Preserving and combining knowledge in robotic lifelong reinforcement learning
Main
Humans show a remarkable ability for lifelong learning by consistently acquiring knowledge and adapting to new task scenarios throughout their lives. This involves the constant and incremental development of increasingly complex behaviours, recognized as a crucial mechanism for achieving general intelligence. Recent advancements in artificial intelligence have showcased agents achieving remarkable performance across a wide range of tasks1, such as image generation2, article writing3 and autonomous driving4. However, even though current methodologies yield impressive outcomes, they primarily focus on agents specialized in narrowly distributed tasks. In contrast, untrained agents generally require more game-play experiences throughout their lifespan than humans and struggle to generalize effectively to new variations. One notable gap between machine-intelligent agents and humans is the lack of lifelong learning capability in current intelligent agents. Lifelong learning, also referred to as incremental or continual learning5,6,7, addresses the challenge of asynchronously acquiring knowledge from a continuous stream of tasks while mitigating forgetting. Its primary goal is to gradually extend the accumulated knowledge and use it for ongoing learning tasks, thereby building more complicated behaviours by knowledge combination and reapplication. This study focuses on robotic lifelong reinforcement learning (LRL), a domain where reinforcement learning provides an agent–environment interaction framework that is well suited for exploring the learning process in a sequential manner. Figure 1a illustrates the training process for a general LRL agent in the robotic context. Given an infinite stream of robotic tasks, the agent continually masters the tasks one after another, consistently accumulating knowledge and skills.

a, Overview illustration of the general LRL process. Unlike the conventional multi-task approaches, where agents have simultaneous access to all tasks, an LRL agent can master tasks sequentially, one after another. Moreover, the agent should continually accumulate knowledge throughout the process. This concept emulates the human learning process. b, Our proposed framework under the lifelong learning concept. We instruct the deployed embodied agent to perform long-horizon tasks using language commands. The agent accomplishes these tasks through the combination and reapplication of acquired knowledge.
For deep learning-based algorithms, the primary challenge when facing a stream of tasks is balancing the stability and plasticity1 of the neural networks. A common issue in this context is ‘catastrophic forgetting’1,8. This refers to the phenomenon where the neural network parameters associated with previously learned skills are rapidly overwritten when the agent learns new incoming tasks. Consequently, the agent’s performance substantially deteriorates when revisiting previously mastered tasks. Recent lifelong machine learning studies have introduced various approaches, including regularization5,9,10, structure modularity11,12,13 and experience replay14,15,16. These methods, however, have primarily been applied to static datasets in conventional machine learning domains such as vision task classification8,17, leaving their effectiveness in robotic learning unclear. Regularization can lead to improper parameter shifting and error accumulation, while structure modularity may struggle with dynamic adaptation when facing an unknown number of tasks. Without replay, both regularization and structure modularity methods tend to overfit on predefined tasks, lacking the flexibility to adapt to new ones in lifelong learning. Our approach does not strictly belong to any of these categories but instead draws inspiration from these methods, aiming to overcome their limitations while leveraging their strengths.
In the context of deep reinforcement learning, a common idea to avoid ‘catastrophic forgetting’ is through multi-task reinforcement learning (MTRL)18,19,20,21. In MTRL, the agent has simultaneous access to all tasks during training, avoiding the forgetting problem inherent in deep neural networks. Recent works in this domain include contextual attention-based representation learning22, soft modularization21, feature-wise linear modulation23 and other baselines19,20,24. However, the MTRL deviates from actual human learning patterns. While MTRL tries to avoid the issue of catastrophic forgetting by providing data from various tasks simultaneously, this problem still persists in the sequential learning process. Furthermore, it relies on a predefined range of task distributions, which are often limited in scope and struggle to generalize when encountering novel non-parametric task variability18. Such variability shows qualitative distinction and cannot be adequately described by continuous parameters, as they require models to learn entirely new sets of rules and interactions, thus challenging their generalization capabilities18. Motivated by MTRL, another set of approaches to tackle the stability–plasticity dilemma is known as ‘learning to learn’ or meta reinforcement learning1. Recent studies have provided diverse approaches that enable agents to acquire knowledge across various task distributions while adapting to new tasks based on acquired knowledge in few-shot or zero-shot manner25,26,27,28,29. One notable example is continuous environment meta-reinforcement learning25, which incorporates a Gaussian mixture model in its prior space of task encoder, which can infer and cluster the task latent representation at a meta level. However, the Gaussian mixture model faces limitations due to its reliance on a predetermined task amount, an assumption incompatible with the typically unknown or infinite task amounts in LRL.
Our study aims to develop a deep reinforcement learning framework for robotic lifelong learning. The focus is on continually learning and preserving knowledge from a stream of one-time feeding task scenarios. The proposed agent shall not forget the knowledge it acquired and can consistently perform stably on corresponding tasks throughout its lifespan. Moreover, our framework is designed to handle more complex long-horizon tasks by effectively combining and reapplying the underlying knowledge acquired from the ongoing task stream. This highlights its capability for incremental development of progressively sophisticated behaviours. To achieve the objective, we develop a framework inspired by the Dirichlet process mixture model (DPMM), a prominent model in the Bayesian non-parametric domain, with a memoized variational Bayes inference method (memoVB)30. This combination enables simultaneous task inference and asynchronous knowledge preservation at the upstream level. Moreover, our framework utilizes natural language-based side information to assist in task inference. This information is encoded by a pre-trained large language model (LLM)31. The resulting language embedding offers the agent richer contextual insights into the current task scenario, contributing to more precise and disentangled representations in the knowledge space. As a result, the collaborative efforts of DPMM and language embeddings contribute to more accurate downstream action pattern learning. Furthermore, our embodied agent shows the ability to solve challenging, long-horizon manipulation tasks in the real world by combining and reapplying knowledge acquired throughout its lifelong learning. This showcases its potential for achieving general intelligence and may inspire the development of more broadly applicable intelligent agents. We name our proposed framework as LEGION: a Language Embedding-based Generative Incremental Off-policy Reinforcement Learning Framework with Non-parametric Bayes.
