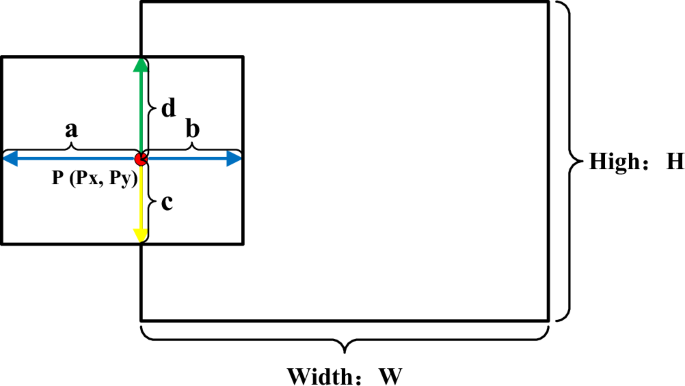
Adaptive random region erasing model.
Thus, the point (P({P}_{x},{P}_{y})) along with the four distances (a), (b), (c), and (d) form a randomly erased area. At this moment, the area of the randomly generated rectangular region is defined as ({{S}_{rand}}=(a+b)times (c+d)), and the area of the bounding box of the target is defined as ({{S}_{bound}}=Htimes W). The ratio of the height and width of the randomly generated rectangular region is (Rrand=(c+d)/(a+b)), and the ratio of the height and width of the bounding box is (Rbound=H/W). We define a parameter named (Io{U}_{Srand}), as described in Eq. (1).
(Io{U}_{Srand}) represents the ratio of the intersection area between the randomly generated erasing region and the bounding box area to the area of the generated erasing region, which falls within the range of ([0,alpha ]), where the value of a is in the range of [0.3, 0.7]. The purpose is to satisfy the first principle of the adaptive random region erasing algorithm, which states that the randomly generated erased area should be located around the bounding box, with approximately half of the generated area inside the bounding box. This ensures that the generated area contains sufficient contextual information, thereby forcing the model to learn the context and background information surrounding the object.
Although (Io{U}_{Srand}) can keep the ratio of the randomly generated erased area to the entire erased area within a reasonable range, if the generated area covers a significant portion of the target’s labeled region, it may lead to the loss of essential information about the target’s salient features, making it difficult to effectively learn the key characteristics of the target. To address this, we introduce another parameter, (Io{U}_{Sbound}), to limit the ratio of the generated erased area to the area of the target’s bounding box. As shown in Eq. (2), (Io{U}_{Sbound}) represents the ratio of the area of the intersection between the randomly generated erased area and the bounding box area to the area of the bounding box, with this ratio falling within the range of ([0,beta ]), where the value of (beta) is in the range of [0, 0.3]. The purpose is to adhere to the second principle of the proposed adaptive random erasing algorithm, which states that the generated erased area should not exceed 30% of the entire bounding box area. This aims to prevent excessive damage to the core salient features of the target, ensuring that the model can still learn sufficient target features from the remaining information.
Additionally, the adaptive random erased rectangle should roughly maintain consistency in shape with the target labeled area. When the shape of the erased region is similar to that of the target, the model can more easily perceive the erased area as an occlusion or deformation of the target during the inference process, thereby enhancing its robustness to occlusions and deformations. As shown in Eq. (3), ({R}_{rand}) represents the ratio of the height and width of the generated erased rectangle, ({R}_{bound}) represents the ratio of the height and width of the target bounding box. (chi) is a hyperparameter with a value range of [−0.1, 0], and (delta) is another hyperparameter with a value range of [0, 0.1]. The purpose of these two hyperparameters is to ensure that the shape of the generated erased region remains roughly consistent with that of the original labeled object.
