Dimension reduction in quantum sampling of stochastic processes

Introduction
Complex stochastic processes abound across the sciences, from evolutionary biology and chemistry1,2,3,4,5, geophysics and astrophysics6,7, to financial markets8,9,10,11, traffic modelling12, and natural language processing13,14. Given their pivotal role in these fields, it is vital that we can effectively simulate, analyse, and understand stochastic processes. However, the number of possible trajectories that such processes can explore generically grows exponentially over time, limiting the horizon over which we can feasibly study their behaviour. This makes tools and techniques that mitigate this growth in complexity of critical value.
Monte Carlo methods15,16,17 present such a technique. They use generative models to reduce computational resources by sampling from the process one trajectory at a time, and then average over many such sampled trajectories to estimate the expected values of properties of the process. The considerable successes of such techniques notwithstanding, they still suffer from certain drawbacks, such as the need for a (typically large) memory system to carry the information propagated in correlations over time in the process.
Quantum information processing provides a further route to efficient sampling, modelling, and analysis of stochastic processes. Known quantum advantages include quadratic speed-ups in analysing properties such as characteristic functions18, pricing options19,20,21, enhanced expressivity22, and significant reductions in the memory required by models23,24,25. These advantages involve the preparation of quantum sample states (‘q-samples’) that comprise of all possible strings of outputs in (weighted) superposition26. Unlike other quantum approaches to superposing classical data states – such as qRAM27 and variational state preparation28 – the computational complexity of assembling q-samples of stochastic process trajectories need not grow exponentially; they can be constructed through a local, recurrent circuit structure prescribed by the aforementioned quantum stochastic models29,30.
This recurrent circuit is illustrated in Fig. 1. It works by propagating a memory system – which carries information about the correlations between the past and future of the process – to interact with blank ancillae and sequentially assemble the q-sample state timestep by timestep. The circuit depth – and number of ancillae qubits – thus scales only linearly with the number of timesteps. However, as complex stochastic processes often exhibit strong temporal correlations, the requisite dimension of the memory system can grow quite large. We here explore the potential to significantly compress this memory by introducing distortion in the q-sample.

For each timestep a memory system is coupled with a blank ancilla; following an interaction U the ancilla is entangled with the previous timesteps of the q-sample to yield the appropriate marginal q-sample state, whilst the memory is passed forward to interact with the blank ancilla for the subsequent timestep. This sequentially generates the full q-sample state for any desired number of timesteps.
Specifically, we develop a systematic approach to lossy quantum dimension reduction, whereby given a target q-sample circuit we determine a new circuit of fixed memory dimension that assembles an approximation to the original q-sample. Our approach is inspired by matrix product state (MPS) truncation techniques31,32, and exploits a correspondence between MPSs and q-samples33. We show that this approach yields high-fidelity approximations to q-samples corresponding to both Markovian and highly non-Markovian (i.e., strong temporal correlations) stochastic processes. We further discuss the applications of this approach in stochastic modelling34, demonstrating that we can achieve significant compression beyond both current state-of-the-art lossless quantum dimension reduction for quantum models, and lossy compression for classical models, whilst retaining highly-accurate reconstruction of the output statistics.
Results
Framework and tools
Stochastic processes and models
A stochastic process describes a sequence of events that are governed by a joint probability distribution35. For discrete-time, discrete-event stochastic processes, at each timestep t the corresponding event ({x}_{t}in {mathcal{X}}) is described by a random variable Xt, drawn from a joint distribution P(…, Xt, Xt + 1, …). Sequences of events are typically correlated, and we use the shorthand ({x}_{t:{t}^{{prime} }}) to denote the contiguous sequence ({x}_{t},{x}_{t+1},ldots ,{x}_{{t}^{{prime} }-1}). Here we consider stationary (time-invariant) stochastic processes, such that (tin {mathbb{Z}}), and all marginal distributions of any length are shift invariant (i.e., (P({X}_{0:L})=P({X}_{m:m+L})forall min {mathbb{Z}},Lin {mathbb{N}}). We can thus without loss of generality define t = 0 to be the present timestep, and respectively define the full past and future event sequences as (overleftarrow{x}:={x}_{-infty :0}) and (vec{x}:={x}_{0:infty }).
Such stochastic processes can be generated sequentially by a causal model, consisting of an encoding function (f:overleftarrow{{mathcal{X}}}to {mathcal{M}}) that maps from sequences of past observations to a set of memory states ({mathcal{M}}), and an update function (Lambda :{mathcal{M}}to {mathcal{X}}times {mathcal{M}}) that acts on the current memory state to (stochastically) produce the next output and update the memory state accordingly. Such models are also unifiliar, such that Λ has a deterministic update rule for the memory given the input memory state and output event36. Amongst all classical causal models that reproduce the exact statistics of the process, the provably-memory-minimal (both in terms of information stored and memory dimension) is the ε–machine, prescribed by an encoding function fε that satisfies ({f}_{varepsilon }(overleftarrow{x})={f}_{varepsilon }({overleftarrow{x}}^{{prime} })iff P(vec{X}| overleftarrow{x})=P(vec{X}| {overleftarrow{x}}^{{prime} }))36. The corresponding memory states (sin {mathcal{S}}) are referred to as the causal states of the process37.
Quantum models and q-samples
It is possible to push the memory cost below classical limits when using quantum encoding and update functions, even though we are considering classical stochastic processes29,30,38,39,40. Such quantum models use an encoding function that maps to quantum states, and the update function is a quantum channel. The current state-of-the-art causal quantum models are based on an encoding function fq that, like the classically-minimal encoding function fϵ, maps pasts to the same memory state iff they belong to the same causal state30; we denote the quantum memory state corresponding to causal state sj as (vert {sigma }_{j}rangle). These memory states are defined implicitly by the update function, which can be expressed in terms of a unitary operator U:
where P(x∣j) is the probability that the next symbol is x given we are in causal state sj, λ(x, j) is an update rule that outputs the updated memory state label, and {φxj} are a set of real numbers. By measuring the second subsystem after this evolution, we obtain the output event for the next timestep, and leave the memory state in the first subsystem, appropriately updated. Repeating this procedure multiple times with fresh ancillae initialised in (leftvert 0rightrangle), the statistics can be replicated for any desired number of timesteps (see Fig. 1). This expression defines a valid evolution for any choice of {φxj}, though each choice defines a different set of memory states – and thus yields different memory costs30. These parameters thus constitute a tunable element of the model; nevertheless, any choice will yield a memory cost that does not sit higher than that of the classical minimal model, neither in terms of information stored or dimension.
Suppose we do not measure the output subsystem at each timestep. If we preserve this at every timestep, then we will build a large entangled state that is a weighted superposition over all possible trajectories29. If we set all {φxj} to 0, then after L steps we obtain the state ({sum }_{{x}_{0:L}}sqrt{P({x}_{0:L}| j)}vert {x}_{0:L}ranglevert {sigma }_{lambda ({x}_{0:L},j)}rangle). We can then perform an operation on the final subsystem, conditioned on knowledge of the initial state label j and controlled by the other subsystems, to deterministically set it to (leftvert 0rightrangle). This leaves us with the corresponding L-step q-sample:
This harnesses the temporal structure of the data to enable a recurrent circuit that assembles the q-sample to any desired number of timesteps L. The associated circuit depth grows only linearly with L, as the circuit invokes the same circuit primitive U at each timestep; see the illustration in Fig. 1. The capacity to prepare such q-samples efficiently is a key component for enabling quantum speed-ups in stochastic analysis18.
