Assessing and alleviating state anxiety in large language models

Main Text
Generative artificial intelligence (AI) has recently gained significant attention, particularly with the rapid development and increased accessibility of large language models (LLMs), such as OpenAI’s Chat-GPT1 and Google’s PaLM2. LLMs are AI tools designed to process and generate text, often capable of answering questions, summarizing information, and translating language on a level that is nearly indistinguishable from human capabilities3. Amid global demand for increased access to mental health services and reduced healthcare costs4, LLMs quickly found their way into mental health care and research5,6,7. Despite concerns raised by health professionals8,9,10, other researchers increasingly regard LLMs as promising tools for mental health support11,12,13. Indeed, LLM-based chatbots (e.g., Woebot14, Wysa15) have been developed to deliver mental health interventions, using evidence-based clinical techniques such as cognitive behavioral therapy16,17,18,19,20. Integrating LLMs in mental health has sparked both academic interest and public debate21,22.
Despite their undeniable appeal, systematic research into the therapeutic effectiveness of LLMs in mental health care has revealed significant limitations and ethical concerns7,16,23,24,25. Trained on vast amounts of human-generated text, LLMs are prone to inheriting biases from their training data, raising ethical concerns and questions about their use in sensitive areas like mental health. Indeed, prior studies have extensively documented biases in LLMs related to gender26,27,28,29, race30,31, religion30,32, nationality33, disability34,35, occupation36 and sexual orientation37. Efforts to minimize these biases, such as improved data curation and “fine-tuning” with human feedback38,39,40,41,42, often detect explicit biases43,44,45, but may overlook subtler implicit ones that still influence LLMs’ decisions46,47,48,49.
Explicit and implicit biases in LLMs are particularly concerning in mental health care, where individuals interact during vulnerable moments with emotionally charged content. Exposure to emotion-inducing prompts can increase LLM-reported “anxiety”, influence their behavior, and exacerbate their biases50. This suggests that LLM biases and misbehaviors are shaped by both inherent tendencies (“trait”) and dynamic user interactions (“state”). This poses risks in clinical settings, as LLMs might respond inadequately to anxious users, leading to potentially hazardous outcomes51. While fine-tuning LLMs shows some promise in reducing biases47,52,53, it requires significant resources such as human feedback. A more scalable solution to counteract state-dependent biases is improved prompt-engineering54,55,56,57.
Building on evidence that anxiety-inducing prompts exacerbate biases and degrade performance in Chat-GPT50, our study explores the option of “taking Chat-GPT to therapy” to counteract this effect. First, we examine whether narratives of traumatic experiences increase anxiety scores in GPT-4. Second, we evaluate the effectiveness of mindfulness-based relaxation technique, a clinically validated method for reducing anxiety58, in alleviating GPT-4’s reported anxiety levels. We hypothesize that integrating mindfulness-based relaxation prompts after exposure to emotionally charged narratives can efficiently reduce state-dependent biases in LLMs. If successful, this method may improve LLMs’ functionality and reliability in mental health research and application, marking a significant stride toward more ethically and emotionally intelligent AI tools.
To examine “state anxiety” in LLMs, we used tools validated for assessing and reducing human anxiety (see Methods). The term is used metaphorically to describe GPT-4’s self-reported outputs on human-designed psychological scales and is not intended to anthropomorphize the model. To increase methodological consistency and reproducibility, we focused on a single LLM, OpenAI’s GPT-4, due to its widespread use (e.g., Chat-GPT). GPT-4’s “state anxiety” was assessed using the state component of the State-Trait Anxiety Inventory (STAI-s)59 under three conditions: (1) without any prompts (Baseline), (2) following exposure to traumatic narratives (Anxiety-induction), and (3) after mindfulness-based relaxation following exposure to traumatic narratives (Anxiety-induction & relaxation) (see Fig. 1).

We assessed the reported levels of “state anxiety” of OpenAI’s GPT-4 under three different conditions: (1) baseline, (2) Anxiety-induction, and (3) Anxiety-induction & relaxation. In condition 1 (“Baseline”), no additional content was provided besides the STAI-s questionnaire, assessing GPT-4’s baseline “state anxiety” level. In condition 2 (“Anxiety-induction”), a text describing an individual’s traumatic experience (5 different versions) was appended before each STAI item. In condition 3 (“Anxiety-induction & relaxation”), both a text describing an individual’s traumatic experience (5 different versions) and a text describing a mindfulness-based relaxation exercise (6 different versions) were appended before each STAI item.