Results
In this section, we present the test results of our LEGION framework. We begin by demonstrating its performance in real-world manipulation tasks, covering both long-horizon tasks and the original sequence of single-task training. Next, we assess how knowledge is preserved in the prior space. In addition, we provide quantitative data to evaluate key aspects of LRL within our framework. Finally, we highlight the contribution of our non-parametric knowledge space in few-shot knowledge recall. The experimental set-up for both simulation and real-world experiments is detailed in ‘Training and deployment’ in Methods and Supplementary Section 5.
Manipulation performance
Long-horizon tasks
The deployment set-up of our framework is illustrated in Fig. 1b. To provide human commands of the task descriptions, we use a speech-recognition device and a pre-trained LLM. The trained embodied agent receives the state observations conditioned with language embeddings as inputs. After receiving the observations, the task encoder infers the knowledge to which it should apply. Subsequently, the downstream policy generates corresponding actions to accomplish the task. In the real-world scenario, we employ a KUKA iiwa robot arm as our embodiment and use a global RealSense camera to acquire vision information. A real-world video demonstration (Supplementary Video 1) showcases our embodied agent successfully completing the long-horizon task ‘clean the table’, which consists of seven sequential subtasks. Our agent accomplishes this by recombining the underlying knowledge gained from the one-time feeding task stream (Fig. 2), illustrating its effective generalization in the face of diverse and challenging task distributions. This ability mirrors the human learning process over a lifetime and is regarded as a key mechanism underlying general intelligence. Conventional approaches to such long-horizon tasks involve relying on human demonstrations for direct imitation. However, these approaches often result in limited generalization and flexibility when confronting varied task distributions and sequences. In contrast, our framework offers flexibility in task execution order, allowing the agent to complete the entire task in any sequence through the combination and reapplication of acquired knowledge. To highlight the generalization and flexibility of our proposed framework, we reorder the subtasks randomly and present two additional demonstrations in Supplementary Video 2. As our broad task assumption includes long-horizon tasks with strict subtask conditions as a subset, we also demonstrate how our agent solves a conventional strictly conditioned long-horizon task, ‘make the coffee’ (Supplementary Section 3.2).

Snapshots of embodied agent on individual manipulation tasks after LRL.
Stream of tasks
Given a stream of one-time feeding tasks, our proposed LRL agent can master the task continually, one after the other, without forgetting previously acquired knowledge. This incremental learning approach mimics the natural human learning process and has the potential to replace, and eventually surpass, inefficient manual services in real-world applications. To assess the lifelong learning capability of our proposed agent, we implement ten distinct robotic manipulation tasks to build up a task stream. Our agent can gain knowledge asynchronously from this stream and eventually achieve the given long-horizon task (Supplementary Video 1). The agent undergoes training on each task for 1 million steps before switching to the next task. The task sequence follows an easy-to-hard task ordering (Supplementary Section 3.1): ‘reach → push → pick–place → door open → faucet open → drawer close → button press → peg unplug → window open → window close’.
To demonstrate the performance of our proposed framework on its original sequence task distributions, we showcase the snapshots of its real-world tasks in Fig. 2, and we provide Supplementary Video 3 of all tasks. As observed in the snapshots and video, our proposed embodied agent completes all tasks within the given time steps. In addition, in each real-world task, we conduct at least three trials, varying the initial object positions and goal positions. The average success rates for these trials are presented in Extended Data Table 1. To demonstrate stability and robustness within the given base task distributions, our embodied agent consistently accomplishes various manipulation tasks, including ‘reach’, ‘faucet open’, ‘drawer close’, ‘button press’ and ‘window open/close’, leveraging asynchronously acquired knowledge. For some more challenging tasks such as ‘push’, ‘pick–place’ and ‘door open’, our agent can also maintain a high success rate with a score of at least 0.67.
Knowledge preservation
We evaluate knowledge preservation through t-distributed stochastic neighbor embedding (t-SNE) visualizations for intuitive understanding and statistical analysis for quantitative performance assessment during training. Furthermore, a detailed ablation study highlighting the contributions of our Bayesian non-parametric knowledge space and language embeddings is provided in Supplementary Section 3.3.
Visualization
In our framework, the task encoder initially infers the state inputs and generates the latent samples as inference results. Subsequently, the inferred task results are fitted into the non-parametric knowledge space. To assess how the acquired knowledge is preserved and managed in its space, we use t-SNE to visualize our knowledge space in a two-dimensional plane. Figure 3a–e shows the projections of knowledge space after training on two, four, six, eight and all ten tasks, respectively. Each coloured group signifies a complete task trajectory and is assigned to a cluster component in our non-parametric knowledge space. In addition, the order of these samples is represented by corresponding colour opacity, progressing from light to dark. Notably, our proposed DPMM module in the knowledge space can generate new components to store new task inference results when switching environments, facilitating the capability to infer and store new knowledge. In addition, to evaluate how our knowledge space handles acquired knowledge, we make the agent undertake the training loop twice. During the second loop, the agent revisits previously mastered tasks, whose knowledge has been preserved in the agent’s knowledge space. In this phase, the agent is expected to directly utilize the existing knowledge to complete the tasks, rather than inferring a new task knowledge cluster in its prior space. We present the results after the first loop (circle markers) and after the second loop (cross markers) in Fig. 3f. The t-SNE results demonstrate that our proposed LEGION framework can infer and identify earlier acquired knowledge and merge it into existing cluster components associated with individual tasks.

a–e, t-SNE projection of knowledge space after training on two tasks (a), four tasks (b), six tasks (c), eight tasks (d) and all ten tasks (e). f, t-SNE projections after the first training loop (circle) and after the second loop (cross). Notably, the inference results of the second training loop are merged into corresponding knowledge groups that are preserved during the first loop.
