Construction of a knowledge graph for framework material enabled by large language models and its application

Introduction
Metal-organic frameworks (MOFs), first reported in 19951, have garnered immense interest due to their unique crystalline and porous structure formed by metal nodes and organic linkers. The discovery of MOFs marks a significant breakthrough in the field of materials science2. Subsequently, covalent organic frameworks (COFs)3 and hydrogen-bonded organic frameworks (HOFs)4 have appeared and attracted intense attention of researchers. MOFs, COFs, and HOFs were called framework materials (FMs), which exhibit greater flexibility and innovation potential in terms of structural diversity, controllable porosity, and functional modification5,6,7,8,9,10,11,12. These properties endow them with a wide range of potential applications in various fields including luminescence13, sensing14, gas storage15, separation16, catalysis17, proton conduction18, drug delivery19, and so on20,21,22. Therefore, the design, synthesis, and application of these FMs have become a focal point for research and exploration among chemists, materials scientists, and engineers.
The knowledge graph (KG) functions as a structured repository for semantic information, using a graphical model to depict entities, concepts, and their relationships23,24. It has great potential application for science education and research. For example, its logical structure and visual representation clearly reveal the relationships between information, facilitating the understanding of complex concepts during students’ learning25. Leveraging the powerful logical relationships expressed by knowledge graphs and technologies such as graph embeddings26, knowledge graphs have played a crucial role in supporting scientific research in areas such as chemical safety27, drug discovery28, property prediction26, and the expansion of chemical reactions29. Additionally, KGs reveal intricate relationships, aiding researchers in exploring interdisciplinary links and pinpointing potential research directions and innovation opportunities, thereby expediting scientific discovery23,30. Recently, the integration of KGs with large language models (LLMs) has been explored to promote the accuracy of information provided by LLMs, thereby broadening the application scope of KG in AI systems31,32. Despite their broad potential application, FMs have not yet benefited from a comprehensive knowledge graph33,34.
Crafting KGs involves transforming domain expertize and comprehensive research data into interconnected knowledge networks35. This process typically demands significant human effort, since researchers must meticulously sort through a vast array of fragmented and unstructured information within the literature23,24. Furthermore, it challenges their ability to discern the logical relationships between pieces of information and to organize them into a structured and interconnected knowledge system36. Application automation and intelligent technologies have reduced the workload and boosted the efficiency of knowledge graph construction37. LLMs are capable of automatically extracting, semantically analyzing, and logically interpreting literature content. This approach has already proven its value in chemistry30, materials38, engineering39, and biology36,40, significantly reducing manual efforts in organizing and integrating information. It is expected that knowledge graph of various research fields will be soon developed with the assistance of these AI technologies.
Herein, as shown in Fig. 1, we have compiled the existing literature on MOFs, COFs, and HOFs. By employing LLMs, we organized and analyzed more than 100,000 documents in a high-throughput manner. A KG is built on the Neo4j platform including 2.53 million nodes and 4.01 million relationships. The graph focuses on FMs, encompassing their fundamental information, properties, applications, and sources. The KG can assist researchers in information retrieval, visualization, and data analysis. Additionally, by coupling with LLMs, the KG can significantly enhance the question-answering capability of LLMs in the field of framework materials. The accuracy rate of the system is 91.67%, significantly higher than that of existing LLMs (GPT-4: 33.33%). Particularly in the chain-of-thought (CoT) reasoning tasks of LLMs, the KG provides rich background information to facilitate reasoning and question-answering.

Flowchart for constructing a knowledge graph from the literature and using it for knowledge querying and enhanced LLMs retrieval and application of knowledge graph.
Methods
Collecting information of relevant literature
The relevant journal articles on MOFs, COFs, and HOFs published before May 8, 2024, were retrieved from the Web of Science database using the following search queries (Eqs. 1–3):
The abstracts and publication details (including DOI, authors, publication date, and journal information as shown in Table S1) of the retrieved papers were exported from Web of Science. The exported information is saved in TXT files as text.
