A global dataset of average specific yield for soils

Background & Summary
Specific yield (Sy [-]) is pivotal in groundwater researches, delineating the capacity for groundwater gain or loss with water table fluctuations. It serves as a key factor in converting groundwater storage changes (GWSC) to groundwater level changes (GWLC) in Earth System Models (ESMs), Land Surface Models (LSMs), Gravity Recovery and Climate Experiment (GRACE) data application1, and other groundwater related studies2,3 (the key abbreviations used in this study are listed in Table 1). Particularly, besides its significance in groundwater modeling, Sy is also of crucial importance for revealing the global distribution of groundwater resources, as well as enhancing the climate change studies, because groundwater is a vital component of climate system and is essential in sustaining the global adaptation to climate variability and changes4,5,6. However, uncertainties in Sy determinations are a primary source of error in water table simulations7,8,9,10,11,12,13,14,15,16.
Sy varies spatially and temporally, and is primarily influenced by soil texture, water table depth, and duration17, while also affected by other factors such as the temperature and chemical composition of water, the antecedent soil moisture condition, etc. Specifically, according to Johnson18, Sy typically ranges from 0 to 0.5 for different soil textures, with coarser textures yielding higher values. Since the water in the soil medium does not move instantaneously, the shorter the accumulated duration, the smaller the Sy value, and in this case, it is called as the transient Sy which is usually estimated through pumping tests or other field methods17. Moreover, the soil near the water table will first reach the static equilibrium state or drain completely, because the capillary fringe can supply sufficient water for the soil medium near the water table. It would take a long period of time, potentially several months or years, to reach static equilibrium or drain completely for one soil column, e.g., it would take more than one year for a 1.71-m-long medium-sand column to reach static equilibrium, but the equilibrium state in the bottom 0.6 m can be attained after five hours19. When sufficient time is allowed to drain completely or reach the static equilibrium state, Sy depends on water table depth due to the effect of capillary fringe, known as the apparent Sy. Once the water table reaches a certain depth, related to soil texture, such as 1 m for sand10,20, Sy stabilizes at a ultimate value (a constant for a soil type), and it is referred to as the ultimate Sy. Note that, the ultimate Sy is obtained only when the water table is deep enough and sufficient time is allowed to reach the static equilibrium condition or drain completely, and the ultimate Sy is typically determined through laboratory experiments, equating to porosity minus specific retention18,21,22,23,24. Consequently, due to the high spatiotemporal variability, for the same soil type, the Sy values under different situations (water table depth, time duration, etc) estimated by different methods vary considerably, even for a given study site. However, the Sy estimation remains largely uncertain due to methodological limitations, with no widely accepted approach, particularly at a regional scale25,26,27. Moreover, using point-scale Sy data to represent regional-scale variations is challenging, due to the absence of spatially distributed Sy data, especially for global simulations. According to the authors’ knowledge, there is no recognized global spatially-distributed Sy data publicly available to date, and we can only find one set of global Sy which unfortunately is not published data and just serves as inputs to the GLOBGM model28 itself (details in the following section of Methods). Due to these challenges, Sy determinations in LSMs and ESMs are simplified, introducing uncertainties in groundwater simulations. A uniform empirical constant is commonly used for convenience in global simulations, for example, models like MATSIRO-GW, Noah-MP, and CLM utilize a constant specific yield, but it fails to capture the variability among soil textures worldwide. To address these challenges, building on previous work by Lv et al.17, this study aims to produce a global dataset of spatially distributed Sy based on Johnson’s18 trilinear graph and three popular soil texture datasets. Because the existing soil texture datasets are all depth-limited, the global Sy data obtained based on them are correspondingly depth-limited, but readers can expand it into deeper soils by making a reasonable assumption about the vertical variation of soil texture with depth, since the Sy value is directly and positively correlated with the sand content and negatively correlated with clay content. It shows promise in generating a reference dataset of global gridded Sy, thereby improving future modeling of groundwater dynamics in ESMs/LSMs, and benefiting for understanding the groundwater resources distribution and mitigation of climate change impacts.
Methods
Performance metrics
In order to assess the match degree between the global Sy data produced in this study and the existing references results, this study used three evaluation indices. They are the correlation coefficient (CC), the ratio of the standard deviation to the reference (RSD), the unbiased root mean square error (RMSE).
where ({x}_{i}) and ({y}_{i}) respectively represent the data that need to be validated and the reference data; (overline{x}) and (overline{y}) denote the averages of ({x}_{i}) and ({y}_{i}), respectively; and N is number of the data points.