Statistics
For a quantitative assessment of our proposed framework, we present the performance results in Table 1 of each task in both conventional multi-task and lifelong training processes. The evaluation for MTRL can lead to an in-depth understanding of our framework in terms of synchronized knowledge acquisition and preservation. In the context of lifelong learning, we utilize an easy-to-hard task ordering strategy, where the agent begins by learning fundamental tasks that serve as milestones for mastering more complex action patterns in subsequent tasks. For more details on other task ordering variations, refer to Supplementary Section 3.1. We report the success rates for each task (row-wise) after the agent trained on a one-time feeding task stream (column-wise). For example, the first column from the left side represents the agent’s performance on all tasks after it has trained on the task ‘reach’. Furthermore, we incorporate two additional metrics to evaluate the specific characteristics of our lifelong learnable agent, namely, ‘forgetting’ and ‘forward transfer’. ‘Forgetting’ is a scalar metric in the range [−1, 1], representing how much knowledge our proposed agent may forget at the end of its lifespan. A lower value in this metric signifies better performance. ‘Forward transfer’, in contrast, has a range of [0, 1] that considers how much the earlier tasks knowledge aids the subsequent tasks, where a larger value indicates better performance. For more details of these metrics, refer to equations (2) and (3). We also report our agent’s multi-task performance of each task listed in the right column of the table. Each datum in the table is based on trials with five random seeds. The last row calculates the average value of the data alongside column-wise. As indicated in the table, after being trained on earlier tasks, the agent maintains its performance on corresponding tasks even when trained with subsequent tasks. This implies that the acquired knowledge is effectively preserved within the model. The average success rate gradually increases, reaching 0.84. Furthermore, our proposed framework’s overall average forgetting score is 0.0, showcasing its robust knowledge preservation capability. We observe that negative scores occur on tasks such as ‘door open’; this is because the subsequent learning process enhances performance on previously learned tasks. For instance, after training on ‘door open’, the agent initially achieves a success rate of 0.4 on this task. However, after training on ‘faucet open’, the success rate for ‘door open’ improves to 0.8. This improvement is probably because the knowledge gained in understanding how to open a faucet (whether clockwise or anticlockwise) contributes positively to the door-opening task. In addition, positive forward transfer phenomena are observed in our agent’s lifelong learning process. Specifically, for the task ‘drawer close’, earlier acquired knowledge from tasks such as ‘push’, ‘pick–place’ and ‘door open’ contributes to the success of ‘drawer close’. For instance, the push and pull motions learned from previous tasks aid the agent in completing the drawer close task. The final average score of this metric is 0.10. In the context of a multi-task learning process, where the agent has simultaneous access to all tasks, our framework attains superior performance with a final success of 0.94 (Supplementary Sections 1 and 2).
Few-shot knowledge recall
Knowledge rehearsal is a critical component of lifelong learning. Recent studies, particularly in computer vision14,16,32,33, have shown that rehearsal effectively mitigates forgetting during the learning process. However, it remains unclear whether this technique performs as well in the robotic domain, where data are continuous and time sequential. In addition, recent biological research34,35,36,37,38,39,40,41 suggests that knowledge rehearsal aids in consolidating long-term memory and improves performance through deep memory recall, even after extended pauses (Supplementary Section 9). Building on these insights, we explore how our proposed agent performs during few-shot knowledge recall with only intermittent replay.
To demonstrate the application and potential limitations of existing replay-based lifelong learning methods in robotic reinforcement learning, we conduct comparison experiments against these baseline methods. All models use the same soft-actor–critic (SAC) policy, including the neural network backbone and shared hyperparameters. Each experiment is repeated at least five times, and the average success rate and standard deviation during evaluation are used as metrics to ensure fairness. The following baseline models are employed for comparison. (1) Reservoir. This baseline uses the ‘reservoir’ sampling method in the buffer to approximate the empirical distribution of observed samples. The buffer is designed to maintain a maximum data ratio of 50%. Unlike our framework, this model does not include an upstream inference and knowledge preservation module, so its policy network inputs consist of only the raw task observations without the upstream inference representations. This allows us to assess the strengths of our proposed Bayesian non-parametric knowledge space in task inference, knowledge preservation and its impact on overall task performance. (2) Perfect memory. Based on the ‘reservoir’ baseline, we extend the buffer size to match the total training steps, meaning that all past trajectories are stored without being forgotten or overwritten. (3) Averaged gradient episodic memory (A-GEM)14 is a rehearsal-based method that treats lifelong learning as a constrained optimization problem. It constructs a global loss based on old training samples to ensure no loss of performance on previous tasks, projecting new sample gradients to avoid interference. Here for each base task, we maintain an episode memory of 10,000.
Figure 4a shows the average success rate during evaluation. As seen in the figure, our proposed LEGION framework consistently outperforms other methods, demonstrating a steady increase in success rate as new tasks are introduced. While perfect memory maintains a full buffer, its success rate reaches around 0.2 throughout training, showing no obvious improvement, highlighting its limitations in adapting or generalizing as the task stream progresses. Similarly, reservoir shows a flat performance curve with no notable gains, and A-GEM also underperforms in our benchmark. To further illustrate the limitations of replay-based methods in robotic LRL, Fig. 4b visualizes the data ratio in the training batch. For instance, after training on the second task ‘push’, the data ratio for ‘push’ initially remains at around 50%. However, as the agent moves through subsequent tasks, this ratio gradually decreases, eventually dropping to around 10% by the end of training. In contrast, in MTRL, the agent trains on individual tasks with a constant data ratio in the batch, ensuring stable learning conditions. This gap in the data sampling process during lifelong learning may weaken knowledge retention and lead to overall performance degradation over time. Our framework addresses this challenge by utilizing a Bayesian non-parametric knowledge inference and clustering module, which ensures consistent knowledge preservation and stable performance throughout the lifelong learning process despite fluctuating data ratios.

a, The average success rates from five runs of the LEGION framework compared with three replay-based lifelong learning methods: perfect memory, reservoir and A-GEM. The figure shows that LEGION consistently outperforms these methods, demonstrating a steady increase in success rate throughout the task sequence. b, Evolution of the ‘push’ task data ratio within the training batch. While the batch size remains constant, the data ratio for the ‘push’ task gradually decreases from an initial maximum of 50% to 10% after learning 10 tasks. c–g, Few-shot knowledge-recall performance on reach (c), push (d), faucet open (e), button press (f) and window close (g). The agent is trained sequentially on five selected tasks over three repeated loops, with buffer capacity limited to three tasks at a time. This configuration forces the agent to pause on each base task for 1 million steps without replay. For a and c–g, the data are calculated based on at least five trials, presented as mean ± standard deviation (μ ± σ).
