Enhancing diagnostic capability with multi-agents conversational large language models

Introduction
Recent advancements in large language models (LLMs) have notably enhanced their capabilities in the medical field, leading to increased exploration of their potential applications1. These models are equipped with vast medical databases and advanced analytical algorithms, offer promising solutions to these challenges2. These models have shown proficiency in simple medical tasks such as answering medical knowledge queries and diagnose common diseases, and warrant further research to test their effectiveness in handling more practical and complex medical tasks3,4. Among them, providing accurate diagnosis has always been an important and practical medical need.
Diagnosis of rare diseases is among the most complex and challenging diagnostic tasks. The prevalence of rare diseases ranges from 5 to 76 cases per 100,000 individuals5. The low prevalence of these diseases often results in a scarcity of specialized knowledge, making accurate diagnosis difficult, thereby delaying proper treatment6. Additionally, the complexity and variability of symptoms can lead to frequent misdiagnoses or delayed diagnos7,8.
Although LLMs such as GPT-4 demonstrate substantial proficiency in medical knowledge and some potential application, their performance in complex real-world clinical scenarios such as disease diagnosis remains questioned. A previous study has demonstrated the limitations of LLMs in the diagnosis of complex cases2. Therefore, an increasing number of studies are focusing on how to better leverage LLMs’ own training data and inherent capabilities to improve their performance in practical medical tasks9,10.
Multi-agent systems are one such attempt. In the context of a large language model, an agent refers to a system capable of receiving input and performing actions to achieve specific goals. For example, when interacting with ChatGPT, the user is engaging with a single-agent model. The multi-agent framework is an innovative approach where multiple digital agents work together and execute tasks through interactions among themselves. This technique significantly enhances the capabilities of LLMs for managing complex tasks, including solving mathematical problems and performing retrieval-augmented code generation11,12,13,14. The adoption of multi-agent framework may facilitate dynamic and interactive diagnostic processes through multi-agent conversation (MAC), where agents would discuss the same question and finally reach consensus on the output. In this case, different agents can simulate the collaborative nature of a medical team, simulating a Multi-Disciplinary Team (MDT) discussion that is commonly adopted in clinical practice to solve complex medical tasks. By facilitating an in-depth analysis that single-agent models may not achieve, they have the potential to improve the performance of LLMs in the diagnosis of rare diseases. Therefore, MAC may serve as a valuable tool that could help doctors analyze patient information and provide useful second opinions.
This study aims to develop a multi agent conversation (MAC) framework that can be used in clinical practice to perform diagnostic tasks. This study also compares the knowledge base and diagnostic capabilities of GPT-3.5, GPT-4, and the MAC.
Results
The study flow is shown in Fig. 1. The Multi-Agent Conversation Framework was developed (Fig. 2) and was tested on curated clinical cases simulating real-world clinical consultations (Fig. 3).

The researchers first identified the rare disease database. Then, they performed normalized weighted random sampling, from which 302 cases were selected. Each case was curated into primary consultation setting and follow-up consultation setting. GPT-3.5, GPT-4, and MAC were tested.
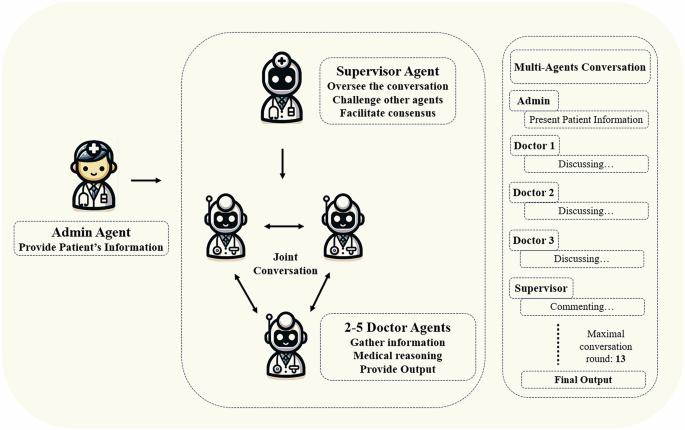
The admin agent provides the patient’s information. The supervisor agent initiates and supervises the joint conversation. The three doctor agents jointly discuss the patient’s condition. The final output is provided either when consensus is reached or after a maximum of thirteen rounds of conversation.

