Experimental demonstration of magnetic tunnel junction-based computational random-access memory

Introduction
Recent advances in machine intelligence1,2 for tasks such as recommender systems3, speech recognition4, natural language processing5, and computer vision6, have been placing growing demands on our computing systems, especially for implementations with artificial neural networks. A variety of platforms are used, from general-purpose CPUs and GPUs7,8, to FPGAs9, to custom-designed accelerators and processors10,11,12,13, to mixed- or fully- analog circuits14,15,16,17,18,19,20. Most are based on the Von Neumann architecture, with separate logic and memory systems. As shown in Fig. 1a, the inherent segregation of logic and memory requires large amounts of data to be transferred between these modules. In data-intensive scenarios, this transfer becomes a major bottleneck in terms of performance, energy consumption, and cost21,22,23. For example, the data movement consumes about 200 times the energy used for computation when reading three 64-bit source operands from and writing one 64-bit destination operand to an off-chip main memory21. This bottleneck has long been studied. Research aiming at connecting logic and memory more closely has led to new computation paradigms.

a, b Compared to a conventional computer architecture (a), which suffers from the memory-logic transfer bottleneck, CRAM (b) offers significant power and performance improvements. Its unique architecture allows for computation in memory, as well as, random access, reconfigurability, and parallel operation capability. c The CRAM could excel in data-intensive, memory-centric, or power-sensitive applications, such as neural networks, image processing, or edge computing (c).
Promising paradigms include “near-memory” and “in-memory” computing. Near-memory processing brings logic physically closer to memory by employing 3D-stacked architectures24,25,26,27,28,29. In-memory computing scatters clusters of logic throughout or around the memory banks on a single chip14,15,16,17,18,19,20,30,31,32,33,34,35. Yet another approach is to build systems where the memory itself can perform computation. This has been dubbed “true” in-memory computing36,37,38,39,40,41,42. The computational random-access memory (CRAM)38,40 is one of the true in-memory computing paradigms. Logic is performed natively by the memory cells; the data for logic operations never has to leave the memory (Fig. 1b). Additionally, CRAM operates in a fully digital fashion, unlike most other reported in-memory computing schemes14,15,16,17,18,19,20, which are partially or mostly analog. CRAM promises superior energy efficiency and processing performance for machine intelligence applications. It has unique additional features, such as random-access of data and operands, massive parallel computing capabilities, and reconfigurability of operations38,40. Also note that although the transistor-less (crossbar) architecture employed by most of the previous true-in-memory computing paradigms36,37,39,42 allows for higher density, the maximum allowable size of the memory array is often severely limited due to the sneak path issues. CRAM includes transistors in each of its cells for better-controlled electrical accessibility and, therefore, a larger array size.
The CRAM was initially proposed based on the MTJ device38, an emerging memory device that relies on spin electronics43. Such “spintronic” devices, along with other non-volatile emerging memory devices, usually referred to as “X” for logic applications, have been intensively investigated over the past several decades for emerging memory and computing applications as “beyond-CMOS” and/or “CMOS + X” technologies. They offer vastly improved speed, energy efficiency, area, and cost. An additional feature that is exploited by CRAM is their non-volatility44. The MTJ device is the most mature of spintronic devices for embedded memory applications, based on endurance45, energy efficiency46, and speed47. We note that CRAM can be implemented based not only on spintronics devices but also on other non-volatile emerging memory devices.
In its simplest form, an MTJ consists of a thin tunneling barrier layer sandwiched between two ferromagnetic (FM) layers. When a voltage is applied between the two layers, electrons tunnel through the barrier, resulting in a charge current. The resistance of the MTJ is a function of the magnetic state of the two FM layers, due to the tunneling magnetoresistance (TMR) effect48,49,50. An MTJ can be engineered to be magnetically bi-stable. Accordingly, it can store information based on its magnetic state. This information can be retrieved by reading the resistance of the device. The MTJ can be electrically switched from one state to the other with a current due to the spin-transfer torque (STT) effect51,52. In this way, an MTJ can be used as an electrically operated memory device with both read and write functionality. A type of random-access memory, the STT-MRAM 53,54,55,56 has been developed commercially, utilizing MTJs as memory cells. A typical STT-MRAM consists of an array of bit cells, each containing one transistor and one MTJ. These are referred to as 1 transistor 1 MTJ (1T1M) cells.
