Automatic recognition of cross-language classic entities based on large language models

Introduction
Chinese culture has a long history, and classical texts are a vital inheritance of historical memory and a repository of the long-standing civilization of the Chinese nation, playing an important role in its development and transmission. These texts contain rich knowledge and embody the long history and culture of the Chinese people. The development and utilization of classical texts can better promote the excellent traditional Chinese culture. Accelerating the transformation and utilization of antiquarian book resources, especially promoting the digitization of antiquarian books and popularizing and disseminating antiquarian books. Not only do classical texts need to be passed down from generation to generation, but their study also needs to keep up with the times and embrace innovation. To preserve classical texts and continue the long-standing traditional culture of China, an increasing number of scholars are engaged in classical text research, promoting the creative transformation and innovative development of Chinese civilization and bringing the written words in classical texts to life.
One important way of bringing the written words in classical texts to life is to improve the level of classical text protection and accelerate the transformation and utilization of classical text resources. Digitizing classical texts involves the use of technologies such as scanning and optical character recognition to preserve the texts in digital form. Classical text digitization is both an essential foundation for humanities research and an important means of value excavation and effective utilization. By utilizing digitization technologies to process and organize vast amounts of ancient book resources, not only can the construction of standardized classical knowledge bases be accelerated, but the in-depth integration and utilization of classical collection resources in China will be promoted1. With the transformation and upgradation of classical text digitization applications, increasing attention has been paid to research on the extraction and application of classical text information resources, including tasks2 such as sentence punctuation3, word segmentation4, part-of-speech tagging5, named entity recognition6, and machine translation7. Digitization not only helps to protect and disseminate cultural heritage, preventing erosion due to time or natural disasters, but also enhances the dissemination efficiency of ancient texts, allowing more users to appreciate the cultural treasures of classical texts.
Named entity recognition (NER) in classical texts is a crucial part of information extraction and plays a vital role in text knowledge mining, knowledge organization, and knowledge graph construction. NER focuses on identifying entities within a text and aims to extract specified entities such as names, locations, titles, and book names from unstructured text. Large language models (LLMs) aim to understand human intentions and generate text similar to natural human language by analyzing input text through pre-training to produce target results. With the development of LLMs and big data technologies, their use in presenting the knowledge in classical texts in a structured form, assisting in text analysis and semantic understanding, and deeply mining the intrinsic value of classical texts will advance the digital, structured, and knowledgeable storage and presentation of classical texts. This is not only a valuable supplement to traditional cultural resources, but also a fundamental resource for cross-linguistic research.
This study aims to explore the performance of LLMs in downstream tasks within the field of natural language processing. First, it validates the feasibility of NER tasks using open-source LLMs and those that were further pretrained and fine-tuned by our research team. Second, it transforms the NER task into a text-generation task and verifies the impact of zero-shot, one-shot, and few-shot prompting on LLM performance in NER tasks after fine-tuning. Finally, it examines the ability of the model to recognize entities with a small amount of high-precision annotated data and determines the generalization capability of LLMs in entity extraction based on the results of fine-tuned models. The application of LLMs in NER tasks introduces new possibilities to traditional natural language processing research, particularly highlighting its advantages in understanding complex contextual content in cross-linguistic classical texts, handling multiple types of entities, and transfer learning, providing insights for future research on LLMs in entity recognition tasks.
-
To explore the performance of NER tasks supported by LLMs.
-
Zero-shot, one-shot, and few-shot prompting methods were used to validate the performance and applicability of LLMs in NER tasks.
-
The fine-tuned LLMs achieved high scores across multiple metrics and demonstrated the generalizability of the model. Additionally, we conducted research using open-source models.
Related work
Classical text entity annotation datasets
NER aims to identify entities such as names, locations, and titles from classical texts and present knowledge in these texts in a structured format to assist in text analysis and semantic understanding. This process helps mine the intrinsic value of ancient texts and promotes the dissemination and utilization of classical knowledge. However, classical text NER faces challenges, including the scarcity of publicly available datasets, high annotation costs, and the need for annotators with specific knowledge backgrounds.
