Discovering nuclear models from symbolic machine learning

Introduction
The atomic nucleus, a strongly correlated quantum many-body system, exhibits a vast array of phenomena that cannot be explained by a single, unified theory. This is mainly because the underlying theory of the nuclear force, quantum chromodynamics (QCD), is non-perturbative at low energies1. Despite the exciting progress that has been made in developing a comprehensive characterization of the nuclear force and powerful many-body methods, a theoretical description of all the nuclei, with a direct link to QCD, remains a major unsolved challenge2. Consequently, physicists have developed a myriad of models, each designed to address specific aspects of nuclear structure and reactions. These models range from the simple liquid drop model to sophisticated many-body calculations, which are continuously refined to reproduce available nuclear data, such as binding energies, nuclear radii, electromagnetic moments, excitation energies, and decay properties1,3,4,5,6,7,8. Thus, one hopes that improved models can provide an interpretation of the observed phenomena and predict the behavior of nuclei at the extremes of the nuclear chart, where data is not yet available.
Recent advancements in machine learning (ML) have emerged as a pragmatic tool to tackle this challenge, with the expectation of fitting models that could reproduce the vast amount of available nuclear properties6,9,10,11,12,13,14. Nonetheless, this approach results in black boxes with obscure physical interpretability15,16,17, and often its use is limited to specialized users who can have access to and run specific software. Moreover, conventional ML models rely on extensive experimental data or high-fidelity emulators, which may not always be available and are very prone to over-fitting, drastically limiting their extrapolation power18,19.
An alternative approach is given by symbolic ML, which aims to provide analytical expressions to describe a given observable20,21. This methodology is remarkably similar to how nuclear physicists have traditionally tackled the problem of describing complex nuclear phenomena. Unlike traditional regression techniques that fit data to a pre-specified model, such as linear or polynomial functions, modern symbolic regression approaches do not assume any particular prior model. In contrast, it changes the existing functional forms in an evolutive manner22,23,24. Because of this, discovering complex equations is now conceivable, something that could not be accomplished by evaluating every possible mathematical expression by brute force25,26. These methods have been widely successfully applied in scientific research, including Cosmology27,28, Astronomy29,30, Materials science31,32, Chemistry33, Dynamics34,35, and Particle physics36,37. However, applying existing methods to describe nuclear physics observables poses several challenges, as most of them have not been developed to the simultaneous fitting of several physical quantities using a single underlying mathematical model and/or incorporate experimental uncertainties directly into the model predictions and uncertainty estimation.
In this work, we explore the natural question of whether symbolic ML approaches, with minimal human bias, can rediscover traditional nuclear physics models or propose alternative ones with similar or better simplicity, fidelity, and predictive power. To achieve these goals, we developed a Symbolic Regression technique that can systematically handle regressions over a set of targets, considers experimental uncertainties, and is robust to high-dimensional problems.
Our approach achieves three key results. First, we provide an interpretable model that discovers relatively simple analytical relationships between the number of nucleons and nuclear properties such as the charge radius and binding energy. Second, we use ML techniques to estimate these nuclear observables beyond our current experimental knowledge. Finally, an improved model with quantifiable uncertainties is used to provide predictions of the limits of stability of both neutron-deficient and neutron-rich nuclei.
Results
Symbolic regression for nuclear observables
We developed a multi-objective iterated symbolic regression (MISR) to iteratively search for analytical models that best describe a set of target variables up to arbitrary accuracy, leading to an expansion-like expression to describe an arbitrary observable O of the form:
We build on top of the symbolic regression proposed in ref. 38 to adopt multi-objective capabilities which we use to fit each one of the symbolic expressions f (i), which allows us to fit the description of a set of diverse target variables, considering the associated experimental uncertainty for each variable. A diagrammatic representation of the MISR approach is shown in Fig. 1. It is also worth noting the MISR is, in principle, agnostic to the SR tool to be employed, as it only constitutes a block of the pipeline. Thus a variety of alternative implementations could be used20.

The process iteratively refines the symbolic regressed models. See the “Symbolic Regression for Nuclear Observables” subsection of the Results.
