Efficient data-driven joint-level calibration of cable-driven surgical robots

Introduction
With help from Robotic Surgical Assistants (RSAs) such as the da Vinci Robotic Surgical Systems, Robot-assisted Minimally Invasive Surgery (RAMIS) improves patient outcomes and has seen accelerating implementation for over 20 years1,2,3,4. Benefiting from cable-driven joints, RSA research platforms such as RAVEN-II5 and the da Vinci Research Kit (dVRK)6 have lightweight and compact arms and tools7,8,9. However, sterilization10 and the complexity of wiring make it difficult and costly to implement encoders directly on the joints of RAVEN-II11. Joint positions obtained from motor encoders at the robot base can have considerable transmission errors and undermine the estimation of the end-effector pose derived by forward kinematics12,13. Although in bilateral leader and follower control14, human operators can still perform accurate operations with visual feedback15,16, however, endoscope-based visual tracking in practice can be challenging because of dynamic and reflective surgical scenes17,18. As a consequence, inaccurate robot pose estimation makes the safe automation of surgical sub-tasks in clinical settings challenging, such as automatic ablation19, cutting20, palpation21, suturing22,23,24, debridement25,26, manipulation of tissue27,28, and peg transfer29,30,31,32. For these tasks, accurate pose estimation is crucial and is generally achieved through painstaking calibration25 or with visual tracking, which may not be feasible in clinical applications. Moreover, for intelligent surgical robot agents for improved surgeon-robot interaction, such as tremor canceling33, motion compensation of the dynamic surgical scenes34,35, and vision-based force estimation36, precise end-effector pose of the surgical robot is also required37. In laparoscopic RAMIS, the requirement of positional accuracy varies with different types of surgeries and instruments, as reported in refs. 38,39, 2 mm is preferred to prevent trauma and ensure safety.
To alleviate the inaccuracy of cable-driven surgical robots, both model-based and data-driven methods show desirable performance. Model-based methods benefit from expert analysis of the robot design and have better explainability in general. However, accurate modeling of cable-driven mechanisms can be challenging with consideration of practical cable effects9,40,41. To model cable effects, Miyasaka et al.42 utilize a Bouc–Wen hysteresis model and a linear damper to model longitudinally loaded cables, in which 9 hysteresis model parameters are optimized by a genetic algorithm. Haghighipanah et al.13 apply an unscented Kalman Filter (UKF) to obtain a more accurate estimation of the positioning joints of RAVEN-II. A significant improvement in accuracy can be found in joints 2 (1.669∘) and joint 3 (0.928 mm), however, joint 1 (1.295∘) sees less reduced error due to relatively higher joint stiffness. Baek et al. present ViO-Com, a vision-based optimized feed-forward compensation method for cable-driven surgical robots that enhances control accuracy by reducing hysteresis using a Bouc–Wen model, optimized with CycleGAN for segmentation of the surgical manipulator and a Siamese Convolutional Neural Network to estimate joint angles, significantly improving precision than single vision feedback compensation43. Lee et al. present a method to model and compensate for non-linear hysteresis for tendon-sheath-driven manipulators, including backlash and dead zone effects, using motor current for parameter identification, improving the accuracy of robotic control without external sensors44.
On the other hand, by utilizing features from robot states, data-driven (preferably learning-based) methods can achieve state-of-the-art accuracy with sufficient training data45,46. With the effectiveness of data-driven methods proved by many, the efficiency of calibration time, training data, and real-time inference remains less investigated. Huwang et al. present a calibration based on a recurrent neural network that reduced the estimation error of the dVRK end-effector position from 2.96 mm to 0.65 mm45. This calibration takes 31 min and further helps automate surgical peg transfer and achieve superhuman performance32. Seita et al. present a two-phase calibration, a DNN model for coarse calibration and then a random forest model for fine training26. Mahler et al. develop a Gaussian process regression calibration for RAVEN-II, in which velocity is found to be an important input for the model46. Cursi et al. propose a method to improve model learning and control of tendon-driven surgical robots by incorporating a backlash compensation technique alongside a feedforward artificial neural network to address nonlinearities caused by tendon backlash47. To ensure the accuracy of supervised data-driven calibration, reliable ground truth is of importance. Visual-based tracking shows considerable feasibility and accuracy. In ref. 12 and ref. 45, ground truth is obtained by tracking colored spheres mounted on the robot end-effector using 4 monocular cameras or 1 RGB-D camera. In ref. 46, ground truth is obtained by tracking LEDs mounted on the end-effector.
In this paper, an efficient data-driven joint calibration of RAVEN-II is proposed. Zig-zag calibration trajectories are used for desirable coverage of the workspace. By studying the effectiveness of the direction and sparsities of the calibration trajectories, the calibration can be finished in 8–21 min and has an accuracy of 0.104∘, 0.120∘, and 0.118 mm in joints 1, 2, and 3, respectively, reducing more than 76% of the error. Although continuous operating and load cause decreased accuracy, with sufficient training data (maximum of 17 min) the accuracy remains within 0.855∘, 0.432∘, and 0.181 mm for the positioning joints in 6-hour heavily loaded operating. To achieve robust calibration performance, the choice of input-output of the calibration models, and the robot homing procedure are also studied.
This work makes the following contributions: 1) an efficient joint calibration pipeline that costs less than 21 min and improves the accuracy significantly; 2) evaluation of calibration performance on 6-hour idleness, unloaded, and loaded operating, in the time scale of real surgeries; 3) besides the DNN calibration with best accuracy, a linear regression calibration established with slightly compromised accuracy but fast enough inference speed to meet the robot’s 1000 Hz servo control; 4) a general software controller for RAVEN-II robot, to the best of the authors’ knowledge, is the only one providing a Python API. To improve the accuracy of cable-driven surgical robots, compared to model-based calibration methods, the proposed data-driven calibration method achieves better accuracy and does not require studying and testing sophisticated cable characteristics that can vary with individual robots. Compared to end-to-end learning-based calibrations on end-effector pose, the proposed method focuses on the more direct source of error – joint positions, and thus allows smaller models, faster training and inference, while maintaining desirable accuracy through long operating time.
Results
Calibration workflow
The objective of the proposed data-driven calibration is to achieve better accuracy of the positioning joints of the RAVEN-II surgical robot in an efficient manner. As shown in Fig. 1, the calibration workflow contains the following sequential procedures:

The time cost mainly depends on the collection of training data. The time cost of data processing and model training may vary with different CPUs. GPU is not necessary for the training of neural network models in this paper, unless stated otherwise. Designed for surgical purposes, the first 3 joint axes of RAVEN-II always intersect at the same location which is called the remote motion center and the surgical instrument will always pass this location as the incision site (top left). In order to possess compact and light arms, the motors and encoders are mounted on the robot base, and joints are driven by cables, which results in considerable errors in joint positions obtained by remote motor encoders (top middle). Without calibration, the average positional error of RAVEN-II’s end-effector is around 20 mm (top right).
Calibration operation
Firstly, it takes less than 2 min to initialize the robot and perform the homing procedure, during which the robot explores joint limits and registers the motor encoders. If calibration is to be performed, temporary encoders for ground truth collection are mounted on the joints and are registered to joint positions at the same time. Then, to collect training data, the robot follows predefined zig-zag trajectories which have even distribution in the workspace of the robot. Meanwhile, the robot states and ground truth joint positions are recorded as ROS bags48. Depending on the sparsity and the size of the training dataset, this procedure takes 4–17 min. Longer trajectories with smaller sparsity have better coverage of the robot workspace, but also require a longer time to record.