Current efforts to construct classical text datasets have mainly focused on extracting entities such as names and locations from classical texts. For example, Zhuo8 used grid-based long short-term memory (LSTM) networks to annotate three types of entities—names, locations, and titles—from the Stratagems of the Warring States. Xu9 employed four deep learning models—Bi-RNN, Bi-LSTM, Bi-LSTM-CRF, and BERT—to explore four types of entities in ancient texts on local chronicles: aliases of products, people, cited books, and production areas. Zhu10 annotated the parts of speech in the Annals of the Ming Dynasty for the first time. Huang11 used rule-based methods to identify names in the Records of the Three Kingdoms: Book of Shu by Chen Shou. Huang12 automatically identified pre-Qin place names in the Spring and Autumn Annals of the Left and conducted a statistical analysis of the internal and external features of place names, building an automatic recognition model based on conditional random fields (CRF). Li13 studied the agricultural text Local Chronicles of Products and used CRF to identify aliases, locations, and cited names. Xie14 constructed a named entity corpus by analyzing entities and used pre-training + fine-tuning + word vectors to recognize entities in the Huangdi Neijing: Suwen of traditional Chinese medicine. Lin15 used the SikuBERT pre-trained model to build a named entity model for animals in classical texts and identified animal entities in the Records of the Grand Historian. Cui16 used pretrained models to recognize seven types of named entities in classical chrysanthemum poetry: time, location, season, flower names, flower colors, tasks, and festivals. Tang17 constructed a Chinese historical information extraction corpus that includes four types of entities: names, locations, titles, and book names. Tang18 annotated seven major types of relationships in the Twenty-Four Histories, including person-to-person, organization-to-organization, and location-to-organization, as well as 25 specific relationship types such as subordinate, sibling, position, location, attachment, and promotion. Qin19 extracted entity types such as names, locations, titles, and time from five classical texts: Xunzi, Analects of Confucius, Mozi, Mencius, and Zhuangzi by adding features such as part-of-speech, word length, boundary words, and function words. Hu20 extracted four types of entities—names, titles, organizations, and locations—from the Comprehensive Mirror for Aid in Government. Li21 proposed aligning low-resource languages with cross-lingual sample instructions to build instruction datasets containing more domain-specific knowledge. Instruction tuning based on instruction datasets allows large multilingual models to demonstrate better zero-shot multilingual performance and language generalization results by leveraging the generative capabilities of LLMs in high-resource languages. Tuning low-resource language samples provides insights into constructing instructional datasets. Therefore, the construction of classical text datasets can facilitate systematically organizing, classifying, and presenting classical text content, making it a knowledge resource that is easier to understand and utilize, thereby promoting knowledge sharing and cultural exchange.
Current research on NER in classical texts
Entity annotation not only helps in understanding the content of classical texts but also promotes the systematic and associative utilization of knowledge. The accurate identification and categorization of entities in classical texts can significantly enhance the readability, retrieval efficiency, and accuracy of information extraction, thereby providing a solid foundation for subsequent knowledge management and application. Liu22 analyzed the characteristics of names in pre-Qin texts and conducted research on name disambiguation and statistical distribution, which provided insights for future name entity extraction studies. Wang23 improved the model’s understanding of classical texts using domain knowledge-based continued pre-training and fine-tuning methods, as well as context-based entity correction methods, thus enhancing the effectiveness of entity recognition and promoting the intelligent development and utilization of classical resources. Zhang24 proposed a method for classical text NER based on information theory and discourse information. Li25 developed a pre-training method based on classical text data that effectively extracts entity information from classical texts. Yan26 proposed a general framework for the automated extraction of named entities from classical texts, covering aspects such as entity pre-annotation, iterative extraction, and annotation decisions in human-machine interactions. Gu27 addressed the issue of limited research on the internal composition of entity words by proposing a method to explore patterns in entity spans in Chinese NER, that is, pattern-inspired recognition networks. Xiong28 extracted titles and ranks from pre-Qin texts such as the Zuo Zhuan and Guo Yu, providing a reference for diachronic corpus work in classical text processing and exploring the evolution of titles in different eras and genres. Xie29 investigated the performance of LSTM neural networks and conditional random field models in extracting person names, locations, titles, and organization names in the Records of the Grand Historian, followed by entity disambiguation algorithms to improve extraction accuracy. Kang30 addressed the language characteristics of single-character representation and multiple usages in classical texts by using a pre-trained model with integrated dictionary information to extract names, locations, titles, organization names, and time entities from the Comprehensive Mirror for Aid in Government. Lü31 replaced the CRF module with an attention-based LAN model in the LatticeCRF model, improving the integration of entity label information and enabling faster entity recognition in classical texts. Jiang32 demonstrated that extracting features from Chinese character shapes and stroke compositions can enhance NER performance. Chen33 proposed a domain-adaptive NER algorithm based on attention mechanisms. By fine-tuning and adding an attention-based adaptive neural network and applying transfer learning strategies to ancient Chinese corpora, this approach builds cross-domain NER models.
