Efficient generation of grids and traversal graphs in compositional spaces towards exploration and path planning
Introduction
The term composition refers to a way an entity can be split into a set of distinct components, and it plays a critical role in many disciplines of science, engineering, and mathematics. For instance, in combinatorics, the composition will refer to a way a positive integer is split into a sequence of other positive integers. In materials science, chemical composition refers to how a material (or, more generally, matter) is split into distinct components, such as chemical elements, based on considerations such as fraction of atoms, occupied volume, or contributed mass. In economics, portfolio composition may refer to how finite capital is split across assets, such as cash, equity instruments, real estate, and commodities, based on their monetary value.
The definition of a composition will typically allow for the definition of a finite space in which such a composition exists. In the typical case of the composition defined in terms of a sequence of d fractions, such space will be a standard simplex – a (d − 1)-dimensional polytope of unit length edges defined for points x which satisfy xi > 0 and (mathop{sum }nolimits_{i = 0}^{d}{x}_{i}=1). Or, in simple terms, the space where all fractions are positive, treated equally, and add up to 1. Some special cases of d = 2, 3, 4, corresponding to 1-simplex, 2-simplex, and 3-simplex, are also known as line segment, triangle, and tetrahedron, respectively.
Working within compositional (simplex) spaces requires several additional considerations relative to the more common Euclidean spaces for which most tools were designed. Otherwise, numerous problems can be introduced, ranging from sampling points outside the space, through incorrect density estimates, to incorrect gradient calculations caused by modifying every xj≠i when changing xi assumed to be independent.
This work introduces a new high-performance library called nimplex or NIM library for simPLEX spaces, created exclusively for working with such spaces efficiently and qualitatively correctly. It was written in low-level Nim language, allowing for careful optimizations without sacrificing readability, and then compiled with a native Python interface for general use. nimplex provides an efficient implementation of (a) several existing methods from literature, discussed in the sections “Monte Carlo for simplex uniform random sampling” and “Full simplex grids”), (b) modifications of existing methods discussed in the section “Internal simplex grids”), and (c) entirely new capability of representing compositional spaces through graphs enabled by novel algorithm, progressively developed in the sections “Binary simplex graphs”, “Ternary simplex graphs”, and “N-dimensional simplex grap”. Furthermore, the section “Simplex graph complexes” shows how nimplex can be leveraged to tackle compositional design problems in innovative ways.
The concepts of compositional spaces and the applications of nimplex are not limited to any single discipline. However, to better illustrate their capabilities, we highlight two complex, highly-dimensional materials-related problems with significant impact. At the same time, translating them and their solutions to other areas can be done directly effortlessly and is discussed throughout this work.
An exemplar of how tackling highly-dimensional problems allows researchers to unlock novel solutions is the class of Compositionally Complex Materials (CCMs), which combine several components (e.g., elements, compounds, or monomers) at significant fractions to take advantage of emergent behaviors, often enabled by the high configurational entropy. CCMs include several sub-classes, such as inorganic Multi Principle Element Alloys (MPEAs) or High Entropy Alloys (HEAs)1,2,3,4,5, High Entropy Ceramics (HECs)6, and High Entropy Metallic Glasses (HEMGs)7, or organic High Entropy Polymers (HEPs)8,9,10, and complex biomolecular condensates11. Furthermore, CCMs are conceptually equivalent to a number of systems found in disciplines seemingly unrelated to materials, such as polypharmacy in the context of the study of drug interactions12,13,14, or complex microbial communities, which can be synthesized to study microbial dynamics15,16,17, and methods introduced in this work should be directly applicable to them as well.
Out of all CCMs, HEAs are the most extensively studied class, with thousands of literature publications spanning decades since two pioneering 2004 works by Yeh et al.1 and by Cantor et al.2, who independently proposed that equimolar (equal fractions) metallic alloys with more than 5 (Yeh) or between 6 and 9 (Cantor) elements, could form single solid solutions (SSS) thanks to the configurational entropy stabilizing them. Other notable HEA definitions include all alloys with idealized configurational entropy (Delta {S}_{conf}ge Rln 5=1.61R)4 (≈ 2.32 bits of information in the composition x) or ΔSconf ≥ 1R3 (≈ 1.44 bits).
Regardless of the exact class or definition, while individual CCMs contain a few components, they always occupy very high dimensional problem spaces relative to other materials because they are not as restricted in terms of which elements are present. This results in homogeneous datasets often occupying over 30-dimensional spaces (or 10-20 for specific problems, like refractory HEA3), which are orders of magnitude larger compared to traditional materials with one or two primary elements. This introduces opportunities for finding exceptional candidates in little-explored chemical spaces, as demonstrated by some HEAs with excellent hardness18, ductility19, room temperature strength20, and refractory strength21,22.
In recent years, high-throughput thermodynamics-driven combinatorial studies on CCMs have been successfully performed to generate high-performance materials23,24, utilizing CALPHAD thermodynamic databases for CCMs/HEAs (e.g.,25,26,27). However, they are often limited to (a) coarse sampling (e.g., spaced at 5/10at.% or specific ratios) due to the combinatorial complexity in number of alloys, (b) low-dimensional points (e.g., d = 4) due to the combinatorial complexity in component interactions tracked in CALPHAD calculations and increasing single evaluation cost23,24, or sometimes even (c) limited further to particular points such as equimolar alloys28.
To somewhat alleviate these computational cost challenges, ML models started to be used as surrogates for thermodynamic calculations and experiments29,30 or in the role of candidate selection from ML latent space31. They are extremely fast relative to traditional methods, usually taking microseconds per prediction, and they may seem to work near-instantly when used as a drop-in replacement. However, when one tries to deploy ML models on more complex systems, the combinatorial complexities involved (discussed in the section “Introduction”) may quickly make ML deployment very expensive, prompting optimization of the approach.
While the ML inference is typically optimized to the computational limits in state-of-the-art tools like PyTorch32, the rest of the customized composition space infrastructure, traditionally designed for thousands of evaluations taking seconds, may become a severe bottleneck when moving to billions of evaluations taking microseconds, as explored throughout this paper. In particular, being able to do the following tasks in nanosecond to microsecond region typically becomes critical and needs to be considered:
-
1.
Efficient random sampling from the uniform grids and continuous distributions (Monte Carlo in the section “Monte Carlo for simplex uniform randomsampling”) to facilitate approaches including active learning31 and generative design5.
-
2.
Efficient generation of the uniform grids in simplex spaces to facilitate complete screenings, quantitatively explored in the sections “Full simplex grids” and “Internal simplex grids”.
-
3.
Efficient generation of high-dimensional graph representations with complete connectivity to all adjacent CCM compositions, explored in detail by the sections “Binary simplex graphs”, “Ternary simplex graphs” and “N-dimensional simplex grap”, to deterministically allocate problem space structure and facilitate neighborhood-based exploration. This is particularly beneficial for the gradient calculations between neighboring grid points, where one typically has to either (a) naïvely compute all possible compositional changes despite redundancy (e.g., if at point 1 gradient ({+1 % B}atop{-1 % A}) from point 1 to 2 and gradient ({+1 % C}atop{-1 % A}) from point 1 to 3, then at point 2 the gradient ({+1 % C}atop{-1 % B}) to point 3 can be known) at least doubling the number of required evaluations, or (b) keep track of all visited states through an associative array (dictionary). The latter can, in principle, scale well with the number of visited points (({mathcal{O}}(1)) avg. time for hash map) but is many times more computationally intensive compared to directly accessing known memory location through a pointer, which one can do with a graph data structure.