When the shape of the erased region is similar to the shape of the target bounding box, the model is more likely to perceive the erased area as a natural variation or occlusion of the target while processing these augmented images, rather than as an entirely unrelated distraction. This consistency in shape helps the model learn how to adapt to variations in the target’s shape, thereby enhancing its robustness to shape changes. If the shape of the erased region differs significantly from the target shape, it could introduce unnecessary shape distortions, which may mislead the model in learning the target features. By maintaining the consistency of the erased region with the target’s shape, such unnecessary distortions can be reduced, allowing the model to focus more on learning the essential characteristics of the target. By adhering to the three principles mentioned above, the randomly generated erased regions can be kept within a reasonable interval and range, and the algorithm must satisfy all three conditions during execution. If not, it will continue to randomly generate a point on the labeled bounding box until it produces an acceptable erased region.
Lightweight multi-scale backbone network
Figure 4 illustrates the overall framework of the proposed object detection algorithm for mural elements excavated from ancient China. In this algorithm, the mural dataset is first augmented through the proposed adaptive random erasing image augmentation model to expand the training dataset. Subsequently, the augmented mural image dataset is input into the proposed lightweight multi-scale feature extraction backbone network for target feature extraction. The extracted features are then fed into the semantic feature extraction model to obtain high-level information of the mural element targets. Finally, the positions and categories of the mural element targets are predicted by a fully convolutional network.
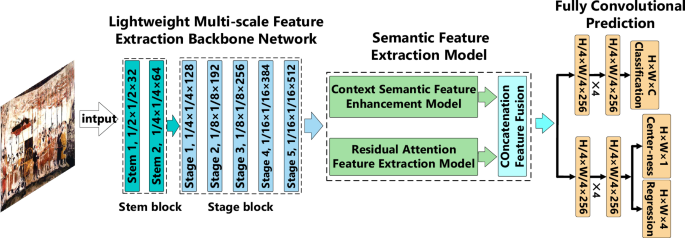
Overall framework diagram of the proposed algorithm.
The lightweight multi-scale backbone network consists of two parts: the Stem block and the Stage block. The primary function of the Stem block is to perform spatial downsampling on the input images through convolution and pooling operations. This downsampling operation reduces the size of the images while increasing the number of feature channels to enhance the depth and breadth of feature representation. It also reduces the computational load of the model by maintaining a consistent number of internal propagating channels. This module significantly decreases the computational burden without noticeably compromising the expressive capability of the features. The Stage block further refines the features input from the Stem block feature extraction module. It progressively increases the number of feature channels using a channel-stacking approach and employs a multi-scale feature fusion technique that combines low-level detail features with high-level semantic information. This allows the model to gain a more comprehensive understanding of the image content.
Figure 5 illustrates the structure of the Stem block in the proposed lightweight multi-scale feature extraction backbone network. The Stem block is divided into two smaller modules, namely Stem block-1 and Stem block-2. In Stem block-1, the input image size is (Htimes Wtimes 3). After performing a convolution operation with a kernel size of (3times 3), a stride of 2, and 32 channels, a feature map of size (H/2times W/2times 32) is obtained. The resulting feature map undergoes dual feature extraction and propagation: one path involves a convolution operation with a kernel size of (2times 2), a stride of 1, and 32 channels, while the other path first performs a convolution operation with a kernel size of (1times 1), a stride of 1, and 32 channels, followed by a convolution operation with a kernel size of (3times 3), a stride of 1, and 32 channels. After the convolutions, the feature maps from both paths are combined using an element-wise feature fusion operation, followed by a (1times 1) convolution operation.
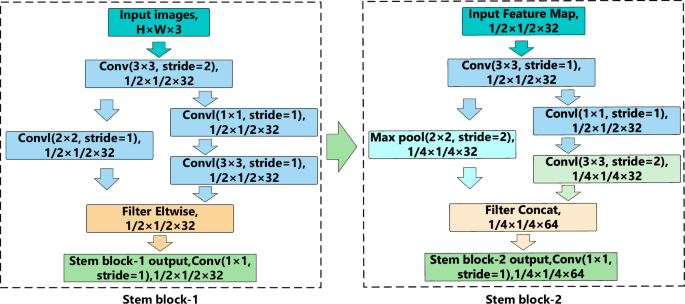
Internal Structure Diagram of Stem Block.