Research progress on LLMs in NER
With the rapid development of artificial intelligence and information technology, the integration of digital humanities and computer technology has provided tools and technical advantages for traditional humanities research. Digital humanities is an interdisciplinary field that combines humanities research with computer technology to advance research and development in the humanities using emerging digital technologies and methods. In the context of the digital intelligence era, classical text organization and research should align with trends of artificial intelligence and big data to enhance the level of intelligent organization and research on classical texts. As tools in natural language processing, LLMs have played a significant role in digital humanities research. In particular, domain-specific LLMs exhibit higher accuracy and efficiency when handling text and tasks from specific domains. Cross-linguistic NER aims to train NER models for the target language using labeled source and unlabeled target-language data. Wang34 built entity recognition and knowledge question-answering LLMs based on four LLMs—Baichuan2-13B-Chat, ChatGLM2-6B, Llama-2-13B-Chat, and ChatGPT—following the high-quality corpus + pre-trained large model + fine-tuning approach. Ding35 proposed a global-local denoising framework for cross-lingual NER, utilizing global and local information in the semantic space to correct incorrect pseudo-labels and improve model generalization. Qiao36 achieved good results in NER tasks by compressing LLMs with advanced training objectives and data strategies. Zheng37 proposed the Lexicon-Syntax Enhanced Multilingual BERT framework, which integrates syntactic knowledge and lexical information, achieving better results than baseline models in NER tasks. Jiang38 introduced a generation-based NER framework that addresses the issues of limited open entity datasets and multiple entity types that disperse model attention. Riaz39 proposed a fully modular neural network method that combines fine-tuned language models with language rules, using masked language models as unsupervised NER models, and applying part-of-speech tags to identify and eliminate unannotated entities, showing that semi-supervised NER models outperform GPT-3.5. Heng40 enhanced the performance of LLMs in structured knowledge extraction tasks by prompting the models to self-reflect on specific domains, generating domain-related content and creating rich training data. Kim S41 proposed an enhanced NER framework that leveraged the knowledge reasoning ability of LLMs. This framework uses the reasoning capability of LLMs to identify errors in existing NER methods based on knowledge and context information, thereby providing insights into research on low-resource data. Through model fine-tuning, technological optimization, and interdisciplinary collaboration, further development of LLMs and digital humanities research offers more opportunities for progress in the humanities, enhancing the efficiency of tasks like classical text NER and providing technical support for in-depth analysis of classical texts.
Research methods and approach
Prompt engineering
A prompt refers to a natural language text input provided to generative artificial intelligence models to execute a specific task or answer a question. This prompt serves as the initial input for the model to generate responses aimed at achieving the desired results. It can be in the form of a question, description, keywords, or any other type of text and is used to guide the model to produce specific content. For example, when using ChatGPT, users interact with an LLM by posing questions (prompts), which allows the model to perform tasks such as answering questions, generating content, and extracting information. Figure 1 illustrates the entire process of research on automatic identification of canonical entities.

General research framework for automatic recognition of canonical entities.
Based on the task requirements, prompts can be categorized as hard, soft, online, offline, or vertical prompts. The purpose of these various types of prompts is to help users interact more effectively with LLMs and optimize the model’s output to meet various application needs. Research indicates that LLMs are well-suited for tasks such as text generation, relation extraction, and entity recognition. Prompt Engineering focuses on guiding LLMs to generate target results without updating model parameters or weights. This involves the use and optimization of prompts to help users leverage LLMs in general scenarios. The main processes in prompt engineering include formatting, content, context, drafting, and optimization. Formatting refers to determining the structure of a prompt according to task requirements or desired outcomes, such as questions, keywords, or descriptions. Content involves the selection of appropriate words, phrases, and questions to ensure that the model understands the intent of the user’s input. The context considers prior information or additional data to ensure that the model responses are relevant to previous questions or information. Drafting involves creating clear and specific natural language descriptions to accurately convey the user’s needs. Optimization involves refining prompts based on the generated results to achieve the desired outcome.
In generative AI, prompt engineering bridges the gap between users and LLMs by understanding user inputs and generating the best possible results. It enhances user experience by enabling quick retrieval of desired outcomes and helps mitigate the impact of biases in the training data on model performance.