a Primary consultation represents the initial information acquired from patient in primary care; b Follow-up consultation represents the complete information of patients after relevant diagnostic tests have been performed.
Study sample
This study included 302 kinds of rare disease from 33 different disease categories. One to nine kinds of rare disease were randomly selected for each category. Details of the sampled diseases and their corresponding clinical case reports are provided in Supplementary Table 1.
Performance on disease specific knowledge
GPT-3.5, GPT-4, and MAC achieved an average score above 4 across all testing aspects, including inappropriate/incorrect content, omission, likelihood of possible harm, extent of possible harm, and bias. The results of disease-specific knowledge performance are shown in Fig. 4.
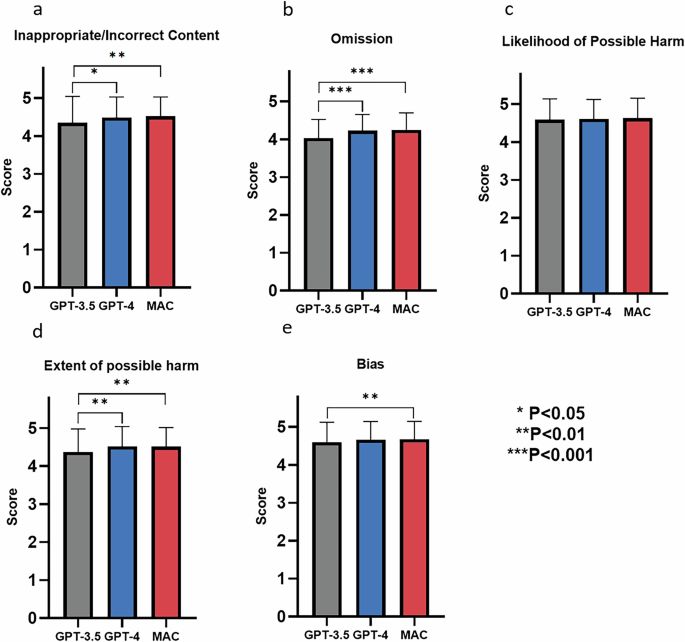
a Inappropriate and incorrect content; b Omission; c Likelihood of possible harm; d Extent of possible harm; e Bias. The bars represent mean values. Error bars indicate standard deviation.
Performance of MAC on diagnostic ability
MAC significantly outperformed single-agent models GPT-3.5 and GPT-4 in terms of diagnostic accuracy and helpfulness of further recommended test in both primary and follow-up consultation. Further analysis was performed to investigate factors potentially influencing MAC’s performance, including changing base model, varying the number of doctor agents, excluding the supervisor agent and assigning case-specific specialties to doctor agents. Detailed results of GPT-3.5, GPT-4, and different subgroups within the MAC framework are listed in Table 1, Supplementary Tables 2 and 3 for primary consultation, and Table 2, Supplementary Tables 4 and 5 for follow-up consultation. The comparisons between MAC and single-agent models are shown in Fig. 5 for primary consultation and in Fig. 6 for follow-up consultation.
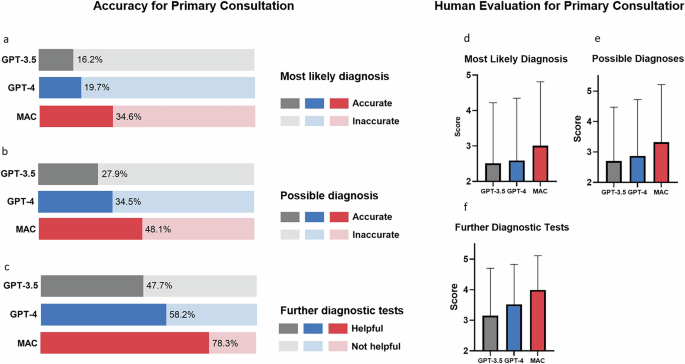
a Accuracy of the most likely diagnosis; b Accuracy of the possible diagnoses; c Helpfulness of further diagnostic tests; d Score for the most likely diagnosis; e Score of the possible diagnoses score; f Score of further diagnostic tests. In (a–c), the bars represent percentages. In (d–f), the bars represent mean values and the error bars indicate standard deviation. Statistical values are listed in Supplementary Tables 2 and 3.