Data processing
This step extracts data from the recorded ROS bags from the previous step and saves them into .csv files. Synchronization between robot states and ground truth joint positions is also used to construct training pairs of input robot state and output joint positions. This step takes less than 1 minute with the largest dataset in this paper.
Model training
With the dataset from the previous step, calibration models can be trained/fitted. Deep neural network (DNN), linear regression, and 2nd-order polynomial regression models are studied in this paper. The models take robot states as input and output calibrated joint positions. With optimized input dimension and DNN structure, all models can be trained within 1 minute (without GPU for the DNN model).
Position correction
After training, the calibration models are able to work in parallel with the robot control system in real time. The models take the original robot states as input so that no additional sensor is needed. The output is the corrected joint positions with sub-mm/deg accuracy and the accuracy remains desirable in 6-hour continuous loaded and unloaded operating.
Robot workspace and calibration trajectories
This paper studies the positioning joints (joints 1–3) of the RAVEN-II robot. Figure 2 shows the joints and cable connections of RAVEN-II. Designed for RAMIS, the last 4 joints of RAVEN-II are concentrated near the end-effector with very small (13 mm) or zero link lengths, and thus have much less effect on the location of the end-effector, compared to the first 3 joints.
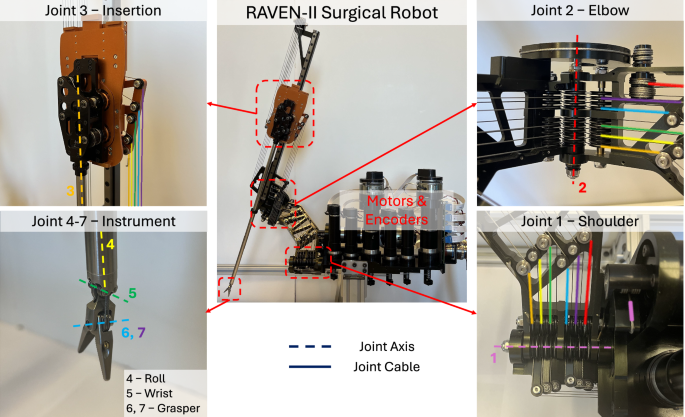
Compared to joints 2–7, joint 1 has a considerably short cable length (alpha wrap). Joint 3 is prismatic and has a large range for insertion, while all the rest of the joints are rotational. Joints 1–3 are positioning joints and have major control of the end-effector’s position. Joints 4–7 are concentrated near the end-effector and have only 1 non-zero link length of 13 mm in the kinematic model. Thus, the last 4 joints mainly control the orientation of the end-effector and have much less influence on the positional accuracy of the end-effector. Joints 6 and 7 control the left and right fingers of the end-effector and can be considered as one joint in kinematics. Thus, RAVEN-II has 6 joints in kinematic models instead of 7. The left arm and the right arm of RAVEN-II are symmetric.
Zig-zag trajectories with different directions and sparsity are chosen as calibration trajectories for data collection, as Fig. 3 shows. With limited calibration time, zig-zag trajectories ensure even coverage of the robot workspace and prevent undiscovered areas. However, because trajectories are continuous, different directions of the trajectories have different coverage in different joints. For example, as the top left sub-plot in Fig. 3 shows, the zig-zag trajectory has a sparsity in the direction of joints 2 and 3, but has no sparsity in the direction of joint 1. The bottom row of Fig. 3 shows different sparsity, smaller sparsity gives better coverage of the workspace but requires a longer time for the calibration.
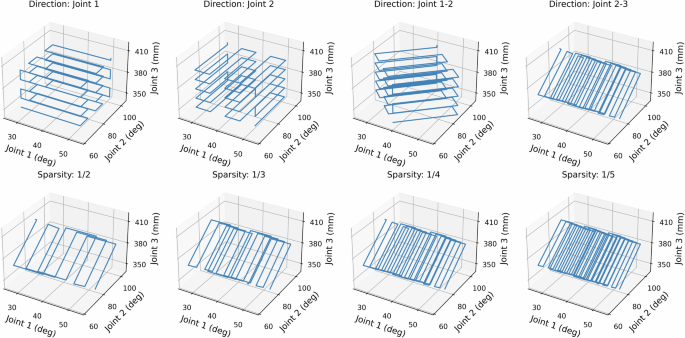
Please note that the trajectories are defined in joint space instead of Cartesian space. Different directions cause different coverage in different joints. Smaller sparsity results in better coverage of the joint space, but also takes a longer time to execute.
The calibration zig-zag trajectories are defined as a set of sequential 3D vectors representing points in the workspace of the positional joints of the robot. All trajectories are obtained by rotating and translating ({{mathbb{T}}}_{1}) – a zig-zag trajectory with the direction of joint 1, and are first defined on a normalized range (−0.5, 0.5) and will be scaled according to each joint’s limit. For example, the trajectory with the direction of joint 2 is obtained by
where T() and R() are operators of translation and rotation, respectively, J3 means the axis of joint 3 in the joint space, the trajectory with the direction of joint 1 – ({{mathbb{T}}}_{1}) is a 4 × N matrix with the direction of joint 1, in which the first 3 rows are positions of joint 1, 2, and 3, respectively. In our implementation, both translation and rotation are applied by homogeneous transformation matrices.
Similarly, trajectories with the direction of joint 1-2 and joint 1-2-3 are generated by the following equations, respectively.
where ⊙ indicates elemental-wise multiplication. After Eqs. (1)–(3), joint limit of all trajectories are within (0, 1), though with different direction.
In this paper, the following directions of zig-zag trajectories are used: 1) single direction: Joint 1, Joint 2, and Joint 3; 2) double direction: Joint 1-2, Joint 2-3, Joint 1-3; 3) triple direction: Joint 1-2-3. Given:
where c and r are the center position and range of a joint, Jmax and Jmin are the maximum and minimum position of a joint. Then trajectories are translated and scaled so that a single direction has a range ((c-frac{1}{2sqrt{3}}r,c+frac{1}{2sqrt{3}}r)), a double direction has a range ((c-frac{sqrt{2}}{2sqrt{3}}r,c+frac{sqrt{2}}{2sqrt{3}}r)), and a triple direction has a range ((c-frac{1}{2}r,c+frac{1}{2}r)). These different ranges result in all trajectories having the same center and covering the same volume in the normalized joint workspace.
Robot states and calibration models
The calibration models based on DNN and regressions are shown in Fig. 4. The details about the hyperparameters of the DNN model can be found in Methods. The input of the models is obtained from the robot state ‘ravenstate’ which is a ROS topic published at 1000 Hz in real time. Based on the ablation study49, the following features are used as input: Current joint positions are the built-in joint positions derived from motor positions, and the accuracy is degraded by the cable-driven mechanism. A typical arm of RAVEN-II has 7 joints. The positioning joints (joints 1–3) mainly determine the position of the end-effector, while the orientational joints (joints 4–7) mainly determine the orientation of the end-effector. Motor torques are derived from motor current control commands. RAVEN-II does not have any direct measurement of joint torques. The control commands are reflected in the desired joint positions, but this robot state is not used as input. This is because RAVEN-II has a 1000 Hz servo control frequency, which results in current and desired joint positions being very close. For example, a joint velocity of 10 deg/s only causes a 0.01 deg difference between the current and desired joint positions. More details about the robot states are in Methods, and the coupling effects between joints in the data-driven calibration are studied in ref. 49.