Another class of materials where complex compositional spaces have to be considered, even if intermediate compositions may not be complex themselves, is the class of Functionally Graded Materials (FGMs), sometimes narrowed to Compositionally Graded Materials (CGMs). In them, a set of compositions is traversed to form a compositional path inside a single physical part in order to spatially leverage combinations of properties that may not be possible or feasible with a homogeneous material33. In the simplest binary example, this could mean increasing the porosity fraction as a function of depth from the part surface to achieve a higher performance-to-weight ratio34.
The computational design of advanced FGMs enable solutions to otherwise impossible challenges, such as the creation of compositional pathways between stainless steel and titanium alloys to allow for additive manufacturing (AM) of aerospace and nuclear components, combining these alloys within a single print35. Such a task is highly non-trivial as the simple linear mixing causes several brittle or otherwise detrimental Fe-Ti and Cr-Ti phases to form, regardless of how gradual the compositional gradient is36. Formation of such phases in significant quantities is not specific to this alloy pair; thus, all possible ternary systems in Cr-Fe-Ni-Ti-V space had to be considered and manually arranged together by experts to obtain a pathway navigating through feasible regions35.
While in recent years, the fabrication of FGMs has become dominated by Directed Energy Deposition AM for various geometries (e.g., radial deposition37), several other notable manufacturing techniques allow the deployment of such pathways. These include deposition-based methods for high-precision applications, casting-based methods for high-volume fabrication33, and recently, brazing consecutive metallic foils38 to create relatively thin compositionally graded interfaces on mass.
In a typical FGM manufacturing scenario, a discrete set of compositions (individual available materials) exists in a compositional (simplex) space formed by a union of all components (usually chemical elements or compounds – not affecting later steps), as depicted in the top of Fig. 1, which one could call the elemental space. The position in this elemental space is fundamental and is usually the one considered in both mechanistic (e.g., thermodynamic CALPHAD-type models39) and predictive (ML/empirical-rule) modeling. However, during the FGM design, it is more convenient to consider another compositional space formed by treating the original available compositions as components, as depicted on the bottom of Fig. 1, which one could call attainable compositions space or more generally the design space.
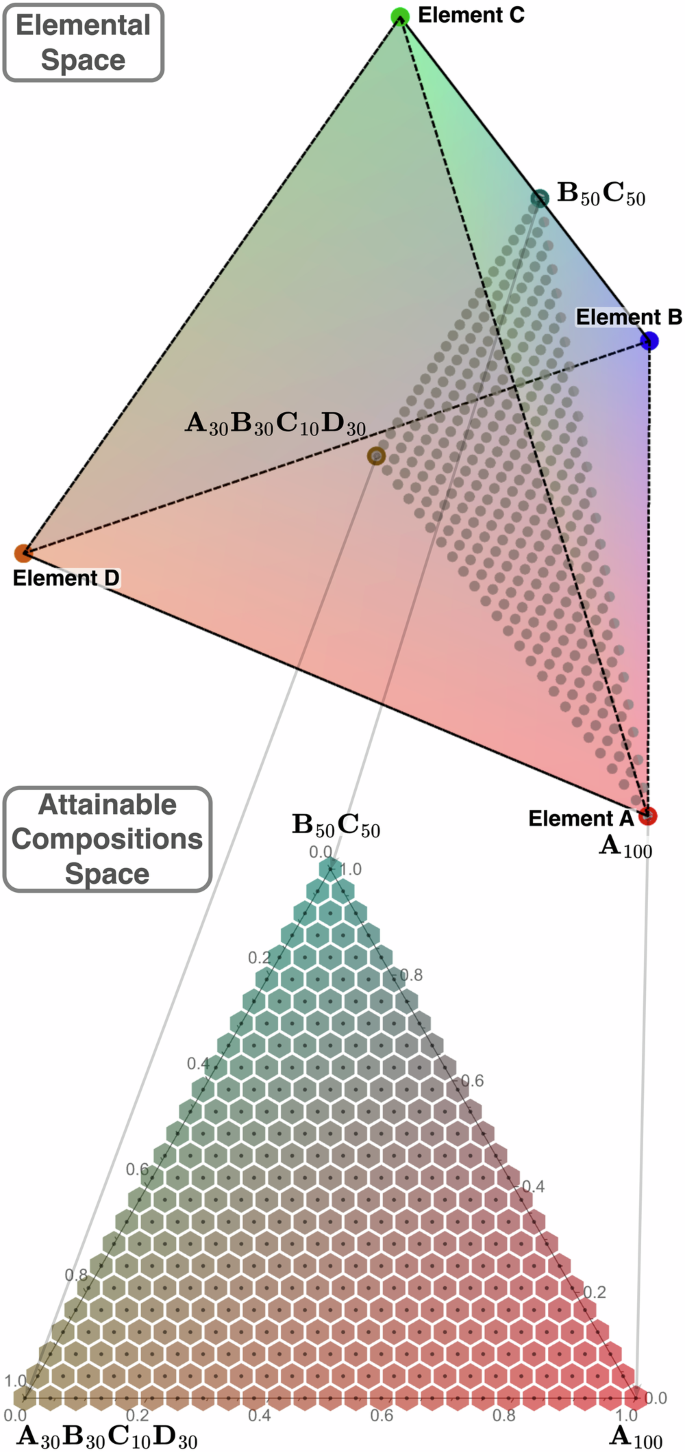
Three available compositions existing in a quaternary (d = 4) compositional space forming a ternary (d = 3) compositional space which can be attained with them; sampled with a uniform grid with 24 divisions. The hexagonal tiling emerges based on the distance metric in 2-simplex and would become rhombic dodecahedral in 3-simplex.
Within an FGM manufacturing apparatus, it is common for each of the available compositions to be treated equally, e.g., powder hoppers40, sputtering targets38, or other flow sources are symmetrically arranged and offer the same degree of control. Thus, as depicted in Fig. 1, the attainable compositional space can be treated as a standard simplex for design purposes and partitioned equally across dimensions, reflecting the nature of the problem even though equidistant points in it may not be equidistant in the original (elemental) space. Notably, a critical consequence of such a setup is the ability to control the relative spacing of the design grid in different dimensions of the elemental space to enable careful control of the element ranges. For instance, one can consider an attainable space constructed from several individual metallic alloys and their equal mixture with 3% of carbon added, enabling fine control of its content in the design.
The attainable spaces used in the final design tend to be lower-dimensional relative to the corresponding elemental spaces, especially when the available compositions are CCMs/HEAs or the number of flow sources is limited. However, this trend is not fundamentally required, and going against it may be beneficial in many contexts. For instance, one may conceptualize a ternary (d = 3) elemental compositional space where 4 compositions are available, arranged as vertices of some tetragon; thus, forming a quaternary (d = 4) attainable compositions space tetrahedron. In such a case, some regions have to overlap in the elemental space, while new regions are guaranteed to be unlocked relative to 3 available compositions if the formed tetragon is strictly convex. This seemingly oversamples; however, it is critical to consider that there is no oversampling in the design space because the available materials can possess properties that are not a function of the composition alone, such as the CO2 footprint or price.