As illustrated in Fig. 1, the main variable refers to the primary target observable that our symbolic regression model aims to predict, such as the nuclear binding energy. Auxiliary variables, on the other hand, are additional target observables related to the main variable that provide supplementary information to enhance the model’s accuracy and robustness. For example, when predicting nuclear binding energy, auxiliary variables might include the binding energy per nucleon and one- and two-nucleon separation energies. It is important to note that all auxiliary variables, such as one- and two-nucleon separation energies, are deterministic functions derived directly from the primary observables, specifically the nuclear binding energies. For instance, the neutron separation energy Sn(Z, N) is computed as Sn(Z, N) = BE(Z, N) − BE(Z, N − 1).
The main variable is regressed via standard symbolic regression. Note that this approach does not yield a single final formula but rather generates a set of candidate formulas through the data-splitting process. This is then used to trace over the Pareto-optimal expressions for minimizing the error over the auxiliary variables in the several k random sub-samples of the data (known as k-folds).
Tracing over these Pareto-optimal expressions involves iteratively refining the models by considering the performance across all auxiliary variables, ensuring a balanced and comprehensive solution. The performance for each one of the expressions also takes into account the experimental error of each data point via weighting the loss by a factor 1/(1 + δp), where δp is the percentage experimental error of the measurement.
This process is then repeated using boosting to fit the residuals of the current analytical model until we reach a stopping criterion39,40. Part of these advances were motivated by the application of multi-objective approaches for dynamic modeling41. For a more detailed understanding, see the pseudocode included in the Algorithm 1.
Unlike traditional regression techniques that offer a static view of feature relevance, MISR continuously re-evaluates the feature importance in each boosting step by averaging the weights of a fitted Boosted Decision Tree39,42 and Mutual Information Regression43. The sampling procedure for selecting a subset of features, Xsub, is performed using a multinomial distribution normalized by these importance scores. This means that features with higher importance scores have a higher probability of being selected. Although the importance scores are not strict probabilities, they act as weights reflecting the relative significance of each feature. This approach prioritizes features that contribute more significantly to the predictive power of the model, thereby enhancing performance and reducing the search space. Additionally, it helps balance the bias-variance tradeoff by including relevant features and controlling overfitting. By capturing different physical behaviors in each iteration, the MISR method systematically refines the model, eliminating redundant or less significant features and improving predictive power.
One of the critical challenges in ML approaches is the quantification of uncertainty in predictive modeling, especially given the often limited and low-precision experimental data that exists for certain nuclear properties. To address this challenge, we incorporate both types of experimental uncertainties into the MISR model. Firstly, we estimate the uncertainties (σi) associated with each symbolic regression prediction using the Jackknife bootstrapping method44. Specifically, we iteratively leave out one data point from the training set, refit the model, and compute the resulting variance in the predictions. This approach ensures robustness against jitter in the experimental data points due to measurement errors. Secondly, we directly incorporate the tabulated experimental uncertainties into the model predictions by linking each one of the model’s predictions to a probability distribution and sampling the posteriors. In addition, we include a truncation uncertainty, for a specific cutoff, given by the absolute value of the subsequent expansion term. This methodology was inspired by an analogy to how effective theories are developed45.
This iterative refinement allows us to express the target data as a sum of the resultant n analytical forms f (i)(N, Z), and estimate the uncertainty of the model. The MISR can thus be expressed as
where N and Z are the input variables, representing the number of neutrons and protons in the nuclei, respectively. And ({varepsilon }_{i}(N,Z) sim {{{mathcal{N}}}}(0,{sigma }_{i})) is a Gaussian distribution numerically fitted after the training process using the Jackknife technique to derive σi44. More information is provided in the Supplementary Information and illustrated in SI. Fig. 9.
We define the nuclear mass as A = N + Z, isospin asymmetry, I = (N − Z)/A, and the Casten factor P = (NnNp)/(Nn + Np), where Np and Nn represent the valence protons and neutrons filling pre-defined shell-model orbits, i.e., the difference between the number of nucleons and the closest magic number {8, 20, 28, 50, 82}46. The model was trained using the input variables {(N, Z, A, I, P, Nn, Np)}. More details of the methodology can be found in the section “Methods” of the Supplementary Information.
