Predictive learning as the basis of the testing effect
Introduction
A key finding in learning and memory studies is the testing effect, which indicates that undergoing a test, as opposed to mere studying, improves learning or retention1,2,3,4. Traditionally, testing has been regarded as an assessment tool to measure learning. However, seminal work from the early 1900s onwards has shown that testing could be an important factor in improving declarative memory5. Since then, studies with repeated studying and testing paradigms have robustly shown the utility of testing over pure studying for improving declarative memory1,6,7,8,9,10,11. Although the testing effect is a robust finding in literature and holds major educational implications4,12, the underlying nature of this effect is still unclear. We aim to clarify this mechanism through a combination of behavioral modeling and experiments, with particular emphasis on testing with feedback.
Several potential explanations for the testing effect have been proposed, including increased retrieval effort13,14, semantic elaboration15,16, and feedback during testing as compared to studying conditions4,17. However, only recently has the testing effect been related to well-known learning principles in biological and artificial neural networks2,18,19, most prominently Hebbian learning20,21,22 and predictive learning23. Hebbian learning proposes that learning occurs (only) between simultaneously activated representations24,25. For example, suppose an English speaker learns a new language like Swahili; if an English word and its Swahili translation often appear together, the connection between the neurons that represent the respective words will be strengthened. Moreover, extensive evidence shows that Hebbian learning could be modulated (or enhanced) by reward signals24,25, which might be a potential explanation for the testing effect. To be specific, the positive feedback during testing can function as a reward signal26, which is absent during study.
Predictive learning (also named delta or contrastive learning) is based on the fact that an artificial neural network (and by hypothesis, also a biological one) learns by minimizing the error between its prediction and feedback23. For instance, a neural network might initially predict Sydney as the capital of Australia but would then receive feedback indicating that Canberra is the actual capital. Based on this prediction error, the connection between Australia and Canberra will be enhanced, but the connection strength between Australia and Sydney will be decreased. Previous studies suggest that predictive learning plays a crucial role in both procedural (i.e., action-related) memory 27,28,29,30 and declarative memory 31,32,33,34,35. Importantly, an emergent theoretical framework suggests that the testing effect could potentially emerge from the benefit of predictive learning 2,18,19. During testing, people would predict the correct answer (which, by definition, is impossible in studying conditions). Afterward, the contrast between their prediction and the subsequent feedback would allow predictive learning to generate subsequent memory benefits.
In all, Hebbian and predictive learning propose different origins for the testing effect. Hebbian learning suggests that the testing effect arises from positive feedback, meaning that only tests followed by positive feedback lead to more efficient learning than study. In contrast, predictive learning attributes the testing effect to prediction error, which can occur in both correct and incorrect tests. It might seem counterintuitive that prediction error can occur in correct tests, given that participants choose the correct answer. However, low confidence in their correct responses may still trigger prediction errors upon receiving positive feedback.
In order to check whether the testing effect is more consistent with one of these two hypotheses, we developed an associative memory neural network framework alongside a behavioral task that, in conjunction, allowed us to investigate the origin of the testing effect. The neural network could implement Hebbian learning or predictive learning (or both), and the simulations of the resulting neural networks could disentangle these two learning mechanisms. We collected human data from two experiments for model fitting, which allowed us to manipulate prediction error differences between testing and studying conditions while controlling other potential confounds (See “Method”). The design consisted of several stages. First, participants memorized several English words and their Swahili translations. Subsequently, they would either be restricted to choose the Swahili translation of an English word from one (correct answer; study condition) or four Swahili options (test condition) and receive feedback on their choice afterward. Finally, participants in Experiment 1 performed immediate recognition. Since prior literature has demonstrated the significance of long intervals in the testing effect3,6,36, participants in Experiment 2 performed recognition with a 24 h delay. Additionally, a feedback-free experiment (Experiment 3) with immediate final recognition was conducted to establish a baseline learning state before introducing feedback. Our results should support predictive learning as a viable account to explain the testing effect, both at qualitative and quantitative levels.
Methods
Model architecture
We developed an associative memory neural network with 90 English units in the input layer and 360 Swahili units in the output layer, with each unit representing an English or Swahili word (Fig. 1a). The main task of this model was to learn the connections between English words and their corresponding Swahili translations. After initializing the connections (See “Model fitting” below), this model would receive test (choose an answer from four options) or study trials (can only choose the correct answer) and implement Hebbian learning or predictive learning (or both) to update the connections, followed by a recognition task. Hebbian learning would strengthen the connections between active English and Swahili units, while predictive learning was driven by prediction error. Importantly, Hebbian learning can appear when reward (or positive feedback) appears, while prediction error only appears in testing trials, which allows disentangling the contributions of Hebbian versus predictive learning. Note that reward-modulated Hebbian learning was implemented as the default Hebbian learning model in the current study25. This is because the Hebbian learning model without reward is unlikely to explain the testing effect. Indeed, for such a model, there would be no distinction between testing and studying conditions. However, non-reward Hebbian learning was still included as an additional model to ensure that Hebbian learning was fully explored as a possible model.

a Model architecture with 90 English input units and 360 Swahili output units. The model starts by initializing the connections by human confidence ratings. Subsequently, in study trials, the model could only implement Hebbian learning, as no predictions are involved in these trials. In contrast, test trials could implement either Hebbian or predictive (or both) learning. Lastly, model learning was tested on a recognition task. b Behavioral task. Phase 1: Participants learned 90 English-Swahili word pairs with each pair presented for 3 s. Phase 2: In each trial, participants chose the correct Swahili translation from four options, and then judged their confidence in their answer. Phase 3: In each trial, participants chose the correct translation, judged their confidence, and received feedback (except in Experiment 3). Only the correct option was framed in the studying trials, while all four options were framed in the testing trials. In Experiments 1 and 3, a 10 min Flanker task was administered between Phases 3 and 4. In Experiment 2, a 24 h interval was built in between phases 3 and 4. Phases 4 and 5: Two recognition phases with the same procedure as Phase 2 were conducted.