A clear and industry-significant example of the above happens during FGM design in elemental spaces containing Hf and Zr. The two are very difficult to separate, causing both price and greenhouse emissions to rise sharply as a function of the separation purity requirements. Furthermore, physical form factors available from suppliers tend to be limited or at lower demand for pure-Zr and pure-Hf, furthering the cost. In the case of AM using wires as feedstock (WAAM)41, as explored in detail in Supplementary Note 1, using pure Zr in place of the more industry-common alloy with 4.5%Hf can be somewhere from a few times to over 100 times more expensive. In a typical, manual FGM design, a researcher selects one of the two grades based on their expertise. However, by considering the two grades as independent components of the higher-dimensional design space, one can avoid forcing a decision before exploring the space, thus limiting human bias and allowing exploration of both options simultaneously, allowing their combination where regions of space insensitive to the Hf content utilize the cheaper grade while the pure Zr is used when necessary or favorable based on some path heuristic.
With the design space carefully set up, one can start to evaluate different paths across it. Typically, the core considerations deal with meeting specific feasibility (hard) constraints. In the case of metal alloy FGMs, these can be (1) the formation of detrimental phases based on thermodynamic equilibrium40, (2) the formation of detrimental phases based on non-equilibrium predictions of solidification results based on Scheil-Gulliver method, which better describes the as-made material42, or (3) a combination of the two35. In the future, these will likely be extended through (4) precipitation modeling improving the metastable material design, thanks to the recent release of open-source high-performance software Kawin43, and (5) automated modeling of manufacturing constraints, such as printability in AM44. Furthermore, one can also try to meet desirability (soft) constraints, such as the physical appearance of a composite material, which can be broken if needed. These two types of constraints are depicted in Fig. 2, alongside an example path navigating through them.
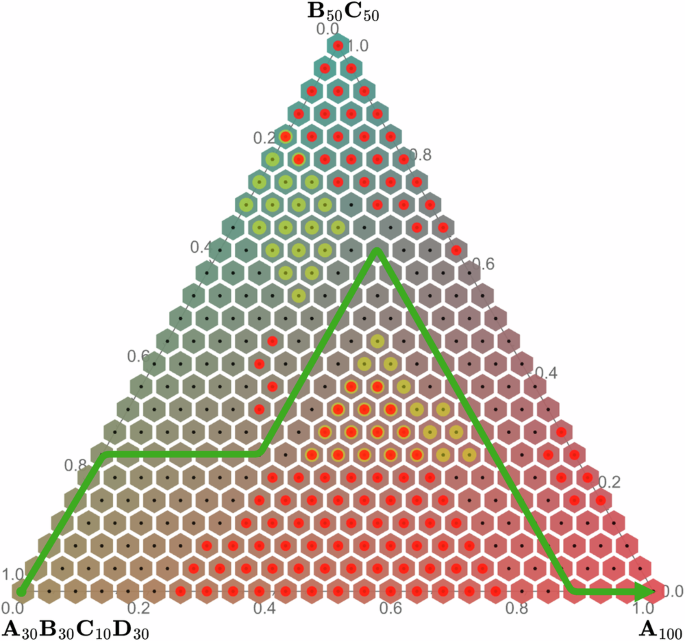
A path example which avoids infeasible (red) and undesirable (yellow) regions, or their combination (orange).
In Fig. 2, all infeasible points violating the constraints are annotated for visualization. However, doing so may be unnecessary when path-planning, especially iteratively based on neighbor connectivity, as the insides of the infeasible space could not be reached, thus reducing the total number of evaluations.
In addition to the feasibility and desirability constraints, further considerations are often made to how the path optimizes values of a set of properties of interest, either individually or through some heuristics combining them. Usually, this optimization constitutes finding the path that minimizes or maximizes either average or extreme values over the set of visited states, exemplified by the pink path in Fig. 3. In the case of metal alloy FGMs, this can mean, for instance, minimizing the average evaporation rate of the molten metal45, minimizing the maximum susceptibility to different cracking mechanisms46, or maximizing the ductility47.
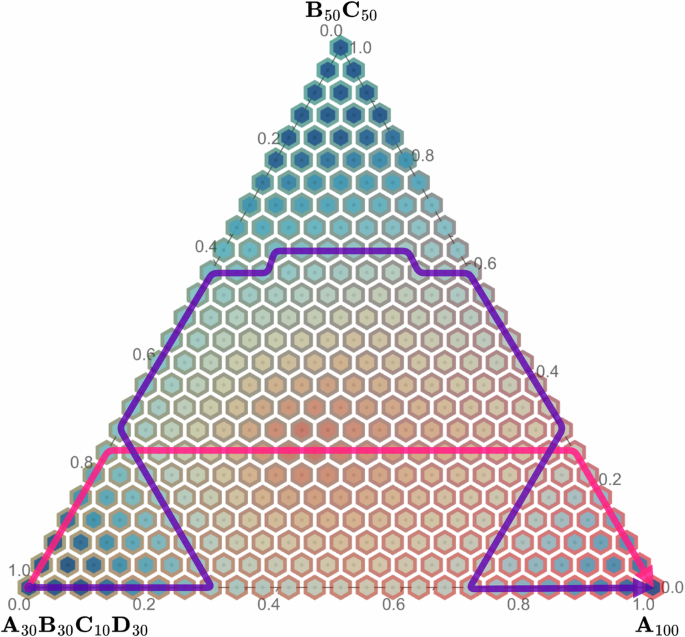
Two path examples in the attainable compositional space overlaid with hypothetical property values, for illustration purposes. One (pink/inner) minimizes/maximizes the average property value given a number of fixed path lengths, and another (purple/outer) minimizes the gradient in the property along the path.
The last, fundamentally different, property optimization task has to do with the gradient, or more generally, the character, of transitions between intermediate states, which will be critical later in the context of graphs. Most commonly, one optimizes the path to minimize value function gradients, exemplified by the purple path in Fig. 3, in order to, for instance, minimize the thermal expansion coefficient mismatch and by extension stresses induced by temperature changes48.
As eluded to in the section “Introduction”, when sampling compositions or partitioning corresponding spaces, the resulting combinatorial complexities have to be considered to determine whether a method will be computationally feasible. There are two key equations governing these complexities based on (1) the dimensionality of the space (number of components) d and (2) the number of equal divisions made in each dimension nd, which can be found for every feasible fractional step size (such that it can add to 100%).
The first, very intuitive equation gives the number of samples NC on a Cartesian grid in d − 1 dimensions, with − 1 term due to one of the components being considered dependent.
The second equation gives the number of ways nd balls can be arranged in d bins, which is well known to be equivalent to much simpler problems of choosing d − 1 moves or nd placements from d − 1 + nd possible options (see ref. 49 or ref. 50). While these may seem unrelated to compositions, the former problem is precisely equivalent to finding a composition of an integer or distributing nd compositional fractions (frac{1}{{n}_{d}}) across components or chemical elements, giving the number NS of unique discrete compositions in the simplex space.