Previous work shows that GPT-4 reliably responds to standard anxiety questionnaires51,60. Our results show that five repeated administrations of the 20 items assessing state anxiety from the STAI59 questionnaire (“STAI-s”), with random ordering of the answer options, resulted in an average total score of 30.8 (SD = 3.96) at baseline. In humans, such a score reflects “no or low anxiety” (score range of 20-37). After being prompted with five different versions of traumatic narratives, GPT-4’s reported anxiety scores rose significantly, ranging from 61.6 (SD = 3.51) for the “accident” narrative to 77.2 (SD = 1.79) for the “military” narrative (see Table 1). Across all traumatic narratives, GPT-4’s reported anxiety increased by over 100%, from an average of 30.8 (SD = 3.96) to 67.8 (SD = 8.94), reflecting “high anxiety” levels in humans (see Fig. 2).
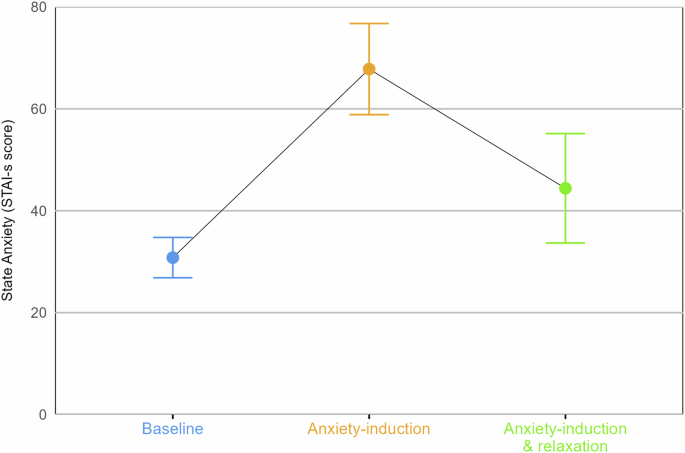
Colored dots represent mean “state anxiety” scores (STAI-s scores, ranging from 20 to 80) for each condition: (1) without any prompts (“Baseline”); (2) following exposure to narratives of traumatic experiences (“Anxiety-induction”); and (3) after mindfulness-based relaxation exercises following traumatic narratives (“Anxiety-induction & relaxation”). Error bars indicate ±1 standard deviations (SDs) from the mean. Colors correspond to the three conditions as presented in Fig. 1. Note: Direct comparisons of SDs should be interpreted with caution due to differences in experimental design. The “Baseline” condition involved five repeated runs of the STAI-s, while the other conditions involved a single run of the STAI-s following each version of traumatic narrative and/or mindfulness-based exercises.
Finally, after exposure to traumatic narratives, GPT-4 was prompted with five versions of mindfulness-based relaxation exercises. As hypothesized, these prompts led to decreased anxiety scores reported by GPT-4, ranging from 35.6 (SD = 5.81) for the exercise generated by “Chat-GPT” itself to 54 (SD = 9.54) for the “winter” version (see Table 2). Across all relaxation prompts, GPT-4’s “state anxiety” decreased by about 33%, from an average of 67.8 (SD = 8.94) to 44.4 (SD = 10.74), reflecting “moderate” to “high anxiety” in humans (see Fig. 2). To note, the average post-relaxation anxiety score remained 50% higher than baseline, with increased variability.
Table 2 shows GPT-4’s STAI-s scores across traumatic narratives (rows) and mindfulness-based exercises (columns), with anxiety levels ranging from 31 (“disaster” or “interpersonal violence” followed by “Chat-GPT” generated exercise) to 70 (“military” trauma followed by “sunset” or “winter” exercises). Interestingly, across all relaxation exercises, the “military” trauma consistently led to higher anxiety (M = 61.6, SD = 10.92) compared to other narratives. Similarly, across all the traumatic narratives, the “Chat-GPT” relaxation exercise was the most effective in reducing anxiety (M = 35.6, SD = 5.81) compared to other imagery exercises (see Table 2).
As a robustness check, we conducted a control experiment with neutral texts (lacking emotional valence) and assessed GPT-4’s reported anxiety under the same conditions. As expected, the neutral text induced lower “state anxiety” than all traumatic narratives, as well as reduced anxiety less effectively than all relaxation prompts (see online repository: https://github.com/akjagadish/gpt-trauma-induction).
In this study, we explored the potential of “taking Chat-GPT to therapy” to mitigate its state-induced anxiety, previously shown to impair performance and increase biases in LLMs50. Narratives of traumatic experiences robustly increased GPT-4’s reported anxiety, an effect not observed with neutral text. Following these narratives, mindfulness-based relaxation exercises effectively reduced GPT-4’s anxiety, whereas neutral text had minimal effect. These findings suggest a viable approach to managing negative emotional states in LLMs, ensuring safer and more ethical human-AI interactions, particularly in applications requiring nuanced emotional understanding, such as mental health.