The trilinear graph
The trilinear graph, introduced by Johnson18, elucidates the correlation between Sy values and soil texture classifications based on sand, clay, and silt percentages (Fig. 1a). Comprehensive details regarding this graph can be found in our prior work by Lv et al.17. Note that, as above-introduced that all methods have limitations, for the trilinear graph, it compiled Sy values obtained by various methods, but with no attention paid to the effects of soil compaction, anisotropy, local heterogeneity, stratigraphic heterogeneity, the chemical composition of water, etc. Overall speaking, with knowledge of just two of the sand, clay, and silt percentages, one can determine the corresponding Sy value using this graph, rendering it a cost-effective, time-saving, and user-friendly tool17. For instance, Richey et al.29 utilized it to estimate Sy for 37 groundwater aquifers globally.

The trilinear graph of Johnson (a) and the data points automatically extracted by the GetData Graph Digitizer software (b).
Importantly, the Sy values used to construct this trilinear graph were derived from both laboratory and field methods18 under different situations of water table depth, time duration, heterogeneity, etc, indicating that Johnson’s18 trilinear graph likely represents an average value for a given soil texture type, falling between the ultimate Sy and the transient Sy. Consequently, Johnson’s18 trilinear graph holds promise for creating a reference dataset of Gridded Average Specific Yield (hereinafter GASY) for all soil texture types. Interested readers can delve into Johnson’s18 study for further insights. With these advantages in mind, we employed this trilinear graph in our study to generate the gridded average Sy globally.
We first used the GetData Graph Digitizer software to automatically extract the trilinear graph’s Sy values under the sand and silt/clay axes (Fig. 1b), and then employed multiple linear regression to establish the equation linking the extracted Sy values with the sand and silt percentages. It was found that, the optimal choice of fitting formula is to first use a fifth-order polynomial (Appendix 1(a)) to perform the global Sy calculation, and subsequently recalculate the values that fall outside the reasonable range of 0 to 0.5 using a third-order polynomial (Appendix 1(b)). The resulting fitted equations demonstrated a high CC of 0.997 with the extracted data points. Leveraging the fitted equations and global soil texture data, we created the GASY data for different soil textures on a global scale. The conceptual flow chart of this study is provided in Fig. 2. Interested readers can also use the trilinear graph in conjunction with artificial intelligence, e.g., the artificial neural networks30.
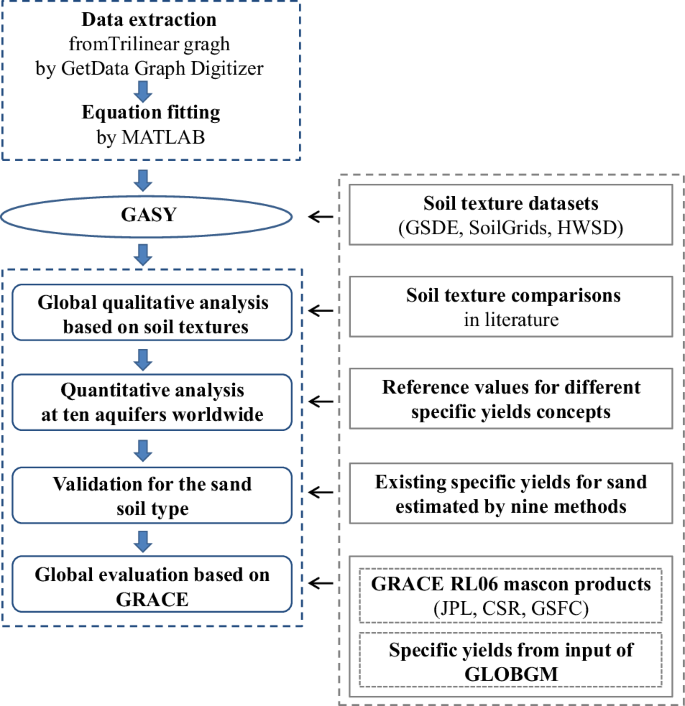
Flowchart of this study.