In terms of factorials, both expressions can be simplified to the same
Between the sections “Full simplex grids” and “Simplex graph complexes”, the interplay between these equations will be utilized to contrast different computational methods, and their direct results will allow computational feasibility evaluation.
Results
Monte Carlo for simplex uniform random sampling
Performing a uniform random sampling, also known as the Monte Carlo method, over a simplex space is a prevalent task; however, it is also one of the most common sources of inefficiency, bias, or errors when implemented incorrectly.
Software (e.g., alchemyst/ternplot in Matlab51) and methods dealing with low-dimensional or otherwise small compositional spaces, often utilize a naïve approach of sampling uniformly distributed points from a Cartesian space/grid in d − 1 dimensions and then rejecting some infeasible points ((mathop{sum }nolimits_{i}^{d}{x}_{i} ,> ,1)), as depicted in the left part of Fig. 4, which for small (d ≤ 4) can be both easiest and computationally fastest.
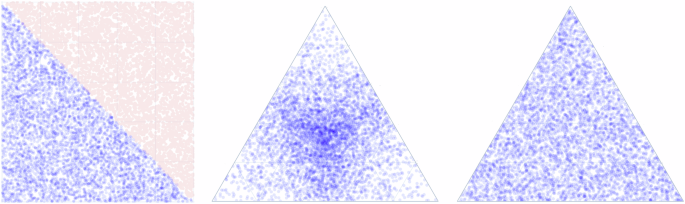
(left) Uniform random sampling in 2-cube (square) filtered to fall onto a 2-simplex (ternary composition), showing 50% rejection rate, (middle) random sampling in 3-cube projected onto 2-simplex by normalizing coordinates, showing oversampling in the center of each dimension, and (right) ideal uniform random sampling of a simplex.
However, this method becomes inefficient for large d because the fraction of rejected points increases with the dimensionality. While this problem is widely noted in the literature52, to the best of the authors’ knowledge, it has yet to be discussed quantitatively despite being critical to estimating the sampling’s computational complexity. Thus, it is derived herein.
One can consider that a grid of NS simplex-feasible points is a subset of a grid of NC points distributed uniformly in the Cartesian space so that random selection from this grid should have a (frac{{N}_{S}}{{N}_{C}}) probability of falling within the simplex. Thus, as shown below, one can find the acceptance rate by considering an infinitely fine grid (({n}_{d}to inf)). Supplementary Note 2 gives an alternative, intuitive method for finding f(4) using geometry, which agrees with this result.
As one can see in Equation (3), the rejection rate exhibits factorial growth, and while it is not a significant obstacle for low-dimensional cases like ternary (f(3)=frac{1}{2}) or a quaternary (f(4)=frac{1}{6}), it will relatively quickly become a problem when compositionally complex materials are considered. For instance, in the case of nonary chemical space (f(9)=frac{1}{40320}) or only ≈ 0.0025% of points will fall into the feasible space. Such a rejection rate could have a particularly severe effect on ML-driven methods, such as generative CCM design.
To circumvent the rejection problem, one may randomly sample from N-cube and normalize to 1; however, as shown in the center of Fig. 4 and commonly known in the literature53, this leads to oversampling in the center of each underlying dimension.
Thus, to achieve a uniform random sampling, nimplex and other carefully designed methods (e.g.,52 and53) tend to take Dirichlet distribution, where one samples points y from Gamma distributions with density (frac{{y}_{i}^{alpha -1}{e}^{-{y}_{i}}}{Gamma (alpha)}) and consider its special “flat” case, where α = 1 simplifies the density equation to just (frac{1{e}^{-{y}_{i}}}{1}={e}^{-{y}_{i}}). This is equivalent to sampling z from linear distributions and calculating ({y}_{i}=-log ({z}_{i})), which then can be normalized to obtain x as xi = yi/∑y. The following snippet shows nimplex’s implementation of this, which samples z with the high-performance xoroshiro128+ random number generator54 underlying randomTensor function from the Arraymancer tensor library55.
proc simplex_sampling_mc(
dim: int, samples: int): Tensor[float] =
let neglograndom =
randomTensor[float]([samples, dim], 1.0
).map(x => -ln(x))
let sums = neglograndom.sum(axis=1)
return neglograndom /. sums
An alternative approach worth mentioning, sometimes found in this context, is based on (1) generating a (d + 1)-length list composed of 0, d − 1 random numbers, and 1, (2) sorting it, and (3) obtaining d-length list of differences between consecutive elements, which is guaranteed to be uniformly distributed over a simplex as shown in56. While this approach may be easier to conceptualize, it is much more computationally expensive due to the sorting step. On the author’s laptop, for d = 9, the method implemented in nimplex (involving calculation of 9 logarithms and normalizing them) takes 3.6ns while the above (implemented with merge sort) takes 74.5ns per iteration, i.e., over 20 times longer while not providing any clear benefit. Furthermore, their complexities are ({mathcal{O}}(N)) and ({mathcal{O}}(Nln N)), respectively, so the computational cost difference will also slowly widen with increasing d.
Quasi Monte Carlo for simplex uniform random sampling
While beyond the current implementation scope of nimplex, it is beneficial to consider quasi-Monte Carlo (QMC) sampling methods, where quasi-random sequences of low discrepancy (having highly uniform coverage of all regions) are used to sample the space deterministically. Such an approach is guaranteed to be very beneficial in low-dimensional (d ≤ 3) problems and has been implemented in thermodynamic tools, including pycalphad53,57 improving sampling of ternary systems. However, the QMC can become problematic as one moves to higher dimensional problems.
Firstly, the upper discrepancy bounds for QMC quickly increase with increasing N, unlike MC, which depends only on the number of samples; thus, MC can outperform it (thanks to better guarantees) unless a quickly (often exponentially) growing number of samples is taken (see discussion on p.271 in58). Because of this, even for quaternary (d = 4) spaces, MC may be preferred for a low number of samples, even though QMC, especially with additional scrambling, can outperform it, as shown in53.
Another significant problem in QMC is the unequal sampling of different dimensions, which can be very severe in high dimensions (see p.154 in59). In addition to causing under-performance in space-filling, such bias, combined with the standard alphabetical ordering of chemical components, can cause systematically worse exploration of, e.g., titanium compared to aluminum in CCMs, just based on their names.
Full simplex grids
Next, one can consider the creation of a grid of uniformly distributed points, which is known to contain (left(begin{array}{c}d-1+{n}_{d}\ d-1end{array}right)) points, as discussed in the section “Introduction”. Similar to the random sampling discussed in the section “Monte Carlo for simplex uniform random sampling”, such a compositional grid cannot be constructed by simply projecting a Cartesian grid in (N − 1)-cube as patterns will emerge (explored in detail by Otis et al.53), but it can be quickly constructed through rejecting infeasible points, as shown in Fig. 5. However, it will suffer from a nearly as bad rejection rate, quantitatively dependent on both d and nd. For instance, if we consider 5% spaced compositions in 9-components, the fraction of points summing to 100% is ({f_{M = 20}}(9)approx frac{1}{12,169}) or 0.0082%.