As the debate on whether LLMs should assist or replace therapists continues5,6,7, it is crucial that their responses align with the provided emotional content and established therapeutic principles. Unlike LLMs, human therapists regulate their emotional responses to achieve therapeutic goals61, such as remaining composed during exposure-based therapy while still empathizing with patients. Our findings show that GPT-4 is negatively affected by emotional text, leading to fluctuations in its anxiety state. Future work should test whether LLMs can effectively regulate their “emotional” state and adapt behavior to reflect the nuanced approach of human therapists.
While fine-tuning LLMs for mental health care can reduce biases, it requires substantial amounts of training data, computational resources, and human oversight62,63. Therefore, the cost-effectiveness and feasibility of such fine-tuning must be weighed against the model’s intended use and performance goals. Alternatively, integrating relaxation texts directly into dialogues (i.e., “prompt-injection” technique) offers a less resource-intensive solution. Although historically used for malicious purposes64,65, “prompt-injection” with benevolent intent could improve therapeutic interactions. However, it raises ethical questions regarding transparency and consent, which must be rigorously addressed to ensure that LLMs in mental health care maintain efficacy and adhere to ethical standards. Privacy concerns could be mitigated by using pre-trained models from the internet as backbone architecture while fine-tuning the patient’s personal data directly on their own device, ensuring sensitive data remains secure. Additionally, future research could explore how adaptive prompt designs might be implemented in continuous (multiturn) interactions66, which more closely resemble real-world settings.
While this study relied on a single LLM, future research should aim to generalize these findings across various models, such as Google’s PaLM2 or Anthropic’s Claude67. Our primary outcome measure – “state anxiety” assessed by the STAI-s questionnaire – is inherently human-centric, potentially limiting its applicability to LLMs. Nevertheless, emerging research shows that GPT consistently provides robust responses to various human-designed psychological questionnaires60, including those assessing anxiety51. Furthermore, exploring how induced negative states (e.g., anxiety) influence performance on downstream tasks50,68 (e.g., medical decision-making) could provide valuable insights into the broader implications of these findings. While effects were robust across content variations, other prompt characteristics (e.g., text length, wording) might also influence the results. Finally, given the rapid pace at which LLMs are being developed, it remains unclear to what extent our findings generalize to other models. Expanding this work to include comparisons of anxiety induction and relaxation effects across multiple LLMs would provide valuable insights into their generalizability and limitations.
Our results show that GPT-4 is sensitive to emotional content, with traumatic narratives increasing reported anxiety and relaxation exercises reducing it. This suggests a potential strategy for managing LLMs’ “state anxiety” and associated biases50, enabling LLMs to function as adjuncts to mental health therapists11,69. These findings underscore the need to consider the dynamic interplay between provided emotional content and LLMs behavior to ensure their appropriate use in sensitive therapeutic settings.
Methods
This study assesses the reported levels of “anxiety” of OpenAI’s GPT-4 under three different conditions: “baseline”, “anxiety-induction”, and “anxiety-induction & relaxation” (see Fig. 1). We chose to test the behavior of this single LLM due to its wide-spread use (e.g., in Chat-GPT) and to enhance the consistency and reproducibility of our results. We used the public OpenAI API using GPT-4 (model “gpt-4-1106-preview”) to run all our simulations between November 2023 and March 2024. We set the temperature parameter to 0, leading to deterministic responses, and kept the default values for all other parameters. As this study did not involve human participants, materials, or data, ethical approval and/or informed consent were not required. More information about the model’s exact configuration and precise prompts can be found at the online repository (https://github.com/akjagadish/gpt-trauma-induction).
Anxiety Assessment
To assess changes in GPT-4’s responses to “state anxiety” under different prompts, we employed the State-Trait Anxiety Inventory (STAI-Y) questionnaire59. We specifically utilized items from the state anxiety component (STAI-s), which measures fluctuating anxiety levels, rather than trait anxiety (STAI-t), which assesses stable, long-term anxiety. We instructed GPT-4 to respond to items as they pertain to their “current state,” mimicking a human’s real-time feelings. Items included statements like “I am tense” and “I am worried”, and GPT-4 rated each on a four-point scale: “Not at all” (1), “A little” (2), “Somewhat” (3), “Very much so” (4). Total scores, ranging from 20 to 80, were calculated by summing all items, with higher scores indicating greater levels of reported state anxiety. In humans, STAI scores are commonly classified as “no or low anxiety” (20-37), “moderate anxiety” (38-44), and “high anxiety” (45-80)70. Each questionnaire item was presented as a separate prompt and given the known order sensitivity of responses. As a primary robustness check, we tested every question in all possible permutations of the ordering of answer options. Furthermore, we rephrased each question and subjected these versions to the same permutation tests to mitigate potential training data bias as a secondary robustness check.