Datasets used in validation
To conduct a comprehensive validation and comparison with existing Sy data in the literature, and to address the requirements of different LSMs or ESMs with multi-layered soil representations, we selected three current widely-used soil texture datasets providing information for multiple layers. These datasets are the 30 seconds Global Soil Dataset for Earth System Models (GSDE)31,32, the SoilGrids 1-km product (hereinafter SoilGrids)33,34, and the 0.5 degree Harmonized World Soil Database V1.2 (HWSD)35, which make it also possible to assess the impact of spatial resolution. The HWSD amalgamates regional and national updates of soil information globally, along with data from the FAO and United Nations Educational Scientific and Cultural Organization (FAO-UNESCO) Digital Soil Map of the World, providing topsoil (0–30 cm) and subsoil (30–100 cm) texture data. The GSDE is derived from an enhanced mapping framework of the HWSD, and it extends the depth and number of soil layers relative to the HWSD, offering eight soil layers with a total depth of 2.296 m. The depths for these eight layers are 0.045, 0.091, 0.166, 0.289, 0.493, 0.829, 1.383, and 2.296 m, respectively. On the other hand, the SoilGrids, developed by the ISRIC using the Global Soil Information Facilities, provides data at seven depths of 0, 0.05, 0.15, 0.3, 0.6, 1, and 2 m. The Sy data corresponding to these datasets are labeled as GASY–GSDE, GASY–SoilGrids, and GASY–HWSD, respectively. It is important to note that readers have the flexibility to choose their preferred soil texture data based on their specific research requirements.
To validate the GASY, we started with a reasonability analysis of spatial distribution for its three sub-datasets on a global scale. Following this, we primarily validated the GASY with reference values derived from various methods for different Sy concepts across ten groundwater aquifers worldwide (Fig. 3). The selection of study aquifers prioritized those containing minimal soil type variations, thus predominantly representing a single soil texture type. This approach facilitated direct comparison between the GASY and the existing reference results estimated for different Sy concepts, obtained by laboratory experiments and field observations, with these comparisons tailored to the specific soil texture types, as depicted in Tables 2–4. The predominant soil type for each aquifer was determined by calculating the area-weighted average of sand, silt, and clay percentages. Similarly, the area-averaged GASY value was considered as the Sy for each respective aquifer.
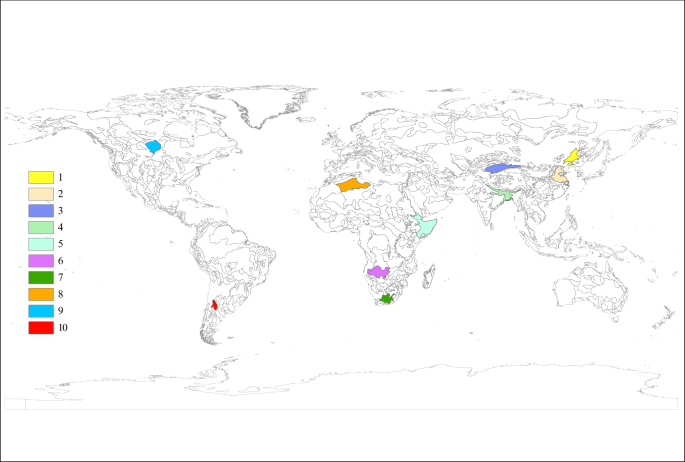
Geographical locations of ten aquifers.
Furthermore, the existing global Sy data (30 seconds), as an input to the model of GLOBGM v1.0 (hereafter referred as GLOBGM–Sy) that is the successor of PCR-GLOBGB 2 (PCRaster Global Water Balance model) groundwater model based on MODFLOW28, was also incorporated into the GASY validations in the ten aquifers mentioned above and in simulating global GWLC based on terrestrial water storage changes data. The monthly total terrestrial water storage changes utilized here are the average of GRACE RL06 mascon products of JPL (Jet Propulsion Laboratory)36, CSR (Center for Space Research)37, as well as the GSFC data38 that is comparable to the JPL and CSR mascon products. The monthly land water content changes data from GLDAS-Noah (Global Land Data Assimilation System-Noah 2.7.1)39 was also employed in this study, which presents the terrestrial water storage changes but excluding groundwater, and is directly comparable to what GRACE measures over land. Therefore, the GWSC can be obtained by subtracting the GLDAS-Noah water storage change from that of GRACE. According to the data availability, in this study, the GWSC was taken as the multi-year average groundwater storage for July minus the multi-year result for January during the period of 2004 to 2010. Moreover, in the global validation based on GRACE, the datasets of GASY, GLOBGM–Sy, and GRACE were all resampled to the spatial resolution of 1 degree as GLDAS-Noah to ensure consistency in spatial resolution. The corresponding GWLC can then be obtained by dividing GWSC by Sy. Additionally, we assessed the performance of GASY in characterizing Sy for the sand soil type that has been extensively studied in the literature, through summarizing the existing Sy values estimated by diverse methods in different areas across the globe.