Irrespective of the learning method, the model generated its prediction following Eq. 1:
In words, the probability of each element ({hat{y}}_{j}) in the output layer (360 units, one for each Swahili word) was calculated by the weighted (({w}_{{ij}})) sum of the input values ({x}_{i}), which was transformed by the sigmoid function in Eq. (1). In the output layer, the elements that were not options on any trial were set as 0.
The Hebbian learning was implemented as follows:
Here, the model would update the weight ({w}_{{ij}}) between active English cue ({x}_{i}) and Swahili target ({y}_{j}) when reward ({r}_{j}) appeared. Predictive learning proceeded as the standard Rescorla-Wagner learning model27:
Here, the model would update the weight ({w}_{{ij}}) by the error between feedback ({y}_{j}) and prediction(,{hat{y}}_{j}).
Human data collection
We collected human data in three experiments by a task (Fig. 1b) that equalized testing and studying procedures as much as possible by consistently presenting four options (in Experiments 1–3) followed by feedback (in Experiments 1 and 2). All participants provided informed consent. Based on the sample size of previous studies using the variable-choice acquisition task19,37, we recruited 80 participants (mean age = 30.35, SD = 6.07, range = 18–41; 37 female participants, 43 male participants) for Experiment 1, 81 participants (mean age = 30.98, SD = 5.44, range = 19–40; 40 female participants, 41 male participants) for Experiment 2, and 62 participants (mean age = 29.97, SD = 6.02, range = 18–40; 24 female participants, 38 male participants) for Experiment 3 through the online experimental platform Prolific (https://prolific.co/). Sex information was collected via self-reports on Prolific using the question: “What is your sex, as recorded on legal/official documents?” Participants in Experiment 1 received £11.10, and those in Experiments 2 and 3 received £12.00 for their participation. All participants were native English speakers. This study falls under the General Ethics Protocol of the Faculty of Psychology and Educational Sciences of Ghent University. This study was not preregistered.
An overview of the experimental procedure is shown in Fig. 1b. A total of 450 words (90 English and 360 Swahili) were used. The participants’ main task was to learn as many as possible of the 90 English-Swahili word pairs. The experiment was programmed with JsPsych38.
Phase 1: initial learning
The main aim of Phase 1 was for participants to learn the word pairs. In this phase, all word pairs were sequentially presented on the screen for 3 s in a pseudorandom order (same random pattern for each participant). Presentation time was deliberately kept short to avoid participants learning all word pairs after a single presentation. As such, we could ensure that the bulk of learning took place in the subsequent formal task (where we manipulated study versus test).
Phase 2: filter test
The main aim of Phase 2 was to measure the strength of learning individual word pairs from Phase 1. In each trial of Phase 2, an English word was presented together with four possible Swahili translations. English words and Swahili translations appeared in a (new) pseudorandom pattern. Participants needed to choose the correct Swahili translation (press “f”, “v”, “n”, or “j”) from the four options (no time limit). After each choice, participants indicated how confident they were in their choice on a five-level scale ranging from 0 (very uncertain) to 4 (very certain; no time limit), which served as a first measure of strength of initial learning. The correct word pairs in this phase were deleted during the data processing to filter the initial learning from Phase 1.
Phase 3: test or study
The main aim of Phase 3 was to manipulate the testing or studying conditions. The set-up was generally the same as in Phase 2, but the English words and Swahili translations were all presented in a new pseudorandom order. Besides this, we manipulated the number of options from which a participant could choose, to operationalize a studying versus testing condition. Study and test conditions were constructed such that they were as similar as possible except for the prediction part. In the studying trials, only the correct answer was framed; thus, participants immediately received the correct answer. However, in the testing trials, the four options were framed, and participants needed to predict the answer, thereby allowing predictive learning. We assigned more trials to the testing condition (80% testing trials and 20% studying trials) to make sure there were enough successful tests (tests with positive feedback). In both conditions, after providing their response but before the feedback, participants had to indicate confidence in their answer on a scale of 0 to 4, which served as a second measure of strength of initial learning. Subsequently, feedback was presented in Experiments 1 and 2 (with ‘Wrong’ in red or ‘Correct’ in green, with no time limit on its display), along with the participant’s choice and the correct answer. In contrast, no feedback was provided in Experiment 3.
Phase 4 and phase 5: recognition
The main aim of Phase 4 was to measure the final memory performance. As mentioned, we formulated the study and test trials in a multiple-choice format in order to control the similarity between the two conditions as much as possible. However, this has the disadvantage of potentially introducing noise due to the fact that participants can choose the correct option at random with 25% accuracy. To address this issue, Phase 5 was included to separate the flukes (random choices) from real knowledge (memory-driven choices). To be specific, we scored a word pair as certainly correct only if it was successfully recognized in both Phase 4 and Phase 5 (See Human Data Processing). The procedure of these two recognition phases was identical to Phase 2, but the words were presented in a new pseudorandom pattern. Participants in Experiments 1 and 3 completed these two phases immediately, while those in Experiment 2 finished these two phases 24 h later. A 10 min flanker task was used as a distraction before these two phases in Experiments 1 and 3. In each trial of the flanker task, five arrows were presented, and participants indicated the direction of the middle arrow by pressing the left or right arrow key on the keyboard.