Basic Prompting
In LLMs, Basic Prompting involves leveraging the pre-trained knowledge of the model to understand user intentions while minimizing input and quickly adapting to and efficiently handling complex tasks. LLMs demonstrate exceptional zero-shot capabilities but often perform poorly on complex tasks. Few-shot prompting refers to the inclusion of contextual information in the prompts to better guide the model in executing tasks. LLMs possess strong few-shot learning abilities, allowing them to perform various natural language processing tasks with only a few examples provided in the prompt, thereby reducing the need for task-specific data. Wu42 explored improving the zero-shot or few-shot performance of natural language prompts during continuous pretraining and achieved highly accurate results with minimal task-specific learning parameters. Brown43 obtained good results in many natural language processing tasks by pre-training on a large corpus of text and then fine-tuning for specific tasks.
-
(1)
Zero-Shot Prompting: Zero-shot prompting refers to performing downstream tasks directly through textual prompts without further pre-training or fine-tuning the LLM for specific domain tasks. By training general-purpose LLMs and learning the fundamental rules of natural language from training data, models can be guided to complete specific tasks through soft prompts without modifying their parameters or weights. Zero-shot prompting relies heavily on the pretraining process and training dataset of the LLM, which may introduce biases that affect the model’s output. To address issues of accuracy or meet the expected outcomes, further pretraining or fine-tuning of the model for specific domains may be necessary. Wei44 proposed a method to enhance the zero-shot learning capability of language models by fine-tuning an LLM on datasets, thereby improving the zero-shot performance.
-
(2)
Few-Shot Prompting: Few-shot prompting involves adding a small number of examples to the prompt during a dialog to help the LLM understand the user’s intent and generate the desired outcome. Wei45 proposed that by showing a few examples to an LLM and explaining the logic and reasoning process within these examples, the model can be guided to understand the intent of the problem and generate results through a reasoning process. This often results in more accurate outputs.
The application of zero-shot and few-shot prompting depends on the specific requirements of the task, including aspects such as task specificity, data requirements, accuracy, and scalability. Task Specificity: Zero-shot prompting is suitable for general tasks that do not require domain-specific knowledge, whereas few-shot prompting is appropriate for domain-specific tasks. Few-shot prompting can generate domain-specific knowledge as in finance, law, and medicine even in the absence of large datasets. Data Needs: Zero-shot prompting does not require additional examples when constructing prompts; it relies on the model’s pre-training process. In contrast, few-shot prompting involves providing a small number of example inputs to guide the model toward generating content that meets the expected goals. Accuracy: Zero-shot prompting may produce less accurate content because of the lack of specific contextual information. Few-shot prompting improves the accuracy by providing specific examples that help the model understand the contextual information, thereby generating more accurate answers. Scalability: Zero-shot prompting depends on the model’s pre-training process and does not require task-specific fine-tuning. In contrast, few-shot prompting involves further pre-training and fine-tuning of the LLM using domain-specific data. The examples provided might cause semantic drift, potentially reducing the accuracy and relevance of the generated results. The prompt content used in this study is listed in Table 1.
Supervised fine-tuning
Supervised fine-tuning of LLMs refers to the process of further pre-training and fine-tuning a pretrained language model using specific datasets from particular domains to adapt the model for specific tasks or fields. A pretrained model serves as a base model suitable for general tasks, including question answering, text generation, and code writing. In general, LLMs may not efficiently or accurately extract entities from cross-linguistic texts. Therefore, it is necessary to fine-tune a suitable base model with cross-linguistic text datasets to meet the demands of specific tasks. Chang46 developed a platform based on human preference evaluations for LLMs. Mangrulkar47 proposed a method to avoid the comprehensive fine-tuning of downstream tasks by fine-tuning only a portion of the model’s parameters, achieving performance comparable to that of fully fine-tuned models while saving storage space. Hu48 created the LLM-Adapters framework to explore efficient fine-tuning methods for LLMs’ PEFT parameters to cater to different task requirements. Sun49 proposed a two-stage method for constructing prompts to address the issue of decreased generalization ability when fine-tuning LLMs for specific domains. This method involves the generation of a variety of prompts covering a wide range of tasks and expressions to produce high-quality data.
The supervised fine-tuning used in this study effectively enhanced the performance of LLMs. This provides a general method for improving the performance of existing language models. Compared with full-parameter fine-tuning, supervised fine-tuning requires fewer instruction data and has lower fine-tuning costs, significantly boosting the model’s performance in specific domains. Supervised fine-tuning helps language models follow natural language instructions to perform specific tasks or generate specific content, resulting in a model with a certain degree of generalization.