In Stem block-2, the feature map extracted from Stem block-1 is first subjected to a convolution operation with a kernel size of (3times 3), a stride of 1, and 32 channels. The feature map then undergoes dual feature extraction and propagation again. One path performs a Max Pooling operation with a kernel size of (2times 2), a stride of 2, and 32 channels, while the other path consists of a convolution operation with a kernel size of (1times 1), a stride of 1, and 32 channels, followed by another convolution operation with a kernel size of (3times 3), a stride of 2, and 32 channels. Finally, the features from both paths are fused through concatenation, followed by a (1times 1) convolution operation, resulting in the final feature map of the Stem block.
In the Stem block, the feature maps undergo a dual-path approach for feature extraction, where each path employs convolution operations with different kernel sizes. This dual-path design is strategically implemented to effectively capture both local and texture details within the images. Simultaneously, it reduces the spatial dimensions of the feature maps and increases the number of channels, which helps in encoding more detailed and discriminant information. The incorporation of smaller convolution kernels in one of the paths facilitates a reduction in computational complexity while still retaining critical feature information, thereby enhancing efficiency. The design of these two parallel paths within the Stem block significantly contributes to decreasing both the computational load and the parameter count of the overall model. The result is a more streamlined and efficient model that maintains high performance. Stem block-1 specifically performs multi-scale element-wise feature fusion. This innovative technique allows for direct computations and interactions between feature maps from different layers or sources at corresponding positions. Stem block-2 employs concatenation for multi-scale feature fusion. This method involves stitching together feature maps from different layers along the channel dimension, thereby combining diverse feature representations into a single. This concatenated feature map provides a richer and more nuanced representation of the input data, further enhancing the model’s ability to detect and analyze intricate patterns and structures.
Figure 6 illustrates a more detailed framework of the Stage block feature propagation. As shown in Fig. 6, within the Stage block, we employ a channel stacking approach to progressively enhance the number of channels in the feature maps. This approach enables the gradual acquisition of more refined target features while significantly reducing the model’s computational load and improving detection efficiency. In previous mainstream convolutional neural network backbone feature extraction architectures, the increase in the number of feature channels during extraction and propagation typically followed a relatively fixed growth pattern, often in powers of two. For example, the feature channel count might increase from 64 to 128, then to 256, and so on to 512. This exponential growth pattern in the number of feature channels can result in the loss of information regarding small target features. Additionally, this method leads to a substantial number of model parameters, thereby decreasing training and inference efficiency. In this paper, we propose a lightweight feature extraction network based on channel stacking, which acquires more detailed target features by incrementally increasing the number of feature channels. Unlike previous methods of feature extraction and channel propagation, in this paper, we utilize a lightweight feature stacking network to progressively acquire more refined features of the target. This approach not only ensures the ability to extract features of ancient mural element targets but also reduces the computational load of the model. This approach reduces the model’s parameter count while enhancing detection accuracy. As depicted in Fig. 6, within the first three small blocks of the Stage block, the number of feature channels in each convolution operation increases by 16, while in the last two blocks, it increases by 32 with each convolution operation.
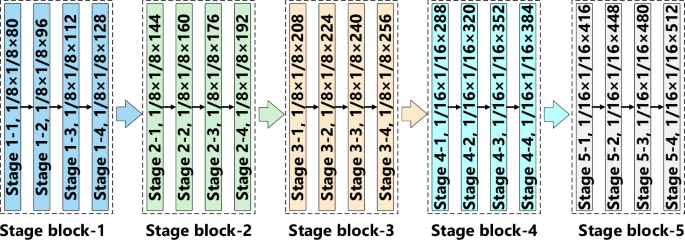
Framework Diagram of Stage Block.