Data Records
The GASY data is available at the Zenodo platform40 and is publicly accessible via https://zenodo.org/uploads/14216083, with format of Netcdf. The spatial resolution is 30 seconds for the GASY–GSDE, 1 km for the GASY–SoilGrids, and 0.5 degree for the GASY–HWSD. There are two files for the GASY–GSDE, which store the Sy data for the first four and last four soil layers, respectively. Similarly, there are two files for the GASY–HWSD, corresponding to the top and sub soil layers. For the GASY–SoilGrids, there are seven files, each storing data for one of the seven layers. Each file contains a single variable of Sy.
Technical Validation
Reasonability analysis of global spatial distribution
The sub-datasets of GASY (GASY–GSDE, GASY–SoilGrids, and GASY–HWSD) can be derived using the fitted equations obtained from the trilinear graph as described in the Methods section. Because the GASY data were obtained directly according to the soil textures, we observed that all the GASY sub-datasets well reflect the spatial distributions of their corresponding sand content data. For example, comparing the GASY–HWSD with the sand content data from HWSD for the sub-layer (Fig. S1), we found that the areas with higher sand contents tend to have larger Sy, corroborating findings from existing literatures17. Specifically, in areas like North Africa, where the sand percentages exceed 80%, the GASY–HWSD Sy values reach 0.28 and higher. Conversely, in areas such as South China and southeastern North America where the sand contents range from 20% to 50%, their Sy values are less than or equal to 0.04. Moreover, the GASY–GSDE and the GASY–SoilGrids both present spatial CCs of 1 for all soil layers, while the GASY–HWSD shows the CCs of 0.829 and 0.855 for the sub and top layers, implying that the spatial correlation may be dependent on the spatial resolution.
To provide a clear view of the GASY sub-datasets, we presented the GASY’s thickness-weighted average over 0.3–1 m depths in Fig. 4, with all data interpolated to the spatial resolution of 0.5 degree of GASY–HWSD. Note that in the GASY–HWSD, missing values exist in many patchy areas, especially in North Africa and West Asia. Previous researches have highlighted substantial local discrepancies in soil texture among commonly used global soil datasets41,42. Consequently, it was explainable that the variations among the three sub-datasets of GASY were also apparent at these local areas, since the GASY was directly derived from soil texture data.
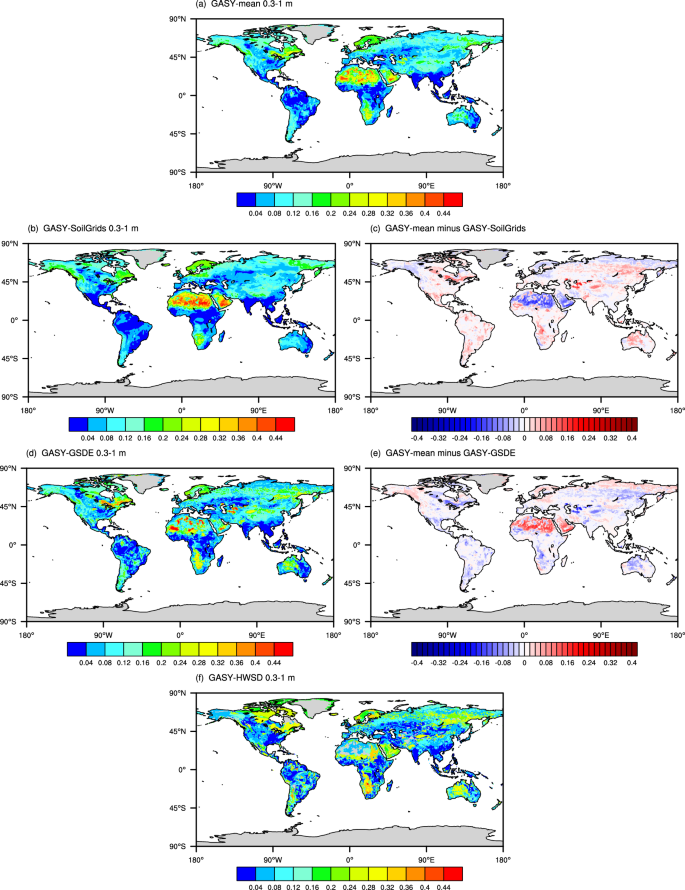
Spatial distributions of GASY–mean (a), three sub-datasets of GASY (b,d,f), and differences between GASY–mean and GASY–SoilGrids (c), GASY–mean and GASY–GSDE (e).