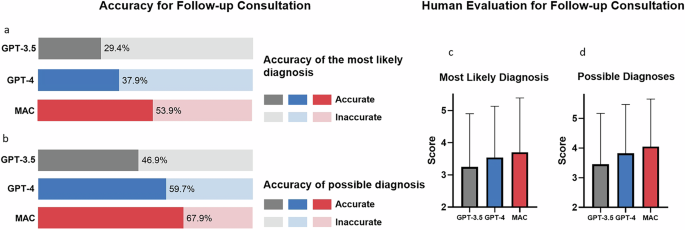
a Accuracy of the most likely diagnosis; b Accuracy of the possible diagnoses; c Score for the most likely diagnosis; d Score of the possible diagnoses score. In (a, b), the bars represent percentages. In (c, d), the bars represent mean values and the error bars indicate standard deviation. Statistical values are listed in Supplementary Tables 4 and 5.
MAC utilizing either GPT-3.5 or GPT-4 as the base model significantly outperformed their respective standalone versions. However, GPT-4 proved superior to GPT-3.5 when used as the base model for MAC. In primary consultations with four doctor agents, GPT-4 achieved higher accuracy for the most likely diagnosis (34.11% vs 24.28%), possible diagnoses (48.12% vs 36.64%), and helpfulness of further diagnostic tests (78.26% vs 77.37%). Similar trends were observed in follow-up consultations, with GPT-4 showing approximately 10% improvement over GPT-3.5. The results are shown in Tables 1, 2, and Fig. 7.
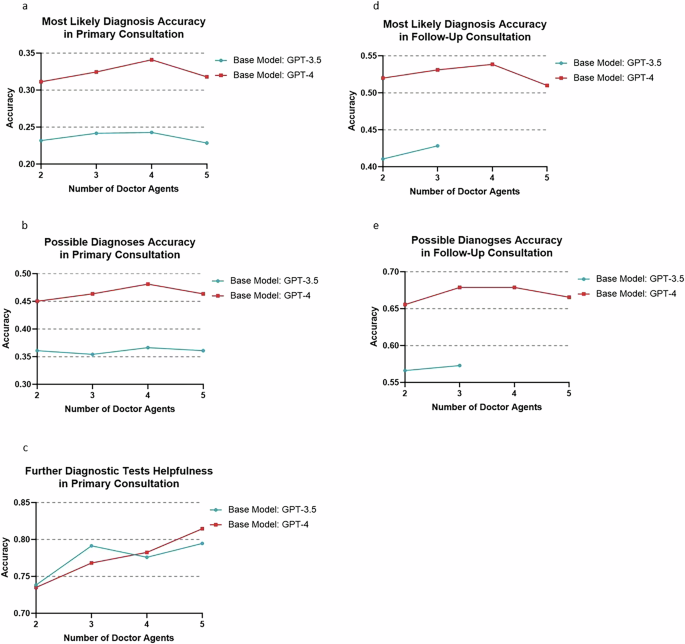
a Accuracy of most likely diagnosis in primary consultation; b Accuracy of possible diagnoses in primary consultation; c Accuracy of most likely diagnosis in further diagnostic test; d Accuracy of most likely diagnosis in follow-up consultation; e Accuracy of possible diagnoses in follow-up consultation. For MAC using GPT-3.5 as the base model, settings with more than 2 doctor agents were not feasible due to token output limitation. The lines indicate percentage.
The study examined the effect of varying the number of doctor agents (2 to 5) on the multi-agent framework’s performance. Using GPT-4 as the base model, the Most Likely Diagnosis accuracy in primary consultations was 31.31% for 2 agents, 32.45% for 3 agents, 34.11% for 4 agents, and 31.79% for 5 agents. In follow-up consultations, the accuracy was 51.99%, 53.31%, 53.86%, and 50.99% for 2, 3, 4, and 5 agents respectively. Similar trends were observed for the Possible Diagnosis accuracy and Further Diagnostic Tests Helpful Rate metrics. With GPT-3.5 as the base model, 4 doctor agents also produced optimal performance in primary consultations. However, for follow-up consultations using GPT-3.5, configurations with 4 and 5 doctor agents were not feasible due to token output limitations. The results are shown in Tables 1, 2, and Fig. 7.