Model Introductions
The Baichuan2-7B-Base language model50 is the second-generation base model of the Baichuan series, open-sourced by Baichuan Company. It is trained on 2.6 trillion tokens of high-quality, multilingual data, demonstrating significant improvements in mathematical abilities, coding, security, logical reasoning, and semantic understanding. The model has been tested on authoritative datasets across six domains: general, legal, medical, mathematical, coding, and multilingual translation. Testing utilized 5-shot evaluations on general domain datasets, including the C-Eval Chinese base model assessment dataset, MMLU with 57 tasks, CMMLU with 67 topics, Gaokao using Chinese college entrance exam questions, AGIEval for single-choice questions, and BBH evaluation datasets. In the legal and medical fields, the JEC-QA dataset from China’s judicial exams was used. For mathematics and coding, the OpenCompass evaluation framework was applied with 4-shot tests on the GSM8K and MATH datasets. The Flores-101 dataset, which covers news, travel guides, and books in 101 languages, was used for multilingual translation. The model achieved the highest results for multiple authoritative Chinese and English datasets with the same number of parameters.
The ChatGLM3-6B language model51 was developed by a team from Tsinghua University, and supports question-answering dialogs in both Chinese and English. Utilizing the General Language Model (GLM) architecture, it was trained on Chinese and English datasets and incorporated techniques such as supervised fine-tuning, reinforcement learning based on human feedback, and self-feedback to enhance the model’s question-answering and conversational abilities. The model also employs techniques like rotary positional encoding and autoregressive blank-filling tasks to improve language comprehension. The base model, ChatGLM3-6B-Base, was evaluated on various datasets across semantics, coding, reasoning, and mathematics, achieving first place among 44 publicly available Chinese and English datasets. Additionally, the ChatGLM3-6B model uses a new prompt format that supports multi-turn dialog, tool invocation, code execution, and complex agent tasks.
The Xunzi-Baichuan and Xunzi-GLM language models were developed by Professor Wang Dongbo’s team at the School of Information Management, Nanjing Agricultural University, specifically for the domain of ancient text processing. The Xunzi-Baichuan model is a continuation of pre-training and fine-tuning based on the Baichuan2-7B-Base model, designed for intelligent information processing of ancient texts. The Xunzi-GLM model was developed from the ChatGLM3-6B base model through further pre-training and fine-tuning. These ancient text-processing models have demonstrated strong performance in intelligent indexing, information extraction, poetry generation, translation, reading comprehension, lexical analysis, and automatic punctuation.
Experiment conclusion analysis
This study explores the applicability of LLMs in natural language processing downstream tasks by extracting named entities from ancient cross-linguistic texts using both open-source LLMs and those pre-trained and fine-tuned by our research team.
Experiment data
Among the vast array of Chinese ancient historical documents, the Twenty-Four Histories comprise 24 official historical texts written during various Chinese dynasties. Spanning the period from around 2550 BCE to the 17th year of the Chongzhen era (1644 CE) of the Ming Dynasty, these texts total 3249 volumes and approximately 40 million characters. The collection includes the following: Records of the Grand Historian (Shiji), Book of Han (Hanshu), Book of the Later Han (Houhanshu), Records of the Three Kingdoms (Sanguozhi), Book of Jin (Jinshu), Book of Song (Songshu), Book of the Southern Qi (Nanqishu), Book of Liang (Liangshu), Book of Chen (Chenshu), Book of Wei (Weishu), Book of the Northern Qi (Beiqishu), Book of Zhou (Zhoushu), Book of Sui (Suishu), Book of Southern History (Nanshi), Book of Northern History (Beishi), Old Book of Tang (Jiutangshu), New Book of Tang (Xintangshu), Old History of the Five Dynasties (Jiu Wudai Shi), New History of the Five Dynasties (Xin Wudai Shi), History of Song (Songshi), History of Liao (Liaoshi), History of Jin (Jinshi), History of Yuan (Yuanshi), and History of Ming (Mingshi). This study utilizes proofread training data from the Twenty-Four Histories, consisting of 62,006 classical Chinese texts and 29,669 modern Chinese texts. Both datasets were divided into training and testing sets at a ratio of 9:1. The basic statistical information of this dataset is in Table 2.
Data format
The corpus used in this study was formatted into three components: instruction, input, and output., representing the prompt instruction, input content, and output result, respectively. When constructing the dataset, the instruction prompt and input content are typically concatenated and the output result is predicted. The instructions used in this study are described in the Basic Prompting section, and Table 3 illustrates the data format for zero-shot prompting.
Experimental environment and parameters
The hardware environment configurations used in the experiments are listed in Table 4. The experiments were conducted on a Linux platform using the PyTorch framework for fine-tuning and testing open-source LLMs.