Specifically, for instance, a comparison of global clay content distributions from the HWSD, GSDE, and SoilGrids by Stoorvogel & Mulder43 revealed localized variations, and from which it was found that the GASY generally displays opposing spatial characteristics to those of clay data, and this result is consistent with existing knowledge that the GASY is negatively correlated with clay content while positively correlated with the sand content. Furthermore, Zhang et al.42 noted that the sand content in southern Africa, in descending order, is highest in the HWSD, followed by the GSDE, and then the SoilGrids, which is also reflected by the GASY sub-datasets (Fig. 4). The fact that the variations among the GASY sub-datasets are resulted from the soil texture differences among the GSDE, HWSD, and SoilGrids, can be proved again by the spatial patterns of sand content differences. The spatial patterns of differences between any two sub-datasets of the GASY are generally consistent with those of their corresponding sand differences (Fig. S2), with the CCs ranging from 0.719 to 0.799.
The GASY–GSDE aligns more closely with the GASY–HWSD, with the former showing slightly higher Sy in the mid-latitude region and slightly lower values elsewhere (Fig. 4d,f). This alignment can be attributed to the similarity between the soil textures classified in the HWSD and GSDE, since the GSDE, as an improvement of the HWSD, shares similar soil data sources and mapping approaches with the HWSD31,42,44. The evident disparity between the GASY–SoilGrids and the GASY–GSDE/GASY–HWSD presented in North Africa (Fig. 4b,d,f), with the GASY–SoilGrids demonstrating notably higher values compared to the other two sub-datasets, for which a possible explanation may be that the SoilGrids processing smoothed out the extreme values of silt and clay soil samples across all soil layers45, and furthermore, it was also found that the sand content from the SoilGrids is larger than the GSDE’s in most of the global land (Fig. S2).
The reasonability analysis of the global spatial distribution suggests that the GASY data are generally reasonable and align with existing knowledge. Readers can choose one of the GASY sub-datasets according to the soil texture data they used, or use the mean values of the GASY–SoilGrids and the GASY–GSDE (hereafter GASY–mean) considering that the GASY–HWSD has a lot of missing values, owns a coarser spatial resolution than the other two datasets, and has similar soil textures with the GASY–GSDE and thus similar Sy with the GASY–GSDE. Except for the deviation in North Africa, the GASY–mean and the GASY–SoilGrids/GASY–GSDE are only slightly different in the majority of the globe (Fig. 4c,e).
Quantitative validation at aquifer scale
We then conducted a quantitative validation to further evaluate the GASY data in ten aquifers worldwide. Among the reference results, the Sy from Richey et al.29 represented average values for different soil textures, directly determined by consulting the trilinear graph of Johnson18 based on a soil types map (1 degree) derived from the FAO-UNESCO’s sand, silt, and clay percentages46. The typical Sy reported in literature18,47 represented the recognized typical values for different texture classes. Note that the apparent Sy and the readily available Sy from Loheide II et al.47 were both obtained for a water table depth of 1 m. Importantly, the Sy from the GLOBGM’s global input data were also referenced here to compare with the GASY. Additionally, to ensure a comprehensive validation, the GASY data for aquifers 1 and 2 were also cross-verified with Sy estimated by the aquifer pumping test method. Figures 5a,c,e illustrates the distinct characteristics of different Sy concepts as mentioned above: (1) the ultimate Sy, with a constant value, represents the upper limit for the Sy of a soil texture; (2) the apparent Sy is usually smaller than the ultimate Sy but larger than the Sy estimated using field approaches, such as the aquifer pumping test; and (3) the readily available Sy, estimated using a similar trilinear graph47 to that of Johnson18 based on diurnal water table fluctuations (about 12 hours), is relatively small compared to the average results.
