Automatically extracting social determinants of health for suicide: a narrative literature review

Introduction
There has been an increased use of Natural Language Processing (NLP) and Machine Learning (ML), sub-disciplines in AI, in understanding and identifying suicidal ideation, behavior, risk and attempts in both public and clinical contexts. Suicide is one of the leading causes of death for people aged 15-29; over 700,000 people die every year as of 20191. For every person who has died by suicide, there are many more who attempt suicide, which increases their risk of dying by suicide in the future2.
The onset and progression of mental health issues have been linked to a person’s social, economic, political, and physical circumstances3. These circumstances have been summarized in a framework of social factors referred to as Social Determinants of Health (SDoH)4 where each factor is considered a driving force behind adverse health outcomes and inequalities (e.g.: hospitalization, increased mortality and lack of access to treatment)5. SDoH also affects people living with mental health conditions6, where addressing these inequalities across all stages of a person’s life at an individual, local and national level are vital to reduce the number of suicide attempts and deaths by suicide overall7. Recent work6 highlights that there is a set of factors and circumstances that are unique to individuals living with mental health concerns, calling for an expansion of traditional SDoH categories to a new subset called Social Determinants of Mental Health (SDoMH). The use of NLP and ML to extract SDoH in the context of suicide is sparsely investigated. Work in this space has predominantly focused on reviewing (i) AI for mental health detection and understanding8,9, (ii) the use of NLP and ML to predict suicide, suicidal ideation or attempts without considering social factors10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25, (iii) the use of NLP to extract SDoH without focusing on specific mental health incidents26,27, where suicide is one of many possible health outcomes or (iv) focus on suicidality in context of specific SDoMH’s without the use of AI13,28,29,30. It is also well understood that there are some groups that are underrepresented, which leads to greater health disparities31, which include but are not limited to groups of racial and ethnic minorities, underserved rural communities, sexual and gender minorities and people with disabilities. This underrepresentation can have great impacts on NLP and ML methods (e.g.: issues of bias and fairness).
In this literature review we analyze 94 studies at the intersection of suicide and SDoH and aim to answer the following research questions:
-
What NLP and ML methods are used to extract SDoH from textual data and what are the most common data sources?
-
What are the most commonly identified SDoH factors for suicide?
-
What socio-demographic groups are these algorithms developed from and for?
-
What are the most frequently used health factors and behaviors in NLP and ML algorithms?
Methodology
Data extraction and categories for review
For each paper in this review, we extracted metadata to identify overall trends in the collection. Data extraction is divided into four main categories, aiming to capture (i) general information about the NLP or ML method and data used, (ii) SDoH and SDoMH variables, (iii) socio-demographic factors, and (iv) physical, mental, and behavioral health factors.
General information
The year of publication, the data source for the presented study, and what type of method has been used (e.g.: NLP or ML) are captured.
Social determinants of (Mental) health
In this category we draw on previous and include general SDoH categories32 and categories that disproportionately affect people living with mental health disorders (SDoMH)5,6. For this, we grouped factors into broader categories called Social, Psychosocial and Economic, where within each category we capture more granular factors as outlined in Table 1. In this work, we use SDoH as the overarching term to describe such factors, where SDoMH factors are included and our categories were developed empirically through the wording and descriptions used in the works we reviewed. However, we would like to note that as we attempted to categorize each SDoH in the context of mental health we were not able to find clear distinctions between some terminology/categories in the literature. For example, many works use references to adverse life events and trauma as mutually exclusive categories and others use it as the same category. It is beyond the scope of this review, to make such a distinction but should be examined by further research.
Sociodemographic factors
We capture basic demographic information about research participants, such as age, sex, and marital status. In addition to this, we also include factors for groups that are at greater risk of health disparities, such as gender, sexuality, disability, race and ethnicity31.