To assess our agent’s knowledge-recall performance after pausing on tasks for a while, we selected 5 tasks from our original sequence, ordered from easy to hard, and trained the agent on them sequentially (1 million steps for each task) across 3 repeat loops: ‘reach → push → faucet open → button press → window close’. In the replay buffer, we allocated space for data from only three tasks at a time. This set-up means that while training on the fourth task, data from the first task are gradually replaced by data from the fourth, and by the time the fifth task is reached, replay data from the first task are no longer available. In the second loop, we revisit the first task and compare its performance in the second loop to that in the first. This process is repeated similarly for the other tasks during the second and third loops. Extended Data Fig. 1 shows the t-SNE projections of the knowledge space after each task learning for all three loops. Figure 4c–g shows the average success rates for each task during the first loop (orange) and the subsequent second (green) and third (blue) loops. As illustrated, despite a 1 million-step pause for each task, the agent quickly re-masters them in the second and third loops, surpassing its initial performance. Our framework demonstrates faster convergence on all tasks during subsequent loops, following few-shot attempts, emphasizing the benefits of few-shot memory recall. This mirrors the biological theory of mnemonics, where knowledge retention supports task re-mastery. Specifically, in the ‘reach’ task, despite the enforced pause, the agent consistently maintains knowledge, achieving a success rate of 0.3–0.4 at the initial evaluation checkpoint. Moreover, the agent shows an average success-rate improvement of 0.2 in the final loop compared with its initial attempts. After few-shot knowledge recalls in the third loop, the framework reaches the maximum success rate on most tasks. This improvement is attributed to effective deep memory recall enabled by our framework leveraging the DPMM.
To quantify the improvement in few-shot knowledge recall, we calculate the improvement percentage for each task (Extended Data Table 2) using equation (4). The results show that the improvement varies across tasks: 19.63% for ‘reach’, 6.66% for ‘push’, 16.77% for ‘faucet open’, 9.94% for ‘button press’ and 6.78% for ‘window close’ between the first and second loops. Moreover, comparing the first and third loops reveals even greater success-rate enhancements. On average, our framework shows an 11.96% improvement between the first and second loops and a substantial 21.36% improvement from the first to the third loop. These findings highlight our framework’s strong capability for effective knowledge recall, rapid adaptation and improved task performance through few-shot exploration. The consistent improvement across multiple tasks underscores its robustness in re-mastering tasks and maintaining high success rates, showcasing the potential of our framework, especially the DPMM knowledge space for advancing LRL.
Discussion
Robotic lifelong learning focuses on acquiring and retaining knowledge from a continuous stream of tasks, enabling agents to progressively build more complex behaviours through knowledge integration and reuse. Our study presents a deep reinforcement learning framework that continuously accumulates knowledge from a stream of tasks, demonstrating human-like lifelong learning capability. In addition, it solves complex long-horizon tasks by combining and reapplying acquired skills, a key step towards achieving general intelligence.
In our real-world experiment with a KUKA robot arm, our agent, aided by real-time vision from a RealSense camera and language embeddings from an LLM, successfully completes a sequence of tasks, efficiently accumulating knowledge and demonstrating flexible, autonomous skill reapplication for long-horizon tasks without relying on predefined human demonstrations. In our LRL framework, we analyse knowledge management through both visualization and statistical perspectives. The non-parametric model in the knowledge space dynamically adjusts to new task inputs by creating or merging components, ensuring continuous knowledge preservation without prior knowledge quantity requirements. Quantitatively, the agent’s success rate improves over time, demonstrating effective knowledge accumulation in LRL.
In summary, our framework LEGION (details refer to Fig. 5) excels at both preserving knowledge and inferring new tasks in its Bayesian non-parametric knowledge space during lifelong learning. Using language embeddings to aid in task inference, the agent can efficiently undertake long-horizon tasks, showcasing flexibility in addressing complex tasks based on accumulated knowledge. We acknowledge that the replay mechanism is an inherent part of our framework due to its use of SAC as policy, which relies on data sampling from a buffer and offline parameter updates. However, the replay is not strictly tied to our approach using the Bayesian non-parametric knowledge space, but rather a feature of the SAC itself. Our framework currently shows substantial improvements in few-shot exploration with intermittent replay. In the future, we plan to optimize it further to better balance stability and adaptability without relying on replay buffers, while also aiming to tackle more challenging scenarios such as zero-shot inference. Meanwhile, we acknowledge that our current framework operates in structured environments with predefined task set-ups and relies on AprilTags for perception. In future work, we aim to expand our framework to unstructured, dynamic environments featuring diverse object arrangements and unseen objects, with the goal of enhancing the generalization and robustness of lifelong learning systems. In addition, we plan to explore applying our non-parametric knowledge space to robot learning involving multiple agents or heterogeneous embodiments (Supplementary Section 3.5), intending to achieve clustered and transferable general intelligence. As our current work assumes the reward function to be an inherent and static property of the environment, another promising future direction involves using LLMs42,43,44 for continuous reward refinement during the lifelong learning process. This would enable agents to quickly adapt to entirely new control tasks. Moreover, the ability to continuously learn and preserve skills from a stream of tasks using a non-parametric knowledge space, combined with smooth and stable downstream action outputs from the diffusion model, holds potential for the development of broadly applicable large behaviour models.
Methods
Training and deployment
Training
Figure 5 a illustrates the concept overview of our proposed LEGION framework. Unlike the typical multi-task approaches, where the agent learns all tasks at once, our proposed framework can continuously gain knowledge from a stream of one-time feeding tasks. This implies that our agent can imitate the real human learning process, tackling each manipulation task one after another throughout its lifespan.