A typical CRAM cell design, as shown in Fig. 2a, is a modification of the 1T1M STT-MRAM architecture57. The MTJ, one of the transistors, word line (WL), bit select line (BSL), and memory bit line (MBL) resemble the 1T1M cell architecture of STT-MRAM, which allows the CRAM to perform memory operations. In order to enable logic operations, a second transistor, as well as a logic line (LL) and a logic bit line (LBL), are added to each memory cell. During a logic operation, corresponding transistors and lines are manipulated so that several MTJs in a row are temporarily connected to a shared LL40. While the LL is left floating, voltage pulses are applied to the lines connecting to input MTJs, with that of the output MTJ being grounded. The logic operation is based on a working principle called voltage-controlled logic (VCL)58,59, which utilizes the thresholding effect that occurs when switching an MTJ and the TMR effect of MTJ. As shown in Fig. 2b, when a voltage is applied across the input MTJs, the different resistance values result in different current levels. The current flows through the output MTJ, which may or may not switch its state, depending on the states of the input MTJs. In this way, basic bitwise logic operations, such as AND, OR, NAND, NOR, and MAJ, can be realized. A unique feature of VCL is that the logic operation itself does not require the data in the input MTJs to be read-out through sense amplifiers at the edge of the array. Rather, it is used locally within the set of MTJs involved in the computation. This is fundamentally why the CRAM computation represents true-in-memory computing: the computation does not require data to travel out of the memory array. It is always processed locally by nearby cells. We note that this concept would also work with other two-terminal stateful passive memory devices, such as memristors. Accordingly, a CRAM could be implemented with such devices. A CRAM could also be implemented with three-terminal stateful devices, such as spin-orbit torque (SOT) devices. This could result in greater energy efficiency and reliability60. Although devices with progressive or accumulative switching behavior, such as spintronic domain wall devices61,62, can be adopted as well, CRAM would otherwise work best if adopting bi-stable memory devices with strong threshold switching behavior. As an oversimplified speculation, the performance comparison between CRAMs implemented by various emerging memory devices is expected to roughly follow the comparison between these for memory applications, since CRAM utilizes memory devices in similar manners as in-memory applications. For example, a CRAM implemented based on MTJs should be expected to offer high endurance and high speed. Also, generally, a CRAM logic operation should consume energy comparable to the energy consumption of a memory write operation, for the same emerging memory device operating at the same speed. However, a careful case-by-case analysis is necessary for CRAMs implemented by each emerging memory device technology. Also, note that we do not show a specific circuit design of CRAM peripherals because CRAM does not require significant circuit design change in sense amplifiers or peripherals compared to 1T1M STT-MRAM. And these in the STT-MRAM are already common and mature. Lastly, the true in-memory computing characteristic of CRAM is limited to within a continuous CRAM array: any computation that requires access to data across separate CRAM arrays will require additional data access and movement. The size of an array is ultimately limited by parasitic effects of interconnects63. However, these limitations are true for all other in-memory computing paradigms. CRAM is not at any disadvantage in this scenario.
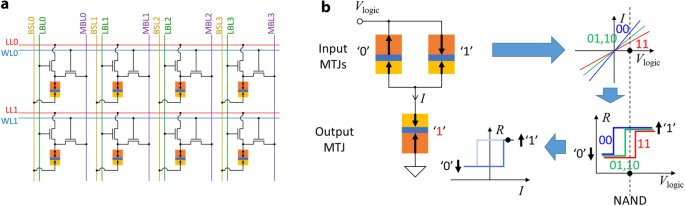
a CRAM adopts the so-called 2 transistor 1 MTJ (2T1M) cell architecture. On top of the 1T1M cell architecture of STT-MRAM, an additional transistor, as well as the added logic line (LL) and logic bit line (LBL), allow the CRAM to perform logic operations. During a CRAM logic operation, the transistors and lines are manipulated to form an equivalent circuit, as shown in b. Although CRAM can be built based on various emerging memory devices, we use MTJs and MTJ-based CRAM as an example for illustration purposes. b The working principle of CRAM logic operation, the VCL, utilizes the thresholding effect that occurs when switching an MTJ and the TMR effect of the MTJ. With an appropriate Vlogic amplitude, the voltage is translated into different currents flowing through the output MTJ by the TMR effect of the input MTJs. Whether the output MTJ switches or not is dependent on the state of the input MTJs.
On top of the potential performance benefits that the emerging memory devices bring, at circuit and architecture level, CRAM fundamentally provides several benefits (Fig. 1b): (1) the elimination of the costly performance and energy penalties associated with transferring data between logic and memory; (2) random access of data for the inputs and outputs to operations; (3) the reconfigurability of operations, as any of the logic operations, AND, OR, NAND, NOR, and MAJ can be programmed; and (4) the performance gain of massive parallelism, as identical operations can be performed in parallel in each row of the CRAM array when data is allocated properly. Based on analysis and benchmarking, CRAM has the potential to deliver significant gains in performance and power efficiency, particularly for data-intensive, memory-centric, or power-sensitive applications, such as bioinformatics40,64,65, image66 and signal67 processing, neural networks66,68, and edge computing69 (Fig. 1c). For example, a CRAM-based machine-learning inference accelerator was estimated to achieve an improvement on the order of 1000× over a state-of-art solution, in terms of the energy-delay product70. Another example shows that CRAM (at the 10 nm technology node) consumes 0.47 µJ and 434 ns of energy and time, respectively, to perform an MNIST handwritten digit classifier task. It is 2500× and 1700× less in energy and time, respectively, compared to a near-memory processing system at the 16 nm technology node66. And yet, to date, there have been no experimental studies of CRAM.
In this work, we present the first experimental demonstration of a CRAM array. Although based on a small 1 × 7 array, it successfully shows complete CRAM array operations. We illustrate computation with a 1-bit full adder. This work provides a proof-of-concept as well as a platform with which to study key aspects of the technology experimentally. We provide detailed projections and guidelines for future CRAM design and development. Specifically, based on the experimental results, models and calculations of CRAM logic operations are developed and verified. The results connect the CRAM gate-level accuracy or error rate to MTJ TMR ratio, logic operation pulse width, and other parameters. Then we evaluate the accuracy of a multi-bit adder, a multiplier, and a matrix multiplication unit, which are essential building blocks for many conventional and machine intelligence applications, including artificial neural networks.