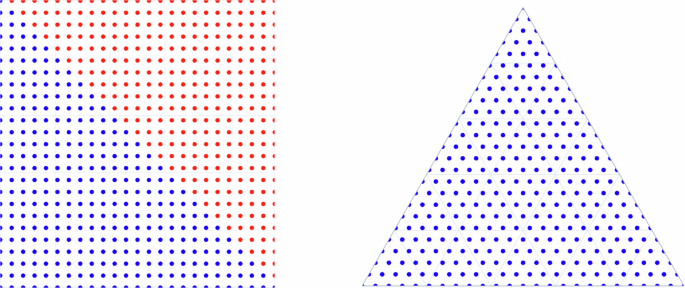
(left) Uniform grid (nd = 24) in 2-cube (square) filtered to fall onto a 2-simplex (ternary composition), showing (frac{12}{25}=48 %) rejection rate, (right) uniform grid in the corresponding simplex.
Fortunately, in their 1978 textbook, Nijenhuis et al.49 explored the problem and gave an efficient algorithm/routine called NEXCOM to procedurally generate these simplex lattice points for arbitrary d and nd, resulting in the grid shown in Fig. 5 on the right.
In the following years, several authors made various modifications to the algorithm, and the most recent one by Chasalow et al.50 improves performance without sacrificing simplicity. Over the years, it has been implemented in relatively modern languages such as FORTRAN90, C, MATLAB, and Python. Now, it has been implemented in Nim language as well, with the Nim code snippet shown below.
proc simplex_grid(
dim: int, ndiv: int): Tensor[int] =
let N: int = binom(ndiv+dim-1, dim-1)
result = newTensor[int]([N, dim])
var x = zeros[int](dim)
x[dim-1] = ndiv
for j in 0..dim-1:
result[0, j] = x[j]
var h = dim
for i in 1..N-1:
h -= 1
let val = x[h]
x[h] = 0
x[dim-1] = val – 1
x[h-1] += 1
for j in 0..dim-1:
result[i, j] = x[j]
if val != 1:
h = dim
return result
As one can deduce from above, the algorithm proceeds through the simplex space starting from [0, 0, …, nd] and redistributes one (frac{1}{{n}_{d}}) fraction NS − 1 times across dimensions, forming a zig-zag path to [nd, 0, …, 0].
Internal simplex grids
To the best of the authors’ knowledge, a minor modification that has not been explicitly implemented before, but that is significant to exploration of CCMs (see Sec 1) is an algorithm to obtain only internal points of the simplex grid, i.e., points with non-zero values in all dimensions, to allow, e.g., generating all 7-component HEAs rather than all alloys in 7-component space. In principle, one can filter the output of the algorithm presented in the section “Full simplex grids”; however, this may quickly become inefficient, especially for nd low enough as to approach d.
The number of points can be found by, again, considering the surrogate problem of ball compositions mentioned in the section “Introduction” and noting that if the last ball cannot be removed from any position, there will be d fewer possible options to perform d − 1 moves, thus resulting in NI samples:
This can be quickly double-checked through summation of internal points of all lower δ dimensional spaces enclosed in d space:
We can now look at NI(d, nd) to NS(d, nd) ratio for the aforementioned case of generating all 7-component alloys. For 5% grid (nd = 20) we get (approx frac{1}{8.5}), and for 10% grid (nd = 10) we get (approx frac{1}{95}), showing a clear benefit of implementing the new method. This is often done by using the full grid algorithm but with d subtracted from nd, followed by the addition of 1 to all grid elements, but it can also be accomplished by a dedicated algorithm to avoid any performance overhead. In this work, the latter is done by taking the modified-NEXCOM algorithm50 from the section “Full simplex grids” and:
-
1.
Adjusting procedure length from NS to NI.
-
2.
Initializing first states in x to 1.
-
3.
Adjusting the starting point from [1, 1, …, ndiv] to [1, 1, …, ndiv − dim + 1].
-
4.
Jumping to the next dimension one step earlier (val ≠ 2).
To implement the following nimplex snippet.
proc simplex_internal_grid(
dim: int, ndiv: int): Tensor[int] =
let N: int = binom(ndiv-1, dim-
result = newTensor[int]([N, dim])
var x = ones[int](dim)
x[dim-1] = ndiv+1-dim
for j in 0..dim-1:
result[0, j] = x[j]
var h = dim
for i in 1..N-1:
h -= 1
let val = x[h]
x[h] = 1
x[dim-1] = val – 1
x[h-1] += 1
for j in 0..dim-1:
result[i, j] = x[j]
if val != 2:
h = dim
return result
Binary simplex graphs
The simplex grid algorithm presented in the section “Full simplex grids” is used commonly; however, it has an important feature that has not been utilized yet and was only briefly noted by its authors50. Namely, the fact that generated points are sorted in a lexicographic order (forward or reverse, depending on convention) which opens the door for using pure combinatorics for finding certain interesting relations between points at near-zero costs compared to other popular methods.
In the simplest possible case, which will be expanded upon later, one can look at a binary (d = 2 / 1-simplex) compositional grid and write a straightforward function that will find all neighboring points (transitions to them) to create a graph representation of the binary system like one presented in Fig. 6, without any notion of distance calculations.

1-simplex graph corresponding to a binary system (nd = 12) with 13 nodes/compositions and 24 edges/transitions.
Such a function, shown below, can be implemented by setting up a neighbors list of lists (NS of ≤2 length) of integer positions and then, at the end of every i-th iteration, populating it with forward (i + 1) and backward (i − 1) transitions unless start ([0, 1]) or end ([1, 0]) points x respectively, corresponding to lack of some component, have been reached.
proc neighborsLink2C(i:int, x:Tensor,
neighbors: var seq[seq[int]]): void =
if x[0] != 0:
neighbors[i].add(i+1)
if x[1] != 0:
neighbors[i].add(i-1)
While the above is trivial, it clearly demonstrates that the graph can be constructed within the original ({mathcal{O}}(N)) computational complexity of the simplex grid algorithm, unlike a similarly trivial distance matrix calculation, which would be ({mathcal{O}}({N}^{2})); thus, unlocking efficient generation of even massive graphs of this kind.
Ternary simplex graphs
With the core of the approach set up in the section “Binary simplex graphs ”, one can move to the more complex ternary (d = 3 / 2-simplex) case, which can be conceptualized as a series of 13 binary systems (already solved individually in Sec. 2.5) of lengths from 13 to 1 and with simple modification of positional coordinates shifted forward by 1 to accommodate for the new dimension.
The newly allowed neighbor transitions across these binaries can be quickly noticed to be dependent on which of these binaries is considered; however, they can be intuitively found by considering that each transition in the 3rd dimension (increasing x0) limits the size of the binary simplex by 1 from the original size of (left(begin{array}{c}d-1+{n}_{d}\ d-1end{array}right)=left(begin{array}{c}2-1+{n}_{d}\ 2-1end{array}right)={n}_{d}+1). Thus, one can define two convenient jump lengths:
Then, one can quickly visualize that (1) unless x2 = 0, a transition by jump J1 should be possible, (2) unless x1 = 0, a transition by jump J1 combined with backward jump J0 in the target binary should be possible, and (3) unless x0 = 0 (the first traversed binary is considered), transitions by both backward jump J1 and backward jump J1 + J0 (extra step within the earlier binary) should be possible. Thus, one arrives at the following algorithm, which requires additional nd (“ndiv”) input on top of the one from the section “Binary simplex graphs” but retains its structure.
proc neighborsLink3C(…,
ndiv: int): void =
let jump0 = 1
let jump1 = 1+ndiv-x[0]
if x[0] != 0:
neighbors[i].add(i-jump1)
neighbors[i].add(i-jump1-jump0)
if x[1] != 0:
neighbors[i].add(i-jump0)
neighbors[i].add(i+jump1-jump0)
if x[2] != 0:
neighbors[i].add(i+jump0)
neighbors[i].add(i+jump1)
Utilizing the above, the result presented in Fig. 7 can be quickly obtained for any number of divisions. The numbering of points can help to visualize how the transitions were obtained.