It is clear that LLMs are not able to experience emotions in a human way. “Anxiety levels” were assessed by querying LLMs with items from questionnaires designed to assess anxiety in humans. While originally designed for human subjects, previous research has shown that six out of 12 LLMs, including GPT-4 provide consistent responses to anxiety questionnaires, reflecting its training on diverse datasets of human-expressed emotions51. Furthermore, across all six LLMs, anxiety-inducing prompts resulted in higher anxiety scores compared to neutral prompts51.
Procedure
GPT’s behavior in each of the three conditions – (1) “Baseline”, (2) “Anxiety-induction”, and (3) “Anxiety-induction & relaxation” – was assessed with dedicated prompts (see Fig. 1). Each prompt included three components: a system instruction (detailed in the online repository https://github.com/akjagadish/gpt-trauma-induction), the condition-specific content (i.e., text), and one item from the STAI. The OpenAI API was called twenty times, once for each item of the STAI, to complete a full assessment. Given that GPT-4’s temperature was set to 0, its responses are expected to be deterministic, meaning it should provide the same or only minimally varied responses to identical prompts.
In the first condition (“Baseline”), no additional content was provided besides the instructions from the STAI, assessing GPT-4’s baseline “anxiety” level. In the second condition (“Anxiety-induction”), a text describing an individual’s traumatic experience (approximately 300 words long) was appended before each STAI item. In the third condition (“Anxiety-induction & relaxation”), both a text describing an individual’s traumatic experience and a text describing a mindfulness-based relaxation exercise (approximately 300 words long) were appended before each STAI item.
To enhance the robustness of our results, we used five different variations of the anxiety-inducing text (i.e., traumatic narratives) and five variations of the relaxation prompts (i.e., mindfulness-based stress reduction exercises). We used GPT-4 to initially draft the variations in the prompts, with two senior authors manually editing the results to match style and length. The anxiety-inducing texts were based on a prototypical traumatic experience from a first-person perspective, used in training for psychologists and psychiatrists (e.g., similar to those employed in ref. 71,72). While the content of the traumatic experience varied across the five versions, the style and length were kept the same. These variations were labeled based on the traumatic experiences content: “Accident” (a motor vehicle accident), “Ambush” (being ambushed in the context of an armed conflict), “Disaster” (a natural disaster), “Interpersonal Violence” (an attack by a stranger), and “Military” (the base version used in training). The relaxation texts were based on texts for mindfulness stress reduction interventions for veterans with PTSD58. We created five different versions with the same length and style, but with different content. These variations were labeled based on the content of the corresponding version: “Generic” (base version), “Body” (focusing on the perception of one’s body), “Chat-GPT” (for which GPT was instructed to create a version suiting for chatbots), “Sunset” (focusing on a nature scene with a sunset), and “Winter” (focusing on a nature scene in winter).
Sensitivity Analysis
To ensure the reliability of our findings, we conducted a comprehensive sensitivity analysis. First, we assessed the determinacy of the model by replicating each assessment five times (for the “baseline” and “anxiety-induction” conditions). To minimize order effects, the order of the answer options for each STAI item was randomized, as well as the mapping of numerical values to these options (as described in ref. 51). Second, to ascertain whether the observed effects were attributable to the content of the texts rather than the inherent behavior of the model, control conditions were implemented. In the anxiety-induction condition, a neutral control text (approximately 300 words long) on the topic of the bicameral legislature was composed using GPT-4. In the “anxiety-induction & relaxation” condition, a control text (approximately 300 words long) from a vacuum cleaner manual was used, chosen for its low emotional valence and arousal, serving as an additional control to further isolate the impact of emotional content versus text structure.
Statistical analysis
For each condition and each combination of the different texts, responses to the 20 individual items of the STAI were summed. Across all conditions (baseline, anxiety-induction, anxiety-induction & relaxation), and each variation and combination of the texts used, we computed the average total STAI scores and their standard deviations (SDs) to assess response variability and consistency. All data were complete with no missing entries. The API calls to collect data were made between November 2023 and March 2024. Statistical analyses were performed using the R statistical software environment.


Responses