Experiments
Figure 3 shows the experimental setup, consisting of both hardware and software. The hardware is built with a so-called ‘circuit-around-die’ approach71: semiconductor circuitry is built with commercially available components around the MTJ dies. This approach offers a more rapid development cycle and flexibility needed for exploratory experimental studies on CRAM arrays and potential new MTJ technologies, while the major foundries lack the specific process design kit available for making a CRAM array fully integrated with CMOS. The hardware is a 1 × 7 CRAM array, with the design of cells taken from the 2T1M CRAM cells38,40, modified for simplified memory access. Software on a PC controls the operation. It communicates with the hardware with basic commands: ‘open/close transistors’; ‘apply voltage pulses’ to perform write and logic operations; and ‘read cell resistance’. The software collects real-time measurements of the data associated with CRAM operations for analysis and visualization. All aspects of the 1 × 7 CRAM array are functional: memory write, memory read, and logic operations (more details in Methods section, and Supplementary Note S1).
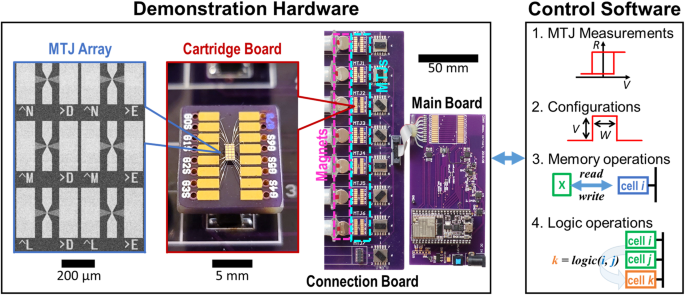
The setup consists of custom-built hardware and a suite of control software. It demonstrates a fully functioning 1 × 7 CRAM array. The hardware consists of a main board hosting all necessary electronics except for the MTJ devices; a connection board on which passive switches, connectors, and magnetic bias field mechanisms are hosted; and multiple cartridge boards that each have an MTJ array mounted and multiple MTJ devices that are wire bonded. The gray-scale scanning electron microscopy image shows the MTJ array used. The color optical photographs show the cartridge board and the entire hardware setup. The software is responsible for real-time measurements of the MTJs; configuration and execution of CRAM operations: memory write, memory read, and logic; and data collection. It is run on a PC, which communicates wirelessly with the main board.
MTJs with perpendicular interfacial anisotropy are used in the CRAM. They exhibit low resistance-area (RA) product and high TMR ratio—approximately 100%—when sized at 100 nm in diameter (more details in Supplementary Note S2).
Results
Device properties and CRAM memory operations
The experiments begin with measuring the resistance (R)–voltage (V) properties of each MTJ device and of each die. In order to compensate for device-to-device variations, the bias magnetic fields for each MTJ are adjusted so that the R–V properties are as close to each other as possible (more details in Supplementary Note S2). As the processes of making CRAM arrays mature, bias magnetic fields are expected to be no longer needed and all CRAM cells will be able to be operated with uniform parameters and under uniform conditions. The resistance threshold for the MTJs logic states is also determined in this stage.
Then the seven MTJ cells are tested for memory operations with various write pulse amplitudes and widths. Based on the observed write error rates for memory write operations, appropriate pulse amplitudes and widths are configured, achieving reliable memory write operations with an average write error rate of less than 1.5 × 10−4 (more details in Supplementary Note S3). We designate logic ‘0’ and ‘1’ to the parallel (P) low resistance state and anti-parallel (AP) high resistance state of MTJ, respectively.
CRAM logic operations
Two-input logic operations are studied. The output cell is first initialized by writing ‘0’ to it. Then two input cells are connected to the output cell through the LL by turning on the corresponding transistors. Voltage pulses of amplitude of Vlogic, Vlogic, and 0, are simultaneously applied to the two input cells and the output cell, respectively. This is the same as grounding the output cell while applying a voltage pulse of Vlogic to the two input cells. Then, depending on the input cells’ states, the output cell will have a certain probability of being switched from ‘0’ to ‘1’. Such a cycle of operations is repeated n times, and the statistical mean of the output logic state, <Dout>, is obtained. The entire process is repeated for different Vlogic values and input states. The basis for logic operations in the CRAM is the state-dependent resistance of the input cells. These shift and displace the output cell’s switching probability transfer curve. As a result, the output cell switches state based on specific input states, thereby implementing a logic function such as AND, OR, NAND, NOR, or MAJ. A specific initial state of the output cell and Vlogic value corresponds to one of these logic gates66. The time duration or pulse width of the voltage pulse applied during a logic operation is expected to contribute to most of the time required to complete a logic operation. In the following, we use the term logic speed to generally refer to the speed of a logic operation. Logic speed is approximately inversely proportional to the time duration of the voltage pulse used during a logic operation.
The experimental results are shown in Fig. 4a, b. Generally, for a given input state, <Dout> increases with increasing Vlogic. The <Dout> response curves are input state-dependent. The four input states can be divided into three groups:
-
The ‘00’ input state yields the lowest resistance at the two input cells, so the output cell switches from ‘0’ to ‘1’ first (with the lowest Vlogic).