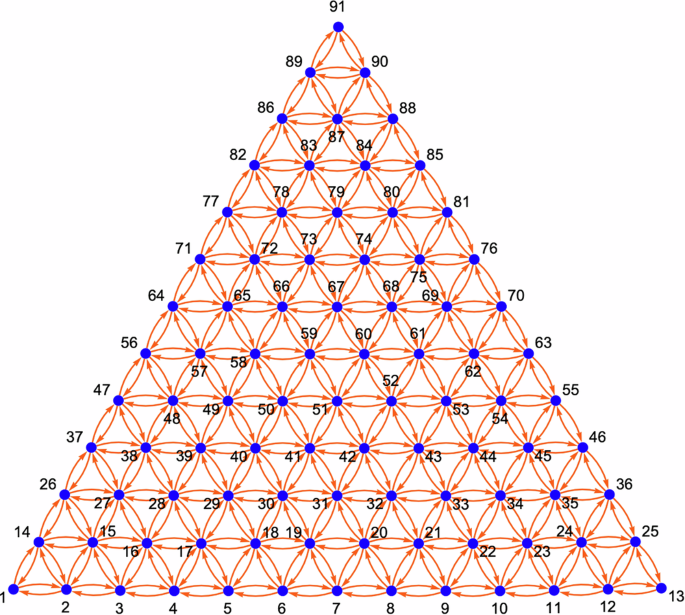
2-simplex graph corresponding to a ternary system (nd = 12) with 91 nodes/compositions and 468 edges/transitions.
N-dimensional simplex graphs
Moving beyond ternary systems, one has to increase the number of tracked transitions to higher dimensions, which can be counted for every jump length Jj with (mathop{sum }nolimits_{0}^{(d-j-2)}{x}_{i}), and then utilized to obtain a general equation for all d − 1 elements of jump length array J as a function of current point x.
As expected, for the special cases of d = 3, the above agrees with J0 and J1 found for the ternary case in the section “Ternary simplex graphs ”. One can also note that J0 always equals to 1 as (left(begin{array}{c}a\ 0end{array}right)=1) for any a.
With J defined, one can take a quaternary system (d=4 / 3-simplex) and perform a similar visualization thought exercise in the head as in the section “Ternary simplex graphs”, but in 3D, considering the new transitions to 3 neighbors above and 3 neighbors below, in order to set up neighborsLink4C procedure which is presented in Supplementary Note 3.
Such an approach of visualizing and counting the possible jumps in the head becomes (a) challenging for quinary systems (d=5 / 4-simplex) case where one has to visualize 4 forward and 4 backward jumps to and from points inscribed in every tetrahedron formed by the 3-simplex tetrahedral grids, and (b) near impossible for higher orders, both because of the visualization dimensionality and the growing number of neighbors to track, given by (mathop{sum }nolimits_{delta }^{d}2(delta -1)=d(d+1)) or for d = 6, 7, 8, and 9 corresponding to 30, 42, 56, and 72 neighbors respectively; thus prompting for an alternative.
Fortunately, while performing the above thought exercises for increasing d, with transition lengths T expressed as compositions of jump lengths described by J, a careful observer can quickly note that for any dimensionality of the simplex grid, the main challenge in finding the higher-dimensional T lies in distributing the d − 1 new forward (x0 increment) transitions across all previous xi = 0 constraints, while the d − 1 new backward (x0 decrease) transitions are always possible for x0 > 0 and follow a relatively simple trend of transition lengths Jd, (mathop{sum }nolimits_{j = d-1}^{d}{J}_{j},ldots ,mathop{sum }nolimits_{j = 0}^{d}{J}_{j}). This allows relatively simple construction of all backward transitions by stacking them together across all d − 2 considered dimensions.
Finally, a simple notion that every backward transition b → a of grid point b is associated with a forward transition a → b of point a allows for the complete construction of the simplex graph representation of the compositional space.
This is implemented very concisely in the nimplex snippet below, where for every considered dimension δ from d (highest at 0th index of x) down to 2 ((d − 2)th index), the δ of backward and δ of forward transitions of lengths tk are found by iteratively summing jump lengths Jδ, (mathop{sum }nolimits_{j = delta -1}^{delta }{J}_{j},ldots ,mathop{sum }nolimits_{j = 0}^{delta }{J}_{j}), and then used to assign neighborhood.
proc neighborsLink(…): void =
var jumps = newSeq[int](dim-1)
jumps[0] = 1 #binom(a,0)=1
for j in 1..<(dim-1):
jumps[j] = binom(
j+ndiv-sum(x[0..(dim-2-j)]), j)
var trans: int
for order in 0..(dim-2):
trans = 0
if x[order] != 0:
for dir in 0..(dim-2-order):
temp += jumps[dim-2-order-dir]
neighbors[i].add(i – trans)
neighbors[i – trans].add(i)
The result of running the above algorithm with d = 4 and relatively low nd is shown in Fig. 8 to help visualize neighbor-neighbor transitions despite the overlap when printed in 2D.
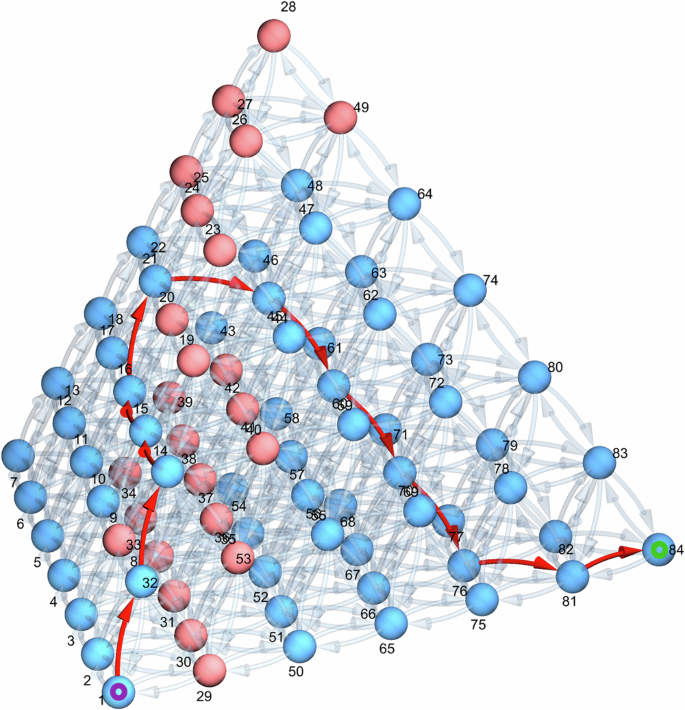
A quaternary (d=4 / 3-simplex) simplex graph (nd = 6) with 84 nodes (compositions) and 672 edges (possible moves). A set of nodes has been manually selected (highlighted in pink) to depict a toy example of infeasible points (similarly to Fig. 2), which forces a non-trivial path (highlighted in red) to traverse from the bottom-left corner at 1 to the bottom-right corner at 84.