Figure 7 illustrates the network architecture for feature extraction and propagation within Stage block 1-1. In Stage block 1-1, the features obtained from Stem block 2 are used as the input feature map, which undergoes three branches for feature extraction and propagation. The first branch processes the feature map through a convolution followed by a downsampling convolution. The second branch applies a Max Pooling downsampling operation. The third branch consists of a convolution, a downsampling convolution, and another convolution. These three branches extract and propagate features from different scales, ensuring that the deep model can achieve a larger receptive field while adequately considering the feature information of small targets. This approach aids the model in simultaneously attending to information from different scales when dealing with complex scenes. Additionally, maintaining the same number of channels for inputs and outputs during convolution operations minimizes memory consumption. Therefore, we ensure that the internal feature channels have a consistent count during feature extraction. Furthermore, within the Stem block, we make full use of the convolution kernels to facilitate cross-channel information interaction. The convolution not only effectively enhances the model’s linear expressiveness and its ability to extract features of small targets, but it also significantly reduces the computational load of the model.
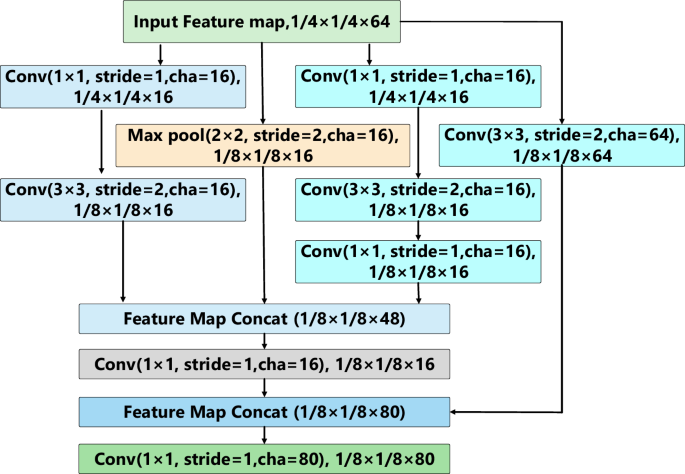
Framework Diagram of Stage Block 1-1.
Semantic Feature Enhancement Model
In object detection tasks, semantic feature information can assist deep models in better understanding and interpreting images, enabling algorithms to accurately identify targets in complex detection scenarios. In this paper, we establish a target semantic feature extraction model for elements of ancient Chinese murals, which comprises a context information fusion module and a residual attention module, enabling the input feature maps to undergo feature extraction and fusion through these modules, thereby enhancing the semantic information features. The semantic feature extraction model proposed in this paper includes a context information fusion module and a residual attention module. These two feature extraction modules capture semantic information between ancient mural element targets across different dimensions, and ultimately obtain high-level semantic feature information of the element targets through Concat feature fusion.
The context information fusion module is capable of fusing features from different levels or scales, which helps capture multi-scale information in the image. This enables the model to gain a more comprehensive understanding of the image content, thereby improving the detection accuracy of target objects. Figure 8 demonstrates the proposed context information fusion module, where we further extract and fuse features obtained from each stage block. Specifically, in the first three stage blocks, we apply a Max pooling operation with a size of (3times 3), a stride of 2, ensuring consistency in feature map dimensions. Subsequently, a convolutional operation with a kernel size of (1times 1), a stride of 1, and 512 channels is applied to increase the dimensionality of the feature maps. In the last two stage blocks, we first apply a convolution operation with a size of (3times 3), a stride of 1, and the same number of channels, followed by another convolution operation of size (1times 1), with a stride of 1 and 512 output channels. After these operations, each stage block produces a feature map of size (1/16times 1/16times 512). We concatenate the final feature maps of this size from each stage block and perform a convolution operation with dimensions (1times 1times 512) to obtain the final context information feature representation. In the context of murals element detection, the target elements are often situated within complex background information. The proposed context information fusion module helps the model better process background information and distinguish between foreground and background, thereby reducing both false positives and missed detections.
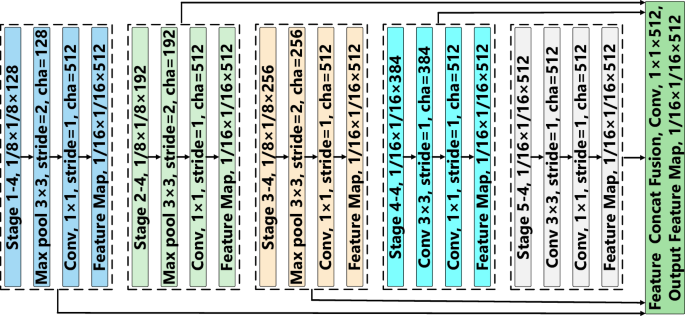
Contextual Semantic Feature Fusion Model.