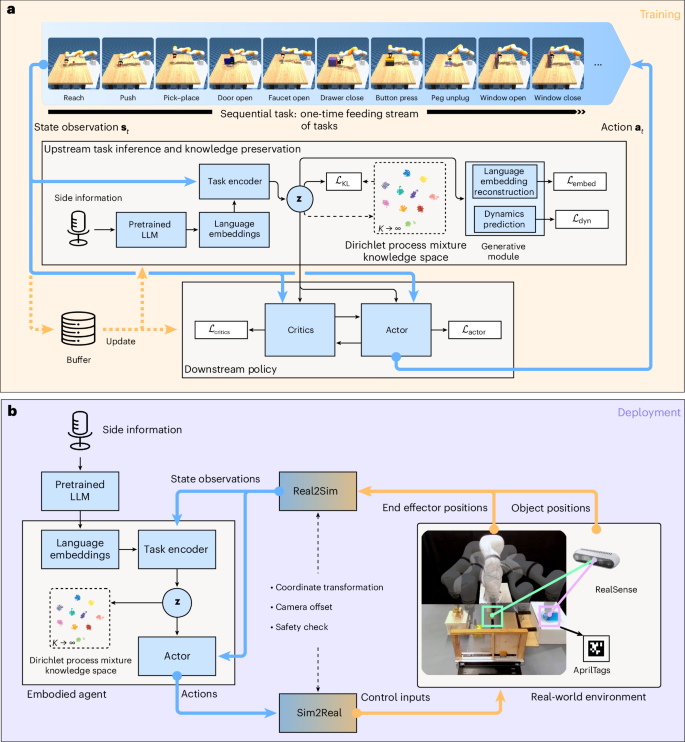
a, Training. The framework receives language semantic information and environment observations as input to make policy decisions and output action patterns, it trains on only one task at a time. ({mathcal{L}}) represents the loss functions and is explained in ‘Upstream task inference’ in Methods. b, Deployment. In the real-world demonstration, the agent parameters remain frozen, the agent receives input signal from real-world hardware and outputs corresponding action signals, both ‘Sim2Real’ and ‘Real2Sim’ modules process the data to align the gap between the simulation and real world.
During training, we let the agent learn tasks one by one, allowing the agent to undergo 1 million training steps for each task. Importantly, we evaluate the agent’s performance on all tasks every 10,000 steps by following the conventional multi-task fashion, irrespective of whether it has undergone training for these tasks or not. In our framework, we follow the off-policy training mode as it has more sampling efficiency. To achieve both preserving existing knowledge and inferring new tasks simultaneously, our proposed framework is structured hierarchically into two parts, namely, the upstream task inference and knowledge preservation module and the downstream policy learning module. The upstream module consists of the following components: the pre-trained language embedding module, the task encoder, the Dirichlet process mixture knowledge space, and the generative modules. In the simulation, we employ an offline approach where language embeddings are pre-encoded using an LLM combined with an audio recognition device and stored for training. This pre-processing step accelerates training by eliminating the need for real-time encoding, which is computationally intensive. For specific details regarding the content of the language side information, refer to Supplementary Section 7. Subsequently, the task state observations s, which include positions of end-effector, objects and goals, are combined with the current task’s language embedding I and sent to the task inference encoder. Following that, the generated inference results z are fitted by the DPMM within the knowledge space. The inferred results from the same task are clustered and stored within the same components in the DPMM, enabling knowledge preservation in our framework. When dealing with data samples from new task distributions, the DPMM can create new components to accommodate them, thereby separating them from existing clusters and supporting continual knowledge accumulation during agent lifelong learning. Simultaneously, the generative module reconstructs the language embeddings and predicts the dynamic function of the current task. This enables disentangled parameter updates between upstream and downstream modules. Moreover, an ablation study in Supplementary Section 3.4 demonstrates that the generative module plays a crucial role in stabilizing the lifelong learning process. For the downstream policy module defined in Fig. 5a, we utilize the SAC45 as a concrete policy learning module, where the critics calculate the action value function Q(st, at, zt) and the actor provides the corresponding action patterns at to accomplish the tasks. The inferred task results are conditioned as part of downstream inputs, contributing to more precise action pattern learning. The detailed structures of individual modules are introduced in Supplementary Section 4.
Deployment
After training in simulation environments, we implement our trained agent onto a real-world KUKA manipulator to build up an embodied lifelong learning agent. The real-world deployment overview is illustrated in Fig. 5b, where the framework includes two primary components: the embodied agent software side and the real-world hardware side. On the software side, we deploy the trained task encoder, DPMM and downstream actor to create the embodied agent. In the real-world demonstration, we utilize an online encoding approach, where human commands are processed and encoded as language embeddings to execute each task. This set-up reflects real-world usage, allowing users to issue verbal commands directly to the robot. For the hardware side, our agent’s physical body comprises a KUKA iiwa with a Robotiq 2F85 gripper. In addition, we utilize a global RealSense camera at the table edge to capture object positions via AprilTags. Later, the task-related goal position is determined by the initial position of the detected object and the corresponding side information context. Python-based robot operating system controls the movement of the KUKA, with a system frequency of 20 Hz. We limit the total work steps of a single-task trajectory to 150, maintaining consistency with simulation environments. To ensure smooth communication between the software and hardware control, we employ two transformation modules, namely, ‘Sim2Real’ and ‘Real2Sim’. These modules serve similar purposes, including safety control checks, coordinate frame transformation between simulation and the real world, hand-to-eye calibration, and camera offset set-up. A detailed experiment set-up for both simulation and deployment can be found in Supplementary Section 5. Moreover, we provide Supplementary Video 4 to introduce the implementation details of our framework for both training and deployment processes.