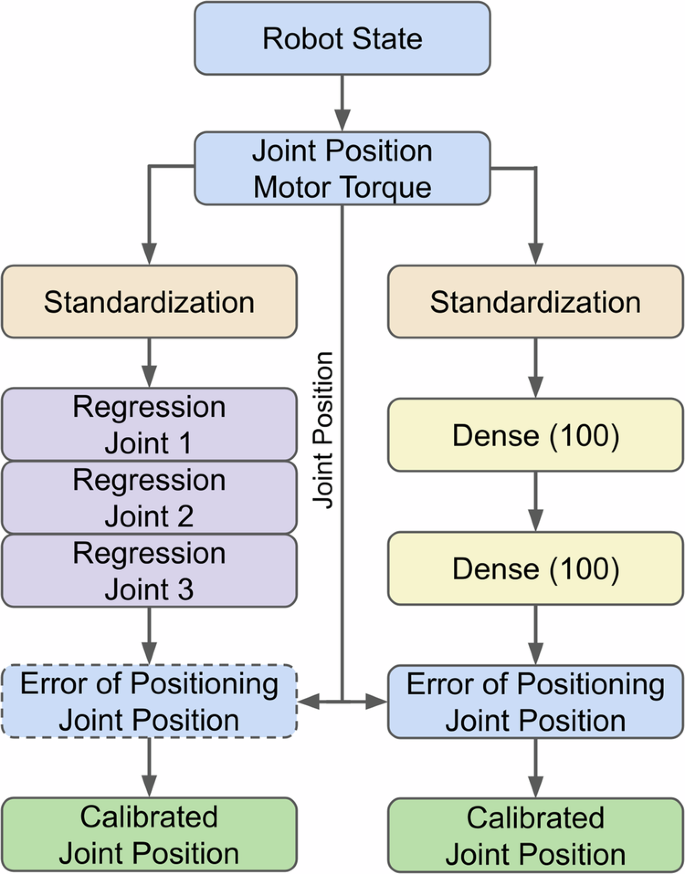
The outputs of the DNN model and regression model are the errors of the joint positions, these errors are added back to RAVEN-II’s original inaccurate joint positions to obtain the calibrated joint positions. The output of the regression models can be either the same or end-to-end output of joint positions (details in Results).
It is possible to include all features in the robot state as input for the calibration models. However, for linear and 2nd-order polynomial regression models, an increase in the input dimension can result in significantly more parameters. With limited training data, there can be a higher risk of overfitting, especially for 2nd-order polynomial regression. Choices of input features are studied in a later subsection.
Instead of end-to-end calibration models that output calibrated joint positions, the output is the error of the original joint positions in the robot state. Then, the calibrated joint positions are obtained by using the output error to correct the original inaccurate joint positions. Training on errors allows better performance for the DNN models, while it is optional for regression models (details in a later subsection).
Besides learning and regression calibration, fixed offset compensation is also applied as a baseline method. This calibration uses the same training data and computes the average bias between the robot’s original joint positions and the ground truth joint positions. Then each joint position is compensated with the average bias when inferred.
Datasets
Data was collected as ROS bags and then processed to form training and test datasets. Details about the experiment setup can be found in Methods. The external joint positions were recorded under 100 Hz, while the robot state ‘ravenstate’ was recorded under 30 Hz due to high dimensions. Synchronization was performed when processing ROS bags. In the experiments, different training trajectories with different directions and sparsity were recorded and the details are included in the following sections, together with experiment results.
All testing trajectories used in this paper are random sinusoidal trajectories in which each cycle has a different velocity and target position (details in Methods). Compared with predefined zig-zag training trajectories, random testing trajectories have the smallest risk of similar patterns with the training trajectories so that the result evaluation can suggest better generalization ability with less risk of overfitting. All testing random trajectories were at least 20 min long in all experiments reported in this paper to be representative to the workspace of the RAVEN-II robot. And the comparisons between different calibration methods and baseline results were from the same random trajectories that could ensure fairness.
Directions of calibration trajectories
As described in Fig. 3, different directions of calibration trajectories cover the joints with different sparsity. Thus, the performance of the calibration was evaluated using trajectories with 7 different directions. For each direction, 3 calibration zig-zag trajectories with sparsity of (frac{1}{2},frac{1}{3},frac{1}{4}) were collected, with an independent 20-minute random movement trajectory as the test trajectory. All calibrations were performed using the combination of the 3 zig-zag trajectories. Evaluation of the DNN model was the average 5 repetitive training and evaluations with different global random seeds, which applied to all evaluations of DNN models in this paper.
The calibration accuracy (RMSE) of different models trained by zig-zag trajectories with different directions is shown in Table 1. For joint 1, fixed offset compensation reduced the raw error from ~2∘ to ~0. 9∘. The best performance of DNN calibration was achieved by the direction J2-J3 of the training trajectory, with an accuracy of 0.104∘. Compared to fixed offset compensation, DNN calibration further reduced 87.9% of the error. The linear regression model also had the best accuracy of 0.174∘(−79.8%) trained with the same trajectory direction. 2nd-order polynomial regression model achieved its second-best accuracy of 0.118∘(−86.3%), while the best accuracy 0.114∘(−87.7%) was trained by direction J1-J3 for this model.
For joint 2, the fixed offset compensation reduced the raw error from ~8.0∘ to ~1.1∘. The best accuracy 0.120∘(−89.1%) was achieved by the DNN model trained with direction J2-J3. When trained with direction J1-J2-J3, the 2-nd polynomial regression and linear regression models saw their best accuracy 0.148∘(−85.8%) and 0.169∘(−83.8%), respectively.
Similarly, for joint 3, the fixed offset compensation reduced the raw error from ~11.7 mm to ~0.5 mm. The best performance of all DNN, 2nd-order polynomial regression, and linear regression was obtained by direction J3, with the accuracy of 0.111(−77.6%) mm, 0.141(−71.7%) mm, and 0.134(−73.1%) mm, respectively. The second-best performance of all models was found with direction J2-J3, with accuracy DNN – 0.118(−76.0%) mm, 2nd-order polynomial regression – 0.173(−64.9%) mm, and linear regression – 0.166(−66.3%) mm.
Overall, the direction of J2-J3 showed the best overall performance in all 3 joints among all 3 calibration models, reducing more than 64.9% of error, and thus was chosen for all the rest of the experiments.
Sparsity and calibration time
As shown in Fig. 3, trajectories with smaller sparsities have better coverage of the robot workspace, but also require more time to collect data in the learning calibration. This experiment studied the calibration performance of the DNN and regression models trained by different trajectories, with sparsities (frac{1}{2},frac{1}{3},frac{1}{4},frac{1}{5}), and (frac{1}{6}). Combinations of different sparsities shorter than 1013 seconds were also evaluated. To rule out the time effect, independent 20-minute random trajectories were collected for each sparsity as test sets. The result is shown in Fig. 5. For sparsities (frac{1}{2},frac{1}{3},frac{1}{4}), 5 independent calibration trajectories were recorded, and for sparsity (frac{1}{5}) and (frac{1}{6}), 3 independent calibration trajectories were recorded to prevent long-time running.