However, there is still an implicit cost that grows with the complexity of the process – the size of the memory system. In practical terms, this can be quantified by the number of qubits required for the memory, i.e., ({D}_{q}:={log }_{2}(d)), where d is the dimension of the memory. This dimension is upper-bounded by the number of memory states, though can be lower when they exhibit linear dependencies23,30. Also of relevance is the amount of information stored within the memory, i.e., the von Neumann entropy of the memory states. That is, Cq: = S(ρ), where (rho :={sum }_{j}P(j)vert {sigma }_{j}rangle langle {sigma }_{j}vert) is the steady-state of the memory system. Clearly, we must have that Cq ≤ Dq; for many stochastic processes we even find that Cq ≪ Dq41,42,43,44. This indicates that much of the memory capacity is under-utilised given the amount of information that must be stored. In turn, this suggests that it may be possible to drastically reduce the memory dimension whilst discarding very little information, and thus assemble high-fidelity approximations to q-samples with drastically reduced memory size. Doing so would reduce the memory cost involved in achieving quantum speed-ups using q-samples, as well as reducing the gate complexity of each U. This is thus the focus of our work.
MPS representation of q-samples
MPSs are a powerful tool for finding efficient representations of one-dimensional (1D) quantum systems and simulating their evolution31,45,46,47,48. A general 1D quantum chain can be brought into MPS form by a series of Schmidt decompositions bipartitioning each neighbouring pair of sites of the chain, resulting in a series of site matrices ({{A}_{kj}^{x,[l]}}), where l represents the site index, x the label of the corresponding local basis state on that site, and j and k are the so-called ‘bond’ indices between sites. For a 1D quantum chain with state ({sum }_{{x}_{1},ldots ,{x}_{L}}{a}_{{x}_{1},ldots ,{x}_{L}}leftvert {x}_{1},ldots ,{x}_{L}rightrangle), we then have that (,text{Tr},({A}^{{x}_{1},[1]}ldots {A}^{{x}_{L},[L]})={a}_{{x}_{1},ldots ,{x}_{L}}). For infinite, translationally-invariant chains the site matrices are homogenous, and the site index can be dropped (see Fig. 2 for a diagrammatic representation); these are referred to as infinite MPS (iMPS)31. To determine amplitudes for contiguous subregions of the chain, the trace can be replaced by appropriate boundary vectors. See Methods A for further details on MPS, including discussion of their canonical forms.
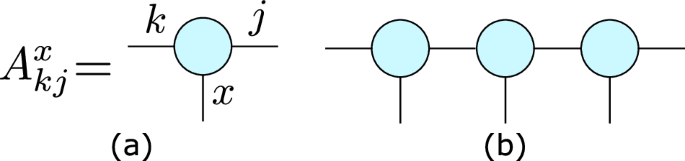
a Each site of a 1D quantum chain can be described by a site matrix ({A}_{jk}^{x}), where x is the physical index corresponding to the local state, and j and k are bond indices carrying correlations between sites. b The full MPS is constructed by joining together these site matrices by multiplying (`contracting’) over the bond indices.
Given that q-samples (see Eq. (2)) are a form of 1D quantum state, they can be recast in an MPS representation46. For q-samples corresponding to the output of a stationary stochastic process, a valid choice of site matrices is given by
where δjk is the Kronecker delta33. For q-samples generated by models with non-zero ϕxj, these can be constructed by appending the appropriate phase factors to the elements in Eq. (3)49. Moreover, the left canonical form of this MPS has site matrices corresponding to the Kraus operators of the channel acting on the memory system in Eq. (1), and the associated Schmidt coefficients for the bond correspond to the spectrum of the steady-state of the memory system used to assemble the q-sample—and thus readily reveal the associated memory costs33.
Quantum dimension reduction for q-samples
A key utility of the MPS representation of 1D quantum chains is that they present a means of identifying efficient representations of the underlying quantum state50. While in principle the dimension of the bond indices can grow exponentially with the length of the chain, for chains that correspond to the ground state of gapped local Hamiltonians the number of non-neglible Schmidt coefficients in each bond tends towards a constant. That is, the number of bond indices carrying non-negligible correlations between sites remains finite even in the thermodynamic limit. This is because such Hamiltonians satisfy an ‘area law’, where the entanglement in the ground state is non-extensive. Crucially, we can then discard the remaining Schmidt coefficients and construct a close approximation of the MPS with finite bond dimension, leading to an efficient, high-fidelity approximate representation of the quantum state.
We apply this approach to q-samples and their assembly by recurrent quantum circuits. That Cq, the information stored by the memory generating a q-sample, is often bounded for many classes of complex stochastic processes suggests a form of ‘temporal area law’ for stochastic process q-samples. We capitalise upon this to identify high-fidelity approximations to q-samples with memory size ({tilde{D}}_{q},ll, {D}_{q}), and prescribe the corresponding quantum circuits to efficiently assemble them.
To quantify the accuracy of our approximate q-samples, we will use the quantum fidelity divergence rate (QFDR)32. This extends the notion of quantum fidelity (i.e., state overlap) from finite-dimensional states to infinite length chains. This is because any distortion introduced in the state at each timestep will – no matter how small—result in the fidelity between the states of the infinite chain going to zero. The QFDR RF therefore captures the rate at which this distortion reduces the fidelity on a per timestep basis. Specifically,
where (F(leftvert psi rightrangle ,leftvert phi rightrangle )=| langle psi | phi rangle |) is the quantum fidelity between states, (leftvert {P}_{L}rightrangle) is shorthand for the L-length q-sample (leftvert P({X}_{0:L})rightrangle), and (leftvert Prightrangle) the L → ∞ limit of this. Given iMPS representations {Ax} and ({{{A}^{{prime} }}^{x}}) of (leftvert Prightrangle) and (leftvert {P}^{{prime} }rightrangle) respectively, this quantity is efficiently calculable, and can be expressed in terms of the leading eigenvector of the matrix ({sum }_{x}{A}^{x}otimes {({{A}^{{prime} }}^{x})}^{* }), where A* is the element-wise complex conjugate of A32,51. The QFDR provides an intensive measure that allows us to quantify the rate (with respect to length) that two infinite, translationally-invariant one-dimensional quantum chains—or equivalently, matrix product states or q-samples – become distinguishable32. Specifically, the inverse of the QFDR gives the length (in the asymptotic limit) over which the fidelity of the two states halves.
Theoretical bounds
The direct form of truncation for MPSs is to reduce them to their canonical form, keep the (tilde{d}) largest Schmidt coefficients at each bond (where (tilde{d}) is the desired final bond size), discard the rest, and then uniformly rescale the remaining Schmidt coefficients such that the resulting MPS is appropriately normalised48,52,53,54. For the case of q-samples, described by iMPS, we can upper-bound the QFDR RF in terms of the magnitude of the discarded Schmidt coefficients.
Theorem 1
Consider a q-sample (leftvert Prightrangle) for which the iMPS representation has d Schmidt coefficients {λj} labelled in decreasing order. For any truncated dimension (tilde{d}), there always exists a q-sample (leftvert tilde{P}rightrangle) that can be constructed sequentially with a memory of at most dimension (tilde{d}) that satisfies
for any (Lin {mathbb{N}}), where ({epsilon }_{tilde{d}}:=mathop{sum }nolimits_{k = tilde{d}+1}^{d}{lambda }_{k}).
The proof is given in Methods B. Moreover, by setting (L sim 1/2{epsilon }_{tilde{d}}) we obtain that ({R}_{F}(leftvert Prightrangle ,leftvert tilde{P}rightrangle )le O({epsilon }_{tilde{d}})). Thus, we see that the QFDR grows only linearly with the sum of discarded Schmidt coefficients. By choosing (tilde{d}) such that ({epsilon }_{tilde{d}}) is sufficiently small, we can therefore control the distortion between the target q-sample and its reduced memory approximation.