Abstract information extraction
Information extraction from the abstracts was carried out by converting the text into a JSON format with logical relations using Qwen2-72B. The task and output format for Qwen2-72B were defined in the prompt (Figs. S1–S3). We focused on whether the nodes extracted from the abstracts and the relationships between them were accurate and comprehensive. The evaluation of the model’s conversion process is similar to the evaluation of classification algorithms in machine learning (Fig. S4). Only accurate and comprehensive relationships are considered correct (True Positive, TP).
Knowledge graph construction and usage
The knowledge graph was constructed using the Neo4j software. Through the Python interface, the publication information and the JSON files generated by the LLM were imported into Neo4j. The code can be accessed at https://github.com/MontageBai/KGFM. The constructed knowledge graph was utilized by invoking the graph database via the Neo4j Docker and conducting data visualization and analysis. The version of Neo4j we used in this study is 5.12.0.
Integration of LLMs with the knowledge graph
The Retrieval-Augmented Generation (RAG) process using LLMs was divided into 3 steps, and the entire process was implemented using Python.
-
1.
Generate Cypher Query: Construct a Cypher query based on the user’s question to retrieve relevant information from a Neo4j database.
-
2.
Execute Query and Retrieve Data: Run the generated Cypher query against the Neo4j database to obtain data related to the user’s query from the KG.
-
3.
Formulate Answer: Use the retrieved KG data to formulate a precise and professional answer to the user’s question.
The code can be accessed at https://github.com/MontageBai/KGFM.
Versions and usage of large language models
The open-source models were accessed locally, whereas the closed-source models were accessed through web interfaces. The specific version numbers are provided in Table 1.
Evaluation of LLMs combined with knowledge graphs
To evaluate the performance of large language models (LLMs) augmented with knowledge graphs, we designed a test set consisting of 150 questions related to framework materials. Both the questions and their reference answers can be accessed at https://github.com/MontageBai/KGFM. The evaluation of the answers was based on manual judgment; an LLM’s answer was considered correct (True) only if it matched the standard answer; otherwise, it was marked as incorrect (False).
Results
Preparation of knowledge graph
We have designed and implemented a framework for the efficient construction of KGs from literature, as illustrated in Fig. 1. The framework’s process comprises data preprocessing, entity and relationship recognition using LLMs, knowledge graph construction, and the application of the knowledge graph. In the data preprocessing phase, we retrieve and collected more than 100,000 published academic literature. As shown in Figs. S5–S7, the data is stored in multiple txt files in the form of text, which is convenient for subsequent retrieval by LLMs. Extracted unstructured data, particularly abstracts, require organization, extraction, and summarization to be converted into a relational database. Here, we use the Qwen2 LLM to conduct a detailed analysis of the summary, identifying key information and organizing it into nodes and relationships, which are then saved in a JSON file. As shown in Figs. S8–S10, LLM effectively recognizes critical elements (such as research methods, experimental results, theoretical concepts, etc.) in the digest and converts them into a structured JSON format using customized prompts (Figs. S1–S3). This step is critical in knowledge graph construction as it determines the quality and accuracy of the nodes and edges in the graph. Therefore, we manually reviewed 100 results extracted by LLM. Based on the concept of a confusion matrix in machine learning (Fig. S4), the model achieved a TP rate of 98% for accurate and comprehensive information extraction, with a FN rate of 2% for inaccurate and comprehensive information extraction. The F1 score is 0.9898. Overall, with the given prompt, LLM performs well in extracting information from abstracts, and this prompt was subsequently used for high-throughput extraction.
Construction of knowledge graph
In the knowledge graph construction phase, we use Cypher statements to import processed node and relationship data from the LLM, as well as structured metadata such as titles and DOI numbers, into the Neo4j graph database. Here, the generated JSON files are first converted into Cypher queries to import the data into the knowledge graph. The structured data is then linked to the nodes parsed by Qwen through manually defined relationships, such as “Derived from”, “Published in (Journal)”, “Published at (Date)”, and etc. More details can be found in the source code at https://github.com/MontageBai/KGFM.