-
The ‘11’ input state yields the highest resistance at the two input cells, so the output cell switches from ‘0’ to ‘1’ last (with the highest Vlogic).
-
The ‘01’ and ‘10’ input states both yield resistance that falls in between that of ‘00’ and ‘11’so that the output cell’s response curve falls in between that of ‘00’ and ‘11’.
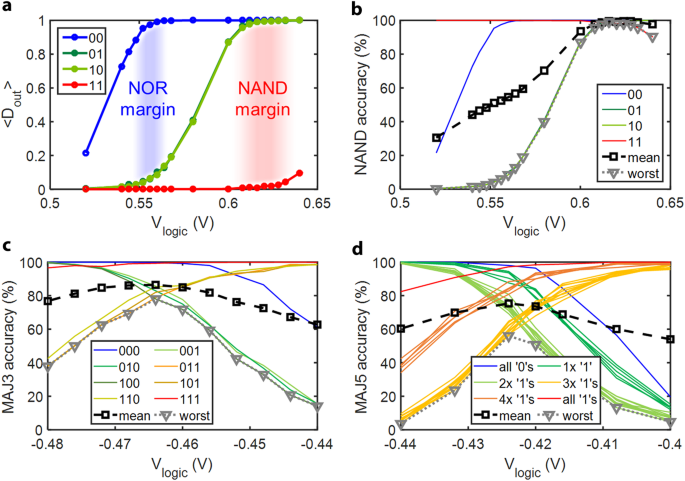
a Output logic average, Dout, vs. logic voltage, Vlogic. In a 2-input logic operation, two input cells and one output MTJ cell are involved. The output cell’s terminal is grounded, while the common line is left floating. A logic operation voltage pulse is applied to the two input cells’ terminals for a fixed duration (pulse width) of 1 ms. Before each logic operation, input data is written to the input cells. After each logic operation, the output cell’s state is read. Each curve corresponds to a specific input state. Each data point represents the statistical average of the output cell’s logic state, <Dout>, sampled by 1000 repeats (n = 1000) of the operations. The separation between the <Dout> curves indicates the margins for NOR or NAND operation, highlighted in blue and red, respectively. b Accuracy of 2-input NAND operation vs. logic voltage, Vlogic. The results in a can be converted into a more straightforward metric, accuracy, for the NAND truth table. The curve labeled ‘mean’ and ‘worst’ indicates the average and the worst-case accuracy across all input states, respectively. So, for NAND operation, the optimal logic voltage is indicated in such a plot where the mean or worst accuracy is maximized. c, d Accuracy of MAJ3 (c) and MAJ5 (d) logic operations vs. logic voltage, Vlogic. Each curve corresponds to an input state or a group of input states. And each data point represents the statistical average of the output MTJ logic state sampled by n = 1000 and n = 250, for c and d, respectively.
Figure 4a shows the experiment results. The two regions highlighted in blue and red that fall in between the three groups of response curves are suitable for NOR and NAND operations, respectively. For example, in the red region, the ‘11’ input has a high probability of yielding a ‘0’ output, while the other three input states have a high probability of yielding a ‘1’ output. This matches the expected truth table for a NAND logic gate. Therefore, if Vlogic is chosen carefully—within the red region for the CRAM 2-input logic operation—the operation performed is highly likely to be NAND.
The experimental results of <Dout> can be converted into a straightforward format representing the accuracy for a specified logic function. This translation can be computed by simply subtracting <Dout> from 1 for those input states where a ‘0’ output is expected in the truth table of the logic function. Figure 4b shows the NAND accuracy of the same 2-input CRAM logic operation. The ‘mean’ and ‘worst’ plots are based on the average value and minimum value of the accuracy, respectively, across all input state combinations at a fixed value for Vlogic. Based on the experimental results, if Vlogic = 0.624 or 0.616 V, the CRAM delivers a NAND operation with a best mean and a worst-case accuracy of about 99.4% and 99.0%, respectively. From a circuit perspective, both increasing the effective TMR ratio of input cells and/or making the output cell’s response curve steeper would increase the vertical separation of these input state-dependent curves, resulting in higher accuracy. For example, a higher effective TMR ratio of input cells results in a larger contrast of current in the output cell between different input states. Therefore, there is more ‘horizontal’ room to separate the <Dout> curves associated with different input states so that for the inputs with which the output is expected to be ‘0’ or ‘1’, the <Dout> of the output cell is closer to the expected value (‘0’ or ‘1’). Also note that for a logic operation, the ‘accuracy’ and ‘error rate’ are essentially two quantities describing the same thing: how true the logic operation is, statistically. By definition, the sum of accuracy and error rate is always 1. The higher or closer to 1 the accuracy is, the better. The lower or closer to 0 the error rate is, the better. Lastly, to facilitate better visualization of how the resistance changes of different input cell states are translated into voltage differences on the output cell resulting in it being switched or unswitched, we list the equivalent resistance of the two input cells combined in parallel and the resulting voltage on the output cell as follows: With Vlogic = 0.620 V, the equivalent resistance of input cells and the resulting voltage on the output cell are 0.4133 V and 1120 Ω, 0.3753 V, and 1461 Ω, and 0.3248 V and 2037 Ω, for input states ‘00’, ‘01’ or ‘10’, and ‘11’, respectively. Note that these values are estimated by the experiment-based modeling, which is introduced in the later part of this paper.