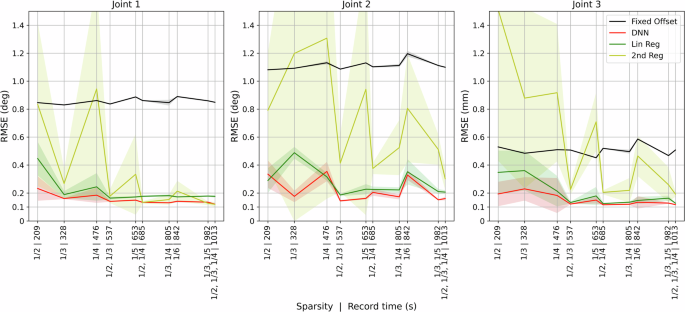
For sparsity 1/2, 1/3, 1/4, 5 independent calibration trajectories were recorded, and for sparsity 1/5, 1/6, 3 independent were recorded to prevent long-time operating. Combinations of trajectories with different sparsities, no longer than 1013 s to record, were also evaluated. Average RMSE is shown in solid lines and the standard deviations are shown in shades.
For joint 1, DNN and linear regression models showed considerable improvement in all sparsities. When sparsity was (frac{1}{2}), it only took 209 seconds to record the calibration trajectory. DNN calibration achieved RMSE of 0.232∘. Compared to the RMSE of fixed offset compensation – 0.846∘, the linear regression model had RMSE of 0.446∘, while 2nd-order polynomial regression showed no significant improvement – 0.834∘. As sparsity got smaller, the performance of all learning and regression methods was improved in both average RMSE and standard deviation. At the longest tested trajectory (1013 seconds to record), the combination of sparsities (frac{1}{2},frac{1}{3}), and (frac{1}{4}), all 3 models showed significant improvement in accuracy, DNN – 0.120∘, 2nd-order polynomial regression – 0.119∘, and linear regression – 0.176∘. Compared to the shortest trajectory with sparsity (frac{1}{2}), the longest combined trajectory had improvement in accuracy of 0.112∘, 0.727∘, and 0.270∘ in DNN, 2nd-order polynomial, and linear regression, respectively. The performance of fixed offset compensation did not see improvement with smaller sparsity. Standard deviation also got reduced with sparsity in general, while a significantly larger standard deviation could be observed in 2nd-order polynomial regression when shorter calibration trajectories were used.
For joint 2, when trained by trajectories shorter than 500 seconds, the DNN model and linear regression model had an average accuracy of 0.288∘ and 0.364∘, respectively. On the other hand, when trained by trajectories longer than 800 seconds, the average calibration RMSE reduced to 0.203∘ (DNN) and 0.248∘ (linear regression). The performance of 2nd-order polynomial regression was very unstable with large standard deviations among most of the sparsities and only achieved comparable accuracy 0.302∘ when trained by the longest trajectory, though still did not outperform the other 2 models.
For joint 3, similarly, when trained by trajectories shorter than 500 seconds, the DNN model and linear regression model had an average accuracy of 0.202 mm and 0.307 mm, respectively. As the calibration trajectory increased to 537 seconds, the combination of sparsities (frac{1}{2}) and (frac{1}{3}), the accuracy was improved to DNN – 0.121 mm and linear regression – 0.132 mm. No considerable further improvement could be found with longer calibration trajectories. Although the 2nd-order regression model had reduced RMSE with longer calibration trajectories, the accuracy was overall unstable and did not outperform the other 2 models.
Long-time idleness, unloaded and loaded operation
The previous experiments showed that data-driven calibrations significantly reduced the error of the joint positions. However, the feasibility of the calibrations also depends on how the calibration accuracy drops with operating time. Due to the relatively small sheave and cable diameter ratio, high tension, large wrap angle, etc., cables of RAVEN-II have a short fatigue life and cable characteristics can change over time50. Generally, the average operating time of laparoscopic RMAIS is less than 4 h51,52,53. To study the influence of operating time on the scale of real surgeries, calibration trajectories in the direction of J2-J3 with different sparsities were recorded first. The robot was then continuously operated by random trajectories for 6 hours to collect the test set. Unloaded and loaded (500 g weight scale hanging on the end-effector) configurations were tested, as well as unloaded idleness for comparison. To the best of the authors’ knowledge, this is the current longest test trajectory set on data-driven calibration of laparoscopic surgical robots. The result is shown in Fig. 6. The same sparsities were used as in Fig. 5 and shown in the box plot. The arrows in the box plot indicate training trajectories longer than 800 s had >20% better calibration accuracy than trajectories shorter than 500 s, which suggests considerably better performance can be obtained by longer calibration trajectories. As shown in Fig. 6, longer calibration trajectories achieved better performance in many entries, especially for regression models. The RMSE described in this section is the average RMSE of models trained by the 3 longest trajectories, unless stated otherwise.
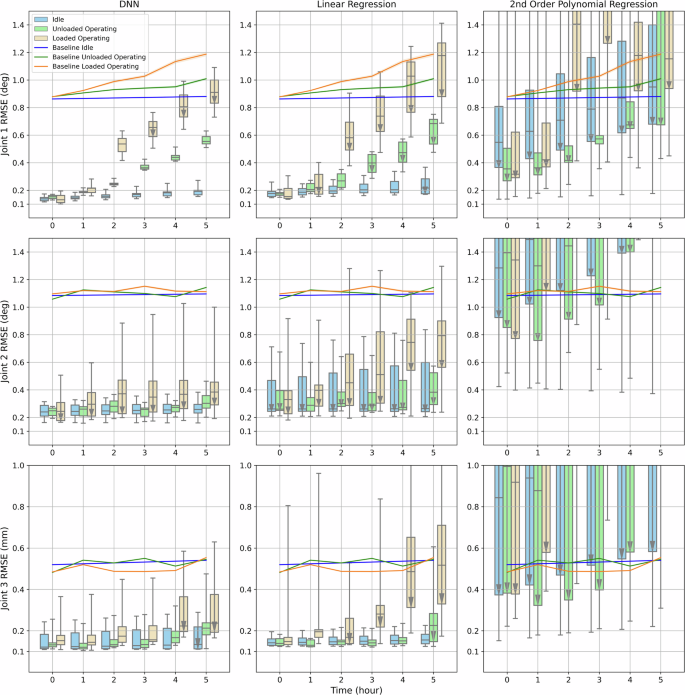
The same sparsities were used as in Fig. 5 and shown in the box plot. The baseline results were obtained by fixed offset compensation. Accuracy of idleness was only evaluated by test trajectories in hours 0 and 5, and hours 1–4 were interpolated. The arrows in the box plot indicate training trajectories longer than 800 s had >20% better calibration accuracy than trajectories shorter than 500 s, and the difference between the 1st and 3rd quartile is larger than 0.2 (deg/mm).