As a proof-of-principle of our approach, we focus on the study of nuclear binding energies and charge radii. However, our proposed method can be generally applied to describe other nuclear observables, with an arbitrary set of input variables. Binding energy, the energy required to disassemble a nucleus into its constituent protons and neutrons, provides important information to guide our understanding of atomic nuclei. This observable is arguably one of the most studied nuclear observables, with a relatively large collection of experimental data available. To train our algorithm, we used a subset of the experimental data of binding energies reported in the AME2020 mass evaluation dataset47,48,49, and experimental charge radii reported in50. For the charge radii—characterizing the charge distributions inside the nuclei—there is a more scarce set of experimental measurements51. This is particularly challenging for light isotopes, which, combined with the large variations in their radii, motivated us to focus on nuclei with 12 ≤ Z ≤ 50, for which reliable experimental data exists. From these data sets, we sampled uniformly 20% of the nuclei for testing purposes. The cutoff on light and medium mass nuclei allows us to study the extrapolation capabilities of our algorithm and provide a test of the model’s ability to deduce complex nuclear properties from relatively small data sets. This demonstrates the broader applicability of our MIRS method, which can describe physical observables where data scarcity is common.
Nuclear binding energies
The study of nuclear binding energies has led to the proposal of several analytical formulas. One of the simplest, the liquid drop model (LDM)52, represents the nucleus as a liquid drop to explain its global properties as a function of Z and A:
where av, as, ac, and aa are the volume, surface, Coulomb, and asymmetry coefficients, respectively, and δ(A, Z) represents the pairing term between neutrons and proton computed as
where δ0 is another fitted constant52. More complex empirical models, such as the finite range droplet model (FRDM)53, and the Duflo–Zuker (DZ)54, attempt to incorporate microscopic corrections to these macroscopic trends, refining the reproduction of nuclear binding energies across the chart of nuclides. The DZ model integrates both macroscopic and microscopic aspects of nuclear structure, featuring a wide array of terms to capture various models of nuclear interactions and nucleon configurations. The DZ model is not represented by a concise formula, but rather as a computational tool. This model is relatively complex and includes several terms to numerically account for nuclear shell effects, monopole Hamiltonian contributions, deformation energies, symmetry, and Coulomb energies.
State-of-the-art nuclear models, such as density functional theory (DFT)55 and ab initio calculations56, follow a very different approach. These models aim to provide a microscopic description of nuclei, starting from inter-nucleon interactions and solving numerically the nuclear quantum many-body problem. DFT, in particular, has successfully described the binding energy and radii across the nuclear chart4,57. For ab initio methods, the simultaneous reproduction of both binding energy and nuclear charge radii remains an open challenge1,58.
To explore the multi-objective capabilities of our model, we apply the MISR algorithm to predict the binding energy, using as auxiliary observables the binding energy per nucleon, and the one and two nucleon separation energies across the same Z region, defined as Sn = BE(Z, N + 1) − BE(Z, N), S2n = BE(Z, N + 2) − BE(Z, N), Sp = BE(Z + 1, N) − BE(Z, N), S2p = BE(Z + 2, N) = − BE(Z, N).
At leading order, in the first iteration of MISR, we obtained a relatively simple expression:
with a = −1.10, b = 32.43, c = 16.70, and η0 = 1.0 MeV. Additional MISR iterations, up to n = 10, are presented in the section “Methods” of the Supplementary Information in Supplementary Table IV.
The differences between the experimental values and model predictions for various observables are shown in Fig. 2. These differences decrease as one includes more orders of the MISR expansion, illustrating how the regression converges without a sign of overfitting to the trained region. In principle, one can keep an arbitrary number of terms in the expansion. However, the Pareto Frontier hints it is optimal to keep up to 10 terms. Notably, primary terms, like those resembling LDM structures, reliably emerge in early iterations due to their strong predictive utility, with higher-order terms introducing flexible, data-specific refinements without altering the model’s stability.
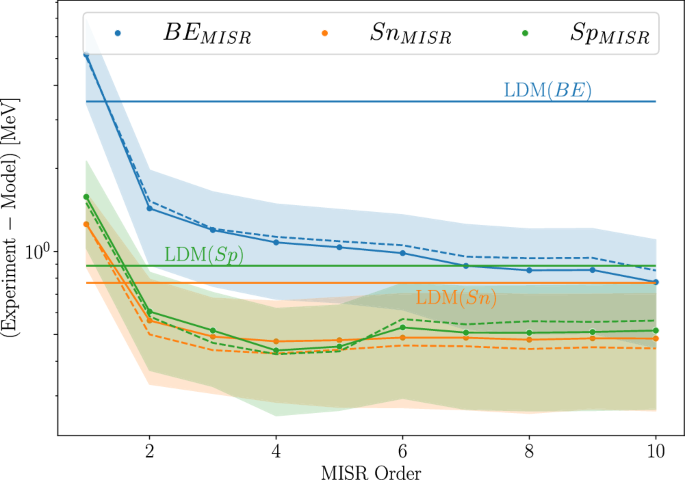
The colored area illustrates the standard deviation of the residuals among the training set and the dashed line shows the mean over the test nuclei. The liquid drop model (LDM) results are illustrated as horizontal lines for reference.