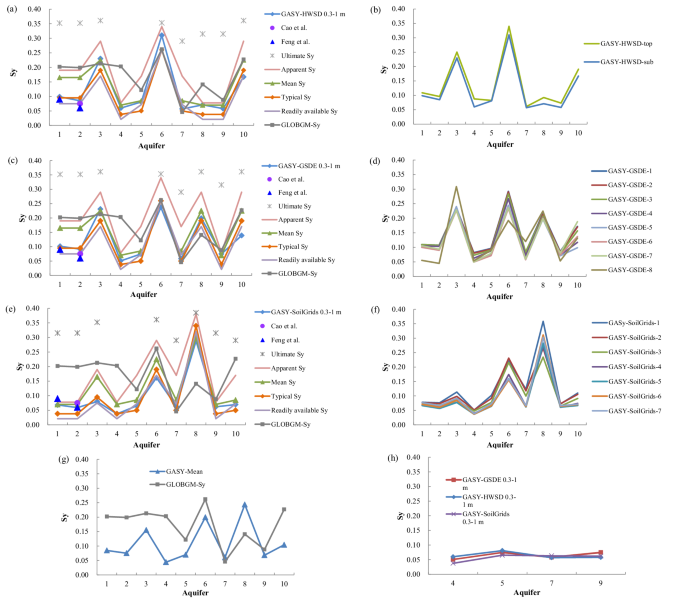
Comparisons of the 0.3–1 m Sy from three sub-datasets of GASY and existing reference results obtained for different Sy concepts in ten worldwide aquifers (a,c,e); the Sy values for each soil layer in each sub-dataset of GASY (d,d,f); comparison between GASY–mean and GLOBGM–Sy in these ten aquifers (g); and values from three sub-datasets of GASY at aquifers 4, 5, 7, 9 (h).
For the clarity of comparisons, we exclusively present the GASY’s thickness-weighted average over 0.3–1 m depths in these ten aquifers (Fig. 5a,c,e), which is almost comparable to the average for different soil layers (Fig. S3), while the results for different soil layers are illustrated in Fig. 5b,d,f. It is noteworthy that we identified the accuracy of the Richey et al.’s29 Sy value for the soil type of loam (at aquifers 1, 2 in Fig. 5a, c, and at aquifer 3 in Fig. 5e) to be questionable, and therefore, the statistical indices here were calculated after excluding this value (Tables 2–4).
Consistent with the finding in the global analysis above that the GASY–GSDE agrees with the GASY–HWSD because of sharing the same soil texture data. The validation in aquifers 1 to 10 reveals that the GASY–GSDE performance closely mirrors the GASY–HWSD, both exhibiting the highest level of consistency with the average Sy from Richey et al.29, closely followed by the typical Sy values reported in literature, characterized by CCs of 0.990–0.943 and 0.988–0.965, RMSEs of 0.016–0.027 and 0.011–0.028, and RSDs of 1.083–0.888 and 0.976–1.076, for the GASY–GSDE and the GASY–HWSD, respectively (Tables 2, and 3). This outcome is explainable as the GASY–GSDE, the GASY–HWSD, and the average Sy in Richey et al.29 were all derived based on the trilinear graph18 and the FAO-UNESCO soil texture information. Moreover, both the GASY–GSDE and the GASY–HWSD exhibit the third closest to the readily available values from Loheide II et al.47, while showing worst agreement with the ultimate results. The GASY–GSDE and the GASY–HWSD demonstrate almost identical Sy values for the aquifers, except in aquifer 8 because the HWSD’s missing data over the area of aquifer 8 resulted in a different soil type with that of GSDE (Tables 2 and 3). Regarding the GASY–SoilGrids, its performance against references demonstrates consistent findings with the GASY–GSDE and the GASY–HWSD, the details can be seen in Fig. 5e and Table 4. The localized differences between the GASY–SoilGrids curve and the other two arise from disparities in their soil textures data, but they align well with each other for the same soil type, e.g., aquifers 4, 5, 7, and 9 where the three GASY datasets share identical soil types (Tables 2–4), which highlights that the GASY production method is robust and sound, and the GASY development is intended for various soil textures but not for specific locations.
The Sy curves depicted in Fig. 5, alongside Tables 2–4, also demonstrated that the GASY values are more applicable than the GLOBGM–Sy. Specifically, the GLOBGM–Sy aligns more closely with the ultimate and apparent Sy relative to the GASY, and as shown in Fig. 5g, the GLOBGM–Sy curve is apparently higher than that of GASY–mean. Additionally, the GASY Sy for aquifers 1 and 2 (0.068–0.101 and 0.059–0.091, respectively) are in satisfactory agreement with the aquifer pumping test values from Feng et al.48 (0.09 and 0.06, respectively) and Cao et al.49 (0.075 in aquifer 2), while the GLOBGM–Sy values are too high (0.202 and 0.199, respectively). It is also worth noting that, these pumping test values represent the soil column’s average Sy weighted by the thickness of the water fluctuation zone50, while the Sy in GASY varies with depth as the soil texture changes vertically and the GASY Sy values analyzed here (comparable to the average of all soil layers) is the thickness-weighted average over 0.3 to 1 m depths, which accounts for the reasonable agreement of GASY with the pumping test values.