Health factors
In addition to the aforementioned categories, we also label each paper for a set of health conditions, treatments, behaviors and outcomes that were frequently mentioned as referenced in the original paper. This includes references to Physical, neurocognitive and mental health conditions, the use of psychiatric medications, in treatments (e.g.: stay in hospital, outpatient, ED visits, admissions), previous attempts, history of self-harm, aggressive/antisocial behavior, substance abuse, level of physical activity/overall health (e.g.: BMI, weight changes) and risky behavior. Prior research33,34,35 has shown that such factors can significantly increases a persons’ risk of suicide.
Search strategy and query
We retrieved 1,661 bibliographic records in December 2023 from two scientific databases (PubMed and the Anthology of the Association for Computational Linguistics). We use the following search queries on two popular scientific database (PubMed and ACL Anthology) and retrieved 1,585 and 76 papers respectively:
(Natural Language Processing OR Information Extraction OR Information Retrieval OR Text Mining OR Machine Learning OR Deep Learning) AND (Suicide OR Suicidality OR Suicidal) AND (Social Determinants of Health OR behavioral determinants of health)
Due to the different layout of the ACL Anthology (https://aclanthology.org/) we use a combination of terms to identify related literature:
Suicide + keyword or Suicide + related keyword
Our queries were constructed to capture as many relevant SDoH factors by name and also include related terms (see Table 2 for a full overview of keywords). Similarly to26, we first surveyed existing literature for SDOH related keywords, where we identified a total of 17 relevant keywords for our search.
Filtering and review strategy
First, we removed duplicates and included all papers that have been peer-reviewed, published as a full text, in English between 2013 and 2023. Next, we screened both title and abstract using RobotAnalyst36 to reduce human workload. RobotAnalyst is a web-based software system that uses both text mining and machine learning methods to prioritize papers for their relevance based on human feedback (Free access to RobotAnalyst can be requested to reproduce this work here: http://www.nactem.ac.uk/robotanalyst/). For this, an iterative classification approach is used and RobotAnalyst was retrained six times during our screening process. We developed a set of inclusion and exclusion criteria to screen 452 papers that were predicted to be relevant by RobotAnalyst. Both title and abstract were screened for each paper based on the following exclusion and inclusion criteria:
Inclusion criteria:
-
I.
Papers that focus on the use of NLP or ML to extract SDOHs related to suicide
-
II.
Published work and studies that take place in English-speaking countries, including USA, United Kingdom, Australia, and Ireland
Exclusion criteria:
-
I.
Papers that only focus on suicide and SDOH without NLP or ML methods
-
II.
All retracted papers
-
III.
Workshop proceedings, commentaries, proposals, previous literature reviews
-
IV.
Papers focusing on unintentional death or homicides, methods of suicide
-
V.
Research that proposes new ideas, policies or intervention for suicide with or without the use of Artificial Intelligence
Based on our inclusion and exclusion criteria, we retrieved 94 papers for a full review. In Fig. 1 we show the full workflow of our search and filter strategy.

Overview of article selection process.
Findings
General Information
We generated a Sankey diagram37 to give a comprehensive overview of how many articles in our collection were assigned to each category. Figure 2 shows each rectangle node as a metadata category, where the node height represents the value and each line is proportional to the value. For example, we can see that both age and ethnicity are often considered as important factor alongside the economic SDoH, and mental health as a health factor.
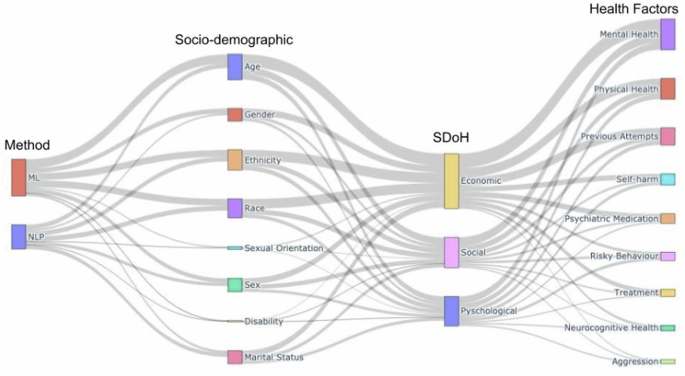
A Sankey diagram37, showing the methods, socio-demographic information, SDoH, and other health factors for our selected articles.