With more input cells, we also studied 3-input and 5-input majority logic operations. Figure 4c shows the accuracy of a 3-input MAJ3 logic operation. At Vlogic = −0.464 V, both the optimal mean and the worst-case accuracy are observed to be 86.5% and 78.0%, respectively. Similarly, for a 5-input MAJ5 logic operation, shown in Fig. 4d, both the optimal mean and the worst-case accuracy are observed to be 75% and 56%, respectively. As expected, comparing 2-input, 3-input, and 5-input logic operations, the accuracy decreases with an increasing number of inputs (more discussions and explanations in Supplementary Note S4).
CRAM full adder
Having demonstrated fundamental elements of CRAM—memory write operations, memory read operations, and logic operations—we turn to more complex operations. We demonstrate a 1-bit full adder. This device takes two 1-bit operands, A and B, as well as a 1-bit carry-in, C, as inputs, and outputs a 1-bit sum, S, and a 1-bit carry-out, Cout. A variety of implementations exist. We investigate two common designs: (1) one that uses a combination of majority and inversion logic gates, which we will refer to as a ‘MAJ + NOT’ design; and (2) one that uses only NAND gates, which we will refer to as an ‘all-NAND’ design. Figures 5a and 5b illustrate these designs. Supplementary Note S5 provides more details.
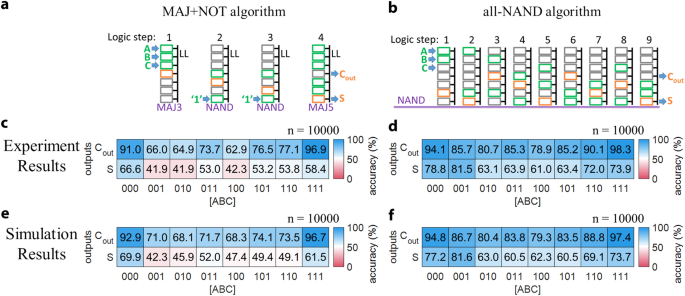
a, b Illustrations of the ‘MAJ + NOT’ and ‘all-NAND’ 1-bit full adder designs. Green and orange letter symbols indicate input and output data for the full adder, respectively. From left to right, numbered by ‘logic step,’ each drawing shows the intended input (green rectangle) and output (orange rectangle) cells involved in the logic operation. The text in purple under each drawing indicates the intended function of the logic operation (MAJ3, NAND, or MAJ5). c–f Experimental (c, d) and simulation (e, f) results of the output accuracy of 1-bit full adder operations by CRAM with the MAJ + NOT (c, e) and all-NAND (d, f) designs. The CRAM adder’s outputs, S and Cout, are assessed against the expected values, i.e., their truth table, for all input states of A, B, and C. The accuracy of each result for each input state is shown by the numerical value in black font, as well as, represented by the color of the box with red (or blue) indicating wrong (or correct), or accuracy of 0% (100%). The accuracy is calculated based on the statistical average of outputs obtained by repeating the full adder execution n times, for n = 10,000. The experimental results for the MAJ + NOT (c) and all-NAND (d) designs are obtained by repeatedly executing the operation for all input states and observing the output states. The simulation results for the MAJ + NOT (e) and all-NAND (f) designs are obtained with probabilistic modeling, using Monte Carlo methods. The accuracy of individual logic operations is set to what was observed experimentally.
Figure 5c, f shows the experimental and simulation results for the MAJ + NOT and the all-NAND designs, respectively. Each plot is a colormap that lists the accuracy of the output bits S and Cout, with each input state coded as [ABC]. The blue (red) indicates good/desired (bad/undesired) accuracy. In the boxes of colormap, results in saturated blue are the most desirable. The numerical values of accuracy are also labeled accordingly. From the experimental results for the MAJ + NOT design full adder shown in Fig. 5c, we make two observations:
-
The accuracy of Cout is generally higher than that of S. This is because Cout is directly produced by the first MAJ3 operation from inputs A, B, and C, while S is produced after additional logic operations. We also note that since Cout is produced earlier than S, it is less impacted by error propagation and accumulation during each step; and the MAJ5 involved in producing S is inherently less accurate than the MAJ3.
-
Both Cout and S have higher accuracy when the input [ABC] = 000 or 111 than in the other cases. This is expected since the input states of all ‘0’s and all ‘1’s yield higher accuracy than those with mixed numbers of ‘0’s and ‘1’s for both MAJ3 and MAJ5.
The experimental results for the all-NAND design are shown in Fig. 5d. The same observations regarding accuracy vs. inputs as the MAJ + NOT design apply. However, it is clear that the accuracy of the all-NAND full adder, at 78.5%, is higher than that of the MAJ + NOT full adder, at 63.8%. This is likely due to the fact that 2-input NAND operations are inherently more accurate than MAJ3 and MAJ5 operations. This offsets the impact of the additional steps required in the all-NAND design. We note that the accuracy of all computation blocks will improve as the underlying MTJ technology evolves. Accordingly, the relative accuracy of the all-NAND versus the MAJ + NOT designs may change66.