Human data processing
We removed some participants for the following reasons: In Experiment 1, four participants’ data were lost due to technical problems, and ten participants’ recognition accuracies (Phase 4 and Phase 5) were not significantly higher than chance level (their mean accuracy was lower than 34%). After removing these participants, the data of 66 participants was retained. In Experiment 2, fifteen participants’ recognition accuracies were not significantly higher than the chance level; one participant completed the recognition phase three days later; two participants knew Swahili; two participants had taken part in previous experiments related to Swahili; so finally, 61 participants were retained. In Experiment 3, twenty participants’ recognition accuracies were not significantly higher than chance level, and 42 participants were retained. Note, however, that our results were essentially equivalent if we did not remove participants with poor performance (See Supplementary Figs. 11–15). Several possible reasons might account for poor performance, such as long duration, low motivation, and no supervision. To be specific, the current experiment took about one and a half hour without any bonus for good performance, which might make it difficult for participants to stay focused in the unsupervised online context. Given this, it might be necessary for similar experiments to reduce duration (or decrease trial numbers) and set bonuses to motivate participants.
The formal analysis was conducted using generalized linear mixed-effects models (GLMM) in R software39. Data distribution was assumed to be normal, but this was not formally tested. Random slopes for all within-participant variables (Test vs. Study, feedback valence, and confidence) and a random intercept for participants were included in each model: Test vs Study (Test 1 and Study 0), feedback valence, and confidence were set as the predictors (The results remained essentially unchanged when only random intercepts were included). All the independent variables in the GLMM were mean-centered. The dependent variable, final recognition was assigned a score of 1 for correct recognitions in both Phase 4 and Phase 5, 0.5 for correct recognition in only one phase, and 0 for no correct recognition. The second method used a binary approach, assigning 1 for correct recognitions in both phases and 0 otherwise. Since both coding strategies yielded consistent results, we only presented the results from the first method in the main text. An equivalence test (Two One-Sided Tests; TOST) was conducted to determine whether the null effects of the standardized regression coefficients indicate the absence of a meaningful difference. The equivalence bounds were defined as −0.1 and 0.1, representing the smallest effect sizes considered theoretically or pragmatically meaningful.
Model fitting
Since no feedback was implemented in Experiment 3, the models were fitted to Experiments 1 and 2 only. Before implementing predictive learning and Hebbian learning, our model first summarized participants’ initial learning that occurred in Phase 1 (Fig. 1) by initializing the weights from word i to word j with the following Equation:
where ({c}_{{ij}}^{2}) and ({c}_{{ij}}^{3}) refer to the confidence ratings from Phase 2 and 3, respectively. Note that this equation is not intended as a learning rule: it is simply intended to capture whatever learning any individual participant may have done in Phase 1, measured via their reported confidence measures (in Phase 2 and 3), and scaled by parameter α. In the studying condition, participants received the correct answer directly and could not express their internal confidence in Phase 3, so we had no measure of their confidence for those items in Phase 3. To address this issue, we replaced study-trial confidence ({c}_{s}) with the mean confidence rating in the testing condition:
for each studied (rather than tested) word. We built several possible models based on the combination of three components: Initial learning (i.e., how much did they learn in Phase 1), Hebbian learning, and predictive learning. Parameter recovery was good for all models (see Supplementary Note 1 and Supplementary Figs. 3–5).
Because our main aim was to simulate the behavioral responses in Phases 4 and 5, we fitted the model’s parameters to the data from these two phases. First, the model prediction was calculated by Eq. (1). Second, model fitting proceeded by optimizing the log-likelihood function for each participant separately.
We allowed the parameters α and β to range from 0 to 1, and parameters k and b to range from 0 to 10. Further note that what matters for the model fit is the relative values of α versus β. To accommodate these two desiderata, at each iteration of the optimization, the parameters (alpha) and β were translated by soft-max functions in the following way:
and then fed into the model, where parameters α* and β* were estimated. The parameters k and b were translated by logistic functions:
Model evaluation and comparison
The weighted Akaike information criterion (wAIC) was used to evaluate and compare the model fits40. First, the AIC was calculated by the following equation:
where the LL is the log-likelihood function, and k is the number of parameters.
Second, the ({Delta {AIC}}_{m}) was calculated based on the AIC of each model and the minimal AIC among the models:
Finally, the ({{wAIC}}_{m}) was calculated using the ({Delta {AIC}}_{m}) to compare different models (higher ({{wAIC}}_{m}) means better model fit):
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
Behavioral oatterns
Because we mainly focus on the learning in Phase 3, the correct word pairs in Phase 2 were deleted to filter the extreme initial learning in Phase 1, with the resulting behavioral patterns illustrated in Fig. 2. Indeed, suppose participants learn a correct Swahili word very well in Phase 1. In this case, they are highly likely to select this correct Swahili word during the final recognition, regardless of feedback and prediction error manipulations after Phase 1. However, it should be noted that eliminating all initial learning is both impossible and counterproductive, as some residual initial learning is necessary to trigger predictive learning in Phase 3. Nevertheless, other strategies like deleting high-confidence word pairs in Phase 2 or no filter always led to similar behavioral patterns (Fig. 3; see modeling results without filtering in Supplementary Figs. 8–10), suggesting the robustness of these patterns across different strategies. To maintain conciseness, we concentrated on the data without correct word pairs in Phase 2 (i.e., data in Fig. 2). The distribution of trials across experimental conditions is depicted in Supplementary Fig. 1.