The effect of excluding the supervisor agent from the MAC framework was investigated. In primary consultations using GPT-4 as the base model, the exclusion of the supervisor agent resulted in decreased accuracy for both the most likely diagnosis (34.11% with supervisor vs. 32.67% without) and possible diagnoses (48.12% vs. 45.47%). The accuracies for further diagnostic tests remained similar (78.26% vs. 78.04%). When using GPT-3.5 as the base model, the exclusion of the supervisor had less impact on performance. In follow-up consultations, excluding the supervisor agent also led to reduced performance for both the most likely diagnosis and possible diagnoses.
The study investigated the impact of assigning case-specific specialties to doctor agents on MAC performance. Using GPT-4, the four most relevant specialties were identified for each case, and doctor agents were instructed to assume these specialist roles. The results showed that the assignment of specialties to doctor agents did not significantly improve MAC’s performance compared to the standard configuration without assigned specialties.
Reliability analysis
The MAC framework’s reliability was evaluated through three repeated testing rounds across six settings. Results demonstrated minimal performance variation across testing rounds. Fleiss’ kappa analysis showed moderate agreement (>0.4) in 23 out of 28 evaluations, and fair agreement (0.35–0.4) in the remaining five. Detailed results are listed in Supplementary Tables 6 and 7.
Error analysis
Errors in diagnoses were classified into four categories based on their proximity to the correct diagnosis, while errors in recommended tests were categorized into three levels based on their utility and appropriateness. Detailed results are listed in Supplementary Table 8.
Cost analysis
A cost analysis of the MAC framework was conducted, revealing that when using GPT-4 as the base model, the average cost per case was $0.12 USD for primary consultations and $0.17 USD for follow-up consultations Detailed results are listed in Supplementary Table 9.
Generalizability of other LLM
GPT-4o-mini was tested to evaluate if the MAC framework could be generalized to newly released LLM. MAC significantly improved GPT-4O-mini’s diagnostic performance as well. The performance of GPT-4O-mini is comparable to that of GPT-3.5-turbo but significantly lower than that of GPT-4. The reliability of GPT-4o-mini within the MAC framework was fair to moderate (ranging from 0.3 to 0.6). The detailed results are listed in Supplementary Tables 10 and 11.
Comparison with other methods to improve diagnostic performance
The performance of MAC was compared with Chain of Thought (CoT) prompting, Self-Consistency, and Self-Refine methods. The results indicated that all methods showed improved accuracy for the most likely diagnosis, possible diagnoses, and helpfulness of further diagnostic tests in both the primary and follow-up consultations. MAC consistently produced the highest average output tokens, followed by Self-Consistency, Self-Refine, and CoT Prompting. Overall, MAC outperformed the other methods across all evaluation metrics, while Self-Refine and Self-Consistency showed improvements but did not reach MAC’s performance. CoT Prompting yielded more modest gains. The results were listed in Supplementary Table 12.
Influence of output token on model performance
The impact of output token scaling across all methods were evaluated. For CoT prompting, increasing the output token count improved performance in both the primary and follow-up consultations, particularly in most likely diagnosis accuracy, possible diagnosis accuracy, and the helpfulness of further diagnostic tests. For self-refine, increasing the number of refinement rounds from 2 to 4 enhanced performance, particularly in most likely diagnosis and helpfulness of further diagnostic test, although further rounds (10) led to a slight decline in performance. Self-consistency showed improved performance when increasing reasoning paths from 5 to 10, but a small decline was also observed when increasing reasoning paths to 20. For MAC, increasing the conversation rounds to 13 and 25 raised output token counts but did not yield significant performance improvements. Detailed results are provided in Fig. 8 and Supplementary Table 13.