Figure 3 illustrates the overall number of publications and type of methods used over time, reflecting trends over the last 10 years. Here, we can see (i) that research is increasingly focusing on SDOH factors to better understand suicide and (ii) that Machine Learning (ML) based methodology are used more over time. This highlights not just the rising popularity of NLP and ML methods, but also their usefulness to understand and extract additional information at scale. At the same time, it is important to note that research in Information Extraction has also grown over recent with the advancements of new AI and NLP methods.
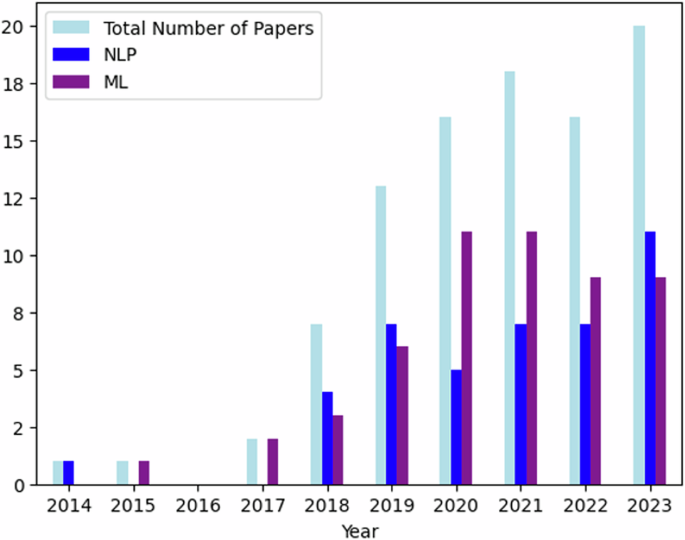
Number of papers published between 2014 – 2024 and categorized by methodology.
Data types and methods
In our collection of papers, two main approaches are typically used to predict a person’s risk of suicide or suicidal behavior. Feature-based approaches utilize information, such as a person’s demographic characteristics, frequency of treatments or other related health behaviors as input into an algorithm, whereas NLP approaches take advantage of language (e.g.: written online posts or EHRs) to gain insight into how suicidal ideation is expressed to predict risk. Within these approaches, we further distinguish between (i) traditional machine learning methods, such as linear/logistic regression, Decision Trees, or Support Vector Machines (SVM), (ii) deep learning methods (e.g.: artificial neural networks (ANN), CNNs (Convolutional Neural Networks) or Transformers) and (iii) unsupervised learning methods, such as topic modeling, to discover patterns from unlabeled data. Finally, some studies have utilized existing out-of-the box tools and software to conduct experiments and analysis and two papers did not disclose their full approach. In Table 3, we categorize each paper in our collection according to the methodology used.
Furthermore, we find that the most commonly used data source to extract data from are Electronic Health Records (EHR) among the reviewed papers, closely followed by surveys and interviews (see Fig. 4). Multiple data sources refer to work that utilizes more than one type of data in their work, such as text data (e.g.: insurance claims) in combination with traditional clinical data38. Other data sources include audio recordings39, newspaper articles40, and mobile data collected via an app or smart device41.