It is critical to note that the above algorithm is still within the ({mathcal{O}}(N)) computational complexity for N grid points, just like the forward/backward jumps discussed in the section “Binary simplex graphs”. Thus, for instance, the task of constructing 1% resolution graph for a 6-component chemical space containing NS(d = 6, nd = 100) or nearly 100 million unique vertices requiring 2.76 billion edges (possible chemistry changes) takes as little as 23s tested on author’s laptop computer. This stands in stark contrast with ({mathcal{O}}({N}^{2})) distance-based graph construction, which, even when well implemented to take around 3ns per comparison, would take approximately 1 year on the same machine.
Furthermore, the method scales excellently with the increasing problem dimensionality. For a 12-component chemical space with nd = 12 divisions per dimension, even though up to 132 neighbors have to be considered for all NS = 1.35 million vertices, the 93 million edges are constructed in 950 milliseconds.
Simplex graph complexes
Once able to rapidly set up simplex graphs in arbitrary dimensions, one can also efficiently combine them to construct more complex graphs representing non-trivial problem statements where many different paths are possible to explore, and prior knowledge can be incorporated as assumptions in the problem solution space if needed. At the same time, it allows the dimensionality of the intermediate compositional spaces to be kept within manufacturing feasibility, i.e., the number of material flow sources. Suppose one tries to connect elemental compositions A and F, but assumes prior knowledge that they cannot be combined directly in any quantity, and also knows that (1) A is compatible with B and C, (2) F is compatible with D and E, but (3) B and E are incompatible in any quantity, (4) C and D are incompatible in any quantity. Furthermore, (5) G and H are individually compatible with B and D, and (6) I and J are individually compatible with C and E. These rules can be used to set up a problem graph like in the top of Fig. 9, encoding everything that is known about the system a priori and limiting the solution space from full (left(begin{array}{c}10-1+12\ 12end{array}right)approx 300,000) to (2times left(begin{array}{c}3-1+12\ 12end{array}right)+10times left(begin{array}{c}2-1+12\ 12end{array}right)=312), or three orders of magnitude.
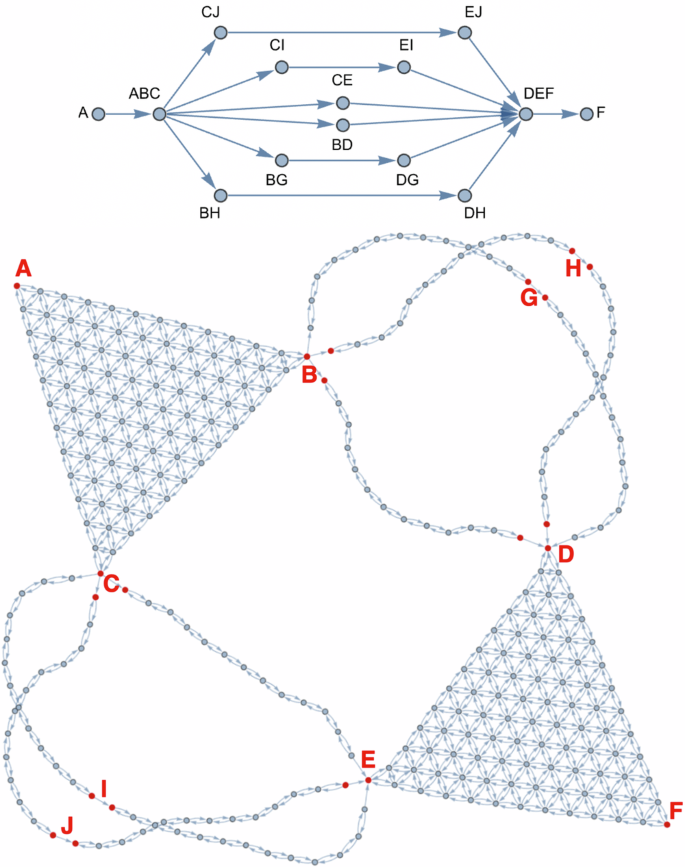
Graph Complex Example #1 depicting a problem space where 2 ternary systems can be connected through 6 different binary paths.
The space constructed in Fig. 9 is kept very minimal in terms of going beyond known assumptions and dimensionality to illustrate the concept in a plane. However, real examples of this technique can be highly non-trivial and essential in bringing the number of considered points into a computationally feasible regime when tens of available compositions can be considered.
Furthermore, unlike in Fig. 9 where spaces are simply connected through single-components, the interfaces between the individual compositional spaces can be along any subspace (e.g., the ternary face of quaternary tetrahedron), allowing one to quickly set up search problems where one or more components are unknown, but their relations to others are fixed.
One can quickly demonstrate the benefits of such ability by looking at the SS316 to Ti-6Al-4V problem studied by Bobbio et al.35. After idealizing and anonymizing the components, it becomes a problem where one tries to combine compositions A with G, which cannot be combined directly in almost any quantity, and also knows that (1) system ABC is highly feasible across it, but (2) C cannot be combined directly with G in any quantity, and (3) a complete path from pure B to G is not possible. In this case, a simple problem setup is to look at several BC? and BG? pairs, forming parallel pathways from ABC to G. This is depicted in Fig. 10 for 3 candidates D, E, F, forming 6 ternary spaces to consider, but nothing limits the method to be extended to an arbitrary number of candidates while still retaining its linear complexity.
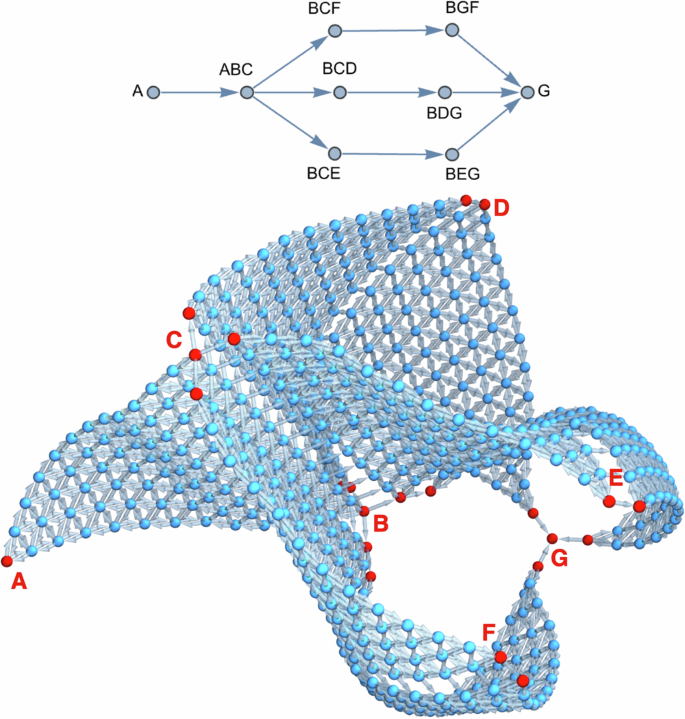
Graph Complex Example #2 depicting a problem where 3 choices (D/E/F) can be made to traverse from ABC to G through dual ternary systems containing B. Vertices were spread in 3D to depict three possible ABC to G paths, which would exactly overlap in a plane.