Language embedding
The manipulation tasks performed by a robot arm show a natural tendency towards a limited set of action patterns. On the one hand, tasks like ‘push the teacup from left to right’ and ‘open the window in a horizontal direction’ may differ in their language description, but their actual action patterns might share similar trajectories. This similarity can pose challenges during agent training, leading to inaccurate action patterns and/or misoperations in real-world performance. On the other hand, although such task-related contextual information (or side information) is often available in real-world scenarios (for example, between human communication), it is frequently overlooked in conventional reinforcement learning methods and is difficult to provide to the embodied agent without encoding of a LLM. By leveraging advancements in LLMs3,31, our embodied LRL agent becomes more adept at utilizing this side information, like natural language-based task descriptions, to acquire generalizable skills and facilitate knowledge transfer among tasks22. In this study, we capture natural language side information through an external speech-recognition device. We adopt a human-in-the-loop approach to guide the embodied agent in real-world tasks. In our case, we employ one of the state-of-the-art pre-trained LLMs, RoBERTa31, to encode the side information about manipulation tasks into language embeddings. Subsequently, these embeddings are conditioned with state observations and provided to the agent, aiding in accurate task inference and improving its execution of corresponding action patterns.
Observation space
The state observation space includes the end-effector position (three dimensions), the object pose (six dimensions) and the goal positions (three dimensions). We encode the language side information related to the task context with a pre-trained RoBERTa model, whose output has 768 dimensions.
Action space
The action space contains four dimensions, including the movement of the end-effector tip (units expressed in metres) and the open distance of the gripper. The upper and lower bounds for each dimension of action space are limited within the range [−1.00, +1.00].
Reward
Our designed scenarios involve goal-based manipulation tasks where success is determined by bringing the target object within a specified goal range. To comprehensively evaluate action patterns, the global reward for tasks is divided into distinct components. These components include rewards for reaching, grasping, pushing, pulling and pressing objects to achieve the specified targets or poses. For more details, refer to Supplementary Section 8.
Optimization
Both the upstream task inference module and downstream policy learning module are trained using Adam optimizers, and we reset the intrinsic parameters of optimizers before initiating the training on every new incoming task.
Metrics
Recent works in the conventional multi-task or meta-learning-based approaches often rely on metrics based on reward and/or success rate to evaluate agent performance. However, in the context of LRL, typical questions still remain unclear, including how much the agent may forget the previously acquired knowledge after training on subsequent tasks, or to what extent the previously acquired knowledge can aid the subsequent ones. Therefore, it becomes necessary to employ additional metrics that capture the unique characteristics of lifelong learning fashion. In our study, in addition to the success rate, we adopt two well-used metrics to access our proposed LRL framework, namely, ‘forgetting’ and ‘forward transfer’. To further evaluate the performance of few-shot knowledge recall, we employ a normalized ‘improvement’ metric to quantify the agent’s performance. Assuming a total of N tasks, and considering that the agent undergoes training for each task over a span of Δ steps, the cumulative global training duration across all N tasks amounts to T = N × Δ steps.
Average success rate
In our study, as all our environments are goal-based manipulation tasks, we select the task’s success rate as one of the evaluation metrics. Here, Pi(t) signifies the success rate of task i at time step t. The values Pi(Δ(i − 1)) and Pi(Δi) denote the success rates of task i before and after training on the same task, respectively. The overall average performance on all N tasks is calculated as follows:
Notably, P is constrained within the range [0, 1]. We also employ P(T) for the final evaluation, particularly for the purpose of hyperparameter optimization and ablation study. A higher value of P corresponds to an improved performance. Moreover, we also consider the episode rewards as one of our metrics, for more details related to the rewards comparison, refer to Supplementary Sections 1 and 2.
Forgetting
This metric quantifies how much knowledge is forgotten after the agent is trained on subsequent tasks. Drawing upon recent research contributions6,46, we introduce the forgetting (F) to assess the agent’s capacity to preserve knowledge within a continuous stream of tasks. Specifically, Fi is calculated by subtracting the final success rate of task i, denoted as Pi(T), from the success rate of task i after training on the task itself, represented as Pi(Δi). The overall forgetting metric is computed as follows:
Notably, evaluating the forgetting of the most recently encountered task carries limited significance. Therefore, we consider only the first N − 1 tasks for this calculation. The forgetting metric is constrained within the range F ∈ [−1, 1]. When F > 0 represents that the agent may have lost knowledge of prior tasks. Conversely, when F < 0, the backwards transfer occurs, signifying that training on subsequent tasks j (with i < j ⩽ N) has led to an improvement in performance on prior tasks i. For the F, a lower value indicates superior performance.
Forward transfer
Forward transfer (FT) assesses the extent to which previous tasks contribute to the learning of new ones. Inspired by recent works1,6, we define the zero-shot forward transfer metric as follows:
Here, the metric range is constrained to FT ∈ [0, 1], where the forward transfer for the 𝑖-th task is calculated as the average performance across tasks from 𝑘 = 1 to 𝑘 = 𝑖 − 1. It is important to emphasize that evaluating the first task holds no meaningful significance. Thus, we consider a total of N − 1 subsequent tasks for this assessment. A higher value in this metric indicates that knowledge acquired from earlier tasks aids the agent in enhancing its performance on subsequent tasks, reflecting better performance.
Improvement of few-shot knowledge recall
To quantify the improvement statistics in few-shot knowledge recall, we calculate the improvement percentage for each task as follows. First, we computed the integral of the agent’s success rate of selected two loops for each task. We then subtracted the integral from the earlier loop from the subsequent loop and normalized the difference. This normalized value, denoted as f (in the range [−1, 1]), serves as our evaluation metric for few-shot improvement. A higher value indicates better performance during the subsequent loops compared with the earlier access, whereas a lower value suggests the opposite. The specific calculation is detailed in equation (4):
where Pmax indicates the best performance value that the agent can acquire (in our case, the success rate with 1.0), P(t) denotes the performance value over time, and t and T are the lower and upper bounds, respectively, of training steps with j > i.
Non-parametric knowledge space
In this section, we present our non-parametric knowledge space from two aspects. First, we introduce the mathematical theory behind the Dirichlet process mixture model. Following that, we introduce an online variational inference method of DPMM that is used to update the model parameters.