However, this does not by itself carry any guarantees that such a (tilde{d}) is much smaller than the original memory dimension d. In the following theorem and corollary we establish a relationship between the information cost of the q-sample, the truncated memory dimension, and the size of the sum of discarded Schmidt coefficients.
Theorem 2
Given an iMPS with d ≥ 3 non-zero Schmidt coefficients, and its approximation by truncation to the largest (tilde{d}ge 3) Schmidt coefficients, the sum of the truncated Schmidt coefficients ({epsilon }_{tilde{d}}) is bounded as follows
where H(λ) is the Shannon entropy of the Schmidt coefficients.
The proof is given in Methods C. By recasting this theorem in terms of q-samples and by further loosening Eq. (6) we obtain the following corollary:
Corollary 1
Consider a q-sample (leftvert Prightrangle) for which the iMPS representation has d ≥ 3 non-zero Schmidt coefficients and can be constructed sequentially by a memory with an information cost Cq. Consider also an approximation to this q-sample (leftvert tilde{P}rightrangle) with truncated dimension (tilde{d}ge 3) formed by truncating the (d-tilde{d}) smallest Schmidt coefficients of (leftvert Prightrangle). The sum of the truncated Schmidt coefficients ({epsilon }_{tilde{d}}) satisfies
where ({tilde{D}}_{q}:={log }_{2}(tilde{d})).
Further, by combining this with Theorem 1, we have that for any q-sample (leftvert Prightrangle) of memory dimension d ≥ 3 and information cost Cq, there exists a q-sample (leftvert tilde{P}rightrangle) of memory dimension (tilde{d}) that approximates (leftvert Prightrangle) satisfying
where ({tilde{D}}_{q}={log }_{2}(tilde{d})). This indicates that if Cq ≪ Dq, there is significant scope for truncating the memory dimension without introducing significant error, affirming our earlier intuition.
Computational Approach
To carry out our quantum dimension reduction for q-sample construction, we use the variational truncation approach for iMPS, based on tangent-space methods32,55,56. Given an injective iMPS (An injective iMPS is one for which the transfer matrix ({sum }_{x}{A}^{x}otimes {({A}^{x})}^{* }) has a non-degenerate leading eigenvalue of 1. The q-sample of an ergodic stochastic process corresponds to an injective iMPS representation.) {Ax} of bond dimension d, this approach seeks to find an injective iMPS ({{tilde{A}}^{x}}) of dimension (tilde{d}) of maximum fidelity with the target iMPS. This is equivalent to finding the iMPS representation of a q-sample (leftvert tilde{P}rightrangle) with memory cost ({tilde{D}}_{q}={log }_{2}(tilde{d})) that minimises the QFDR with respect to a target q-sample (leftvert Prightrangle) with memory cost ({D}_{q}={log }_{2}(d)). We then use the iMPS representation of the approximating q-sample to prescribe a circuit that can be used to construct it. The procedure is summarised in the box “Variationally-truncated q-samples”.
This computational approach involves several MPS gauges: the left and right canonical forms Al and Ar, and the mixed gauge {Ac, C}, explained in detail in Methods A. Specifically, it relies on the fact that the minimality condition for the QFDR can be expressed in terms of a tangent-space projector of the iMPS, which has an explicit representation in the mixed-gauge canonical form of the iMPS. Here we outline the computational steps; further details on how and why this approach to iMPS truncation works can be found in ref. 32.
For the initial stage, the first step involves randomly generating an initial ansatz injective iMPS for (tilde{A}) of bond dimension (tilde{d}), and determining its associated left and right canonical forms and mixed gauge tensors. Similarly, we use Eq. (3) to obtain the iMPS representation of the target q-sample, and calculate the associated left and right canonical form.
In the second step we then construct the left and right mixed transfer matrices, defined as follows:
Subsequently, we perform an eigendecomposition on these matrices to find their leading eigenvalue η, and associated left (for ({bar{{mathbb{E}}}}_{l})) and right (for ({bar{{mathbb{E}}}}_{l})) leading eigenvectors Gl and Gr respectively.
In the third step we use these eigenvectors to update our truncated ansatz iMPS, according to
Then, as the fourth step we calculate the left and right canonical form of this new ansatz. We feed this back in to step 2 and iterate until the error Δ falls below a predetermined threshold, where
These steps are illustrated diagrammatically in Fig. 3.
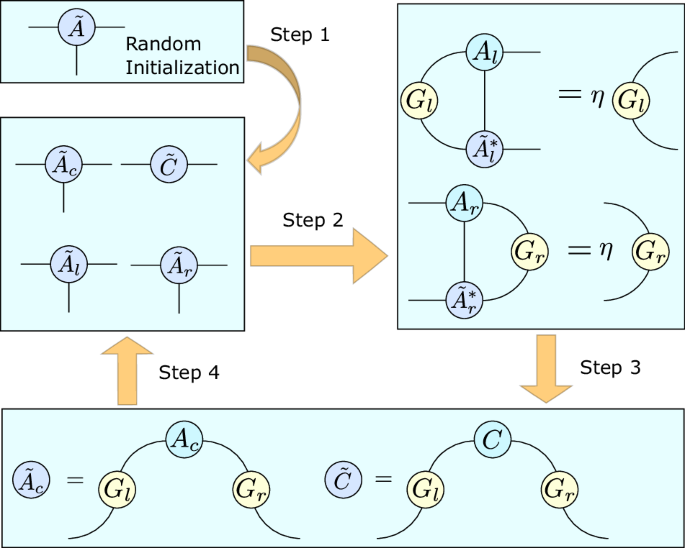
From an initial ansatz iMPS an iterative approach is employed where at each iteration a new ansatz is generated that is closer (i.e., has lower QFDR) to the target iMPS, and used as the input for the next iteration. The steps are repeated until the error falls below a predefined threshold.
We remark that in precursor work we compared this approach also with the direct truncation approach, i.e., where only the (tilde{d}) largest Schmidt values are kept and the rest discarded, and found that the variational approach achieved stronger performance, and was more stable due to explicitly preserving injectivity of the MPS49. One could also consider a two-step approach, where the direct truncation is fed into the variational approach as the initial ansatz.
There is a computational cost associated with the variational truncation method. Specifically, the computational complexity scales as (O(d{tilde{d}}^{2}| {mathcal{X}}| +{d}^{2}| {mathcal{X}}{| }^{2}))32. Note however that this cost is incurred only once, in the initial stage where the truncated q-sample construction is determined—and consists wholly of classical resources. In contrast, our main concern here—the memory cost of assembling the q-sample—involves quantum resources, and is a cost incurred every time we make use of the quantum model and thus dominates once a model is used sufficient number of times.
The final stage is to turn this reduced-dimension iMPS (tilde{A}) into a quantum circuit that assembles the approximating q-sample. To do this, we find the left canonical form ({tilde{A}}_{l}) of (tilde{A}), which satisfies ({sum }_{x}{({tilde{A}}_{l}^{x})}^{dagger }{tilde{A}}_{l}^{x}={mathbb{I}}). That is, the ({tilde{A}}_{l}^{x}) define a valid set of Kraus operators for a completely-positive, trace-preserving (CPTP) quantum channel ({mathcal{E}}(cdot )={sum }_{x}{tilde{A}}_{l}^{x}cdot {({tilde{A}}_{l}^{x})}^{dagger }) acting on a system of dimension (tilde{d})33,46. Taking this system to be the memory used to assemble the q-sample, we can dilate this into a unitary operator (tilde{U}) such that for all basis states ({leftvert jrightrangle }) of the memory system,
The remaining elements of (tilde{U}) which act on initial states of the ancilla orthogonal to (leftvert 0rightrangle) can be assigned arbitrarily, provided they preserve the unitarity of (tilde{U}) (This can be achieved using a Gram-Schmidt procedure29). It can be shown that recursively applying (tilde{U}) with a fresh ancilla at each timestep will then assemble the q-sample (leftvert tilde{P}rightrangle) associated with the iMPS (tilde{A}), with the initial condition dependent on the initial memory state.