Fine-tuning open-source LLMs not only enhances the models’ understanding and adherence to instructions but also improves their knowledge and capabilities in cross-linguistic ancient texts by incorporating domain-specific knowledge. The fine-tuning was performed using Low-Rank Adaptation (LoRA), which significantly reduces the number of parameters that need to be fine-tuned. The fine-tuning phase was designated Supervised Fine-Tuning (SFT), and DeepSpeed was used for distributed training. Proper parameter settings enabled efficient fine-tuning of LLMs in a multi-GPU environment. Specific parameters included maximum input sequence length, learning rate, rank of LoRA low-rank matrices, overfitting prevention measures, and model layers to apply LoRA. Some model parameters are listed in Table 5.
Evaluation metrics
BLEU52 is a metric used to assess the machine translation quality. It evaluates translation quality by calculating the number of N-grams in the translated text that match those in the reference translations. The BLEU-4 score used in this study is a specific form of BLEU that considers the 1-gram, 2-gram, 3-gram, and 4-gram matches. The process involves calculating the matching degree of the N-grams, applying a weighted geometric mean, and using a penalty factor for brevity (Brevity Penalty, BP). The formula is as follows:
In BLEU scoring, BP is the bre vity penalty factor that reduces the BLEU score when the generated text is shorter than the reference text. ({p}_{n}) represents the precision of N-gram matches, ({w}_{n}) is the weight of the N-gram, r is the length of the reference text, and c is the length of the generated text.
ROUGE53 is a widely used metric in natural language processing tasks to evaluate the quality of the generated text by comparing its similarity to the reference text. ROUGE has several variants, of which ROUGE-1, ROUGE-2, and ROUGE-L are the most commonly used. ROUGE-1 focuses on word-level recall. It evaluates similarity based on unigram overlap by calculating the number of overlapping words between the automatically generated text and the reference text. The formula is as follows:
In ROUGE-1, the numerator is the number of unigrams shared between the generated text and the reference text, while the denominator is the total number of unigrams in the reference text.
ROUGE-2 evaluates similarity based on bigram overlap, focusing on the overlap of consecutive word pairs and considering word order matching. It is used to assess the accuracy of generated text at the phrase level. The formula is as follows:
In ROUGE-2, the numerator is the number of bigrams shared between the generated text and the reference text, and the denominator is the total number of bigrams in the reference text.
ROUGE-L measures similarity based on the longest common subsequence (LCS) between the generated text and the reference text, with the evaluation metric calculated according to the length of this sequence. The formula is as follows:
In ROUGE-L, LCS represents the longest common subsequence between the reference text and the generated text.
To assess the performance of fine-tuning LLMs in this study, three metrics were used: Precision54, Recall, and the F1 score55. Precision measures the number of identified entities that are correct, ignoring the entities that the model fails to predict. Recall measures the number of actual entities that are correctly identified, ignoring errors in identification. The F1 score balances Precision and Recall, providing a more comprehensive view of model performance.
In these metrics: True Positives (TPs) are the number of entities correctly predicted by the model as belonging to a known type. False Positives (FPs) are the number of entities incorrectly predicted as belonging to a known type or as entities when they are not. False Negatives (FN) are the number of entities that belong to a known type but are incorrectly predicted as not belonging to that type.
Analysis of BLEU and ROUGE results
To evaluate the performance of fine-tuned LLMs in NER tasks, four metrics—BLEU-4, ROUGE-1, ROUGE-2, and ROUGE-L—were used to assess the ChatGLM3-6B, Baichuan2-7B-Base, Xunzi-Baichuan, and Xunzi-GLM language models. The results are summarized in Table 6.
From the analysis of the experimental results, it is evident that in zero-shot prompting fine-tuning, the Xunzi-Baichuan model achieved the highest BLEU-4 score of 93.34, surpassing the ChatGLM3-6B model by 1.8 points. Furthermore, Xunzi-Baichuan had the highest scores across all ROUGE metrics (ROUGE-1, ROUGE-2, and ROUGE-L) among the four models. The fine-tuned Xunzi-GLM model had a BLEU-4 score 0.38 lower than that of the Baichuan2-7B-Base model, indicating that the number of parameters in LLMs does impact performance. In one-shot prompting fine-tuning, the Xunzi-Baichuan model again showed the best performance across all four evaluation metrics. However, the difference between the Xunzi-GLM and Baichuan2-7B-Base models was relatively small, with the BLEU-4, ROUGE-1, ROUGE-2, and ROUGE-L scores differing by 0.36, 0.09, 0.3, and 0.21, respectively. Overall, Xunzi-GLM outperformed the Baichuan2-7B-Base model. In few-shot prompting fine-tuning, the Xunzi-Baichuan model remained the top performer across all four metrics, followed by the Xunzi-GLM, Baichuan2-7B-Base, and ChatGLM3-6B models, in that order. These results suggest that the LLMs used in this study demonstrated excellent performance in text generation and evaluation. The BLEU-4 scores ranged from a high of 93.34 to a low of 91.54, indicating the models’ effectiveness in generating text with similar structures. The ROUGE-1, ROUGE-2, and ROUGE-L results further confirmed the high accuracy of the models in terms of text semantics and grammatical structures. Overall, the models exhibited robust performance and a degree of generalization capability. Figure 2 illustrates the differences in results between the models.