Dirichlet process mixtures
Bayesian non-parametric models are a class of models that allow for flexible modelling of complex data structures without making strict assumptions about the underlying distribution of the data. Unlike Bayesian parametric models (for example, Gaussian mixtures), which have a fixed number of parameters, Bayesian non-parametric models have a potentially infinite number of parameters that are determined by the data. Bayesian non-parametric models are typically based on probabilistic models that involve prior distributions over model parameters. Such prior distributions are often chosen to be flexible and allow for infinite-dimensional parameter spaces. This allows the model to adapt to the underlying structure of the data, whether it is simple or complex. One of the typical non-parametric models is the Dirichlet process mixture model, whose parameters are determined through the Dirichlet process. The Dirichlet process is a probability distribution over probability distributions. It is used in Bayesian non-parametric to model data when the number of groups or clusters is not known a priori. Let G be a random probability measure, ({mathcal{H}}) be a base probability distribution from a parameter space Θ, and α be a positive real-valued scalar named concentration parameter. Then, G is said to be drawn from a Dirichlet process (DP) with α and ({mathcal{H}}), denoted as (G sim ,text{DP},(alpha,{mathcal{H}})). To generate the samples from a Dirichlet process, a method called the stick-breaking process is employed (Supplementary Section 10).
DPMM serves as a prominent model in the Bayesian non-parametric domain that is used to capture an infinite mixture of clusters for modelling a set of observations x = x1:N. Unlike finite mixture models in the Bayesian parametric domain, the number of components in DPMM is not predefined, but rather determined by the observations in an online fashion. In DPMM, each data xi is sampled from a distribution ({mathcal{F}}({theta }_{i})), where θi represents a latent variable independently drawn from a Dirichlet process prior G-based base distribution. A Dirichlet process prior introduces discreteness and clustering properties by allowing θi to take on repeated values. Consequently, all data points drawn with the same value of θi form a cluster, resulting in the natural clustering of observations. The active number of cluster components is determined by the number of unique values of θi, which can be dynamically inferred based on the observed data. To assign data points to clusters, each point is associated with an assignment variable vi. This variable takes on the value k with probability πk, which is drawn from a categorical distribution (Cat). The generative process of DPMM can be expressed using the stick-breaking process (Supplementary Section 10.1), where the mixing proportions π can also be equivalently expressed as sampled from a generalized Ewens distribution (GEM). Specifically, the generative process of DPMM can be represented as follows:
Variational inference
In this study, we focus on a variational inference-based method to estimate the true posterior of data, as they tend to offer faster and more scalable solutions compared with sampling-based methods. The fundamental concept behind variational inference is to transform the inference problem into an optimization problem. Subsequently, the aim is to uncover the underlying joint probability distribution of the unknown parameters, allowing us to explore their implicit relationships. In the case of the DPMM, as described in equation (5), the joint probability distribution of its parameters can be expressed as follows:
where ({mathcal{B}}) is stick-breaking process probability and βk are corresponding random variables. As the true posterior p(v, θ, β∣x) is intractable, the objective is to identify the optimal variational distribution q*(v, θ, β) that minimizes the Kullback–Leibler (KL) divergence from the exact conditional distribution. Instead of directly minimizing the KL divergence, we maximize the evidence lower bound (ELBO) which includes the expected log-likelihood of the data ({mathbb{E}}[log p({bf{x}}| {bf{v}},{bf{uptheta }},{bf{upbeta }})]) and the KL divergence between two priors ({mathbb{KL}}(q({bf{v}},{bf{uptheta }},{bf{upbeta }})| | p({bf{v}},{bf{uptheta }},{bf{upbeta }}))). Here, we have (Supplementary Section 10.2):
In the context of DPMM, grounded in the concept of variational inference, we formulate the variational distribution q under the mean-field assumption, where each latent variable possesses its variational factor, and these factors are considered independent from one another. Specifically, we have:
where ({q}_{{v}_{n}}) is a categorical factor with variational parameters ({hat{r}}_{nk}), ({q}_{{beta }_{k}}) is a factor for stick-breaking proportion with parameters ({hat{alpha }}_{{k}_{0}},{hat{alpha }}_{{k}_{1}}), and ({q}_{{theta }_{k}}) is a base distribution factor with parameters ({hat{lambda }}_{k}). In the context of variational inference, it is fundamental to recognize that the true posterior distribution is inherently infinite, and obtaining an exact representation is unfeasible, hence necessitating approximations. However, by augmenting the number of components K within the categorical factor, we can enhance the optimization of the ELBO objective, leading to a variational distribution that closely approximates the infinite posterior. To maintain computational tractability, we restrict the categorical factor to a finite set with K components (q(vn = k) = 0 for k > K), ensuring that K is sufficiently large to encompass all potential features. Furthermore, we explore a specific scenario in which both the base distribution ({mathcal{H}}) and the cluster component distribution ({mathcal{F}}) come from the exponential family. Hughes and Sudderth30 illustrated that in this context, it is possible to formulate the ELBO in terms of the expected mass ({hat{N}}_{k}) and the expected sufficient statistic sk(x) associated with each component k:
Subsequently, each variational factor can be iteratively updated independently. In the initial stage, we perform updates on the local variational parameters ({hat{r}}_{nk}) within ({q}_{{v}_{n}}) for each clustering assignment. Following this step, we advance to the update of the global parameters within the stick-breaking factor ({q}_{{beta }_{k}}) and the base distribution factor ({q}_{{theta }_{k}}). We employ this coordinate ascent method to iteratively optimize the local and global parameters with the objective of maximizing the ELBO. The computation of the summary statistics ({hat{N}}_{k}) and sk(x) requires accessing the complete dataset. In the case of large datasets, a batch-based approach known as memoVB30 is employed. This approach breaks down the summary statistics of the full data into a summation of the summary statistics of each batch. The non-parametric nature of the DPMM allows for flexibility in adapting to varying numbers of clusters. This characteristic enables the development of heuristics for dynamically adding or removing clusters, which proves beneficial in avoiding local optima when utilizing batch-based variational inference methods. For detailed derivations, refer to Supplementary Section 10.2.