The knowledge graph, built from over 100,000 academic papers, encompasses over 2.53 million entities (nodes) and 4.01 million relationships, as detailed in Table 2. Among the materials, MOFs, as one of the earliest developed, hold a significant place in the knowledge graph. Figure 2 illustrates that the knowledge graph is centered on materials and includes information about their properties, structures, applications, performance, and related reports. The knowledge graph not only provides researchers with a comprehensive and multidimensional database of material information but also offers robust data support for the research and development of materials science. In the knowledge graph, each material is represented as a node, connected across multiple dimensions, including properties, synthesis methods, and application fields, forming a vast networked structure. This structured data representation enables researchers to intuitively grasp the relationships between materials and their potential value in various application scenarios.
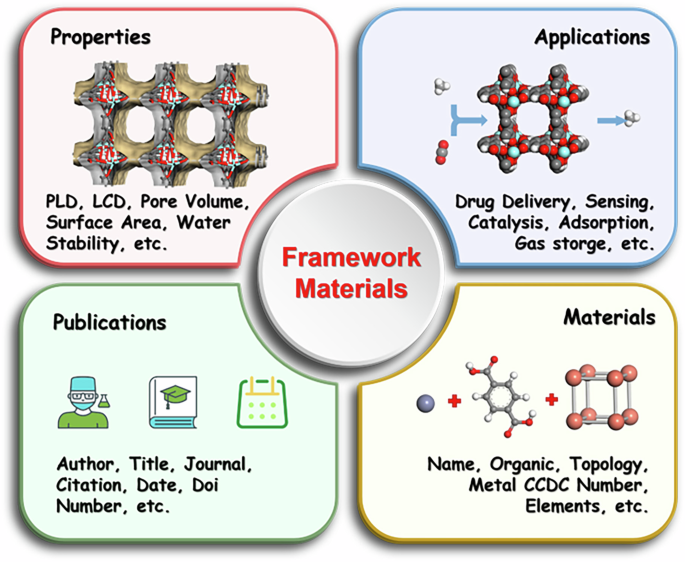
The main types of information in the knowledge graph include the application, properties, intrinsic information of the material, and related information from journal publications.
Applications of knowledge graph
In this section, we report the exploration of KG in information retrieval as well as their integration with large language models (LLMs). The combination of KG and LLMs not only facilitates the querying KG with natural language but also addresses key challenges of LLM such as factual inaccuracies and limited domain specificity. Particularly, incorporating KGs into the chain-of-thought (CoT) reasoning of LLMs significantly enhances reasoning quality and interpretability, thereby enabling precise guidance for framework material screening.
The Neo4j platform offers a user-friendly graphical interface that allows domain experts to query the knowledge graph using simple search terms. As shown in Fig. 3, we queried the work of Li and colleagues41 using a simple Cypher statement (Eq. 4). From the knowledge graph, it is evident that the paper focuses on the material BUT-55 and reports on the application of a series of isomorphic MOFs for the trace adsorption of benzene. The structure of BUT-55 is a bi-armed structure, consisting of the metal Co and the ligand H2BDP (1,4-di(1H-pyrazol-4-yl)benzene). The paper also explains the adsorption mechanism further by testing single crystals loaded with benzene. Similar to Fig. 3, information from different literature sources can also be obtained through Eq. S1 and Eq. S2 (Figs. S11–S12). We can also conduct a material-specific search. Overall, with the help of the knowledge graph, researchers can quickly search for and access research literature on MOFs, greatly facilitating knowledge discovery and research progress in the field of materials science.