As illustrated in Fig. 2, our MISR results for n = 2 exhibit a significant improvement in the prediction of nuclear binding energies with respect to the LDM. This is also true for the neutron and proton separation energies.
The results for the binding energy per nucleon, BE/A, together with the distribution of their predicted uncertainties are shown in Fig. 3. The ability to provide uncertainty estimates allows for a more robust analysis of the predictive power of the model. This feature of MISR assesses where additional experimental data or refinement of the model might be necessary. The standard deviation σ(BE) of the binding energy predictions, as indicated by the color gradient, tends to correlate with the residual distribution. We remark that the uncertainty is not uniform across the nuclear chart. Instead, the highest uncertainties coincide with the transitional regions between different nuclear shells. These regions are known for increased structural changes that impact nuclear stability and are more challenging to predict accurately. This shell structure effect is illustrated in Fig. 3c. The MISR expansion is well-behaved around closed-shell structures, but its accuracy decreases for open-shell nuclei. The contrary is true for the Duflo–Zuker model, with the discrepancy with respect to the experiment larger around neutron magic numbers.
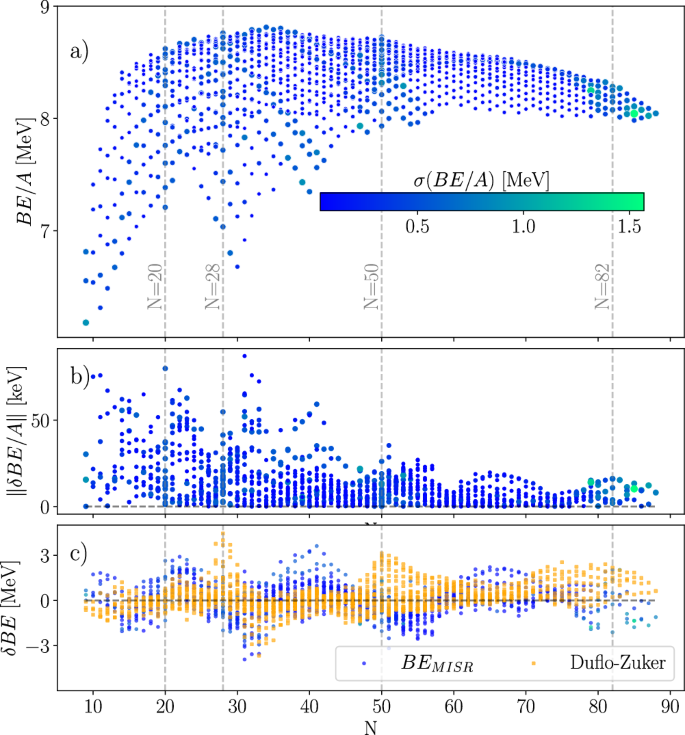
a Predicted binding energy per nucleon (BE/A) as a function of neutron number with associated model uncertainties denoted by the color bar. b Absolute error on ∥BE/A∥ predictions (Experiment − BEMISR), showcasing the distribution of discrepancies for different neutron numbers. c Residuals of the binding energy (Experiment − Model) obtained for our MISR10 results and the Duflo–Zucker models. Vertical dashed lines show the traditional nuclear magic numbers.
In Table 1, we compare the performance of different nuclear models in terms of mean absolute error (MAE) and root mean squared error (RMSE). Note that these results represent only a subset of DFT calculations and do not include the latest DFT developments. MAE is calculated as the average absolute difference between the predicted and experimental values, while RMSE is derived from the square root of the average of the squared differences between the predicted and experimental binding energy values. For comparison, the table includes the results from DFT calculations using different density functionals such as DD-ME259, NL3*60, HFB2461, and UNEDF162. Outstandingly, the MISR10 model shows competitive performance, particularly when considering the fact that it is built on a small number of input variables.