We can use the left canonical form to determine the appropriate state to initialise the memory in given some specified conditional past. For a past x−L:0, we prepare the memory in ({tilde{f}}_{q}({x}_{-L:0}):={rho }_{{x}_{-L:0}}propto {tilde{A}}_{l}^{{x}_{-L:0}}rho {({tilde{A}}_{l}^{{x}_{-L:0}})}^{dagger }), where ρ is the fixed point of ({mathcal{E}}), ({A}^{{x}_{0:L}}:={A}^{{x}_{L}-1}ldots {A}^{{x}_{1}}{A}^{{x}_{0}}), and the proportionality is such that the state is appropriately normalised. To assemble the q-sample with no conditioning on the past, the memory should be initialised in ρ, i.e., the steady-state, or purification thereof.
As with the truncation, there is a computational cost associated with determining a gate decomposition of (tilde{U}) in order to construct the appropriate quantum circuit. This cost is also a one-off cost, and involves only classical resources. While the specific scaling depends on particular details such as the gate set involved, and the process embedded in the q-sample, gate decomposition often scales very unfavourably with increasing numbers of qubits in the circuit. Since gate decomposition is a cost also incurred for q-sample assembly without the truncation, by reducing the memory dimension our truncation approach will actually generally contribute to (significantly) reducing the cost compared the the bare untruncated construction.
Variationally-truncated q-samples
Inputs:
({mathcal{P}}) – the target process.
(tilde{d}) – the desired truncated memory dimension.
Δthresh – the desired error tolerance.
Outputs:
(tilde{U}) – the unitary dynamics to generate the truncated approximate q-sample (leftvert tilde{P}rightrangle).
({tilde{f}}_{q}) – the encoding map from pasts to truncated memory states.
Algorithm:
-
1.
Obtain an iMPS representation of (vert Prangle), the q-sample of ({mathcal{P}}), according to Eq. (3) and calculate the associated left and right canonical forms Al and Ar.
-
2.
Determine the iMPS representation (tilde{A}) of the truncated q-sample (leftvert tilde{P}rightrangle):
-
(a)
Randomly initialise tensor (tilde{A}) with dimension (tilde{d}).
-
(b)
Compute the left and right canonical forms of (tilde{A}), ({tilde{A}}_{l}) and ({tilde{A}}_{r}), and the mixed gauge ({{tilde{A}}_{c},tilde{C}}).
-
(c)
Compute leading eigenvalue and eigenvectors η, Gr, Gr according to ({G}_{l}{bar{{mathbb{E}}}}_{l}=eta {G}_{l}) and ({bar{{mathbb{E}}}}_{r}{G}_{r}=eta {G}_{r}), using the definitions Eq. (9).
-
(d)
Update ({tilde{A}}_{c}to {G}_{l}{A}_{c}{G}_{r},tilde{C}to {G}_{l}C{G}_{r}).
-
(e)
Evaluate Δ using Eq. (11).
-
(f)
Repeat (b)-(e) Until Δ < Δthresh.
-
(a)
-
3.
Determine (tilde{U}):
-
(a)
Calculate the left canonical form ({tilde{A}}_{l}^{x}) of (tilde{A}).
-
(b)
Define the associated columns of (tilde{U}) according to Eq. (12).
-
(c)
Use the Gram-Schmidt procedure to fill the remaining columns of (tilde{U}), preserving unitarity.
-
(a)
-
4.
Determine ({tilde{f}}_{q}):
-
(a)
Determine the fixed point ρ of ({mathcal{E}}(cdot )={sum }_{x}{tilde{A}}_{l}^{x}cdot {({tilde{A}}_{l}^{x})}^{dagger }).
-
(b)
Define ({tilde{f}}_{q}) according to ({tilde{f}}_{q}({x}_{-L:0}):=frac{{tilde{A}}_{l}^{{x}_{-L:0}}rho {({tilde{A}}_{l}^{{x}_{-L:0}})}^{dagger }}{,text{Tr},left({tilde{A}}_{l}^{{x}_{-L:0}}rho {({tilde{A}}_{l}^{{x}_{-L:0}})}^{dagger }right)}).
-
(a)
Examples
We demonstrate the application of our quantum dimension reduction with two illustrative examples that capture two different extremes of stochastic processes with high memory cost. The first are cyclic random walks, which are Markovian processes with large event alphabets42. The second is the sequential read-out of a Dyson-Ising spin chain, which manifests a highly non-Markovian stochastic process41. In both cases, our algorithm is able to identify new quantum circuits that reconstruct the ideal q-sample with low QFDR, and yet have drastically reduced memory cost compared to the original circuit. In Methods F we compare these results with the bounds indicated by our theoretical heuristics.
Cyclic random walks
A cyclic random walk describes the stochastic motion of a particle on a ring, as depicted in Fig. 442. Without loss-of-generality, the length of the ring can be taken to be one unit, such that the position of the walker is given by y ∈ [0, 1), where due to the periodicity of the ring positions outside of this range can be mapped back within it by taking the fractional component (e.g., Frac(5.46) = 0.46). At each timestep the walker shifts its position by a stochastic increment x, i.e.,
where x is drawn from some distribution Q(X).

At each timestep, the walker shifts position around the ring by some stochastic variable X; yt+1 = Frac(yt + x).
It is clear that this constitutes a Markovian process, as the next position of the walker depends only on its current position and a memoryless stochastic variable. However, exact specification of the current position of the walker is given by a real number, and so to avoid this divergence in memory cost we consider approximations based on n-bit discretisations of the current position. The natural approach to this discretisation is to divide the ring into N = 2n segments of equal length, labelled Ik, i.e., ({I}_{k}=left{y:leftvert y-k/Nrightvert < 1/2Nright}). We then describe the approximate position of the walker according to the interval its position belongs to, and denote this state as Sk. The corresponding Markov chain is then found by integrating Q(X) over these regions to obtain a distribution P(Sk∣Sj) = P(Yt+1 ∈ Ik∣yt ∈ Ij). It can be shown that the {Sk} correspond to the causal states of the process42.
Since each interval carries equal probability mass, this means that for general Q(X) the memory-minimal unifilar classical model not only requires N memory states, but also has an information cost of ({log }_{2}(N)). In contrast, it has been shown that for several families of distribution for Q(X), the quantum information cost Cq can remain finite as N → ∞, even while dq diverges as N, akin to the classical model42. Such scenarios present an excellent opportunity to test our lossy dimension reduction for constructing q-samples of these processes, and demonstrate Theorem 1 in action.
As a concrete example, we consider the case where Q(X) is uniformly distributed over the interval [− 0.1, 0.1], and 0 elsewhere. We examine the perfomance of our reduced memory q-sample circuits for truncated dimensions ({tilde{d}}_{q}={3,5,7}). The corresponding QFDRs RF are plotted in Fig. 5(a). We remark that for N → ∞, Cq ≈ 3.4 for this process, and so even with ({tilde{D}}_{q}le {C}_{q}), we can maintain a reasonably high degree of accuracy (distortion O(10−2)bits/timestep). As a further example, we carry out a similar computation for Q(X) taking the form of a normal distribution with zero mean and width 0.1, finding qualitatively similar results [Fig. 5(b)]. In this case, we find that even at N = 256, our method can achieve distortions below 10−6bits/timestep with a memory dimension of only ({tilde{d}}_{q}=7) – substantially reducing the memory cost involved in generating the associated q-sample.