The residual attention feature extraction model combines the advantages of both residual networks and attention mechanisms. Residual networks address the training difficulties of deep networks by introducing residual connections, enabling the network to go deeper and thus learn more abstract and complex feature representations. The attention mechanism automatically focuses on the significant parts of the input features, ignoring irrelevant information, thereby further enhancing the accuracy and efficiency of feature extraction. In the task of target detection of ancient Chinese mural elements, this efficient feature extraction capability enables the model to learn complex image and texture information within the murals, and exhibit a strong sensitivity to color variations within the murals.
Figure 9 illustrates the network framework of the proposed residual attention feature extraction model. As shown in Fig. 9, the input to this module is the feature map extracted by the previous lightweight feature extraction module. The feature map obtained previously first undergoes a residual feature extraction process, followed by a convolutional operation with a kernel size of (3times 3) and a stride of 2. This reduces the size of the feature map to half of its original dimensions, which is then input into a residual block for further processing. Subsequently, a Max pooling operation with a kernel size of (2times 2) and a stride of 2 is applied, and the resulting feature map undergoes residual calculation. In the feature fusion stage of the proposed residual attention feature extraction model, we use bilinear interpolation upsampling to upsample the acquired feature map and perform feature fusion. By using bilinear interpolation for upsampling, the high-level feature map can be enlarged to the same resolution as that of the low-level feature map, enabling effective feature fusion. This fusion method integrates features from different levels, not only restoring the resolution of the feature maps but also supplementing the contextual information of the targets. The proposed residual attention feature extraction model, with its robust feature extraction capabilities, can extract useful feature information from these damaged mural images, thereby enhancing the robustness of the model. Additionally, the attention mechanism enables the model to focus more on the key features of mural elements, accelerating the detection speed while ensuring detection accuracy.
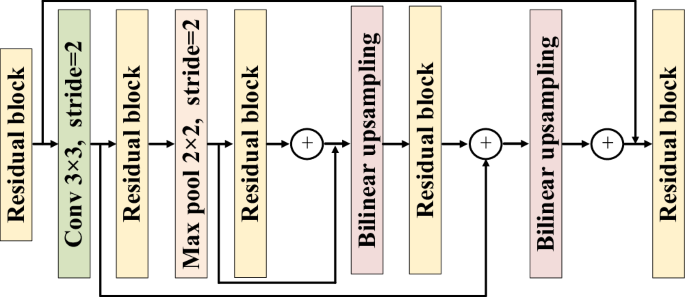
Residual attention feature extraction model.
Results
In this section, we will validate the effectiveness of the proposed element target detection model on the created ancient Chinese mural element target detection dataset. Specifically, we will conduct a series of extensive ablation experiments to verify the contributions of the proposed adaptive random region erasure mural image augmentation model, lightweight multi-scale feature extraction backbone network, and semantic feature enhancement model to the detection accuracy and speed within the overall model.
Furthermore, we will compare and analyze the detection results of the proposed mural element target detection model with several other state-of-the-art object detection models on the mural dataset. The software and hardware environment used in the experiments of this paper are as follows: the deep learning framework is Pytorch, the operating system is Ubuntu 16.04 (Canonical, London, UK), the CPU model is i9-11900k (3.5 GHz), the GPU model is NVIDIA RTX4090 (24 GB memory), and the memory is 64GB (DDR5 4800 MHz).