For joint 1, for idleness of 6 hours, the baseline result – fixed offset compensation had no obvious decrease in accuracy from hour 0 – 0.863∘ to hour 5 – 0.879∘. The DNN model saw a small drop of 0.048∘ in accuracy from hour 0 – 0.124∘ to hour 5 – 0.172∘. A similar trend was observed in the linear regression model, from 0.162∘ to 0.193∘. However, the 2nd-order polynomial regression model saw a significant decrease in accuracy, from 0.241∘ to 0.493∘ even when the robot stayed idle for 6 hours. When the robot was operated for 6 hours without load, a considerable drop in accuracy could be found in all 3 calibration models. Compared to fixed offset compensation that dropped 0.121∘ in 6 hours (from 0.879∘ to 1.000∘), the accuracy of the DNN model dropped 0.411∘ (from 0.142∘ to 0.553∘), the linear regression model dropped 0.358∘ (from 0.169∘ to 0.527∘), and the 2nd-order polynomial regression model dropped 1.294∘ (from 0.235∘ to 1.529∘). It is also worth noticing that after hour 3, longer trajectories could result in better performance in the linear regression model, while the DNN model is less affected by the amount of training data. When the robot was operated for 6 h with a 500 g load on the end-effector, a larger decay in accuracy could be found in all models. The fixed offset compensation had accuracy dropped 0.296∘ (from 0.878∘ to 1.174∘), the DNN model dropped 0.741∘ (from 0.114∘ to 0.855∘), the linear regression model dropped 0.772∘ (from 0.144∘ to 0.916∘), and the 2nd-order polynomial regression model dropped 0.824∘ (from 0.221∘ to 1.045∘).
For joint 2, with 6-hour idleness, no decay in accuracy could be found in fixed offset compensation – from 1.084∘ to 1.094∘, DNN model – from 0.211∘ to 0.217∘, and linear regression model – from 0.237∘ to 0.232∘. The performance 2nd-order polynomial regression model was much worse and unstable than the other calibration models in all configurations and thus will not be compared. When operated for 6 h without load, the drops in accuracy were: fixed offset compensation – 0.083∘ (from 1.056∘ to 1.139∘), DNN – 0.099∘ (from 0.232∘ to 0.331∘), linear regression – 0.106∘ (from 0.247∘ to 0.353∘). When operated for 6 h with 500 g load, the drop in accuracy was: fixed offset compensation – 0.017∘ (from 1.092∘ to 1.109∘), DNN – 0.181∘ (from 0.251∘ to 0.432∘), linear regression – 0.322∘ (from 0.266∘ to 0.588∘). It could be found that although the fixed offset compensation did not see a big difference, a larger drop in accuracy was seen by the DNN and linear regression models. Overall, in the configurations of idleness and unloaded operation, the DNN model achieved desirable performance in all calibration trajectories, while longer trajectories were preferred by the linear regression model to achieve comparable accuracy. In the loaded configuration, longer calibration trajectories were preferred by both models.
For joint 3, with 6-hour idleness, no decay in accuracy could be found in fixed offset compensation – from 0.520 mm to 0.541 mm, DNN model – from 0.113 mm to 0.113 mm, and linear regression model – from 0.131 mm to 0.132 mm. The performance 2nd-order polynomial regression model was again excluded for comparison because of undesirable performance. When operated for 6 h without load, the drop in accuracy was: fixed offset compensation – 0.063 mm (from 0.482 mm to 0.545 mm), DNN – 0.039 mm (from 0.126 mm to 0.165 mm), linear regression – 0.068 mm (from 0.132 mm to 0.200 mm). When operated for 6 h with a 500 g load, the drop in accuracy was: fixed offset compensation – 0.069 mm (from 0.485 mm to 0.554 mm), DNN – 0.059 mm (from 0.122 mm to 0.181 mm), linear regression – 0.335 mm (from 0.138 mm to 0.473 mm). Both DNN and linear regression models showed desirable accuracy with all calibration trajectories in the configuration of idleness and unloaded operation. However, for loaded operation, longer calibration trajectories were necessary to obtain better accuracy.
Overall, with sufficient training data, the calibration models improved the accuracy significantly among 6-hour idleness, unloaded, and loaded operating. Examples of calibrated joint position trajectories in the test set can be found in Fig. 7, and the corresponding end-effector trajectories in Cartesian space can be found in Fig. 8.
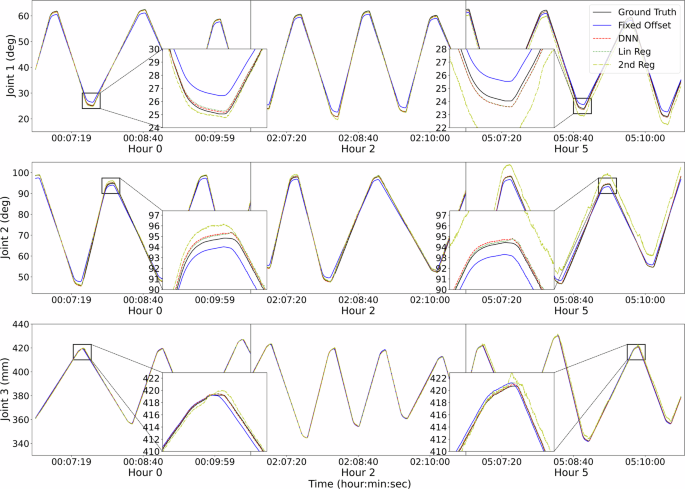
The models were trained by the calibration trajectory with sparsity (frac{1}{6}). 3 sections are shown horizontally. The first section is the immediate performance right after calibration. The second and third sections show performance in hour 2 and 5, respectively.
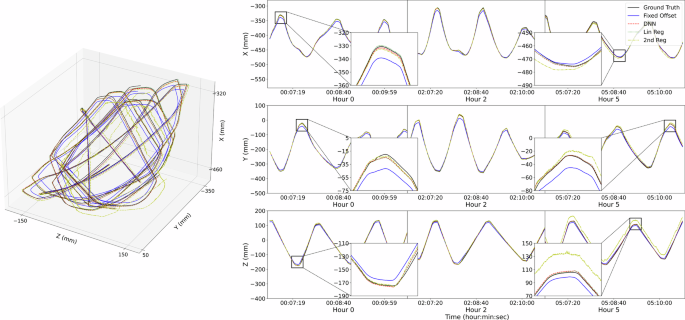
Frame 0 is located at the remote motion center (described in Fig. 1, upper left) of the robot arm. It is worth noting that in the front view, the X-axis is pointing vertically up and the Z-axis is pointing right, determined the joint 1 axis and its positive direction of rotation. Only around 10-minute testing trajectories are shown for clear visualization, the entire testing trajectories were recorded throughout 6-hour continuous operating.
Robustness of unnecessary input features
There are numerous types of information in the robot state (details in Methods), including the robot run level, joint position, velocity, motor torque, end-effector pose, and so on. Among these types of information, based on the ablation study49, only joint positions and motor torques were found important to the calibration. However, the ablation study also took a considerable effort. Without the ablation study, in order to not miss critical input features, all information in the robot state should be given as input to the calibration models, which will increase the parameters of the models. Under the same amount of training data, more parameters may result in a higher risk of overfitting. Thus, this experiment utilized the same 6-hour unloaded operation data in the previous subsection. The DNN, linear regression, and 2nd-order regression models were trained using only selected useful features (joint positions and motor torques, dimension of 16), and using all features in the robot state (dimension of 138). Besides the original DNN model (2 layers, 100 hidden units each), a larger DNN model was also used to accommodate more input dimensions, which has 3 layers with 600, 500, and 400 units, respectively. Regularization rates were also applied, kernel L1 10−5 L2 10−4, bias L2 10−4, and activity L2 10−5. The other hyperparameters stayed unchanged. GPU acceleration was utilized for the training of the larger DNN model.