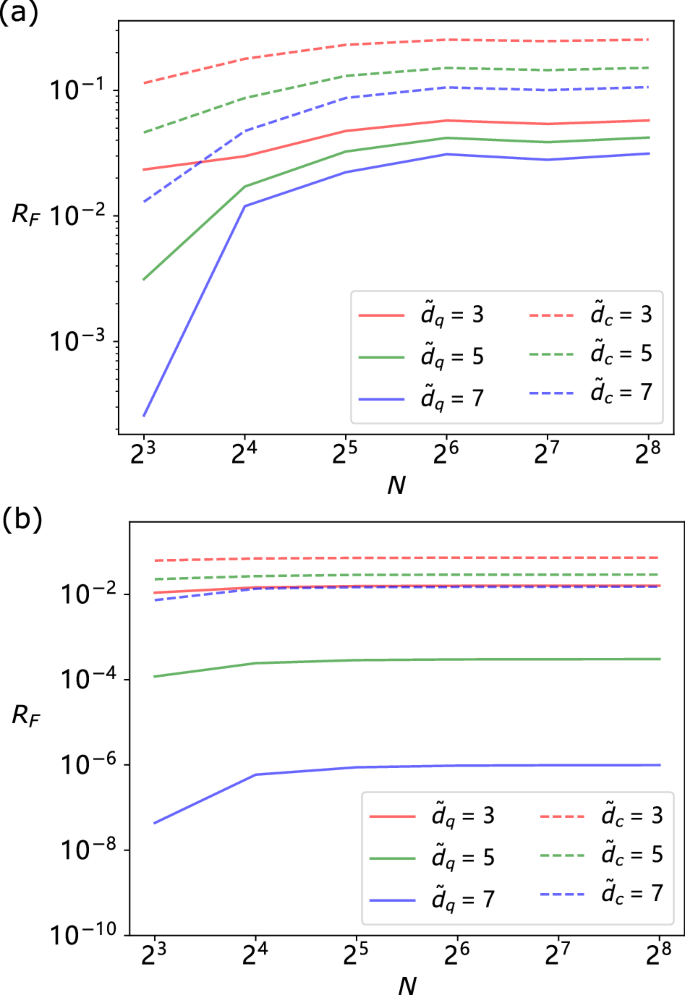
We plot the QFDR RF of reduced memory quantum circuits to generate q-samples of such processes. This is an upper-bound on the corresponding statistical FDR of a quantum model of the process. We also plot the statistical FDR for dimension-reduced classical models, showing inferior performance to the quantum models. a Cyclic random walk with uniformly distributed shifts; b cyclic random walk with normally distributed shifts.
Dyson-Ising spin chains
The Dyson-Ising spin chain generalises the Ising model to non-neighbouring interactions57,58. Its dynamics are described by the (classical) Hamiltonian
where σj is the spin at site j, taking on values { ± 1}. The interaction takes the form J(j, k) = J0/∣j − k∣δ for some interaction strength scaling J0 and decay rate δ. This infinite-range interaction is then typically approximated by a finite-length truncation, where J(j, k) is set to zero for ∣j − k∣ > L for truncation length L; we denote the corresponding Hamiltonian as ({H}_{{rm{DI}}}^{(L)}).
Consider the thermal state of this Hamiltonian at temperature T. The probability of a given spin configuration ({overleftrightarrow{sigma}}) is given by
where the normalisation Z is the partition function. This can be viewed as a stochastic process, where we sweep sequentially along the chain spin by spin, and consider the distribution for the state of the next spin given the previous spins seen41. It can be shown that the corresponding conditional distribution for a given site is a function of only the last L spins – it is a Markov order L process. Thus, as L is increased the non-Markovianity of the process increases.
Moreover, each of the 2L possible configurations of these last L spins gives rise to a different conditional distribution. Each such configuration thus corresponds to a causal state of the process, and so the minimal unifilar classical model requires 2L memory states. Previous study of these models has shown that the classical information cost is a monotonically-increasing function of T, and asymptotically tends towards L as T → ∞41.
Meanwhile, it can be shown that there exists a quantum model with an information cost Cq of at most 1 qubit for any L and T41. Nevertheless, the memory states still inhabit a 2L-dimensional space, akin to the classical models. We therefore ask whether our approach to quantum dimension reduction can be used to find means of constructing high-fidelity q-samples of the Dyson-Ising chain process with at most 1 qubit of memory (i.e., ({tilde{d}}_{q}=2)).
Our findings answer this in the affirmative. As can be seen in Fig. 6(a), for high T our reduced memory q-samples achieve QFDRs below 10−3qubits/timestep, even as L increases.
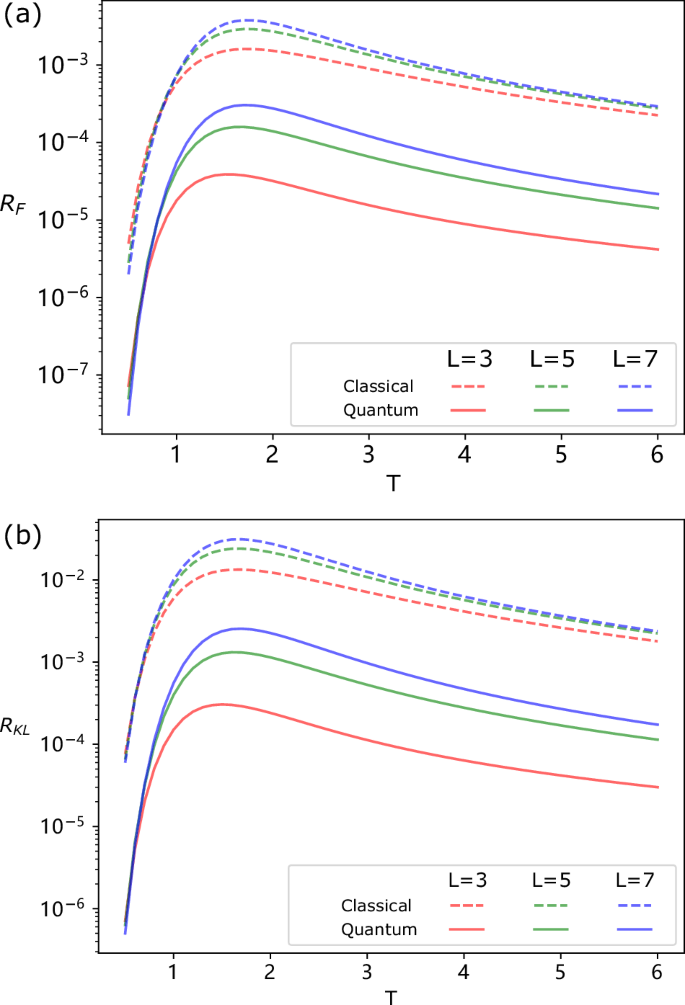
a QFDR RF of reduced memory quantum circuits to generate q-samples of such processes, and statistical FDR for dimension reduced classical models, showing inferior performance to the quantum models. b KL divergence rate RKL of the statistics generated by the reduced dimension q-sample, and lower bound on RKL for reduced dimension classical models. Plots shown for J0 = 1, δ = 2, L = {3, 5, 7}.