a Behavioral patterns from Experiment 1 replicated a significant testing effect in immediate recognitions (N = 66 participants); Final recognition after rewarded tests was better than after study, while unrewarded tests performed comparably to study. b Behavioral patterns from Experiment 2 replicated the findings from Experiment 1 in a 24 h delayed recognition phase (N = 61 participants). c The testing effect was not significant in the data without feedback (immediate final recognition; N = 41 participants). The difference in final recognition after correct and incorrect tests was driven by initial learning rather than by the valence of feedback. d–f The average final recognition accuracies in the testing and studying conditions. X-axis depicts confidence ratings from Phase 3; Error bars depict standard errors; Dots depict individual data.

a–c Behavioral patterns without high confidence word pairs in Phase 2. d–f Behavioral patterns with all word pairs. Different filter strategies generated similar behavioral patterns. X-axis depicts confidence ratings from Phase 3; Error bars depict standard errors; Dots depict individual data. Experiment 1: N = 66 participants, Experiment 2: N = 61 participants, Experiment 3: N = 41 participants.
Formal analysis (across three Experiments) included the Test vs. Study, Feedback (with feedback vs without feedback, i.e., Experiment), and their interaction into the same model to predict the final recognition accuracy. An omnibus test suggested that the inclusion of the interaction term (compared to a null model without interaction term) significantly improved the model fit (χ2(1, N = 168) = 71.674, p < 0.001), and the interaction effect between Feedback and Test vs Study was significant (χ2(1, N = 168) = 100.370, p < 0.001, β ± 95% CI = 0.176 ± 0.034, R2 = 0.073). This indicates that the testing effect differed across Experiments (i.e., Experiments with versus without feedback). Further simple effect analyses suggested that the testing effect was significant in both Experiments 1 and 2 with feedback (Experiment 1: χ2test(1, N = 66) = 30.323, p < 0.001, β ± 95% CI = 0.170 ± 0.061, R2 = 0.030; Experiment 2: χ2test(1, N = 61) = 26.702, p < 0.001, β ± 95% CI = 0.188 ± 0.072, R2 = 0.029), but not significant in Experiment 3 without feedback (Experiment 3: χ2test(1, N = 41) = 0.179, p = 0.672, β ± 95% CI = 0.022 ± 0.105, R2 = 0.187; Equivalence test: T(lower) = 2.204, p(lower) = 0.017, T(upper) = −1.500, p(upper) = 0.071). The effects of the covariates Correct vs. Incorrect (Phase 3) and Confidence (Phase 3) were also evaluated (Experiment 1: χ2correct(1, N = 66) = 77.166, p < 0.001, β ± 95% CI = 0.213 ± 0.049; χ2confidence(1, N = 66) = 0.552, p < 0.457, β ± 95% CI = 0.022 ± 0.056; Experiment 2: χ2correct(1, N = 61) = 48.951, p < 0.001, β ± 95% CI = 0.202 ± 0.058; χ2confidence(1, N = 61) = 0.346, p = 0.556, β ± 95% CI = 0.019 ± 0.064; Experiment 3: χ2correct(1, N = 41) = 132.597, p < 0.001, β ± 95% CI = 0.428 ± 0.076; χ2confidence(1, N = 41) = 0.801, p = 0.371, β ± 95% CI = 0.036 ± 0.078). In all, feedback was crucial for eliciting the testing effect.
In a further analysis, we statistically measured the learning effect from positive and negative feedback, with Feedback set as a between-participants factor (with feedback vs. without feedback). Here, the interaction between Feedback and Testing success (Correct vs Incorrect) in Phase 3 was significant (χ2(1, N = 168) = 23.682, p < 0.001, β ± 95% CI = −0.094 ± 0.038, R2 = 0.098). Further simple effects analysis suggested that the Feedback effect was even stronger for an incorrect test (χ2(1, N = 168) = 67.653, p < 0.001, β ± 95% CI = 0.261 ± 0.063, R2 = 0.067) than for a correct test (χ2(1, N = 168) = 4.544, p = 0.033, β ± 95% CI = 0.077 ± 0.071, R2 = 0.006). Therefore, learning from negative feedback exceeds learning from positive feedback, highlighting the crucial role of negative feedback in the testing effect (while noting that positive feedback also contributes significantly to the testing effect). To clearly assess the pure contribution of feedback, we subtracted the final recognition (mean value in each condition) of data without feedback from those with feedback, using data from Experiments 1 and 3 with immediate recognitions. This analysis revealed learning from both positive and negative feedback, with the learning from negative feedback being greater than learning from positive feedback (see detail in Supplementary Fig. 2). Note that this subtraction is included purely for illustrative purposes and does not hold statistical value. Overall, these findings support the predictive learning assumption that both positive and negative feedback could support the testing effect.