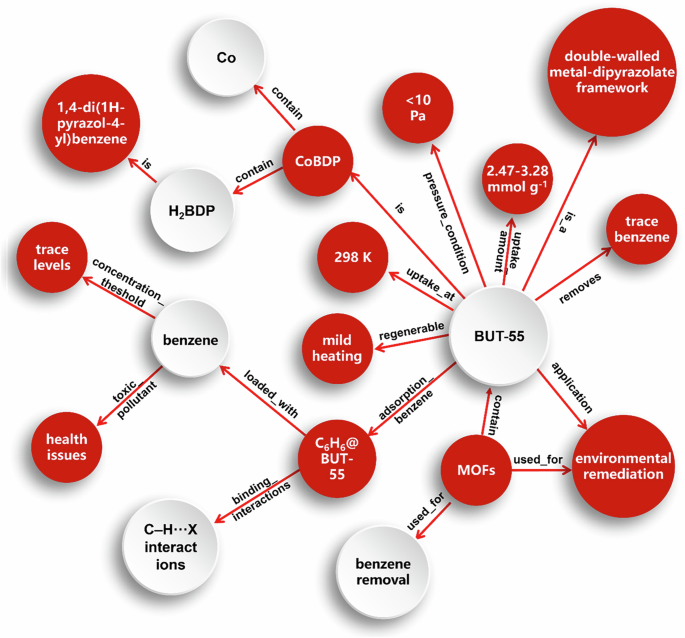
The result by using a knowledge graph to query the literature titled “Trace removal of benzene vapor using double-walled metal–dipyrazolate frameworks”.
The application of KGs not only enables us to delve into potential information but also offers a clearer and more comprehensive perspective for analyzing and tracking domain trends and research focuses, surpassing traditional review papers. As shown in Fig. 4a, over the past decade, there has been a significant rise in the number of publications on MOFs, COFs, and HOFs, with a particularly notable increase in the proportion of COFs in the literature. This highlights the increasing importance and popularity of COFs in research. In Fig. 4b, we focus on the research into MOFs with different metal centers for adsorption applications. The analysis reveals that cobalt Co-based MOFs occupy a significant proportion in CO2 adsorption studies, providing important guidance for future material design and suggesting the potential of Co-based MOFs in the field of carbon capture and conversion. Moreover, Fig. 4c and d showed the results of data mining using the knowledge graph with those from the Web of Science. Through statistical analysis using search expressions (as detailed in Table S2), we discovered significant discrepancies between the two sources. This discrepancy is likely due to the superior capability of KG to discover hidden links between different terms. For instance, in some literature, classic Cu-based MOFs such as HKUST-1 may not explicitly state the metal type in the title and abstract. The knowledge graph, however, can directly link Cu to HKUST-1, thereby enhancing the accuracy and reliability of the data mining process.
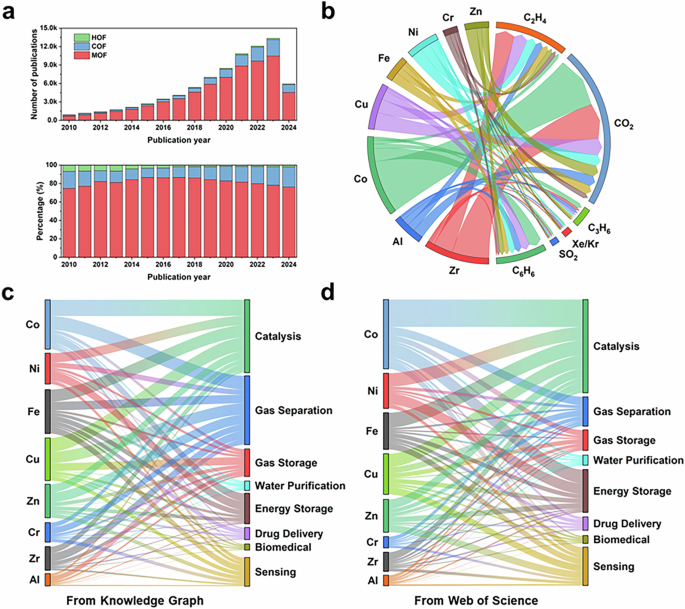
a Publication of literature on MOF, COF, and HOF; b Report of MOFs of different metals for gas adsorption; c Application of MOFs of different metals through knowledge mapping; d Application of MOFs of different metals through web of science.