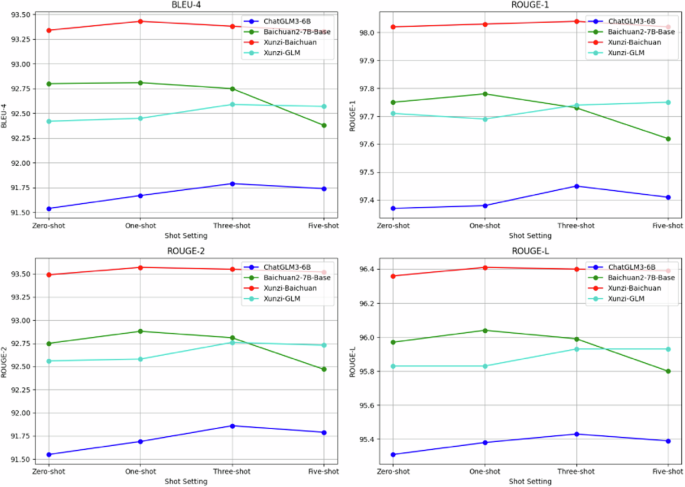
Comparison results of BLEU-4, ROUGE-1, ROUGE-2, and ROUGE-L metrics.
Analysis of experimental results
To evaluate the applicability of LLMs in NER tasks, experiments were conducted using the ChatGLM3-6B, Baichuan2-7B-Base, Xunzi-Baichuan, and Xunzi-GLM models on the constructed datasets. Tables 7, 8, 9, and 10 display the experimental results. The accuracy, recall, and F1 scores of these models were analyzed.
In zero-shot prompting, the Xunzi-Baichuan model achieved the highest F1 scores for NER in both Classical and Modern Chinese. It had the highest accuracy of 82.32, surpassing the ChatGLM3-6B model by 3.61 points. The recall was also highest for Xunzi-Baichuan, at 81.41, exceeding the ChatGLM3-6B model by 3.89 points. The highest F1 score was 81.87, again for Xunzi-Baichuan, which was 3.76 points higher than that of the ChatGLM3-6B model. The results indicate that among all types of named entities, the best-performing models are Xunzi-Baichuan, followed by Baichuan2-7B-Base, Xunzi-GLM, and ChatGLM3-6B. Specifically, Xunzi-Baichuan performed best in extracting the Person names (PER), Book titles (BOOK), and Official titles (OFI) entity types. For book title recognition in Modern Chinese, the ChatGLM3-6B model had a higher accuracy, 54.39, than Xunzi-GLM’s 52.92. However, their F1 scores differed by only 0.02, likely due to variability in text generation. In Ancient Chinese BOOK entity recognition, Xunzi-Baichuan outperformed ChatGLM3-6B by 0.49 in accuracy and 0.65 in F1 score, possibly due to the smaller number of such entities in the training data affecting performance.
In one-shot prompting, the Xunzi-Baichuan model again showed the highest accuracy across cross-linguistic datasets, with a score that was 3.38 points higher than the lowest-performing ChatGLM3-6B model (79.28). For recall, Xunzi-Baichuan achieved the highest score of 81.73, exceeding ChatGLM3-6B by 3.84 points. The highest F1 score was 82.19, outperforming ChatGLM3-6B by 3.61 points. However, the un-fine-tuned Baichuan2-7B-Base model showed better performance in accuracy, recall, and F1 score across all entity types than did the fine-tuned models. In Modern Chinese entity recognition, Xunzi-GLM’s F1 score was 1.94 points lower than that of Baichuan2-7B-Base, possibly because Xunzi-GLM is fine-tuned from ChatGLM3-6B, whereas Baichuan2-7B-Base has a larger parameter size. Xunzi-Baichuan’s recall for the BOOK entity type in Modern Chinese was 1.15 points lower than that of ChatGLM3-6B, but its F1 score was higher by 1.89 points. Overall, the fine-tuned models generally performed better in one-shot prompting.