A potential argument against the contribution of negative feedback to the testing effect is that final recognition accuracy following negative feedback did not surpass that after study. Indeed, the interaction effect between Feedback valence and Test vs Study was significant (χ2(1, N = 168) = 130.350, p < 0.001, β ± 95% CI = 0.169 ± 0.029, R2 = 0.028), with the final recognition accuracy after positive feedback (correct tests) being significantly higher than after study (Experiment 1: χ2(1, N = 66) = 42.722, p < 0.001, β ± 95% CI = 0.196 ± 0.060, R2 = 0.038; Experiment 2: χ2 (1, N = 61) = 54.796, p < 0.001, β ± 95% CI = 0.246 ± 0.066, R2 = 0.060). In contrast, the final recognition accuracy after negative feedback (incorrect tests) was not significantly higher than after study (Experiment 1: χ2(1, N = 66) = 1.049, p = 0.306, β ± 95% CI = −0.020 ± 0.039, R2 < 0.001, Equivalence test: T(lower) = 3.950, p(lower) < 0.001, T(upper) = −6.050, p(upper) < 0.001; Experiment 2: χ2 (1, N = 61) = 0.098, p = 0.754, β ± 95% CI = 0.007 ± 0.044, R2 < 0.001, Equivalence test: T(lower) = 4.864, p(lower) < 0.001, T(upper) = -4.227, p(upper) < 0.001). However, the low final recognition accuracy after negative feedback was primarily driven by weak initial learning. Indeed, when negative feedback was absent and only initial learning could have an effect (Experiment 3), the final recognition accuracy after incorrect tests was significantly lower than after study (χ2 (1, N = 41) = 108.28, p < 0.001, β ± 95% CI = −0.413 ± 0.080, R2 = 0.167). Notably, despite the weak initial learning in incorrect testing items, final recognition accuracy after negative feedback (Experiment 1: 50.971%; Experiment 2: 38.787%) eventually became statistically similar to after study (Experiment1: 53.186%; Experiment 2: 40.925%; See statistical results above), indicating that incorrect tests with negative feedback were in fact more effective than study when considered relative to an appropriate baseline.
Model fitting
Model comparison
Before the implementation of Hebbian and predictive learning, the initial learning in Phase 1 was calculated by participants’ choices and confidence ratings in Phase 2 and Phase 3 (See Method). We fitted all 23 – 1 = 7 possible models including various combinations of the components of initial learning, Hebbian learning, and predictive learning (Each model in Experiment 1: N = 66 simulations; Each model in Experiment 2: N = 61 simulations; Each simulation corresponds to one participant’s data). The main goal of the model fitting was to replicate the performance in Phase 4 and Phase 5, so model parameters were optimized by fitting the data from these two phases. Model comparison by wAIC (See “Method”) suggested that the best fitting model in Experiment 1 was the full model with initial learning, Hebbian learning, and predictive learning (Model 7; Fig. 4a and i). A within-participants ANOVA that predicted each participant’s wAIC value showed a main effect of the factor model (F (6, 390) = 47.691, p < 0.001, η² = 0.423, N = 66 participants), which suggested a significant fitting difference. Model 5 (with only initial and predictive learning) obtained the second-best fit (Fig. 4a). In Experiment 2, the model with both initial learning and predictive learning had the highest wAIC (Model 5; Fig. 5a and g). The within-participants ANOVA showed a significant main effect of the factor model (F (6, 360) = 89.419, p < 0.001, η² = 0.598, N = 61 participants). Model 7 (the full model) obtained the second-best fit in this case (Fig. 5a). The parameters of the winning models are shown in Supplementary Table 1.
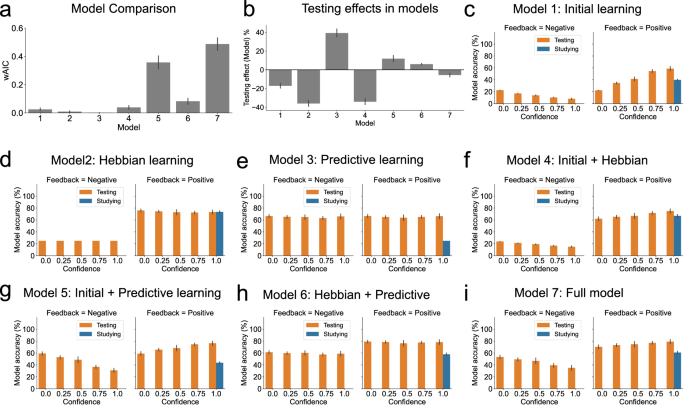
a Model comparison by wAIC. Higher wAIC means better model fitting. b The testing effects in the models were calculated by subtracting the mean final recognition accuracy of the study condition from that of the test condition. c–i Simulations from all seven models (Each model: N = 66 simulations). X-axis depicts confidence ratings from Phase 3; Error bars depict standard errors.

a Model comparison by wAIC. Higher wAIC means better model fitting. b The testing effects in the models were calculated by subtracting the mean final recognition accuracy of the study condition from that of the test condition. c–i Simulations from all seven models (Each model: N = 61 simulations). X-axis depicts confidence ratings from Phase 3; Error bars depict standard errors.
Model simulation
The simulations from the fitted models disentangled the contribution of Hebbian learning and predictive learning. Specifically, Hebbian learning enhanced (Phases 4 and 5) recognition after study and tests followed by positive feedback, while predictive learning benefited (Phase 4 and 5) recognition after all tests (irrespective of whether the feedback was positive or negative). Importantly, only the two models with initial learning and predictive learning (Models 5 and 7) could replicate (both qualitatively and quantitatively) the human behavioral patterns (Figs. 4g, i; 5g, i). Moreover, for the testing effect, predictive learning was crucial. The models with initial learning and/or Hebbian learning but no predictive learning (Figs. 4c, d, f; 5c, d, f) did not reproduce the testing effect. Indeed, the mean height of the orange bars (tests) is higher than that of the blue bar (study) in models with predictive learning and human data, but not in models with Hebbian learning.