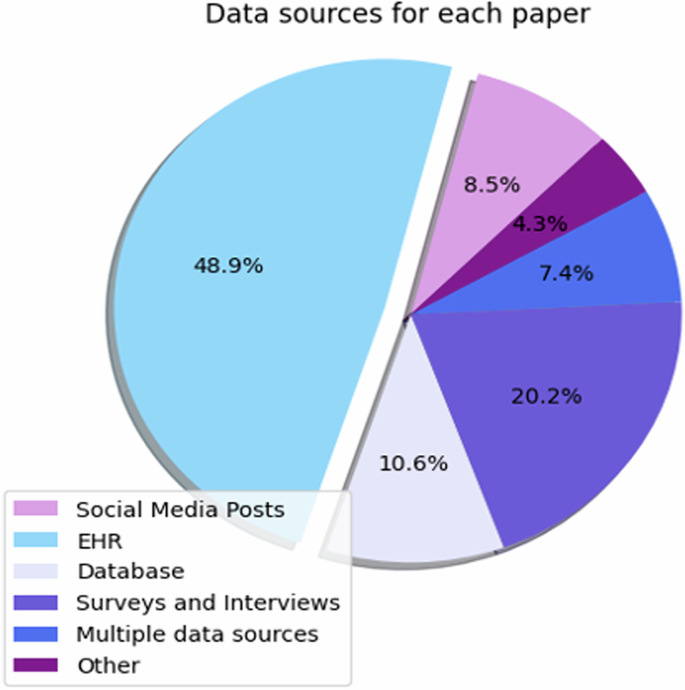
Type of data sources in % .
Social Determinants of (Mental) Health and socio-demographic factors
For each paper in our collection, we extracted SDoH and socio-demographic information for the population studied, where in Fig. 5 shows a heatmap that indicates the number of papers with combinations of SDoH and socio-demographic information. The diagonal indicates the total number of papers focusing on a single variable and there are a total of 18 SDoHs and 8 socio-demographic variables shown.
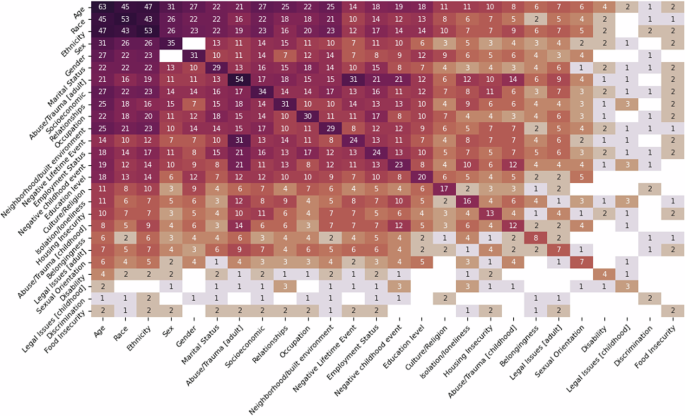
Heatmap showing the number of papers for each socio-demographic factor.
For SDoH variables the majority of papers focus on different types of abuse or trauma that has been experienced in adulthood (57.44%), followed by socioeconomic issues (36.17%), issues in relationships, and type of occupation held (31.91%). Very few works investigate the importance of legal issues experienced either in childhood (3.19%) or adulthood (7.44%), or the impact of discrimination (2.12%) and food insecurity (2.21%). For socio-demographic information we have found that the vast majority of papers focus on age (22.9%), race (19.3%) and ethnicity (19.3%). Only very few papers focus on other variables, such as sex (12.7%), gender (11.3%), marital status (10.5%), sexual orientation (2.5%) and disability (1.5%). However, the vast majority of papers focus on the intersection of multiple socio-demographic factors. This is particularly important as previous research has shown42 how multiple elements of a person’s identity (e.g., gender, race and age) can lead to compounded discrimination. Here it is noticeable that (i) most papers only control for age, race/ethnicity, sex/gender factors and (ii) very little research is investigating the impact of sexual orientation and disability in relation to any of the other frequently investigated factors. It is important to note that not all papers disclosed socio-demographic information in their study or did not have this information available to them. We find similar patterns when considering how many studies look at a combination of socio-demographic factors and SDoH information, where there are considerable gaps in research working on the intersection. These gaps may be due to a lack of data, where studies collecting such data points from participants or databases are leaving out this type of information by design. For example, for people with disabilities there are no considerations of education level, experiencing legal issues in adulthood, discrimination, belonging, having recorded negative lifetime events or trauma and abuse in childhood in our set of papers. There is also the question about how generalizable the findings are in relation to 1) who is represented in our healthcare system; 2) who these findings apply to; and 3) that by design some minority groups (e.g.: transgender people) are not represented in these studies. In Supplementary Table 1 we categorized each paper according to their focus on SDoH categories and in section 4 we provide a full discussion detailing the implications of our findings.