In this paper, we have improved the accuracy and speed of detecting ancient Chinese mural elements in complex scenes through methods such as the adaptive random erasure image augmentation model, lightweight multi-scale feature extraction backbone network, and semantic feature enhancement model. To validate the impact of the proposed modules on the detection results, we have conducted numerous experiments to demonstrate the accuracy and computational cost of detecting ancient mural elements under different module combinations. As shown in Table 1, the proposed adaptive random region erasure image augmentation model can simulate deficiencies faced by murals in real detection scenarios. This method generates a large amount of sample data that meets training requirements, enhancing the deep object detection model’s understanding of mural images. The introduction of this module has improved the detection accuracy by 5.9%. The proposed lightweight multi-scale feature extraction network enhances the model’s ability to extract features of mural element targets in complex scenes through methods such as channel stacking, unified internal feature propagation, and multi-scale feature extraction. This ensures that the model captures fine features of targets at different scales while reducing both the computational load and parameter count of the model. The introduction of this module has improved detection accuracy by 2.3% and reduced the computational load by 47.1%. The context information fusion module comprehensively considers the overall environment and local details of the murals, enhancing target recognition robustness in complex environments. The introduction of this module increases detection accuracy while adding minimal computational load. Additionally, the introduction of the residual attention mechanism module has also effectively improved the model’s detection accuracy. Although the semantic feature model incurs an increase in computational load, it has achieved a more suitable balance between computational accuracy and computational cost. Ultimately, the proposed ancient Chinese mural element target detection model achieves a detection accuracy of 87.5% on the created dataset, with FLOPs of only 268 M.
To further validate the effectiveness of the proposed mural element target detection algorithm, we have conducted a comparative analysis of its detection results against several other state-of-the-art object detection algorithms on the created dataset. Table 2 presents the detection accuracy, detection time, and other metrics of various lightweight or semantic feature-based object detection algorithms on the mural dataset. As shown in Table 2, the mural element target detection algorithm proposed in this paper, which is based on a lightweight multi-scale feature extraction backbone network and a semantic feature enhancement model, demonstrates significant advantages in both detection accuracy and detection speed. This algorithm meets the needs for mural element target detection in complex scenes, providing robust technical support for the study and subsequent conservation of mural elements. Specifically, on the created ancient Chinese mural element dataset, the proposed target detection algorithm achieved a recall rate of 87.6%, a precision rate of 89.3%, an F1-score of 0.884, and a mean Average Precision (mAP) of 87.5%, with an average detection time of only 0.022 seconds per image.
In this detection task, there are significant differences in the number of labeled samples among the different mural element categories, and there is also substantial variation in the intraclass feature presentation within the same category. As a result, the six element categories created in the dataset show noticeable differences in detection accuracy and speed. Table 3 presents metrics such as detection accuracy and detection time for different element categories on the proposed detection model. As shown in Table 3, there are considerable disparities in the number of samples and detection results among the mural element categories. In particular, the Male and Female categories boast a larger number of samples with relatively small intra-class feature variations, leading to significantly higher detection accuracy and speed compared to other categories. In contrast, the Flower, Bird, and Cloud categories have a relatively smaller number of labeled samples, coupled with substantial intra-class feature differences, resulting in lower detection accuracy.
Table 4 demonstrates the impact of the proposed adaptive random erasing augmentation model, lightweight backbone network model, and semantic feature enhancement model on the detection accuracy and speed for various types of mural elements. As shown in Table 4, the adaptive random erasing augmentation model can effectively improve the detection accuracy of target elements. The lightweight backbone network model exhibits significant advantages in enhancing detection speed. Although the semantic feature enhancement model sacrifices some detection speed, it achieves good results in terms of improving target feature extraction capability and detection accuracy.
Figure 10 presents the visualized detection results of different mural element categories. As shown in Fig. 10, the proposed mural element object detection model is capable of effectively detecting categories such as Male, Female, Beast, Bird, Flower, and Cloud on murals. For each detection result, the model provides a confidence score indicating its certainty in the prediction. A higher confidence score suggests that the model is more confident that the prediction is correct. Such visualized detection results are of great significance for mural research, protection, restoration, and artistic appreciation. They can assist researchers in more accurately analyzing the constituent elements, artistic styles, historical backgrounds, and other information of murals, providing strong support for in-depth mural research and protection. At the same time, for art lovers and connoisseurs, such visualized presentations undoubtedly enhance their understanding and appreciation of mural art.