A minor issue is that no model’s final recognition after incorrect tests perfectly matched the human data in Experiment 1. Specifically, human final recognition accuracy did not decrease with confidence ratings after incorrect tests (χ2(1, N = 66) = 2.828, p = 0.093, β ± 95% CI = −0.072 ± 0.084, R2 = 0.002), unlike in the model simulation. One possible explanation is that initial learning and confidence ratings were unreliable in these incorrect tests, as participants never selected correct answers (Phases 2 and 3) in these conditions. This unreliable initial learning may have introduced excessive noise into the final recognition process (Phases 4 and 5), making accurate simulation difficult. Interestingly, in Experiment 2, human final recognition accuracy decreased with confidence ratings (χ2(1, N = 61) = 4.391, p = 0.036, β ± 95% CI = −0.055 ± 0.051, R2 = 0.003), which was very well simulated by Model 5, possibly because the noisy initial learning had significantly diminished 24 h later.
Next, we investigated which estimated model parameter best predicted the participant-level testing effect, defined as the difference between the mean recognition accuracies of all testing trials and all studying trials. We found that only the learning rate of predictive (Model 5) but not of Hebbian (Model 4) learning (Experiment 1: χh2 (1, N = 66) = 0.332, p = 0.564, β ± 95% CI = 0.012 ± 0.039, R2 = 0.005; χp2 (1, N = 66) = 17.892, p < 0.001, β ± 95% CI = 0.075 ± 0.035, R2 = 0.218; Experiment 2: χh2 (1, N = 61) = 0.985, p = 0.321, β ± 95% CI = 0.021 ± 0.041, R2 = 0.016; χp2 (1, N = 61) = 8.183, p = 0.004, β ± 95% CI = 0.057 ± 0.039, R2 = 0.122; h: Hebbian; p: predictive) could predict the magnitude of the human testing effect at the individual level (Fig. 6). Alternatively, one could combine Hebbian and predictive learning rates in the same model (e.g., full model) to predict the human testing effect. Hence, we built a new full model (Hebbian and predictive learnings in the current full model share the same learning rate; See “Method”) with separate Hebbian and predictive learning rates to predict the participant-level testing effect, which led to nearly same results (Supplementary Fig. 6).

a, b Predictive learning rate, rather than Hebbian learning rate could predict the human testing effect in Experiment 1 (N = 66 participants). c, d predictive learning rate, rather than Hebbian learning rate could predict the human testing effect in Experiment 2 (N = 61 participants).
Pure contribution of predictive learning
Although the above findings support that predictive learning, rather than Hebbian learning, is the basis of the testing effect, the pure contribution of predictive learning remains unclear due to the influence of initial learning. To address this, we utilized the optimal parameters from the fitted Model 5 for further simulations. In the first simulation, we incorporated only initial learning (with the optimal parameter α from Model 5) to establish a baseline recognition accuracy before predictive learning (Fig. 7b, e). In the second simulation, we included both initial learning and predictive learning (with the optimal parameters α and β from Model 5). By subtracting the baseline recognition accuracy from the final recognition accuracy (Fig. 7a, d), we were able to quantify the contribution of predictive learning (Fig. 7c, f). This result shows that predictive learning occurred in both correct and incorrect tests but was absent in the study condition. Moreover, predictive learning in incorrect tests was even stronger than in correct tests.

After fitting Model 5, we retained the optimal parameters and conducted further simulations. a, d Both initial learning and predictive learning were included in this simulation, providing a final recognition accuracy. b, e Only initial learning was included in this simulation, yielding a baseline recognition accuracy without predictive learning. c, f By subtracting the baseline recognition accuracy from the final recognition accuracy, we quantified the pure contribution of predictive learning. X-axis depicts confidence ratings from Phase 3; Error bars depict standard errors. Experiment 1: N = 66 simulations, Experiment 2: N = 61 simulations.
Testing the limits of Hebbian learning
To further explore if there was any possibility for a Hebbian learning-based testing effect, we conducted four further explorations. First, we carried out a systematic parameter exploration to investigate if it was at all possible for the Hebbian model to produce a testing effect. This turned out to be impossible: No combination of parameters in the Hebbian learning model yielded a testing effect (Model 4; Supplementary Note 2 and Supplementary Fig. 7). Second, we investigated whether Hebbian learning without a reward component (allowing the model to extend learning to all trials) could simulate the testing effect. This approach also failed, and model comparisons did not support this version (Model 8; Fig. 8a, e, b, f). Third, in the studying context, participants already knew the correct answer, so the positive feedback in this context might not function as a reward. As such, we removed the reward component in the model’s studying condition, and this revised model can mimic the final recognition after study and correct tests (Model 9; Fig. 8c, g). However, this model’s recognition following incorrect tests was worse than after study, which contrasts with human data and the testing effect. Additionally, model comparisons did not support this model (Fig. 8a, e). Finally, we developed a third model featuring regular Hebbian learning during study and reward-enhanced Hebbian learning during tests with positive feedback (Fig. 8d, h). During tests with negative feedback, this model not only implemented Hebbian learning but also suppressed the connections between English words and incorrect Swahili choices. However, this model suggests that (Hebbian) learning from positive feedback is larger than from negative feedback (Fig. 9), which is opposite to the human behavioral pattern. Furthermore, model comparisons revealed that this revised Hebbian learning model fit the human data less accurately than the predictive learning model (Fig. 8a, e).