The evaluation result is shown in Fig. 9. When the model input was only joint positions and motor torques, the DNN model had desirable average accuracy in 6-hour unloaded operating among all calibration trajectories from short to long, with the RMSE of joint 1 – 0.328∘, joint 2 – 0.264∘ and joint 3 – 0.167 mm. When all features in the robot state were used as input, the input dimension was 8.6 times larger from 16 to 138, but the number of model weight parameters was only 2 times larger from 12,103 to 24,303. A considerable drop in accuracy could be observed in all 3 joints. The average RMSE when trained by the 3 longest calibration trajectories was joint 1 – 0.700∘, joint 2 – 0.754∘, and joint 3 – 0.388 mm. When the 3-layer larger model was used with all features as input, the weight parameters increased dramatically to 585503. The average RMSE when trained by 3 longest calibration trajectories improved to joint 1 – 0.397∘, joint 2 – 0.565∘, and joint 3 – 0.229 mm, though the performance was still not as good as the small model with selected features.
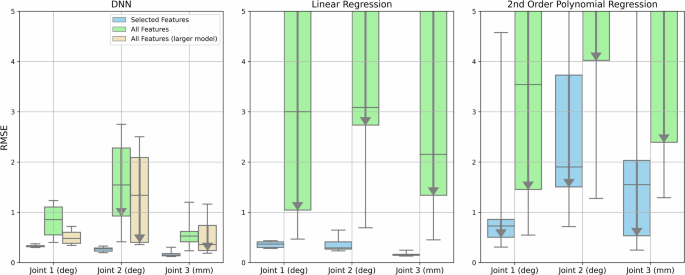
Besides the original DNN model, a larger DNN model was also used to accommodate more input dimensions. The boxed plot shows the average RMSE among 6-hour unloaded operating with different calibration trajectory sparsities, as in Fig. 6. The arrows in the box plot indicate training trajectories longer than 800 s had >20% better calibration accuracy than trajectories shorter than 500 s, and the difference between the 1st and 2nd quartile is larger than 0.2 (deg/mm).
The linear regression model had 17 parameters for each joint when trained by selected features, and had desirable average accuracy in 6-hour unloaded operating among all calibration trajectories, with the RMSE of joint 1 – 0.361∘, joint 2 – 0.355∘ and joint 3 – 0.167 mm. When all 138 features in the robot state were used as input, the number of parameters also increased linearly to 139. A significant drop in accuracy could be observed, and the average RMSE trained by the 3 longest calibration trajectories was joint 1 – 1.985∘, joint 2 – 1.834∘, and joint 3 – 1.352 mm, which did not outperform fixed offset compensation. A similar trend could also be observed by the 2nd-order regression model, but the performance was worse than linear regression.
Effects of homing
The homing procedure is an important function of the RAVEN-II robot, during which the robot explores the hard limits of all the joints and registers the encoders on the motors. Joint positions will be meaningful after the homing procedure. Re-homing may sometimes be necessary during operations, for example, the surgical instrument is changed or software e-stop is triggered because of joint limits or singularity. Thus, it is important to study whether the homing procedure influences the calibration’s performance. Two new datasets were collected to study the effectiveness of homing. In each dataset, 5 homings were performed and a 20-min random trajectory was recorded as test data before the first homing, in between the homings, and after the last homing. The difference between the two datasets was that one dataset had all training calibration trajectories before the first homing, thus this training set ‘saw’ no homing. The other dataset had the same sparsities and length of the training trajectories, but these trajectories were separated before and after the first homing, thus this training set ‘saw’ 1 homing.
The evaluation of calibration performance among homings is shown in Fig. 10. For joint 1, the accuracy of the DNN model slightly fluctuated between 0.117∘ and 0.146∘ among 5 homings with no homing ‘seen’ in training. With 1 homing ‘seen’ in training, the accuracy of the DNN model slightly fluctuated between 0.133∘ and 0.152∘. No obvious drop in accuracy could be observed caused by homing. A similar trend was found using the linear regression model, fluctuating between 0.155∘ and 0.207∘ with no homing in training, and fluctuating between 0.163∘ and 0.218∘ with 1 homing in training.
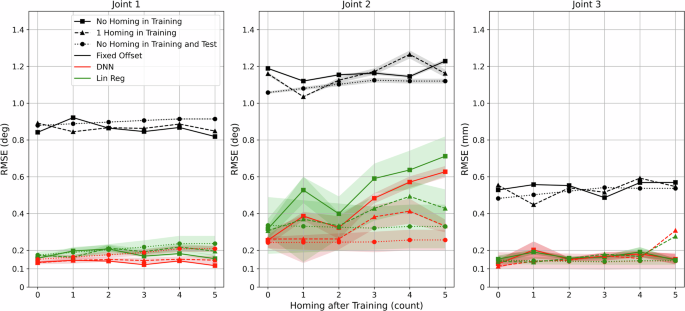
Different combinations (<20 min) of training trajectories with various sparsities were tested and the average is shown with standard deviation as shade. The 2nd order polynomial regression model is not shown because of unstable performance. Two datasets were used for training, one had the training set with no homing, and another one had the training set with 1 homing. To study the effectiveness of homing, baseline results with the same operating time but no homing in both training and test sets are also included.
For joint 2, when the calibration models ‘saw’ no homing in training, the accuracy of the DNN model dropped significantly from 0.255∘ to 0.627∘ after 5 homings, and similarly, the accuracy of the linear regression dropped from 0.317∘ to 0.712∘. On the other hand, if the models ‘saw’ 1 homing in training, although the accuracy still dropped with homing, the RMSE stayed within 0.413∘ for the DNN model and within 0.493∘ among 5 homings.
For joint 3, except for an outlier at the 5th homing, the DNN model and the linear regression model had close accuracy regardless of ‘seeing’ homing in training or not, slightly fluctuating from 0.113 mm to 0.202 mm.
Training on error
As introduced in Fig. 4, the DNN and regression models were not trained as end-to-end models that directly outputted the calibrated joint positions. Instead, the models outputted the errors of the inaccurate original joint positions in the robot state. The errors were then used to correct the original joint positions and thus provided calibrated accurate joint positions. To study the necessity of training on error, this experiment used the same 6-hour unloaded data, and the models were trained on error or end-to-end.
The comparison of calibration accuracy is shown in Table 2. For the regression models, no difference in RMSE could be found between models trained on error or end-to-end, though the average performance of 2nd-order polynomial regression was not desirable. On the other hand, for the DNN model, when trained on error, the best accuracy was achieved, joint 1 – 0.328∘, joint 2 – 0.264∘, and joint 3 – 0.167 mm. However, when trained end-to-end, the calibration error increased sharply to 0.830∘, 0.875∘, and 1.583 mm in joints 1, 2, and 3, respectively. Further tests found that increasing the number of training epochs could improve the performance of the end-to-end DNN model, however, the accuracy was still not as good as the DNN model trained on error. Since training on error requires no extra effort and can be faster with fewer epochs, it is highly preferred for efficient calibration.