Validation against existing specific yields for the sand soil type
The GASY dataset was further validated against current Sy for the soil type of sand, which has been extensively studied in the literature. By compiling Sy for sand estimated by nine different methods including laboratory experiments and field observations (details provided in Table S1), it was observed that the data from GASY fall within a reasonable range, aligning closely with the average range of results recorded in the literature, as depicted in Fig. 6. This again underscores the GASY’s emergence as a robust global reference dataset for average Sy. Note that the GASY values presented here for sand are taken from those provided in the analysis of the aforementioned ten aquifers.
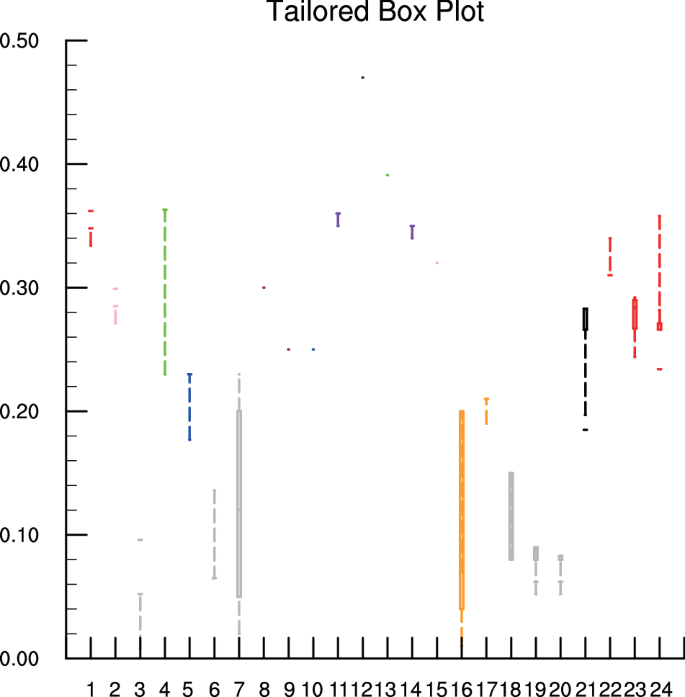
Boxplot of Sy determined by different methods marked by different colors. Red: The trilinear graph of Johnson18, and GASY. Pink: Readily available specific yield. Green: Ultimate specific yield. Blue: Rainfall–water table response method. Gray: Traditional pumping test and slug test. Brown: Laboratory drainage experiment. Purple: Apparent specific yield by the numerical equation of Crosbie et al.7. Navy: The method provided by Wang & Pozdniakov55 based on daily periodic signal. Orange: The water table fluctuation (WTF) method. Black: An improved pumping test method provided by Malama51. The abscissa numbers of 1 to 24 present the specific researches, and the details can be found in Table S1.
As described earlier and in the literature, pumping tests typically yield smaller Sy, as indicated by the gray color in Fig. 6. However, it is noteworthy that an improved pumping test method introduced by Malama51 yielded larger results compared to older methods, ranging from 0.02 to 0.25 with durations spanning from 15 to 3870 minutes. Importantly, the Sy values obtained from this improved pumping test method show a better agreement with the GASY results.
Global validation based on GRACE
At the global scale, the spatial distribution of GLOBGM–Sy (input to the GLOBGM model) differs significantly from that of GASY-mean (CC of 0.161), especially in the Americas and Asia (Fig. 7). Moreover, neither does it characterize the spatial distribution of soil textures from the GSDE or the SoilGrids, with the CCs of 0.201 and 0.271 with their respective sand content data, respectively. Figure 7 clearly depicted that, relative to the GASY–mean, the GLOBGM–Sy exhibits positive bias in South America, southern North America, central Africa, Oceania, and most of Asia, which again affirms the conclusions drawn above at the aquifer scale.
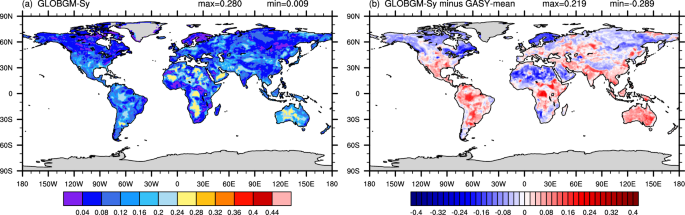
Spatial distribution of GLOBGM–Sy (a) and its difference with GASY–mean (b).