Visualized Detection Results of Different Mural Element Categories.
Figure 11 showcases the detection results of mural element targets in complex and challenging scenes. As illustrated in Fig. 11, these scenes contain dense element targets, with a large number of targets and limited distinguishing features for each individual target. Additionally, the murals exhibit defects such as damage and peeling, which significantly increase the difficulty of detecting the element targets. In this paper, we enhance the detection capability for damaged mural element targets through an adaptive random erasing augmentation algorithm to expand the sample size, and we improve detection accuracy and speed using a lightweight backbone network and a semantic feature extraction model. As shown in Fig. 11, although the complexity of the scenes results in low confidence in target detection, the proposed algorithm successfully achieves effective detection of mural element targets in these complex and challenging environments. Furthermore, by analyzing the results of mural element target detection, we gain deeper insights into the compositional elements, stylistic features, and historical changes of the murals, providing richer information and data support for the academic research and conservation of murals.

Visualization detection results in complex and difficult scenarios.
Although the mural element object detection model proposed in this paper demonstrates good detection performance on the created dataset, its effectiveness on mural datasets with different cultural backgrounds and styles has not been verified. In our future work, to further enhance the generalizability of the proposed algorithm, we can first expand the mural dataset to include murals of various styles and types, such as by incorporating ancient Buddhist murals from Dunhuang, China, and ancient European art murals. Additionally, we will conduct a more refined classification of the element types within the murals, for instance, by providing more detailed annotations for different types of figures, enabling the model to extract and learn the essential features of different categories. Furthermore, we will attempt to utilize diffusion models for mural element object detection, allowing the model to recognize unlabeled object types and thus improving the applicability and robustness of the detection model.
Conclusion and discussion
In this paper, we propose a model for the recognition and understanding of elements in ancient murals unearthed in China, achieving efficient detection of mural elements in various complex environments and challenging detection scenarios. In our work, we first created a large-scale dataset for target detection of ancient murals, which features a wide chronological span, a vast number of samples, and a rich variety of labeled categories. To further enrich the number of mural image samples, we have established an adaptive random erasure augmentation model for mural images, capable of randomly generating erasure regions to simulate the damage that may exist in murals, thereby forcing the model to learn the ability to recognize and understand element targets through incomplete image information. Additionally, we have developed a lightweight multi-scale backbone network for feature extraction of mural elements. This model significantly reduces computational load while maintaining detection accuracy through a lightweight convolutional neural network and multi-scale feature fusion methods. Furthermore, to enhance the semantic understanding of mural elements, we have introduced a semantic feature enhancement model for mural elements, which improves semantic understanding and increases detection accuracy through contextual information and residual attention mechanism. The ancient mural element object detection algorithm proposed in this paper achieves a recall rate of 87.6%, a precision rate of 89.3%, a mean Average Precision (mAP) of 87.5%, and an average detection time of 0.022 s per image on the created dataset. These results demonstrate that the proposed method outperforms several other state-of-the-art object detection algorithms in both detection accuracy and speed.
However, the research presented in this paper still has some shortcomings and limitations. While the proposed method is capable of accurately detecting the target elements on mural paintings, it cannot accurately ascertain the historical and dynastic information associated with those elements. For instance, the method cannot determine the era of the figures based on their headgear and attire. Furthermore, a crucial aspect of digital research on ancient Chinese mural paintings is virtual restoration, and although the method proposed in this paper provides some valuable information for virtual mural restoration, it cannot be directly applied to this purpose. In future research, we will deeply explore the semantic feature information of mural elements, such as the dynasties, artistic styles, and cultural backgrounds they pertain to. Meanwhile, based on the established dataset of ancient Chinese mural paintings excavated from archaeological sites, we will focus on virtual restoration and reconstruction. We will utilize computer vision techniques to extract shape and texture features from mural images and seamlessly blend them with surrounding areas to optimize the generated textures. Additionally, by applying the principles of traditional art restoration in conjunction with computer vision outputs, we will reasonably reconstruct colors, shapes, and details.




Responses