Nuclear charge radii
Now we shift our focus to the study of the nuclear charge radius, rc. This nuclear property is highly sensitive to the details of the inter-nucleon interactions, not yet fully understood. The reproduction of the magnitude of rc is an unresolved challenge for ab initio nuclear theory63.
At leading order, we obtain the first MISR expression to be:
with a = 0.95 fm, b = 1.48 fm, c = 0.017 fm. Additional terms obtained for higher order corrections, up to n = 10, can be found in the section Methods, Appendix V. The first term is analogous to the well-known droplet model for the isospin symmetric case, rc ~A1/3. The second term in this equation shows an exponential dependence on the isospin asymmetry, I, which, to our knowledge, does not appear in other phenomenological models for the charge radii. Similar exponential terms have been proposed in nuclear mass models64.
The difference between the experiment and our MISR results is shown in Fig. 4. The MISR expansion captures the overall trend of the charge radii. We do find a higher residual outlier in the distribution for Z = 34, N = 40 (74Se), which is mainly due to its relatively large experimental uncertainty. Similarly, as with the results obtained for binding energies, the residuals are larger between magic numbers.
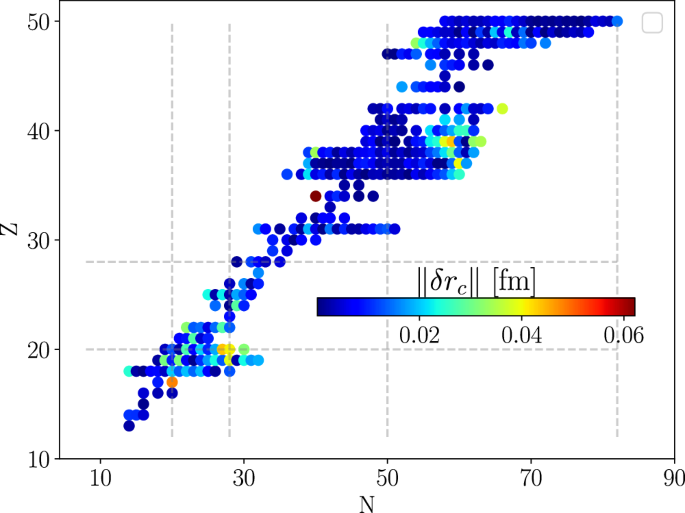
The magnitude of these differences is shown with different colors as a function of the neutron and proton numbers.
The performance obtained on the training and testing sets is shown in Table 2. Our MISR results are contrasted with different DFT calculations in the same table. For comparison, we include an analytical model proposed by Nerlo–Pomorska with Casten modifications65:
where the constants αi are fitted to the experimental data.
Our MISR for the nuclear charge radii exhibits an overall good agreement with the experimental data, which is better than all models presented in Table 2. This is the case even at leading order, Eq. (6), with a simple expression.
While Eq. (6) is obtained by training only on light nuclei, it extrapolates well to heavy nuclei. This is illustrated in Fig. 5. This implies that our multi-objective optimization yields physical information valid across the entire nuclear chart. A similar extrapolation is observed for the binding energy predicted by Eq. (5), which shows a smooth linear increase with the proton number. This suggests that adding a simple linear term in Z can provide a major improvement for heavy nuclei. Such a term would likely appear if large nuclei were included in the training process. We choose not to add this term manually, as our goal is to allow the ML algorithm to discover analytical expressions with minimal human intervention.
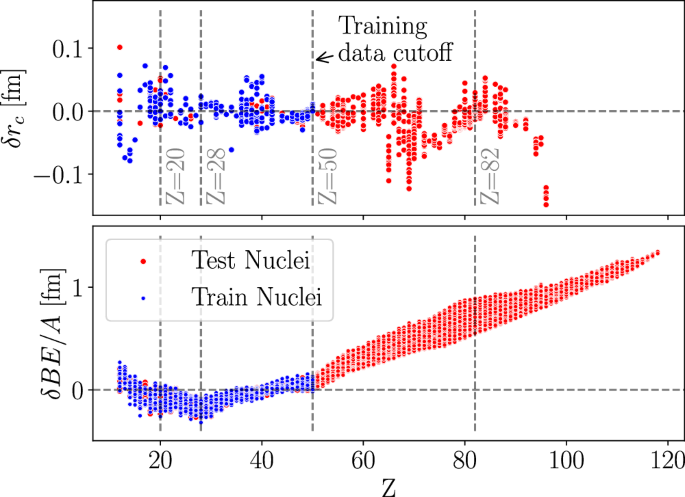
(bottom): Same but for binding energy (Experiment − BEMISR1). MISR was trained only using the blue points.