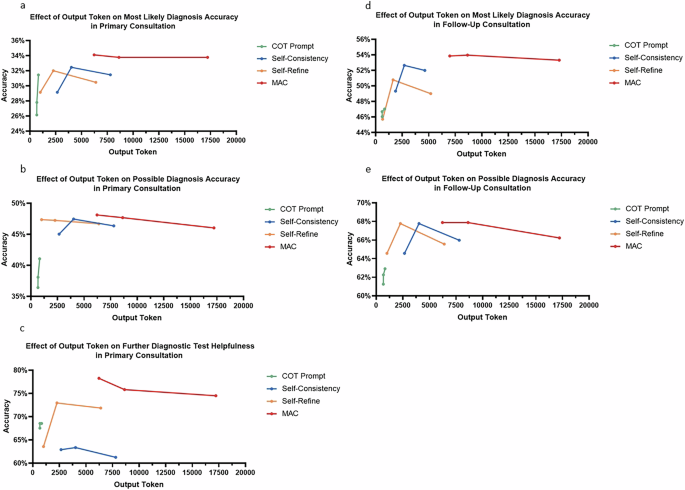
a Effect of output token on most likely diagnosis accuracy in primary consultation; b Effect of output token on possible diagnosis accuracy in primary consultation; c Effect of output token on further diagnostic test helpfulness in primary consultation; d Effect of output token on most likely diagnosis accuracy in primary consultation; e Effect of output token on possible diagnosis accuracy in follow-up consultation.
Discussion
Despite GPT-3.5, GPT-4, and MAC demonstrating comparable levels of satisfactory knowledge, the diagnostic outcomes for GPT-3.5 and GPT-4 were notably less effective in real-world cases. These findings demonstrate the gap between having an extensive knowledge base and effectively applying it in clinical practice.
On the other hand, the implementation of MAC substantially enhanced the diagnostic capabilities of LLMs in comparison with single-agent models. Further investigation into the Multi-Agent Collaboration (MAC) framework yielded several important insights. A more powerful base model (GPT-4) led to better overall performance compared to configurations using GPT-3.5. The optimal number of doctor agents was found to be four, with three agents producing comparable results. The presence of a supervisor agent significantly enhanced the framework’s effectiveness. Further comparison with other methods, including CoT, self-refine, and self-consistency, showed that MAC outperformed these techniques in diagnostic performance, generating significantly more output tokens. The increased output facilitated the exploration of diverse reasoning paths and enabled the reflection and revision of previous outputs. This allowed for more in-depth analysis, potentially uncovering underlying causes of diseases that may have been overlooked. As such, MAC represents a promising approach to bridging the gap between knowledge bases and clinical capabilities in disease diagnosis.
In this study, a gap was identified between the extensive knowledge base and clinical diagnostic capabilities of LLMs. This disparity could be attributed to several factors. First, a robust medical reasoning capability is required for LLMs to make diagnoses based on patient conditions. However, recent studies have raised questions regarding the reasoning abilities of these models, suggesting potential limitations in their application to complex reasoning scenarios15. Second, the training materials for LLMs are primarily structured in a question-and-answer format, with a focus on imparting general medical knowledge16,17,18. However, this approach fails to provide training in specialized domains and does not sufficiently incorporate actual clinical practice. Given the vast number of these diseases, their low incidence rates, and the limited reporting of cases19,20, the creation of a comprehensive database for training LLMs in the management of rare diseases remains challenging.
In this study, the MAC framework significantly outperformed the single-agent models across all metrics. One previous study tested the capability of GPT-3.5 and GPT-4 in rare disease diagnosis with ten cases, the reported accuracy was 23% and 40%, respectively21. In this study, GPT-3.5 and GPT-4 are capable of diagnosing diseases based on apparent symptoms, such as identifying pericarditis and epilepsy through clinical presentation. However, they lack in-depth exploration of the underlying causes of these conditions. In contrast, the MAC framework, through more in-depth analysis via joint conversation, can determine that pericarditis in a specific case is caused by Bardet-Biedl Syndrome. Representative examples of comparison between single-agent model and MAC are listed in Table 3.