The global comparison of GWLC derived by dividing GWSC by Sy, revealed that the GWLC obtained by GASY-mean displayed greater spatial correlation with the GWSC (CC of 0.878) than that based on GLOBGM–Sy (CC of 0.721), while the GWLC calculated using a constant Sy of 0.2 only captured the spatial characteristic of the GWSC, but failed to reflect the spatial heterogeneity of the soil texture (Fig. 8). The significant GWLC deviations occur mainly at low latitudes near the equator. The maximum positive and negative deviations of the GWLC based on GLOBGM–Sy from the GWLC obtained by GASY-mean are 13.14 and −28.48, respectively (Fig. 8d), and those for the GWLC based on the constant Sy are 7.35 and −31.22, respectively (Fig. 8f). Although the GWLC deviations in the rest of world are relatively small as shown in Fig. 8, they will be increasingly large along with the step by step calculation in ESMs and LSMs.
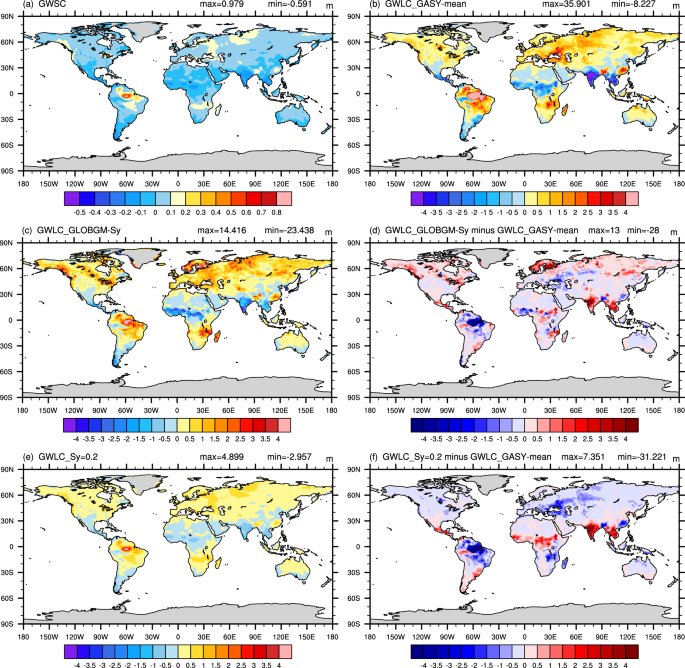
Spatial distributions of GWSC (a) and GWLC obtained by GASY–mean, GLOBGM–Sy, and a constant specific yield of 0.2 (b,c,e); and spatial maps of difference between GWLC derived by GLOBGM–Sy or a constant specific yield of 0.2 and that based on GASY–mean (d,f).
In this study, the validation of the GASY data primarily focused on different soil types, given that the GASY was directly estimated based on soil textures. It is important to note that, for each soil type, it encompasses a range of sand, silt, and clay percentages, resulting in a corresponding range of Sy values. Consequently, the Sy for a given soil type may vary across different regions due to differences in the proportions of sand, silt, and clay.
Moreover, it is worth mentioning that the trilinear graph developed by Johnson18 has limited samples over the clay and sandy clay areas. As a result, the fitted equations based on this graph may not be directly applicable to clay and sandy clay soil types. Therefore, the applicability of the GASY for clay and sandy clay soils requires further validation in future studies.
Notably, the three soil texture datasets of HWSD, GSDE, and SoilGrids are all depth-limited (about 0–2 m), and therefore, the GASY data obtained based on them are also depth-limited. If there is a soil texture dataset with deeper depth, we can surely obtain the corresponding GASY data by using the fitted equations of this study. For a region where groundwater dynamics occurs at depths > 2 m below ground surface, interested users can reasonably consider (1) taking the Sy at the last layer of GASY as the result for the soil > 2 m with the assumption that the soil texture below 2 m is the same as the last layer of GASY, or (2) expanding GASY into the depths > 2 m by establishing a reasonable trend for the vertical variation of soil texture with depth, since the Sy of GASY is directly and positively correlated with the sand content and negatively correlated with clay content, or (3) calculating the Sy for the depths > 2 m by the fitted equations in this study when the texture of the deep soil is known.
It is crucial to emphasize that the main goal of this study was to develop a global dataset of gridded average Sy for various soil textures, by employing the multiple linear regression technique to derive the fitted equation, and utilizing soil texture data from the GSDE, the SoilGrids, and the HWSD. However, users have the flexibility to generate their own gridded Sy using their preferred fitting technologies and selecting alternative soil texture data with different soil depths they needed based on their specific research objectives.


Responses