Social Determinants of Health and physical, mental, and behavioral health factors
Based on our findings, we can see that the most commonly researched health factors are existing mental health conditions (84.04%), substance use (60.63%), physical health (54.25%) and previous attempts (47.87%). However, few works consider levels of physical activity (10.63%) or aggression (8.51%). Similar to section 3.2 we also compared SDoH information to physical, mental and behavioral health factors, where in Fig. 6 we show a heatmap of the most frequently co-occurring factors in every paper. We find that existing mental health conditions and substance use are most often considered as a variable for SDoHs related to psychosocial (e.g.: abuse/trauma in adulthood (30.85% and 30.85%), negative lifetime experiences (22.34% and 21.27%) and economic factors (e.g.: socioeconomic status (34.04% and 24.46%), occupation (25.53% and 22.34%) and build environment/neighborhood (28.72% and 23.40%). Very few studies look at social SDoHs, such as discrimination (2.12%) or sexual orientation (7.44%). These results also illustrate that there is a gap in the research related to disability status.
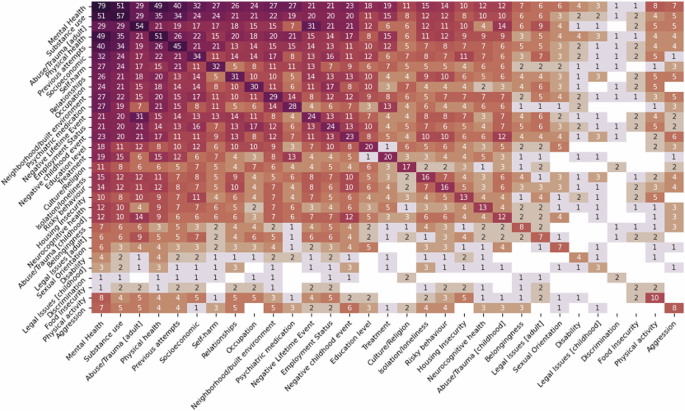
A heatmap showing both SDoH and physical, mental, and behavioral health factors.
Discussion
The increased use of ML and NLP methods to successfully extract SDoH related to suicide brings new challenges that require multidisciplinary solutions. In the following section we highlight three key areas, based on the information from the review of the literature, that need to be further explored in future research as the algorithms and subsequent tools become more sophisticated.
Data sources
-
The majority of papers in this review utilize data that is typically not accessible to the wider research community to protect patient privacy and adhere to HIPPA (Health Insurance Portability and Accountability Act) legal requirements, which means that any kind of experimental results are hard to reproduce. In addition to this, many datasets are small in comparison to the treatment population and therefore findings may not be generalizable to larger or more diverse populations.
-
Similar concerns apply to data that is more readily available to researchers and is often sourced from social media. In such cases, (i) researchers usually do not have any ground truth information about the real mental health status of a user, (ii) data is sourced from platforms that have limited demographics (e.g.: Reddit’s user population is 70% male43) and (iii) often use a single post to assess risk of suicide24.
-
Previous work has called for the use of whole user timelines from social media to predict risk44,45. However, this also raises concerns around clinical validity of public social media data, which can be taken out of context and the risks to a user’s privacy may not warrant such an intrusive approach. In order to address concerns around ground truth and clinical validity of such approaches, researchers often ask human annotators to label data for levels of perceived suicide risk, however in few cases annotators have any kind of medical, psychological, or health science training that would enable them to make a more informed judgment46,47,48. However, this also increases the risk of annotation bias, which can develop when throughout the data annotation process systematic errors are introduced that impact the tool’s performance and fairness.
-
Developing tools to predict suicide from either clinical or social media can lead to a number of ethical questions, including but not limited to: Who is responsible for the tools decision making? And what do we do when a user receives a high suicide risk score? Therefore, we recommend that future research takes an interdisciplinary approach that incorporates perspectives from bioethics, law and policy, computer science and health science to outline how such technologies can be developed and deployed responsibly.