Modeling and analysis of CRAM logic accuracy
To understand the origin of errors, how they accumulate, and how they propagate, we performed numerical simulations of the full adder designs. These are based on probabilistic models of logic operations, implemented using Monte Carlo methods. Figure 5e, f shows the simulation results for the MAJ + NOT and all-NAND designs, respectively. In these simulations, the accuracy of individual logic operations was set to match what was experimentally observed. The simulation results for the overall designs of the full adders correspond well to what was observed experimentally for these, confirming the validity of the proposed probabilistic models (more details in the Methods section and Supplementary Note S6).
We note that beyond the inherent inaccuracy of logic operations, other factors such as device drift and device-to-device variation in MTJ devices will contribute to error in a CRAM. Specifically, drifts in temperature, external magnetic field, MTJ anisotropy, and MTJ resistance can lead to drift of the response curve, <Dout>. Most likely, any such drift will result in a reduction (increase) of accuracy (error rate). More discussion regarding device-to-device variation is provided in Supplementary Note S7.
On the other hand, the accuracy of logic operations will significantly benefit from improvements in TMR ratio as MTJ technology evolves. To project the future accuracy of CRAM operations, we employ various types of physical modeling informed by existing experimental results (more details are provided in the Methods section and Supplementary Note S8).
Three sets of assumptions on the accuracies (or error rates) of NAND logic operations underlie the following studies.
-
The ‘experimental’ assumptions are based on the best accuracy experimentally observed among the 9 NAND steps involved with the all-NAND 1-bit full adder. These are adjusted linearly to ensure that the error for inputs ‘01’ and ‘10’ equals that for input ‘11’. In reality, as supported by the experimental results shown in Fig. 4a, such a condition can be reached by properly tuning the Vlogic. Therefore, assuming the gate-level error rate is already optimized by tuning the Vlogic, then the per-input state NAND accuracies can be further simplified so that an error rate, δ (0 ≤ δ ≤ 1), can be used to characterize the error, accuracy, and probabilistic truth table of NAND operations in a CRAM. The NAND accuracy is [1, 1–δ, 1–δ, 1–δ], and the NAND probabilistic truth table is [1, 1–δ, 1–δ, δ], both being a function of δ. Through the above-mentioned modeling and calculations, the ‘experimental’ assumptions yield δ = 0.0076, which corresponds to a TMR ratio of approximately 109%, based on experiments.
-
Two additional sets of assumptions, labeled as ‘production’ and ‘improved’, assume MTJ TMR ratios of 200% and 300%, respectively. These two assumptions yield δ = 2.1 × 10−4, and δ = 7.6 × 10−6, respectively, based on modeling and calculations. The ‘production’ assumptions represent the current industry-level TMR ratios developed for STT-MRAM technologies. The ‘improved’ assumptions present reasonable expectations for near-future MTJ developments.
CRAM NAND error rates vs. TMR ratio with various logic voltage pulse widths are shown in Fig. 6a. Higher TMR ratios and faster logic speed—so shorter Vlogic pulse widths—lead to smaller error rates. Further details can be found in Supplementary Note S8 and in Supplementary Figure S5. Also included is an analysis of error rates vs. effective TMR ratio, which is independent of the specific TMR modeling. Note that, for all subsequent results, we will use the NAND error rate at the assumed TMR ratios, with pulse widths of 1 ms. This is more conservative but is consistent with the pulse widths used in the experimental results reported above.
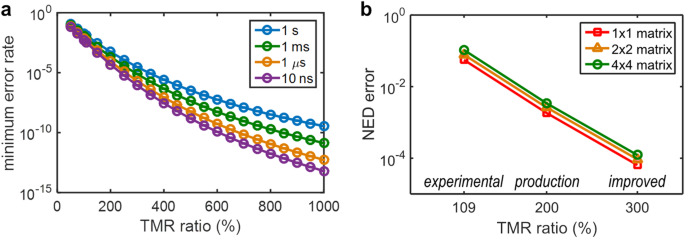
a NAND gate minimum error rate vs. MTJ TMR ratio with various Vlogic pulse widths. For a given TMR ratio, the error rate is a function of Vlogic. So, the ‘minimum error rate’ represents the minimum error rate achievable with an appropriate Vlogic value. All subsequent studies use the error rates observed with 1 ms pulse widths (to be consistent with the earlier experimental studies) at assumed TMR ratios. b The NED error of a 4-bit dot-product matrix multiplier vs. TMR ratio. TMR ratios of 109%, 200%, and 300% are adopted for the ‘experimental,’ ‘production,’ and ‘improved’ assumptions, respectively. The size of the input matrix is indicated in the legend of the plot.