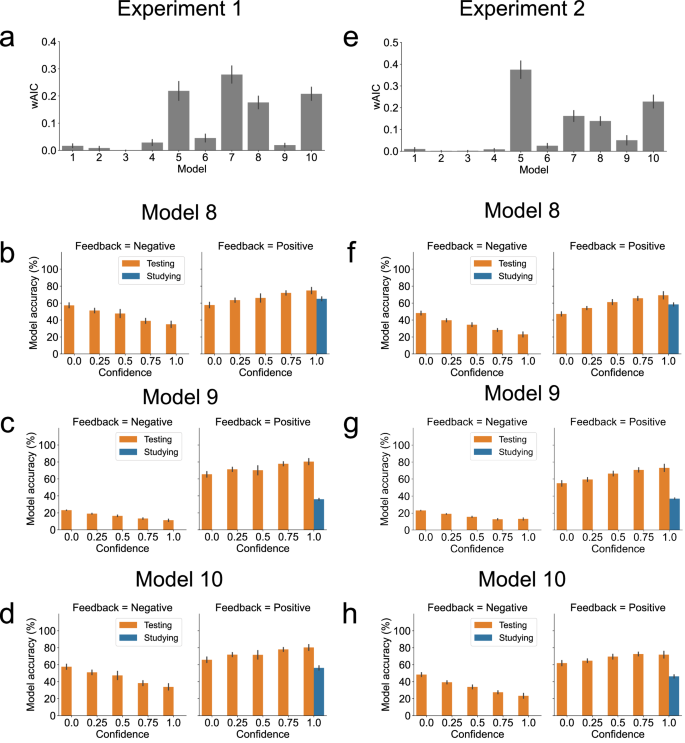
a, e Model comparison in Experiment 1 and Experiment 2. Model 8: Initial learning and standard Hebbian learning without reward component. Model 9: Initial learning and Hebbian learning only with reward component in tests with positive feedback. Model 10: Initial learning; punishment-based Hebbian learning during tests with negative feedback, regular Hebbian learning during study, and reward-based Hebbian learning during tests with positive feedback. b, f Simulations of model 8 in Experiment 1 and Experiment 2. c, g Simulations of model 9 in Experiment 1 and Experiment 2. d, h Simulations of Model 10 in Experiment 1 and Experiment 2. X-axis depicts confidence ratings from Phase 3; Error bars depict standard errors. Experiment 1: N = 66 simulations, Experiment 2: N = 61 simulations.

After fitting Model 10, we retained the optimal parameters and conducted further simulations. a, d Both initial learning and Hebbian learning were included in this simulation, providing a final recognition accuracy. b, e Only initial learning was included in this simulation, yielding a baseline recognition accuracy without Hebbian learning. c, f By subtracting the baseline recognition accuracy from the final recognition accuracy, we quantified the pure contribution of Hebbian learning. X-axis depicts confidence ratings from Phase 3; Error bars depict standard errors. Experiment 1: N = 66 simulations, Experiment 2: N = 61 simulations.
Discussion
The current study explored the nature of the testing effect with several neural networks manipulating Hebbian and predictive learning. Human data from two experiments were collected for model fitting, which replicated the robust testing effect. A third no-feedback experiment provided an appropriate baseline. Notably, all tests, regardless of reward, led to more efficient learning compared to studying alone, supporting the predictive learning hypothesis. Crucially, the neural networks could only simulate the testing effect observed in human data when predictive learning was incorporated, with predictive learning contributing to both rewarded and unrewarded tests, aligning with human data. To explore whether Hebbian learning could account for the testing effect nevertheless, we systematically searched the parameter space and built three additional variants of the Hebbian learning rule. However, neither approach was able to produce a (Hebbian-based) testing effect.
It is well known that predictive learning is computationally much more powerful than Hebbian learning41. The current study demonstrates that it is also more empirically plausible for human learning (testing effect). Of course, a major body of work demonstrates that neurons are in some sense associative, meaning that if two cells co-activate, their connection strength will grow as a result. This finding is often interpreted in a Hebbian learning context (cf. “if it fires together, it wires together”). However, it is important to acknowledge that predictive learning is associative in the same sense; future work that aims to disentangle these different associative learning rules will be valuable.
In line with our findings, Liu et al. (2021) proposed the Testing Activated Cortico-Hippocampal interaction (TEACH) framework based on predictive learning to explain the testing effect2. They suggest that the hippocampus holds a representation of the target, while the neocortex can make a (model-based) prediction of the target. During test (but not during study), these target representations are compared, and their contrast leads to predictive learning and the subsequent testing effect. In follow-up work, Zheng et al. (2022) implemented a model with only predictive learning in Hippocampus, which could replicate the testing effect18. Interestingly, in their model, the testing effect could also not be produced if predictive learning was replaced by Hebbian learning. Our model and TAECH model are complementary in some respects. In particular, our model was tractable enough to be fitted to human data. In our model, the initial learning, Hebbian learning, and predictive learning contributions were all estimated from human data, where the models could clearly disentangle these learning components and show the contribution of each component. In contrast, the TEACH model was neurobiologically detailed but were not fitted to data, which makes it hard to disentangle different learning components in human data like what we could do in our model.
Notably, our model has the potential to incorporate some ideas from the TEACH model and explain the testing effect without feedback1,42. The hippocampal representation of a target in the TEACH model might serve as internal (or implicit) feedback. Previous studies have indeed found that people can generate internal (or implicit) feedback43,44,45. For example, the ventral striatum is an important neural basis of external feedback and reward, but this region is also active when participants answer correctly even without external feedback46. Importantly, because testing is an active task, participants’ internal feedback (i.e., “Is my answer correct?”) can change within a testing trial47,48,49 and may generate a temporal prediction error2,18, which makes (temporal) predictive learning possible even without external feedback. This argument is not applicable in study trials because study is not an active task: No prediction errors can be generated in this case. Moreover, the temporal prediction error is more likely to be positive in correct tests (e.g., “Aha! I finally find the correct answer!”), which may explain why good retrieval performance is important for the testing effect without external feedback1,42. Given this (admittedly, speculative) interpretation, future studies could explore whether temporal predictive learning could explain the testing effect without external feedback.