The integration of KGs with LLMs to enhance their response capabilities has been implemented across various domains32,39. Here, we employ the Qwen2 model as the foundation and enhance its retrieval capabilities by incorporating the FMs knowledge graph (Fig. S13). As shown in Fig. 5, we compare the Qwen2 model enhanced with the knowledge graph to other general-purpose models using the structure of BUT-55 as an example. Even with internet-accessible retrieval, the general-purpose models are unable to accurately answer queries regarding to BUT-55. This is because the original text’s abstract does not mention the term BUT-55 specifically, but rather refers to it in the range of BUT-53 to BUT-5837, which poses a challenge for general LLMs. The Qwen2 model, enhanced with the knowledge graph, accurately answers questions about the structure and properties of BUT-55 through Cypher queries. As KGs furnish publication details for literature, LLMs can now provide precise sources of information, effectively addressing the limitations of LLMs in citation and source tracing. In addition to querying material structures, the integration of LLMs with the KG can also provide accurate answers of material properties (Figs. S14–S15), the content of literature (Figs. S16–S17), and material applications (Figs. S18–S19). Furthermore, it can supply specific references, either one or multiple, as needed.

A comparison of the use of a knowledge graph to enhance the LLM question answering and the use of no techniques, taking the structure of BUT-55 as an example.
Subsequently, we adopted an evaluation approach that has been previously used to assess the performance of large language models in the field of MOFs42. We prepared a test set consisting of 150 questions (Table S3) and tested the response accuracy of different general-purpose models as well as open-source models combined with knowledge graphs against this set (Table 3). The evaluation criteria for the accuracy of the responses were determined by two domain experts, who judged the correctness and relevance of the answers. An answer was considered correct if it provided the accurate information without any misleading content. The Qwen2-KG model achieved an accuracy rate of 91.67 ± 0.94%, as assessed by the experts based on these criteria. This result further validates the significant advantage of our knowledge graph in enhancing the accuracy and effectiveness of answering questions within the domain of FMs. With the support of the knowledge graph, the Qwen2 model demonstrated a superior ability to comprehend and apply domain-specific knowledge, leading to the provision of more precise and insightful answers in materials science and related fields (Table S4).
CoT can effectively guide structured reasoning, helping models build answers step by step, which significantly advances the reasoning and innovation of LLMs in scientific problems. However, CoT techniques heavily rely on background knowledge. In the absence of sufficient background knowledge, even a well-structured reasoning process cannot yield good answers. Here, we attempt to introduce KG answers before CoT reasoning. As shown in the simple example in Fig. 6, we take the development of SO2 adsorbents for industrial applications as an example and prompt the LLMs to think in a CoT manner. Without using the KG, the LLMs, although clear in their reasoning, recommend materials with suboptimal performance. In this case, LLMs (Prompt by Fig. S13) searched for relevant SO2 information in the Knowledge Graph and passed it to the LLM (Prompt by Fig. S20). After analysis and reasoning (Figs. S21–S23), the LLM recommended a reasonable adsorbent material. In the future, integrating KG with CoT’s thinking process may further enhance its ability for scientific discovery.

The CoT thinking process that enhances LLMs without and with knowledge graphs is used for industrial SO2 adsorbent design.
Discussion
In this study, we leveraged the exceptional natural language processing capabilities of LLMs to curate and examine over 100,000 articles. This extensive collection of textual data enabled us to construct a comprehensive knowledge graph, which encompasses an impressive 2.53 million nodes and 4.01 million relationships. Our research showcases the vast potential of this knowledge graph in enhancing data retrieval, facilitating data mining. and developing sophisticated question-answering systems in conjunction with LLMs. The enhanced LLMs, Qwen2-KG, empowered by a knowledge graph, can precisely respond to inquiries about FMs (accuracy rate 91.67%) and cite the sources of information. Incorporating KGs into the chain-of-thought reasoning of LLMs significantly enhances reasoning quality for a material screening task. The combined use of KGs and LLMs represents a pivotal step forward in AI for scientific research. It is expected that the comprehensive knowledge graphs of various research fields will be developed in the near future, to promote the automation and intelligence of scientific research through integration with AI tools.




Responses