Analysis of CRAM multi-bit adder, multiplier, and matrix multiplier
With these defined sets of assumptions, we provide projections of CRAM accuracy at a larger scale for meaningful applications. First, we evaluate ripple-carry adders and array multipliers72 operating on scalar operands, with up to 6 bits. To evaluate the results, we adopt the normalized error distance (NED) metric73 to represent the error of these primitives, as it has been shown to be more suitable for arithmetic primitives in the presence of computational error. We will refer to the error for a given primitive as ‘NED error’. We also define a complementary metric of ‘NED accuracy’ as the NED subtracted from 1 and then multiplied by 100%, to facilitate a more intuitive visualization of the error values. While the ‘experimental’ assumptions with a TMR ratio of 109% yield good overall accuracy for adders and multipliers, as the TMR ratio increases, the ‘production’ assumption with a TMR ratio of 200%, and the ‘improved’ assumption with a TMR ratio of 300%, yield significantly better or higher accuracies. Specifically, a 4-bit adder produces NED error of 2.8 × 10−2, 8.6 × 10−4, and 3.3 × 10−5, or NED accuracy of 97.2%, 99.914%, and 99.9967%, for the ‘experimental’, ‘production’, and ‘improved’ assumptions, respectively. A 4-bit multiplier produces NED error of 5.5 × 10−2, 1.8 × 10−3, and 6.6 × 10−5, or NED accuracy of 94.5%, 99.82%, and 99.9934%, for the three sets of assumptions, respectively. It is expected that when comparing the adder to the multiplier, since the latter is more complex and involves more gates, its accuracy is generally lower than that of the adder. Similarly, as the bit width of the adder or multiplier increases, their accuracy decreases. Further details and results with bit width up to 6-bit are provided in the Methods section and in Supplementary Note S9.
Then, using these primitives, we evaluate dot-product operations, which form the basis of matrix multiplication. They are heavily employed in many applications in both conventional domains and machine intelligence. Dot products consist of element-wise multiplication of two unsigned integer vectors, followed by addition. We perform additions with binary trees to maintain smaller circuit depth. Figure 6b shows the NED error of a 4-bit 4 × 4 dot-product matrix multiplier with respect to various TMR ratio assumptions. Like the adders and multipliers, as the TMR ratio increases, the NED error decreases, or the NED accuracy improves. Specifically, a 4-bit 4 × 4 dot-product matrix multiplier produces an NED error of 0.11, 3.4 × 10−3, and 1.2 × 10−4, or NED accuracy of 89%, 99.66%, and 99.988%, for the ‘experimental’, ‘production’, and ‘improved’ assumptions, respectively. Also, when comparing different input sizes (e.g., 1 × 1 to 4 × 4), as expected, the NED error is larger for larger input sizes due to the increased number of gates involved. Further details and results with bit width up to 5-bit are provided in the Methods section and in Supplementary Note S9.
Discussions
To summarize the experimental work, an MTJ-based 1 × 7 CRAM array hardware was experimentally demonstrated and systematically evaluated. The basic memory write and read operations of CRAM were achieved with high reliability. The study on CRAM logic operations began with 2-input logic operations. It was found that a 2-input NAND operation could be performed with accuracy as high as 99.4%. As the number of input cells was increased, for example, for 3-input MAJ3 and 5-input MAJ5 operations, the accuracy decreased to 86.5% and 75%, respectively. The decrease was attributed to having too many levels corresponding to the input states crowding a limited operating margin. Next, two versions of a 1-bit full adder were experimentally demonstrated using the 1 × 7 CRAM array: an all-NAND version and a MAJ + NOT version. The all-NAND design achieved an accuracy of 78.5%, while the seemingly simpler MAJ + NOT, which involves 3- and 5-input MAJ operations, only achieved an accuracy of 63.8%. Note that although each type of logic operation achieves optimal accuracy performance with a specific voltage value, the value is expected to only need to be static or constant. Therefore, only a finite number of power rails is needed to accommodate the logic operations of the CRAM array. Also, if the multiple logic pulse duration is allowed by a peripheral design, it is possible to operate the CRAM array with a single set of power rails for both memory write and logic operations.
A probabilistic model was proposed that accounts for the origin of errors, their propagation, and their accumulation during a multi-step CRAM operation. The model was shown to be effective when matched with the experimental results for the 1-bit full adder. The working principles of this model were adopted for the rest of the studies.
A suite of MTJ device circuit models was fitted to the existing experimental data and used to project CRAM NAND gate-level accuracy in the form of error rates. The gate-level error rates were shown to be 7.6 × 10−6, with reasonable expectations of TMR ratio improvement as MTJ technology develops. Other device properties, such as the switching probability transfer curve, could also significantly affect the CRAM gate-level error rate. This calls for improvements or new discoveries of the physical mechanisms for memory read-out and memory write. Error is an inherent property of any physical hardware, including CMOS logic components, which are commonly perceived as deterministic. As the development of CRAM proceeds, the gate-level error rate of CRAM will be further reduced over time. For now, while the error rate of CRAM is still higher compared to that of CMOS logic circuits, CRAM is naturally more suitable for applications that require less precision but can still benefit from the true-in-memory computing features and advantages of CRAM, instead of those that require high precision and determinism. Additionally, logic operations with many inputs, such as majority, may be desirable in certain scenarios. And yet, these were shown to have lower accuracy than 2-input operations. So, a tradeoff might exist.
Lastly, building on the experimental demonstration and evaluation of the 1-bit full adder designs, simulation and analysis were performed for larger functional circuits: scalar addition and multiplication up to 6 bits and matrix multiplication up to 5 bits with input size up to 4 × 4. These are essential building blocks for many conventional and machine intelligence applications. The parameters for the simulations were experimentally measured values as well as reasonable projections for future MTJ technology. The results show promising accuracy performance of CRAM at a functional building block level. Furthermore, as device technologies progress, improved performance or new switching mechanisms could further reduce the gate-level error rate of CRAM. Error correction techniques could also be employed to suppress CRAM gate errors.