Comparison to the state-of-the-art
The comparison of calibration performance with the state-of-the-art in the joint space is shown in Table 3, and the comparison in Cartesian space is shown in Table 4. The requirement of accuracy in RAMIS varies with different types of surgeries and instruments. As examples reported in refs. 38,39, 2 mm positional accuracy is ideal for laparoscopic RAMIS. When unloaded, both the proposed DNN and linear regression calibration had positional accuracy within 2 mm throughout 6 h of continuous operating. When heavily loaded by 500 g, the DNN calibration still had accuracy within 2 mm while the accuracy of linear regression was slightly larger than 2 mm at hour 5. The proposed method in this paper performs calibration in the first 3 joints. Thus, the location accuracy in Cartesian space is obtained by assuming the last 4 joints are accurate and the surgical tool has no deformation. The last 4 joints of RAVEN-II are concentrated near the end-effector with only one non-zero link length of 13 mm. Thus, the inaccuracy of the last 4 joints mainly results in errors in the orientation of the end-effector but less in position. However, a certain error increment still exists in real practice because of deformation.
Compared with the state-of-the-art works, we also focus on efficiency while achieving state-of-the-art accuracy on RAVEN-II. We trained the calibration models within 21 minutes and evaluated the performance of calibration in 6-hour unloaded and loaded operating, and among robot re-homings, in order to prove the feasibility of applying data-driven calibration in the time scale of real surgeries. Besides using computationally expensive DNN models that have slower inference time, by excluding unnecessary input features49 and providing sufficient training data, we also show that the linear regression model can have a significantly faster inference speed that can be applied to the 1000 Hz servo control of RAVEN-II, with slightly compromised accuracy.
Discussion
The DNN model and linear regression model showed comparable performance in the experiments reported in this paper, which raises an interesting question: is the linear regression model competitive to the DNN model? The comparison between these two models in different aspects is shown in Table 5.
In terms of accuracy, with sufficient training data, i.e. long enough calibration trajectory, the DNN model slightly outperformed the linear regression model. According to the 6-hour testing, when trained by the 3 longest calibration trajectories, the performance of the 2 models was very close in unloaded operation. When loaded, the DNN model slightly outperformed the linear regression model by 0.015∘, 0.109∘, and 0.124 mm in joints 1, 2, and 3, respectively. In terms of data hunger, when trained with the 3 shortest calibration trajectories, counter-intuitively, the DNN model has considerably better performance than the linear regression model. When unloaded, the DNN model had 0.052∘, 0.189∘, and −0.037 mm better accuracy in joints 1, 2, and 3, respectively. When loaded, the difference increased to 0.128∘, 0.360∘, and 0.178 mm.
With the small size of the DNN model, even with the largest training set presented in this paper, the DNN model could be trained within 50 seconds without GPU acceleration. The training time of the linear regression model was less than 2 seconds. Although the linear regression model could be trained much more quickly, compared to the entire calibration procedure described in Results, the data collection, which takes 4–17 min, remains the dominating time consumption. In terms of real-time efficiency, the inference time of the DNN model without GPU was 61 ms (<20 Hz) on the Intel(R) Xeon(R) 2.2GHz CPU, which had a huge gap to meet the 1000 Hz servo control rate of the CRTK and RAVEN-II robot. However, since calibrated joint positions may not be necessary in the servo control loop of the robot, the inference time of the DNN model could meet the rate required by the CRTK’s interpolate control level, which is designed for vision-based control, and so on. With GPU acceleration, the inference time could be shortened to 54 ms. The average inference time could also be significantly shortened if inferred in a mini-batch, however, this caused delay and could not be applied to real-time servo control. On the other hand, the inference time of the linear regression model was 0.38 ms (around 3500 Hz), which was sufficient for the 1000 Hz servo control rate of the robot.
As described in Fig. 9, in the calibration of the RAVEN-II robot in this paper, useful features were found by an ablation study49, which required a certain effort. In other cases, if useful features are unknown, in order to not miss useful features, unnecessary features may also be selected as input of the model. Under this condition, a larger DNN model showed much better robustness with a slightly compromised performance, while the linear regression model had a significant drop in accuracy and became undesirable. In terms of the model output, regression models could be either trained end-to-end (directly output calibrated joint positions) or trained on error (output the error of the original inaccurate joint positions and made correction). In comparison, the DNN model had to be trained on error, to achieve better accuracy and faster convergence. However, since no considerable extra effort was needed to perform training on error, both in the calibration phase and the real-time inference phase, there was no difference in efficiency.
To sum up, both models have their advantages and disadvantages. Depending on the use case, one may be more desirable than the other. To achieve the best accuracy, or when data collection must be fast, or unnecessary features may be given as input, the DNN calibration has better accuracy and robustness in performance. However, when calibrated joint positions are required in high frequency by real-time applications, the linear regression calibration becomes the only choice. In this case, longer calibration trajectories are critical to maintain better accuracy.
The first 3 positioning joints of the RAVEN-II robot, though all being cable-driven, have considerable differences in mechanisms (Fig. 2) and calibration performance described in Results.
Joint 1 is a single alpha-wrapped pulley joint, which has the shortest cable length and little or no free cable length. As the first joint, it also bears the largest load caused by the mass of the following robot arm links. As for calibration performance, joint 1 had the largest drop of calibration accuracy with time and load. And it was the only joint that had increased error with time and load in fixed offset compensation.
The joint 2 is a general rotational joint. Although the instantaneous accuracy right after calibration was not as good as that of joint 1, the accuracy of joint 2 dropped less with operating time and load. However, joint 2 saw a considerable increase in error with the robot homing procedure, while the other 2 joints did not.
The joint 3 is the only translational joint of the robot. To insert and extract the surgical instrument, joint 3 has a large range. However, during normal operating, only the lower half of the range is used. Approaching the higher half causes disabled inverse kinematics due to singularity. According to the feature ablation study49, joint 3 was the only joint in which joint torques were more important than joint positions as input features of the calibration model. Although the DNN and linear regression models had very desirable calibration accuracy, the percentage improvement compared to fixed offset compensation was the lowest among all 3 positioning joints.
Although the zig-zag training trajectories have desirable even positional coverage of the robot workspace, the variety of velocity and its direction is not as desirable. Although calibration models trained by zig-zag trajectories had state-of-the-art accuracy and efficiency, in the future, we aim to develop a calibration trajectory with optimized coverage in high-dimensional coupled space that includes both position and velocity, which may further improve the accuracy and efficiency of the calibration.
Methods
General-purpose controller for RAVEN-II surgical robot
To achieve efficient control and data collection on the RAVEN-II robot, a general-purpose software controller is developed, based on ROS, Python, and Collaborative Robotics Toolkit (CRTK)54. CRTK is a common control API for two surgical robot research platforms, the RAVEN-II and the da Vinci Research Kit. The controller has the following parts (shown in Fig. 11).
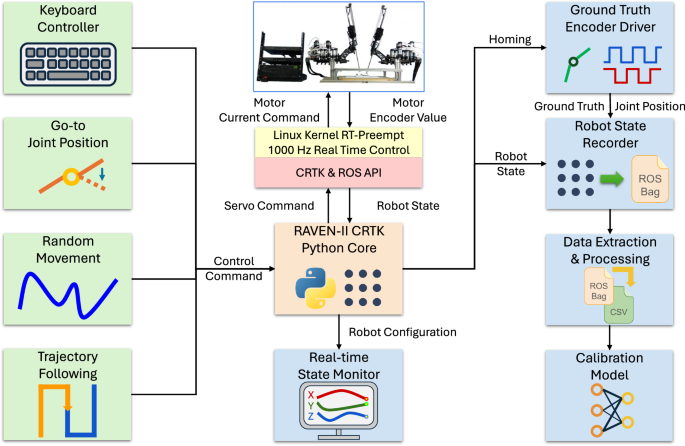
Compared to the original C++ controller that only supports servo incremental control, this new controller has more control, visualizations, data recording, and safety functions.