In contrast to nuclear binding energies, the nuclear charge radii are known to exhibit more complex and distinct behavior across the nuclear chart. In what follows, we explore the performance of our MISR result in describing complex charge radii trends for selected isotopic chains with Z = 18, 20, 22, 25. Our results are compared with the experimental values in Fig. 6.
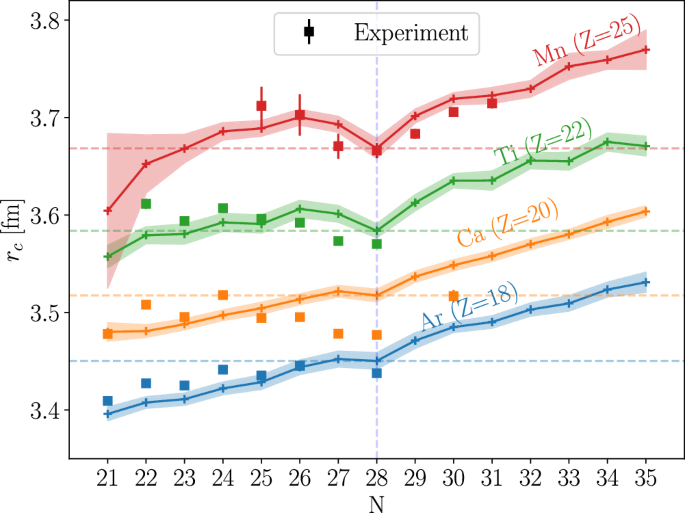
Experimental results66,67,71,72 are contrasted with multi-objective iterative symbolic regression (MISR10) results. The error bars represent the experimental uncertainties and the shaded areas correspond to MISR’s uncertainty.
Overall, the MISR prediction, including uncertainty estimation, provides a good description of the experimental trends. The model captures the expected kinks at magic numbers and part of the odd-even staggering effects, with large discrepancies found for Ca (Z = 20). These isotopes exhibit a unique trend, which is known to be challenging to describe by nuclear theory66,67.
A different, distinct charge radii trend is observed for Krypton (Kr) isotopes (Z = 36). The MISR results are compared with the experiment in Fig. 7. Here, the MISR model performs exceedingly well, capturing all the main features: (i) the kink at N = 50, (ii) a parabolic trend for neutron-deficient isotopes, (iii) staggering between isotopes with odd and even neutron numbers.
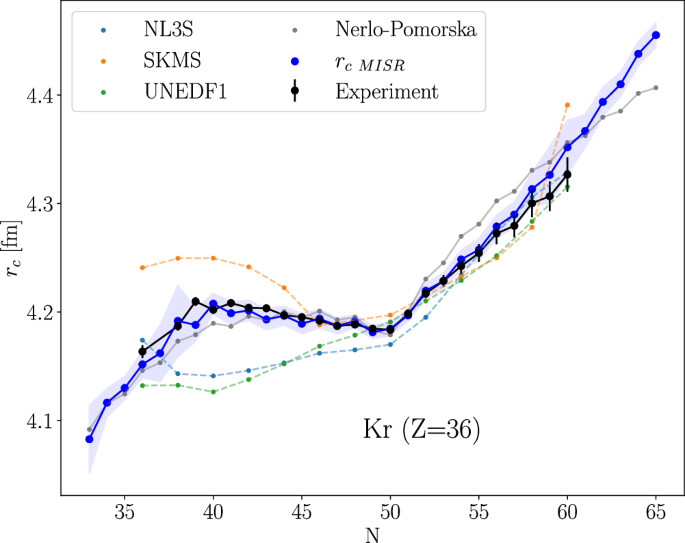
Experimental results71 are compared with different nuclear models. The colored area represents the uncertainty of the multi-objective iterative symbolic regression (MISR) model.
As illustrated in Fig. 7, the analytical formula (NP) from65 also performs relatively well for the particular case of Kr isotopes. The difference between the NP and MISR becomes significant for neutron-rich nuclei.