MemoVB incorporates birth and merge moves to facilitate dynamic cluster adjustment. To create new clusters, poorly described subsamples x′ from one existing cluster are collected as they pass through each batch, and a separate DPMM model with K′ initial clusters is fitted. Assuming that the active number of clusters before the birth move is K, the acceptance or rejection of new cluster proposals is determined by comparing the result of assigning x′ to K + K′ with that of assigning x′ to K. In addition to the birth move, a merge move can potentially combine a pair of clusters into one. The decision to merge two clusters is based on whether the merge improves the ELBO objective, resulting in K − 1 clusters after the merge30. By integrating with this online inference method, the DPMM can consistently preserve the gained knowledge in the knowledge space from a theoretically endless stream of data, where the features or knowledge within it may steadily grow. For more details, refer to Supplementary Section 10.3.
Upstream task inference
In this section, we introduce the derivations behind our upstream task inference module (Fig. 5a). We start with the knowledge inference and preservation process of our knowledge space. Subsequently, we introduce the generative process of upstream modules that enable the disentangled and stabilized learning process.
Knowledge inference and preservation
To enable simultaneous knowledge inference and preservation in the knowledge space, we employ a DPMM + memoVB that was introduced in the previous section. The DPMM + memoVB has the advantage of being able to cluster a potentially infinite number of features based on the observations, while dynamically adapting to fit the number, shape and density of individual components. This dynamic adaptability holds great potential for preserving knowledge in a continuous stream of tasks.
Our framework employs an alternating optimization scheme to eliminate the necessity of fitting a new DPMM from scratch every time. First, we update the DPMM module using the inference result zi, which are sampled from the task encoder. Each update of the DPMM module takes place after certain training steps of the task encoder and generative module. Then, with the DPMM module fixed, we update the task encoder by minimizing the KL divergence, using the assigned clusters to each zi.
When updating the parameters of the DPMM, we perform fitting on the task inference result zi obtained from the task encoder. Consider a set of state inputs ({{{{boldsymbol{x}}}_{i}}}_{i = 1}^{n}in X) with xi = (si, Ii), the DPMM module in the knowledge space learns: (1) the inference results zi and corresponding mapping between xi and zi; (2) the number of K active components and their parameters ({{{{bf{upmu }}}_{k},{{mathbf{Sigma }}}_{k}}}_{k = 1:K}); and (3) the cluster assignment vi of each input, where vi ∈ {1, …, K}. The cluster assignments of inference results are determined jointly by the latent representation and the DPMM components. In each update, we initialize the DPMM with the parameters learned from the previous updates and apply it to new samples generated by the updated task encoder. This enables us to update the same DPMM while incorporating the latest changes in the knowledge space mappings.
During the training of the task inference module, we aim to minimize both the generative loss ({{mathcal{L}}}_{{mathrm{gen}}}) and the KL divergence loss ({{mathcal{L}}}_{{rm{KL}}}) in a joint manner. ({{mathcal{L}}}_{{mathrm{gen}}}) measures the error between the original inputs x and the generated samples x*. Meanwhile, ({{mathcal{L}}}_{{rm{KL}}}) represents the KL divergence between task encoder distribution and knowledge clustering components. To compute ({{mathcal{L}}}_{{rm{KL}}}), we first obtain the cluster assignment vi = k of each task inference results zi from the current DPMM. Using the DPMM, we determine the mean and covariance of the assigned cluster k, denoted as μk and Σk respectively. Following that, the ith inference result assigned to the component k, which is represented as zik, is generated through the reparametric trick47. Notably, the hard assignment between the inference result and corresponding cluster component in knowledge space may lead to incorrect assignments for certain samples, resulting in errors when calculating the KL divergence. To address this issue, we propose the use of a soft assignment, in which we compute the probability pik of assigning the zi to cluster k using the DPMM, considering all possible components k ∈ {1, 2, …, K}. As a result, the KL divergence is defined as a weighted sum, taking into account the probabilities of each cluster assignment:
where ({{mathcal{L}}}_{{{rm{KL}}}_{ik}}) indicates the KL divergence between the distribution of task encoder output and component k in DPMM, and pik represents the probability of zi assigned to cluster component k. While more sophisticated weighting strategies can be employed, our empirical findings suggest that simple weighting based on probabilities is effective. For detailed derivations, refer to Supplementary Section 11.1.
Generative process
In our framework, we employ a generative module at the upstream level to facilitate a disentangled and stabilized learning process. The generative module includes two distinct components: the language embedding generation, denoted as pθ(It∣zt), and the dynamic prediction model for corresponding manipulation task, represented as pθ(st+1∣st, at, zt). Each component is interpreted by a separate multilayer perception module with general parameters θ ∈ {θembed, θdynamics}. The detailed structures of our proposed generative modules are presented in Supplementary Figs. 18 and 19. During the training process, the language embedding decoder takes only the task inference results zt as inputs and generates the language embedding tokens, donate as I*. These tokens are then combined with the original inputs I to compute the overall similarity using the sum of mean squared error as the side information loss function, denoted as ({{mathcal{L}}}_{{mathrm{embed}}}). Furthermore, the dynamics prediction module models the state transition function by taking the current state observation st, normalized action vector at, and latent variables as inputs to generate the expected state observation at the next step, denoted as ({{bf{s}}}_{t+1}^{* }). By comparing this prediction with the actual next observation st+1, we obtain the loss function for dynamic prediction, which is represented by ({{mathcal{L}}}_{{mathrm{dyn}}}). Meanwhile, with normalization in each input dimension, we can stabilize the overall training process. Following that, the total loss of the upstream task inference module is calculated as follows:
with ζ and η representing the weighting factors for each loss function term, which regulate the importance of each generative module. ξ represents the disentangled factor of the KL divergence term. In summary, the generation module facilitates a disentangled learning process unaffected by downstream policy training. This set-up stabilizes the exploration process of the downstream policy module, particularly during the initial steps of each task where noise is inevitable. Simultaneously, regenerating language embeddings and modelling the state transition function contribute to the agent learning more accurate action patterns for individual manipulation tasks. For detailed derivations of the loss functions related to the generative process, refer to Supplementary Section 11.2.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Responses