Besides predictive learning, several alternative explanations for the testing effect have been proposed in the literature. According to retrieval theory, the mere act of retrieving consolidates the original memory trace, thus producing a testing effect1,3,7. A related theory, retrieval effort theory, suggests that the retrieval effort or retrieval difficulty induced by testing produces the testing effect4,14,15,36. In line with this latter theory, previous studies found that the testing effect increases with retrieval difficulty14, and with the time interval between initial learning and retrieval practice13,14. Semantic elaboration theory proposes that testing produces an elaborative network of multiple mediators to the (word) target which can support subsequent correct recall4,15,16. For example, during testing, people might generate many possible answers before recollecting the target, which then serve as mediators for subsequent tests4. These studies found that fewer cues and weakly associated word pairs would trigger a stronger testing effect, in which conditions participants had more chance to elaboratively generate mediators15,16. Finally, feedback is a crucial factor in enhancing the testing effect4,17. Indeed, previous studies showed that the testing effect was stronger with than without feedback4,17.
Grounding the testing effect in predictive learning, as we did, could provide an encompassing framework that integrates several aspects of the alternative theories mentioned above, but can also account for observations falling outside the explanatory realm of these theories. First, predictive learning can account for the fact that weakly associated word pairs16 and difficult tests13,14 are remembered well. Indeed, such pairs are likely to evoke a stronger contrast between prediction and feedback. Second, predictive learning also predicts that feedback is a crucial factor in subsequent recall, just like the feedback-effect theory. In the predictive framework, the role of feedback receives a concrete mechanistic role, namely, to evoke prediction error, necessary for learning, which generates a testing effect. Third, retrieval-based theories predict that retrieval attempts can trigger a testing effect50. Given that prediction is a type of retrieval, there is again conceptual overlap between these theories.
The current framework also offers several unique advantages. For example, disentangling initial learning from other learning components, as achieved by our model, holds profound implications. Initial learning is essential to the testing effect4, as subsequent testing cannot trigger the retrieval process without it. However, initial learning obscures the contributions of other learning components. If not adequately controlled, it may lead to the misleading conclusion that the testing effect is primarily driven by correct tests, as final recognition after incorrect tests did not surpass that after study. Yet, our model extracted the predictive learning component during test and study, revealing that both correct and incorrect tests could result in more efficient learning than study. This finding goes beyond the viewpoint of existing theoretical frameworks but can be explained by the predictive learning framework. Notably, the predictive learning framework aligns with earlier evidence showing that retention after an incorrect test can surpass that after study when initial learning is absent51.
Another advantage of the predictive framework is that it immediately leads to neural predictions about the testing effect and declarative memory more generally. Previous fMRI studies have explored the unique neural activations during test (relative to restudy) that led to superior subsequent memory52,53,54,55,56, or the unique neural similarity between initial studying and test (relative to restudy) by representational similarity analysis57, which identified the hippocampus and several cortical regions as importantly involved in testing. Furthermore, predictive learning could lead to future neural exploration. Indeed, several neurobiological findings in predictive learning may be relevant for the testing effect29,37,28,58,59. For example, many previous studies have suggested that dopamine is the neural basis of predictive learning and plays an important role in memory28,29,58. Therefore, future studies could explore whether the testing effect emerges from dopamine-driven learning. Moreover, in light of TEACH model2, the interaction between the hippocampus and cortical regions might mediate the testing effect.
The hypercorrection effect suggests that high-confidence errors are more readily corrected by feedback than low-confidence errors60,61,62. However, the current study found that final recognition accuracy did not increase with high wrong-confidence ratings in the negative feedback context, which appears inconsistent with this effect. A possible, though speculative, explanation for this discrepancy may lie in the role of background knowledge. Previous studies often employed general knowledge questions, where participants had relevant background knowledge. This background knowledge may generate stronger high-confidence errors. For example, if someone is pretty sure that Sydney is the capital of Australia, feedback indicating that Canberra is the capital might be quite strong as it goes against the person’s background knowledge base. In contrast, the current study used Swahili words as materials, for which participants lacked such background knowledge. Obviously, further work is needed to test this possibility.
Limitations
Finally, certain limitations must be acknowledged. First, the current study employed a variant of the variable-choice task, a recognition-based memory task that was previously used to study declarative memory more generally19. This task was chosen because recognition is typically easier than recall63,64, thus ensuring enough correct tests with positive feedback in Phase 3, which is crucial for (Hebbian or predictive) learning. Indeed, recalling a Swahili word after its brief presentation in Phase 1 is challenging. For example, a previous study found that participants recalled only about 24% of 50 Swahili words after the first study phase65. This percentage would likely be even lower in our study, which involved 90 Swahili words. In future studies, we aim to replicate our findings in a recall-based task by using fewer word pairs (to reduce difficulty) and more participants (to maintain statistical power). Second, the testing effect without feedback is typically stronger in delayed final tests3,6,36. This could be one factor why the testing effect was not significant in Experiment 3 (which used immediate final recognition). This point warrants further investigation in future studies. Finally, initial learning couldn’t be completely eliminated by deleting the correct or high-confidence word pairs in Phase 2. To address this, the model incorporated confidence ratings from both Phase 2 and Phase 3 to simulate initial learning and disentangle it from other components. Although the filtering strategies are never perfect, it is reassuring that, regardless of how we filter the data, we consistently obtain very similar results. This consistency ensures the robustness of our findings.
Responses