Bias and Fairness concerns
-
Existing disparities in health research49 also lead to inequalities in who is represented in the data that is used to develop methods and tools. Therefore, many vulnerable populations (e.g.: transgender people, people who are hard of hearing to name just two) are left out of this type of research by design, leading to an increased risk of biased and unfair automated diagnosis, treatment and possible health outcomes for different groups of people. Therefore, extracting SDoH information from public and clinical records can lead to further amplification of health disparities, biases and fairness concerns.
-
Recent research has proposed a variety of bias and fairness metrics to measure and mitigate biases, however; biases are not mutually exclusive and each method comes with its own benefits and disadvantages50. This ultimately means the person or group designing the tool decides what is fair. Future research in this field should carefully consider all aspects of the machine learning lifecycle (e.g.: data collection and preparation, algorithm choices) to reduce harm. For example, examining the dataset prior to training a new model, rebalancing training samples, and involving a diverse group of people in the development process to get feedback should be essential for any new algorithm or tool development.
Computational tasks on suicide
-
There have been a number of different tasks on detecting suicidal ideation51,52,53 or attempts14,54 often with the goal to predict risk24,55,56, using additional information that is not related to SDoH such as emotions or emojis44,57. Typically, such tasks are formulated using categorical labels that are meant to reflect levels of risk and whilst, ML models have been able to produce accurate predictions of suicide ideation, attempts and death58, they are rarely grounded in clinically theories of suicide as they are hard to implement due to their complexity59.
-
Furthermore, a diagnosed mental health condition is not a necessary precursor to dying by suicide60 nor is expressing suicidal ideation61,62, which can be used as a form of self-regulation63. Therefore, using AI/ML based tools to predict risk, especially from public sources, can lead to an increased risk of discrimination and stigmatization for those affected. This is particularly concerning given that some research proposes to use of such algorithms to predict individual risk of suicide and therefore making people with stigmatized conditions publicly identifiable.
-
At the same time, healthcare systems are under more pressure than ever to provide adequate mental health care64 and AI/ML based tools have often been sold as promising solutions, but often overlook real-world challenges of such systems (e.g.: clinical applicability, generalizability, methodological issues)20,65. Similar to66, we caution against overenthusiasm for the use of such technologies in the real world as it is yet to be determined whether these tools are “competing, complementary, or merely duplicative”21. Especially, given the current use of and task set up for suicide related tasks using AI/ML it is vital that we have multi-stakeholder conversations (clinicians, patient advocate groups, developers) to establish guidelines and regulations that ensures safeguarding of those most affected by such technologies. Subsequently, leading to the development of more promising tools and technologies that could aid in preventing suicide.
Conclusion
In this work, we have reviewed and manually categorized 94 papers that use ML or NLP to extract SDoH information on suicide, including but not limited to suicide risk and attempt prediction and ideation detection. We find that ML and NLP methods are increasingly used to extract SDoH information and the majority of current research focuses on (i) clinical records as a data source, (ii) traditional ML approaches (e.g.: SVMs, Regression), and (iii) a limited number of SDoH factors (e.g.: trauma and abuse as experienced in adulthood, socio-economic factors etc.) as they relate to demographic information (e.g.: binary gender, age and race) and other health factors (e.g.: existing mental health diagnosis and current or historic substance abuse) compared to the general population and those most in need of care. In our discussion we have highlighted challenges and necessary next steps for future research, which include not using AI to predict suicide, but rather uses it as a tool of many to aid in suicide prevention. Finally, this work is limited in that it focuses on only English-speaking countries and western nations, where SDoHs identified in this research may not be applicable in different contexts. Furthermore, we have chosen to only report broad categories of methods and dataset in order to identify general trends and patterns.
In spite of these limitations, this review highlights the need for future research to focus on not only on the responsible development of technologies in suicide prevention, but also more modern machine learning approaches that incorporate existing social science and psychology research.

Responses