In few-shot prompting, specifically in the three-shot experiments, Baichuan2-7B-Base significantly outperformed ChatGLM3-6B across all entity types, with accuracy, recall, and F1 scores differing by 2.22, 2.46, and 2.34 points, respectively. This suggests that in NER tasks, a model with 7 B parameters outperforms one with 6 B parameters. The Xunzi-Baichuan model achieved the highest F1 scores across all entity types, with a score 3.28 points higher than the lowest-performing ChatGLM3-6B. In Ancient Chinese entity recognition, Xunzi-Baichuan’s F1 score was 82.50, 3.73 points higher than ChatGLM3-6B. For Modern Chinese entity types, Xunzi-Baichuan had an F1 score 2.64 points higher than Xunzi-GLM. In experiments focusing on single-entity types, fine-tuned models generally performed better than non-fine-tuned models. However, fine-tuned models did not always outperform non-fine-tuned ones in Modern Chinese. For instance, Xunzi-GLM’s recognition of PER entities was 1.87 points lower than that of Baichuan2-7B-Base, and the F1 score difference between Baichuan2-7B-Base and ChatGLM3-6B was only 0.25 points. Five-shot experiments revealed that Baichuan2-7B-Base outperformed Xunzi-GLM with a 0.27 higher F1 score. For PER entities in Ancient Chinese, Baichuan2-7B-Base also outperformed Xunzi-GLM, with a 0.02 higher F1 score. This indicates that the parameter size of LLMs affects their performance to some extent. For Modern Chinese entity recognition, Xunzi-GLM’s results were close to those of ChatGLM3-6B, but the fine-tuned models tailored to specific domains generally outperformed the general models. Figure 3 presents a more intuitive comparison of the model results.
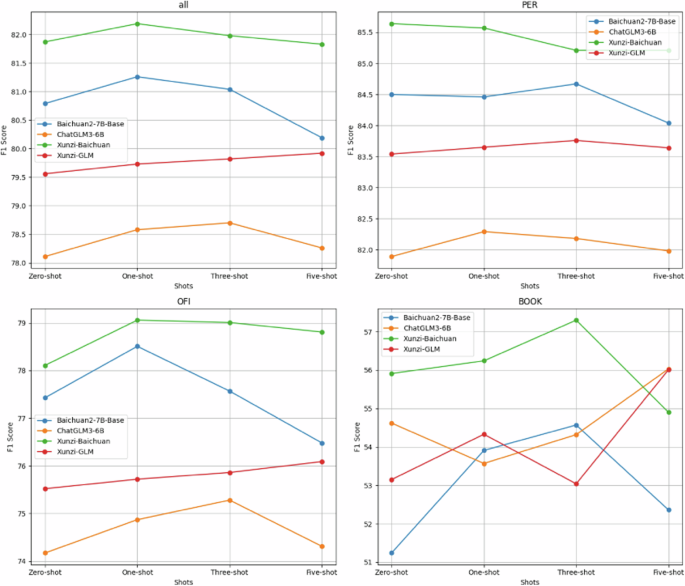
F1 score comparison results of ChatGLM3-6B, Baichuan2-7B-Base, Xunzi-Baichuan, and Xunzi-GLM Models.
During the testing of the fine-tuned LLMs, it was observed that the models exhibited a certain level of generalization capability. In the instruction prompts and input text, the focus was solely on extracting three entity types: PER, BOOK, and OFI. However, during the evaluation, the LLMs demonstrated generalization abilities, as shown in Table 11. Although the test corpus did not include location entity types or corresponding entity labels, the generated results included the “LOC” entity label and the location entity “Shile River.”
Conclusion and future work
With the development and application of technologies, such as artificial intelligence and big data, LLMs can be leveraged to extract entities with specific significance from classical texts, such as person names, place names, official titles, and book titles. By exploring and validating the performance of LLMs in the subtask of NER within natural language processing, new research ideas and methods for the intelligent processing of classical texts have emerged. This study used supervised fine-tuning methods to adjust and test four LLMs—Xunzi-Baichuan, Baichuan2-7B-Base, Xunzi-GLM, and ChatGLM3-6B—to verify the feasibility of LLMs in NER research. Implementing named entity extraction in classical texts with LLMs not only preserves the integrity and logical structure of the content but also advances digitalization and knowledge-based approaches for classical texts. LLMs show immense potential in the intelligent processing of classical information, and ongoing research and technological updates can achieve a more accurate and in-depth cross-linguistic understanding and application of classical texts. Future research could focus on enhancing the model’s cross-linguistic generalization ability, improving the understanding of the cultural context of classical texts, and increasing model interpretability.


Responses