Limits of the nuclear landscape
Inspired by the fact that our MISR model is highly complementary to the DZ model—MISR excels around closed shells, while DZ performs better for open-shell nuclei (see Fig. 3)—we combined them using Bayesian automatic relevance determination (ARD) regression68. Implemented via ‘sklearnǹ’s ‘ARDRegression’, this approach assigns adaptive weights to each model based on their relevance for regressing the binding energies. Specifically, our ensemble model uses predictions from DZ and MISR alongside N and Z as input features x:
where Φ includes DZ, MISR, N, and Z values, γ represents weights for each feature fitted by iteratively marginal log-likelihood maximization, and λ is a regularization term. The total uncertainty of the ensemble is obtained by adding the ARD-derived uncertainty orthogonally to those of the MISR model. The obtained assembled model, labeled as ARD provides an MAE of 0.389 (0.411) MeV on the train (test) samples, yielding a relative improvement of around 20% with respect to the best-performing HFB24 model61, a comparison of different models is presented in Table 3.
This motivates us to use the ARD model to study open questions in nuclear science, such as the limits of the existence of nuclear matter. The ARD model provides a robust estimation of nucleon separation energies, which is critical for predicting the limits of stability of nuclei. Using our model uncertainties, the probability of having a bound nucleus can be estimated for any number of protons and neutrons. Proceeding with this approach, we compute the one and two-nucleon separation energies and obtain the probability of having a positive central value via the Cumulative Density Probability of a Gaussian distribution56. The results for the limits of stability predicted by the ARD model for nuclei with 12 ≤ Z ≤ 50 are presented in Fig. 8. Where data are available, overall good agreement with the experiment was found.
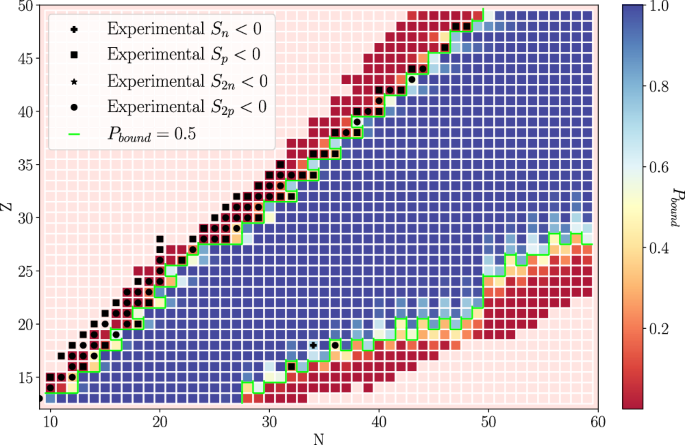
The colors represent the estimated probability of a bound nucleus for a particular combination of N and Z. The green lines represent the threshold of having a bound nucleus, defined as Pbound ≥ 0.5. Experimental limits are shown with black symbols.
Conclusions
We developed a multi-objective iterative symbolic regression framework, labeled as MISR, to enable the discovery of analytical models of nuclear properties. As a proof of principle, the MISR method was employed to describe the binding energies and charge radii of light and medium mass nuclei. Surprisingly, simple expressions were found as functions of the neutron and proton numbers. The models found can provide a relatively good description of the available data, with precision comparable to that of state-of-the-art nuclear models.
The MISR model was combined with the well-known DZ model to enable a powerful, complementary description of binding energies and nucleon separation energies. The combined model, ARD, resulted in an overall agreement with the experiment. The uncertainty estimation provided by the ARD model was used to estimate the limits of stability of nuclei in the region 12 ≤ Z ≤ 50. These results highlight the potential of integrating physics-informed ML approaches with established complementary theoretical models to improve predictions of yet-to-be-explored regions of the nuclear chart.
By combining the predictive power of machine learning with the interpretability of symbolic expressions, MISR offers a promising avenue for advancing our understanding of complex nuclear phenomena and, hopefully, guiding the development of more accurate and insightful nuclear models.
Future work will focus on extending the application of MISR to describe complementary nuclear observables using different sets of input variables. Of particular interest would be the development of the MISR method to discover the analytical forms of nuclear interactions and, more generally, interaction Hamiltonians of quantum many-body systems. This could be combined with powerful many-body methods to establish a direct link between microscopic interactions and observables. Work is ongoing to generalize the MISR approach for this purpose, including vectors and tensor operators.



Responses