CRTK Python core establishes communication with the CRTK API and ‘ravenstate’ – a ROS topic containing the states and measurements of the robot, including joint positions, end-effector poses, run-level, etc. It also generates and sends control commands to the robot via CRTK API. The CRTK Python core achieves semi-servo control of RAVEN-II, around 500 Hz. The control command is scaled by a factor computed in each control loop, compared to RAVEN-II’s 1000 Hz servo interface.
Keyboard controller allows the user to control RAVEN-II using local keyboard input, which enables easy testing of the functions of the robot. The robot will follow a predefined constant joint or Cartesian velocity while the corresponding key is holding pressed. The keyboard controller can also change the run level of the robot, replacing the physical pause control pedal.
Go-to joint position controls the robot to reach a target joint configuration, regardless of the current position. While far away from the target configuration, joints have constant velocities. The velocities get reduced while approaching the desired position, and then the joints stop within a predefined tolerance.
Random sinusoidal joint movement controls the robot joints to run random sinusoidal trajectories. All joints are controlled independently. In each iteration, a target joint position is randomly chosen with a random velocity, both in predefined ranges.
Trajectory generation & follow. The purpose of this part is to control the robot to follow a target trajectory with a desired speed to collect training data for calibration. A trajectory is given by a sequence of configuration vectors of joint positions. The controller first moves the robot to the initial configuration using the ‘go-to’ control. Next, in each control loop, the current position of the robot is obtained via ‘ravenstate’ and CRTK API. Then, the target position is found in the trajectory, and the control command is generated based on the difference between the current position and the target position, with a desired smooth velocity.
Runtime monitor provides real-time visualization of the joint positions, end-effector poses, and control commands. It obtains robot states and plots them in an animated manner.
External joint encoder. The controller also includes an external joint encoder driver PCB and software for ground truth data collection on RAVEN-II. In RAVEN-II’s initialization and homing, all joints go to the limit to register motor encoders. The external joint encoders are registered in the same way and readings are then published via ROS message.
Robot state recorder records robot states as ROS bags via CRTK API and ‘ravenstate’ ROS topic, as well as external joint encoder positions. Selected CRTK joint positions and external joint positions are recorded at 100 Hz, and ‘ravenstate’ is recorded at 30 Hz due to high dimensions. Data extraction processes the ROS bags and synchronizes all robot states.
Experiment setup and model paramaters
The proposed methods were implemented and evaluated on a RAVEN-II surgical robot, which is fully cable-driven. Only the left arm of the robot was used. To collect reliable ground truth of joint positions, Avago Technologies AEDA-3300 encoders were installed on the rotational joints 1 and 2, with a resolution of 80,000 PPR. Mercury II 1600 was installed on the translational joint 3, with a resolution of 5 μm, as shown in Fig. 12. The external encoders were registered during the initialization of RAVEN-II, in which the limit of each joint was explored and reached. In this work, temporary joint encoders were used for the best accuracy and reliability of the ground truth. The RAVEN-II robot has threaded holes on the arm links to support easy installation. Plug-in and use hardware and software drivers for encoders are also open-sourced with this paper. For other robot arms that do not support easy installation of joint encoders, for better feasibility, visual tracking might be preferred12,45,46.

RAVEN-II has threaded holes for easy installations of joint encoders. After training, they can be removed before operation.
The hyperparameters of the DNN model were chosen empirically and are inspired by our previous work12,49 and the state-of-the-art work26. Unless stated otherwise, the DNN model for calibration in this paper has 2 fully connected hidden layers with 100 units each. The sigmoid function was used as activation for all hidden units. Mean squared error was used as the loss function. L2 kernel regularization was applied with a factor of 0.0005. The DNN model was trained by 200 epochs with a learning rate of 0.001 and batch size of 1024. Adam55 was used as the optimizer, and the exponential decay rates of the 1st and 2nd order moment estimates were 0.9 and 0.999, respectively.
Robot states of RAVEN-II
There are multiple original and derived measurements, control commands, and system statuses available in the robot state of RAVEN-II, which is published to a ROS topic ‘ravenstate’ at 1000 Hz. According to the ablation study49, joint positions and motor torques are used as the input of the calibration models, unless stated otherwise. The robot states and control system of the RAVEN-II robot is shown in Fig. 13.
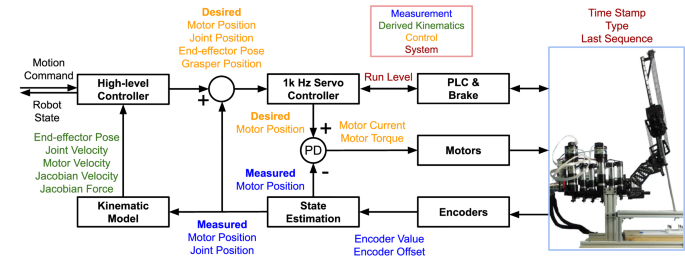
Among the robot states, only encoder values are direct measurements from the encoders mounted on the motors on the robot base. The motor positions and joint positions are derived from encoder values and have a linear relationship. Motion commands can be given in either Cartesian space or joint space, and motor current commands are determined by PD control on measured and desired motor positions. The motor current in the robot state is the command instead of measurement, and the motor torque is derived from the motor current with a linear relationship.
Operating status includes the time stamp; run level – a number indicating major run levels such as operating, pausing, and homing; sublevel – a number indicating subordinate run levels, such as motor torque test; last sequence – sequence number of teleoperation commands; arm type – a number indicating left or right arm; desired grasper position – a number indicating open or close of the grasper.
Encoder values are measurements from encoders on the motors mounted on the robot base. Encoder offsets are registered during the robot homing procedure when joint limits are explored. Measured motor positions are derived from encoder values and offsets. Similarly, measured joint positions are derived from the measured motor positions. Encoder values and offsets, measured motor positions, and measured joint positions have a linear relationship. Due to the cable-driven mechanism, the joint positions of RAVEN-II have considerable errors. Utilizing forward kinematics56, measured end-effector pose is obtained by measured joint positions and has errors as well. By taking derivatives, motor velocities and joint velocities are obtained from previous and current motor positions and joint positions, respectively.
Control command of RAVEN-II can be given in joint space or Cartesian space, incrementally or absolutely. Desired end-effector pose is determined by the control command and the current end-effector pose. Next, desired joint positions are derived from the desired end-effector pose by inverse kinematics, which is further processed to desired motor positions with a linear relationship. RAVEN-II has closed-form inverse kinematics solutions reported in ref. 56. Because the servo control loop of RAVEN-II runs on 1000 Hz, the difference between the current joint positions and the desired joint positions is minuscule. For example, a joint velocity of 10 deg/s results in a difference of 0.01 deg.
Motor current command is the DC current command determined by motor PD control based on the current and desired motor positions. And motor torques have a linear relationship with the motor current command. Thus, both states are control commands instead of measurements.
Jacobian velocity & force: velocity and contact force of the end-effector, derived by joint velocities, motor torques, and the Jacobian matrix57,58. It is worth noticing that these states can be considerably inaccurate since the real robot is not purely kinematic with frictions, masses, and so on.



Responses