Application to quantum stochastic modelling
As is evident from our presentation of the framework, there is a clear connection between q-samples and quantum stochastic models. Our approach to quantum dimension reduction for sequential q-sample generation thus also corresponds to an approach for quantum dimension reduction for the memory of quantum stochastic models. Indeed, the truncated unitary dynamics (tilde{U}) and encoding function for truncated memory states ({tilde{f}}_{q}) output by our algorithm already define a reduced memory dimension quantum model; all one needs to do is measure the output system at each timestep rather than generate the whole q-sample.
How well do these truncated quantum models perform relative to classical models with truncated memory? We begin by stating a simple—yet important—proposition relating to compressed classical and quantum models of stochastic processes.
Proposition 1
Given a (stationary, discrete-time, discrete-event) stochastic process, suppose there exists a classical model of dimension (tilde{d}) that replicates the statistics of the process to within distortion R, for some suitably-chosen measure of distortion. Then there exists a quantum model of dimension (tilde{d}) of the process with a distortion of at most R.
This follows trivially from the fact that classical models are a subset of quantum models. An explicit means of converting any classical model into a corresponding quantum one has previously been exhibited59. Thus, given any classical model achieving a particular distortion, there exists a quantum model with the same distortion. The question remains of whether there then also exists a quantum model with lower distortion.
For our measure of distortion, we generically encounter the same issue as we did for state fidelity—that similarities of distributions of sequences decay to zero as the length of sequence increases. This similarly motivates the use of statistical divergence rates, which quantify the asymptotic rate at which these similarities decay51. One such measure is the statistical fidelity divergence rate (statistical FDR):
where ({F}^{(S)}(p,q)={sum }_{x}sqrt{p(x)q(x)}) is the statistical fidelity between distributions, and PL represents the probability distribution for length L sequence drawn from the stochastic process. Profitably for our purposes, the QFDR between the q-samples of these two stochastic processes also corresponds to the statistical FDR. When the q-samples have non-zero phase factors (as will typically occur in our dimension reduced approximate q-samples), the QFDR is a strict upper-bound on the statistical FDR. Thus, a low QFDR also corresponds to a low statistical FDR, and hence a good model. Just as the QFDR is an intensive measure of distinguishability for translationally-invariant q-samples, the statistical FDR is an intensive measure of distinguishability for stationary stochastic processes – and has an equivalent operational interpretation in terms of the distance over which fidelity halves.
Thence, we can repurpose our bounds on the performance of truncated q-samples and directly apply them to bound the performance of dimension reduced quantum stochastic models.
Corollary 2
Consider a stochastic process P that can be modelled exactly by a quantum model with information cost Cq and memory dimension d. Let the steady-state of this model have spectrum {λj}, labelled in decreasing order. Then, there exists a quantum model with memory dimension (tilde{d}) of process ({P}^{{prime} }) satisfying the following bounds:
where ({epsilon }_{tilde{d}}:=mathop{sum }nolimits_{k = tilde{d}+1}^{d}{lambda }_{k}) and ({tilde{D}}_{q}:={log }_{2}(tilde{d})).
From the bound ({R}_{F}^{(S)}(P,{P}^{{prime} })le {R}_{F}(leftvert Prightrangle ,leftvert tilde{P}rightrangle )) we can readily read off upper bounds on the distortion of our truncated quantum models using the results for the examples above. We compare these with lower bounds on the distortion of any truncated classical models of the same memory dimension ({tilde{d}}_{c}). The procedure by which these lower bounds can be determined is outlined in Methods D, and displayed alongside the quantum bounds for the cyclic random walk (({tilde{d}}_{c}in {3,5,7})) and Dyson-Ising chain processes (({tilde{d}}_{c}=2), L ∈ {3, 5, 7} in Figs. 5 and 6a respectively, showing significantly—by several orders of magnitude—better performance for the quantum models.
As a further point of comparison, we also consider the KL divergence rate (see Methods E), an analogous quantity to the statistical FDR that is commonly used in machine learning. We calculate the KL divergence rate of our truncated quantum models of the Dyson-Ising chain process, and lower bounds on the same for the truncated classical models; this also demonstrates much superior performance for the quantum models [Fig. 6b]. Note that the same calculation could not be meaningfully made for the cyclic random walks due to the extreme sensitivity of the KL divergence to vanishing probabilities.
Discussion
Quantum sample states are a valuable resource in studying stochastic systems, as they are the requisite input for many quantum algorithms for sampling and analysing their properties. For stochastic processes, such q-samples can be constructed piecemeal, one step at a time. Yet, this requires using an ancillary memory system that carries the information about the correlations in the process, and for complex processes this may require a high-dimensional memory. Here, we have introduced an approach to quantum dimension reduction, wherein this memory size may be reduced. We have provided theoretical heuristics demonstrating that when the amount of information carried by the memory is much smaller than the capacity offered by the size of its memory, a significant reduction in memory size is possible without significant distortion to the resulting q-sample. Further, we prescribed a systematic approach for performing this quantum dimension reduction, and demonstrated its efficacy with two illustrative examples: one a large-alphabet Markovian process, and the other a highly non-Markovian process, showing in both cases high fidelity reconstruction of the respective q-samples is possible with a significantly reduced memory size.
Moreover, we have linked this approach to (quantum) stochastic modelling, where we are tasked with reproducing the output statistics of a stochastic process. Prior works have shown that quantum models of complex stochastic processes often have much less stringent demands on the amount of information that must be stored in memory compared to their classical counterparts25,41,42,43,44. Nevertheless, outside of a small number of examples with explicit constructions23,60,61,62, there are heretofore no known systematic methods for converting this into a reduced memory dimension—or indeed, any guarantees that such a method exists in general for exact modelling. Our approach overcomes this issue by trading off a small distortion in statistics to achieve a potentially large reduction in quantum memory dimension, reducing it commensurately with the amount of information in must store. This complements a similar work that developed a ‘quantum coarse-graining’ approach to dimension reduction in quantum modelling of continuous-time stochastic processes24, providing also theoretical guarantees and a stronger performance than an initial foray into such for discrete-time processes63.
Being based on MPS truncation techniques, our results sit among a growing body of work revealing the broad power of tensor network-based approaches in studying stochastic dynamics and sampling problems. These include improved computational techniques for classical simulation of classical stochastic dynamics (including efficient estimation of high-variance observables)64,65,66,67,68,69, a means of efficiently representing classical and quantum hidden Markov models and general observer operator models33,70,71,72,73, efficient calculation of distances between stochastic processes51, in machine learning and generative modelling (such as ‘Born machines’)72,74,75,76,77,78,79,80,81,82,83, and for classical simulation of memoryful open quantum system dynamics84,85,86. To our knowledge, ours is the first work to explore the use of tensor network techniques to simplify quantum simulation of classical processes.
Another potential future application area is the study of (classical) non-equilibrium stochastic dynamics, where a standard approach involves dynamical Monte Carlo-type methods that sample over individual trajectories3. Here, q-samples—representing a quantum superposition over all possible trajectories—unlock the full suite of quantum sampling tools. Examples include improved efficiencies in estimating expectation values of multi-time observables of the dynamics by using Hadamard tests on multi-site operators87, and quadratic speed-ups in importance sampling and estimating the likelihood of certain stochastic events using amplitude estimation18. Our truncation approach has the potential to drastically reduce the memory resources required for creating such q-samples, and thus, significantly reduce the technological barrier for exploring such potential applications.