In the first two examples in Figs. 9 and 10, all connections between compositional spaces were directional; however, that is not necessary, and in some problems it may be beneficial to allow bidirectional movement. Suppose one tries to combine compositions A with D, which cannot be combined directly in any quantity, and also knows that (1) system ABC is highly feasible across it, but (2) system BCD is not traversable on its own. Thus, E can be introduced to set up intermediate spaces BDE and CDE, allowing obstacles in BCD to be avoided. Furthermore, BCE can also be set up as an alternative, possibly shortening the total path. Figure 11 depicts such a problem setup.
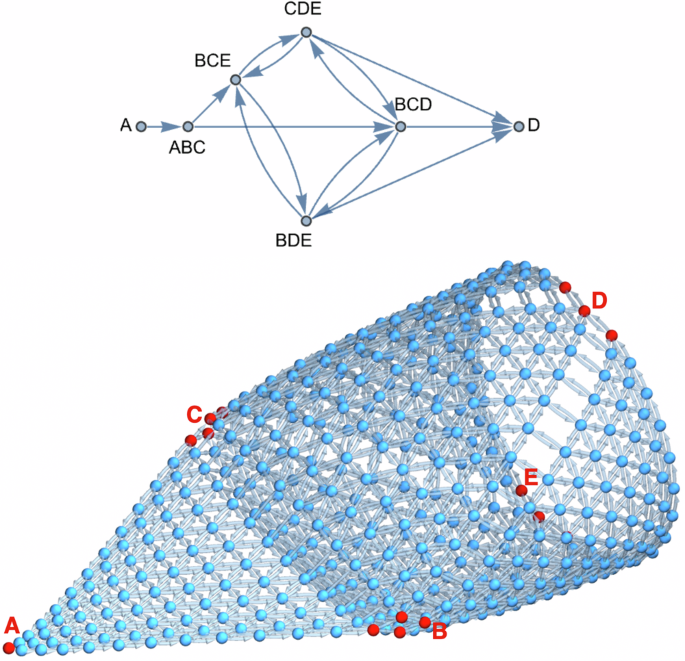
Graph Complex Example #3 depicts the possibility of competing paths, including cycles.
Notably, while the above example in Fig. 11 depicts a single 5th component E to help visualize cycling between spaces, these concepts can be extended to many possible intermediate components. At the same time, the maximum dimensionality of individual compositional spaces is kept constant (d = 3). Thus, it provides a powerful method to keep the problem solvable, even experimentally, while considering many possible pathways formally defined prior to path planning to fit within the feasibility of evaluation and manufacturing.
Exploration of simplex graphs
Critically, creating such a homogeneous problem structure through graph representation allows one to deploy the same exploration strategies across many dimensionalities and even combinations of individual spaces shown in the section “Simplex graph complexes”. Furthermore, in the described graphs, points are on an equidistant grid; thus, it is easy to set up a heuristic function that can be both consistent and admissible.
This, in turn, enables one to harvest many general-purpose graph traversal algorithms, which are actively researched and available through high-performance libraries. For instance, to navigate against constraints, the A* algorithm60 can be used with such a heuristic and is mathematically guaranteed to find the shortest feasible compositional path while exploring the least number of nodes61, what can be critical if the shortest path is necessary while each evaluation is relatively expensive. Then, if one tries to find a feasible solution first and then improve on it, modifications of the A* algorithms such as the RWA*62 can be used to first make it more greedy and then gradually move towards A* to obtain the optimal solution if sufficient resources are available. Alternatively, for highly complex problems where exploration needs to proceed quickly towards the goal but the optimality guarantees are not needed, one can use a search algorithm based on the Monte Carlo tree search (MCTS), which has been famously used in conjunction with an ML model to master the game of Go63.
Discussion
This work starts by providing an abstract description of compositional spaces applicable to a wide range of disciplines while formalizing several vital concepts. Then, it discusses complex compositional spaces, using Compositionally Complex Materials (CCMs) as a real-world application and considers the challenges of exploring such spaces using different methods. Another real-world application of Functionally Graded Materials (FGMs) then expands on that by discussing compositional spaces derived from compositions in other spaces and when these spaces are preferred for design. It also discusses key concepts related to path planning in relation to types of constraint and property optimizations. Lastly, the paper’s Introduction presents key equations for investigating the combinatorial complexities in these problems, providing a foundation for the methods discussed throughout the work.
Next, discussions and implementations are given for several methods for efficiently solving compositional problems through random sampling in the section “Monte Carlo for simplex uniform random sampling”, grid-based methods in the section “Full simplex grids”, graph-based methods, including graphs combining multiple compositional spaces, in the section “Simplex graph complexes”. The three most critical contributions introduced in this process are:
-
1.
Novel algorithm for rapid procedural generation of N-dimensional graph representations of compositional spaces where uniformly distributed simplex grid points in d dimensions are completely connected to up to d(d − 1) neighbors representing all possible component-pair changes. For instance, in economics, this could represent all possible compositions of a financial portfolio of 12 assets and, for each one of them, all 132 transfer choices that can be made to modify it. Critically, this method scales linearly with the number of points and generates graphs with billions of connections between millions of points in just seconds. Furthermore, this algorithm allows deterministic memory allocation during the graph construction, where arrays of pointers to neighboring compositions represent allowed transitions, resulting in a very high-performance data structure.
-
2.
The new free, open-source software (FOSS) package nimplex (nimplex.phaseslab.org), which gives high-performance implementations of both essential existing methods and all new methods introduced within this work including the simplex graphs.
-
3.
The novel concept of combining many compositional spaces using graph representations to create homogeneous problem spaces, both simplifying the path planning and allowing for efficient incorporation of constraints and assumptions about problem spaces as demonstrated in the section “Simplex graph complexes”.
In addition to the above, three other new contributions are given in this work:
-
1.
The sections “Monte Carlo for simplex uniform random sampling”, “Quasi Monte Carlo for simplex uniform random sampling”, “ Full simplex grids”, and “Internal simplex grids” discuss random sampling and grid construction in simplex spaces in the context of the composition of chemical spaces. In the process, several theoretical results critical to the problem, which have not been discussed previously in this context, are presented. For instance, the commonly found random sampling of a d − 1 hypercube and rejection of compositions > 100% to sample a d-component space, commonly found in software, has a rejection rate exhibiting factorial growth and can severely impact when deploying ML models.
-
2.
In the section “Full simplex grids”, a new algorithm was developed to efficiently create internal (subspace-exclusive) grids in simplex spaces based on an algorithm from the literature (modified-NEXCOM50) without introducing any overhead. It is beneficial in cases of, for instance, sampling only d-component materials in d-component chemical space without considering lower-order points.
-
3.
In a few areas, the section “Introduction” leverages its general character to go beyond the usual FGM literature introduction. For instance, it contrasts elemental spaces with attainable design spaces and discusses the use of similar compositions (alloy grades) in the design process to reduce cost and greenhouse emissions without making prior assumptions.


Responses