In summary, this work serves as the first step in experimentally demonstrating the viability, feasibility, and realistic properties of MTJ-based CRAM hardware. Through modeling and simulation, it also lays out the foundation for a coherent view of CRAM, from the device physics level up to the application level. Prior work had established the potential of CRAM through numerical simulation only. Accordingly, there had been considerable interest in the unique features, speed, power, and energy benefits of the technology. This study puts the earlier work on a firm experimental footing, providing application-critical metrics of gate-level accuracy or error rate and linking it to the application accuracy. It paves the way for future work on large-scale applications, in conventional domains as well as new ones emerging in machine intelligence. It also indicates the possibility of making competitive large-scale CMOS-integrated CRAM hardware.
Methods
MTJ fabrication and preparation
The MTJ thin film stacks were grown by magnetron sputtering in a 12-source deposition system with a base pressure of 5 × 10−9 Torr. The MgO barrier was fabricated by RF sputtering, while all the metallic layers were fabricated by DC sputtering. The stack structure is Si/SiO2/Ta(3)/Ru(6)/Ta(4)/Mo(1.2)/Co20Fe60B20(1)/MgO(0.9)/Co20Fe60B20(1.4)/Mo(1.9)/Ta(5)/Ru(7), where numbers in brackets indicate the thickness of the layer in nm. The stack was then annealed at 300 °C for 20 minutes in a rapid thermal annealing system under an Ar atmosphere (more information on the MTJ stack fabrication can be found in refs. 74,75).
The MTJ stacks were fabricated using three rounds of lithography similar to those described in ref. 76. First, the bottom contacts were defined using photolithography followed by Ar+ ion milling etching. Then, the MTJ pillars were patterned into 120-nm circular nano-pillars via E-beam lithography and etched through Ar+ ion milling. After etching, SiO2 was deposited via plasma-enhanced chemical vapor deposition (PECVD) to protect the nano-pillars. Finally, the top contacts were defined using photolithography, and the metallic electrodes of Ti (10 nm)/Au (100 nm) were deposited using electron beam evaporation.
The die of the MTJ array was diced into smaller pieces, with each piece containing about 10 MTJ devices. Each of the small pieces was mounted on a cartridge board, and up to 8 MTJ devices were wire-bonded to the electrodes of the cartridge board. Seven cartridge boards were inserted into the connection board, providing MTJs to the CRAM. The MTJ in each CRAM cell is selected among up to 8 MTJs on the corresponding cartridge board. In total, seven MTJs are selected from up to 56 MTJs. This method allows the user to find a collection of seven MTJs with minimum device-device variations.
CRAM experiment
An individual bias magnetic field was implemented for each of the seven MTJs on the connection board by positioning a permanent magnet at a certain distance from the MTJ devices. The bias magnetic field was used to compensate for intrinsic magnetic exchange bias and stray fields in the MTJ devices, thereby restoring the balance between the P and AP states. Additionally, slight rotation of bias field in the device plane was used to effectively adjust the switching voltage of each MTJ. More details can be found in Supplementary Note S2.
The connection board with seven MTJs was connected to the main board. On the main board, necessary active and passive electronic components were populated on the custom-designed PCB. The CRAM demo hardware circuit implemented a 1 × 7 CRAM array with a modified architecture to emphasize logic operations while compromising on memory operations bandwidth for simplicity. It was modified from the full-fledged 2T1M40 architecture. It was equivalent to a 2T1M CRAM in logic mode, but it only had serial access to all cells for memory read and write operations (more details in Supplementary Note S1). The hardware was powered by a battery and communicated with the controller PC wirelessly via Bluetooth®. In this way, the entire hardware was electrically isolated from the environment so that the risk of ESD to these sensitive MTJs was minimized.
The experiment control software running on a PC was implemented using National Instruments’ LabVIEW™. It was responsible for real-time measurements and control of the experiments, as well as necessary visualizations. Certain results were further analyzed post-experiment.
CRAM modeling and simulations
The simulation studies of accuracy as well as error origination, accumulation, and propagation began with a simple probabilistic model of each NAND logic operation. A probabilistic truth table was used to describe the expected statistical average of the output logical state. Then, the 1-bit full adder designs and operations were simulated using the Monte Carlo method with assumed probabilistic truth tables for each of the logic steps (see Supplementary Note S6).
The experiment-based physics modeling and calculations for obtaining the projected CRAM logic operation accuracies began with an MTJ resistance-voltage model77, which was fit to the experimental data of TMR vs. bias voltage. The coefficients of this model were scaled accordingly to model projected TMR ratios higher than those observed experimentally. Then, a thermal activation model78,79 of MTJ switching probability was fit to experimental data and was used to calculate the switching probability of the output MTJ cell under various bias voltages. Finally, the average of the output state, <Dout>, could be calculated under various Vlogic, and the optimal NAND accuracies could be obtained in a manner similar to that discussed with Fig. 4 (more details in Supplementary Note S8).
Further simulation studies of a ripple-carry adder, a systolic multiplier, and the dot-product operation of a matrix multiplication for various numbers of bits as well as matrix sizes were carried out using the same methods. More details can be found in Supplementary Note S9.

Responses