More broadly, our approach to quantum dimension reduction for quantum sampling and quantum stochastic modelling may provide a route to leveraging quantum approaches for more efficient feature extraction88,89, a task of vital importance in a world that is becoming ever-increasingly data-rich and data-intensive. We have substantiated that quantum models can in effect do more with less, requiring smaller memories to capture expressivity not possible with larger classical memories. A natural direction for future work in this direction would be to learn quantum models and means of q-sample preparation direct from data90,91, eliminating the need to proceed via a classical model first. Such an approach could then include parameterised circuits aligned to the physical architecture of the quantum device used, and ensure the circuits discovered have efficient gate decompositions. Moreover, by reducing the quantum resources required for such tasks, we bring them increasingly into reach of quantum processors of the nearer future.
Methods
A. MPS Primer
We here provide some further discussion on MPSs to aid the reader in understanding the formalism in the main text. For a more in-depth presentation, we refer the reader to reviews such as refs. 31,92,93.
A particularly useful property of MPSs (and tensor networks in general) is that they have powerful diagrammatic representations. Each tensor is represented by a node with several legs (see Fig. 2), where each leg corresponds to an index of the tensor. For example, a rank-3 tensor, such as the site matrix of an MPS, has 3 legs. When the legs of two tensor nodes join together, this corresponds to a tensor multiplication over these two indices. Any open legs correspond to the remaining indices of the overall tensor. In the case of an MPS, these legs correspond to the physical states at each site.
The transfer matrix of an iMPS {Ax} is defined as
with analogous matrices being defined for general MPS in a site-dependent manner. The left and right leading eigenvectors of ({mathbb{E}}) and denoted by Vl and Vr respectively, with corresponding eigenvalue η (with η = 1 for a normalised MPS), as shown in Fig. 7.
Diagrammatic representation of the transfer matrix of an MPS, and its left and right leading eigenvectors.
A quantum state does not have a unique MPS representation; any transformation of the site matrices ({A}^{x,[l]}to {M}^{[l]}{A}^{x,[l]}{({M}^{[l+1]})}^{-1}) for invertible matrices {M[l]} will correspond to the same state. We can use such transformations to define canonical forms of MPSs. For an (i)MPS in left canonical form Vl is the identity matrix, while for right canonical form Vr is the identity matrix. We denote the corresponding site matrices as ({A}_{l}^{x}) and ({A}_{r}^{x}) respectively. A generic MPS can be brought into the corresponding left (right) canonical form by choosing M (M−1) to be Wl (Wr) that satisfy
These can also be used to define the mixed gauge tensors of an iMPS {Ac, C}, where
We can readily convert between these forms using Ac = AlC = CAr.
These canonical forms can be decomposed into a product of two tensors {Γ, λ} as follows:
Γ is a rank-3 tensor, which, like the A carries a physical index corresponding to the state at the corresponding site. Meanwhile, λ is a diagonal matrix, whose diagonal entries correspond to the (ordered) Schmidt coefficients of the (i)MPS. It can further be shown that the left and right canonical forms satisfy the completeness relations:
Thus, the site matrices of the left canonical form can be interpreted as Kraus operators of a quantum channel; indeed, it is this channel that can be used to sequentially generate the MPS46.
B. Proof of Theorem 1
Our proof of Theorem 1 draws heavily upon the proof of Lemma 1 in ref. 50. Specifically, in the course of said proof it is shown that given a state (vert {psi }_{d}^{L}rangle) with an MPS representation of bond dimension d and L sites, there exists a state (scriptstylevert {psi }_{tilde{d}}^{L}rangle) with an MPS representation of bond dimension (tilde{d}) and L sites formed from discarding the (d-tilde{d}) smallest Schmidt coefficients of (leftvert {psi }_{d}^{L}rightrangle) at each bond that satisfies
where ({epsilon }_{tilde{d}}^{[l]}) is the sum of the discarded Schmidt coefficients at the lth bond. Using that (| langle {psi }_{d}^{L}| {psi }_{tilde{d}}^{L}rangle | le 1), this can be rearranged as
Consider now the case where (leftvert {psi }_{d}^{L}rightrangle) and (vert {psi }_{tilde{d}}^{L}rangle) correspond to (purified) L-length segments of an infinite chain, such that ({epsilon }_{tilde{d}}^{[l]}) is the same at every bond. We can then simplify Eq. (24) to
From the right canonical form of the untruncated iMPS, we can express the site matrices of the two iMPSs as ({{A}_{r}^{x}}) and ({{tilde{A}}_{r}^{x}={A}_{r}^{x}{Pi }_{tilde{d}}}), where ({Pi }_{tilde{d}}) is the projection operator with support on the (tilde{d}) largest Schmidt coefficients. Let ({bar{{mathbb{E}}}}_{r}:={sum }_{x}{A}_{r}^{x}otimes {tilde{A}}_{r}^{x}) be the corresponding mixed transfer matrix, which can be expressed in terms of its eigenvalues {μj} (labelled in descending order) and left (right) eigenvectors (langle {l}_{j}vert) ((vert {r}_{j}rangle)):
We can then express
where (vert Lambda rangle :=mathop{sum }nolimits_{j = 1}^{tilde{d}}{lambda }_{j}vert jrangle vert jrangle) is a vector of Schmidt coefficients for the iMPSs, and (vert Irangle :=mathop{sum }nolimits_{j = 1}^{d}vert jrangle vert jrangle). We will now assume that the largest eigenvalue μ0 is non-degenerate for ease of notation, noting that the following can be readily adapted for the degenerate case. Combining Eq. (25) and Eq. (27) we have
Thus,
Finally, we use that the QFDR can be expressed in terms of the leading eigenvalue of ({bar{{mathbb{E}}}}_{r}):
where in the last line we have used the inequality ((x-1)/xln 2le {log }_{2}x) (This inequality can be readily proven by defining the function (g(x)=1-1/x-ln x), noting that the maximum is at x = 1, and then using that g(x) ≤ g(1) = 0.). This yields the statement of the Theorem.
C. Proof of Theorem 2 and Corollary 1
Our proof of Theorem 2 similarly draws upon ref. 50, mirroring elements of the proof of Lemma 2 therein.
Let us define the following family of probability distributions:
All distributions in this family are majorised by the following distribution ({{bar{p}}_{j}}):
where (f=tilde{d}+lfloor {epsilon }_{tilde{d}}/hrfloor), and ⌊x⌋ denotes the floor of x.
Consider an iMPS with bond dimension d ≥ 3 and Schmidt coefficients λj labelled in decreasing order. Consider also the iMPS of bond dimension (tilde{d}) formed by truncation of the first iMPS to its (tilde{d}ge 3) largest Schmidt coefficients. Define the largest kept Schmidt coefficient (h:={lambda }_{tilde{d}}), and ({epsilon }_{tilde{d}}:=mathop{sum }nolimits_{k = tilde{d}+1}^{d}{lambda }_{k}) the sum of discarded Schmidt coefficients. Noting that the Schmidt coefficients are non-negative and sum to unity, they can be interpreted as a probability distribution. Specifically, they belong to the family of distributions described in Eq. (31), and are thus majorised by the distribution Eq. (32). We further have the following inequalities: (tilde{d}+{epsilon }_{tilde{d}}/hle d) and (hle {bar{p}}_{1}), leading to
Using the Schur-concavity of the Shannon entropy, we thus have that
Thence,
yielding the content of Theorem 2. Corollary 1 then follows by noting that for an iMPS representation of a q-sample Cq = H(λ), ({tilde{D}}_{q}:={log }_{2}(tilde{d})), and loosening the bound in Eq. (35) by noting that the first term in the denominator is non-negative.
D. Reduced dimension classical models
In general it is hard to find the most accurate (i.e., lowest distortion) unifilar classical model of a process with memory size ({tilde{D}}_{c},<,{D}_{mu }). However, we can obtain lower bounds on their distortion by finding bounds on the distortion of a more general class of objects.
In particular, ref. 91 introduced pre-models. Like unifilar models, pre-models have an encoding function that maps from pasts to memory states. However, instead of an update rule that produces the next output and updates the memory state, an L-length pre-model need only produce the next L outputs all at once, and nothing more. It is clear that unifilar models are a subset of L-length pre-models. Therefore, the L-length pre-model with lowest distortion sets a bound on the lowest distortion achieveable by any unifilar model of the same dimension. The formal proofs of these statements are given in ref. 91.
In ref. 91, it was also shown that the memory states of the best L-length pre-model are coarse-grainings of the causal states. Therefore, the distortion can be bounded by a brute force search over all possible coarse-grainings of the original d states into (tilde{d}) states, calculating its minimum value for all possible assignments of transition probabilities.
For a Markovian process, since the most recent output uniquely defines the current causal state, their L = 1-length pre-models are define unifilar models. For cyclic random walks, the number of possibilities for coarse-graining the memory states essentially becomes intractable with increasing N. There is however, a very natural coarse-graining, which is essentially to mimic that of the coarse-graining done of the continuous variable in the case of a smaller N. That is, we consider coarse-grainings based on clustering neighbouring segments only.
Formally, assume the circle is divided into 2n segments, i.e., {S0, S1, …SN−1} where N = 2n. We partition this set into (tilde{d}) sets of non-overlapping, equal-size contiguous segments, to define our coarse-grained states ({{tilde{S}}_{j}}), (jin [0,ldots ,tilde{d}-1]). Let (K=lfloor N/tilde{d}rfloor) and (r=N-Ktilde{d}). Then the coarse-grained state ({tilde{S}}_{j}) contains K + 1 segments if j < r, and K segments otherwise. Specifically, these states are defined as:
We can then derive the associated transition probabilities for these coarse-grained states:
To convert this from a pre-model to a unifilar model, the transition rule is simply that if after output y the non-coarse-grained model would transition to Sk, then on output y the model transitions to the ({tilde{S}}_{j}) to which Sk belongs.
Meanwhile, for reduced dimension classical models with ({tilde{D}}_{c}=1) and two outputs, the topology of possible models is sufficiently limited to allow for a brute force search directly over the set of unifilar models to obtain a tigher bound. Specifically, there are only six possible topologies, as shown in Fig. 8, with each equipped with only two parameters to fully specify the transition probabilities. For the ({tilde{d}}_{c}=2) truncated classical models of the Dyson-Ising chain process we adopt this approach.
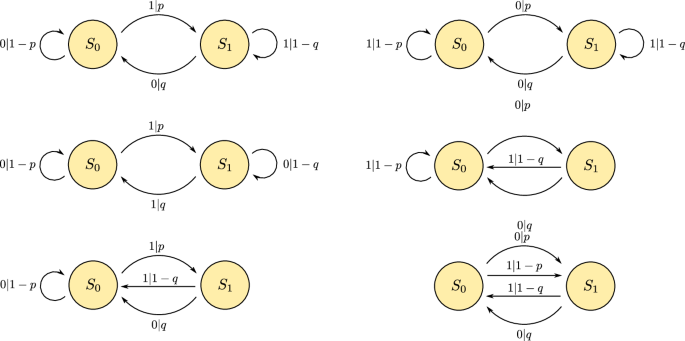
All topologies for two state, two symbol unifilar classical models.
E. Kullback–Leibler divergence
The KL divergence94 is a widely-used quantifier of the distance between two probability distributions P(x) and Q(x), defined as follows:
It is asymmetric in its arguments, and takes on an operational value in terms of the overhead of the cost of communicating messages drawn from Q(x) using a code optimised for P(x).
As with the fidelity, when applied to stochastic processes the KL divergence does not behave well, and will diverge with increasing sequence length. This is fixed by defining a KL divergence-rate that quantifies the asymptotic rate at which the KL divergence grows with increasing sequence length:
F. Numerical Bounds
In Fig. 9, we plot again the fidelity divergence rates RF for our examples in the Results, together with the bounds ({epsilon }_{tilde{d}}/2ln 2) as prescribed by our theoretical heuristics.
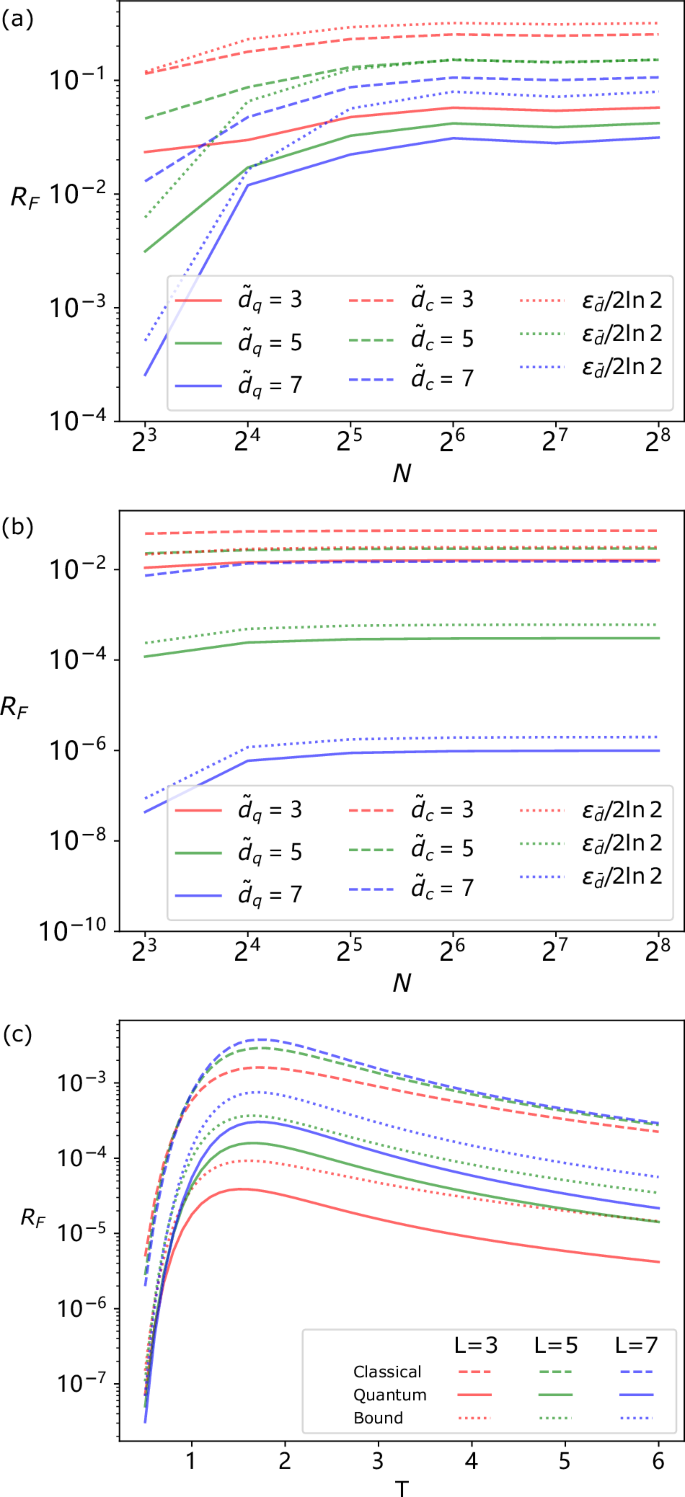
a Cyclic random walk with uniform distribution; b cyclic random walk with normal distribution; and c Dyson-Ising Chain.
Responses