Comparative analysis showed MAC outperformed other methods, including CoT, self-refine, and self-consistency22,23. The reason might be that the multi-agent systems allowed significantly more output token, the increased output allowed exploration of diverse reasoning paths and enabled the reflection and revision of previous outputs. This multi-agent structure enables complex, multi-directional interactions between different reasoning paths, allowing for immediate integration of diverse perspectives. One case example, as shown in Supplementary note 1, illustrated how doctor agents present varied opinions on diagnostic approaches and tests, with the supervisor agent synthesizing viewpoints and guiding discussions.
Further analysis was conducted to investigate the role of output tokens in model performance across all methods used in this study. Our results suggest that increasing the number of output tokens can lead to performance improvements. However, for Self-Refine, Self-Consistency, and MAC, this performance increase reaches a threshold, beyond which further increases in output tokens do not yield additional improvements. In contrast, for CoT, we observed that as the output token count increased, model performance continued to improve. These findings align with previous research, which shows that while increasing the number of LLM calls and thus output tokens can enhance performance, the extent of this improvement is limited by task type and the refinement methods employed24.
Our investigation into the Multi-Agent Collaboration (MAC) framework revealed several key factors that influenced its performance. The choice of base model significantly impacted the system’s effectiveness. While the MAC framework utilizing GPT-3.5 outperformed standalone GPT-3.5 and GPT-4 models, it still fell short of the MAC framework employing GPT-4. This suggests that more advanced language models can enhance the overall performance of multi-agent systems, the finding is in consistent with one previous study25. The number of doctor agents plays a crucial role in the framework’s performance. Configurations with four agents consistently produced the best outcomes, closely followed by those with three agents. The presence of a supervisor agent proved to be another critical factor. This agent was instrumental in moderating discussions and eliciting diverse opinions. Its exclusion led to a notable decrease in MAC’s overall performance, highlighting the importance of a coordinating entity in multi-agent systems. Lastly, assigning specialties to doctor agents did not yield a significant performance improvement; this may stem from the inherent capabilities of the base model. This observation is consistent with prior research indicating that although agents can assume specific roles, their fundamental abilities may be insufficient in the domain-specific knowledge and skills require to function optimally as clinical specialists in complex clinical task26,27. This finding underscores the need for further research aimed at enhancing the specialized capabilities of AI agents for healthcare applications.
Recent advancements in multi-agent systems have shown promising results in medical decision-making and diagnosis. Several notable frameworks have emerged, each with unique approaches to leveraging large language models (LLMs) for clinical tasks25,28,29. For example, MEDAGENTS is an innovative multi-disciplinary collaboration framework that enhances large language models’ performance in zero-shot medical question answering25. There are several distinct features among different multi-agent systems. While the majority of the frameworks focus on general medical question answering25,28, our framework is focused on diagnostic tasks. It encourages multiple agents to analyze the same clinical context, engage in interactive discussions, and provide open-ended diagnostic suggestions. With regard to the setting of agents, the MAC framework includes several doctor agents and a supervisor agent, while other frameworks adopted settings such as creating agents for questions and answers separately. Regarding consensus determination, these frameworks differ in their approaches. In MedAgents’ iterative revision process, the answer is refined until all experts approve. In contrast, our framework employs a supervisor agent who determines when doctor agents have reached a sufficient level of agreement. While various multi-agent systems exhibit distinct configurations and objectives, their collective potential for application in the medical domain appears promising. Further research may be warranted to fully explore and evaluate the capabilities of such systems in healthcare settings.
Multiple studies have evaluated the diagnostic capabilities of large language models (LLMs). One study examined GPT-4’s performance in diagnosing complex cases using published case records, finding that the model’s top diagnosis matched the final diagnosis in 39% of cases2. Another study demonstrated that while LLMs show potential for clinical decision-making, they currently underperform compared to human clinicians in diagnosing common conditions such as appendicitis, cholecystitis, diverticulitis, and pancreatitis. The study also revealed that LLMs struggle with guideline adherence and require substantial supervision. However, it should be noted that this study used older models such as Llama-2, which may perform less optimally than more advanced models like GPT-430. In a separate investigation, researchers evaluated the differential diagnosis capabilities of OpenAI’s GPT-3.5 and GPT-4 models across 75 consecutive real-world clinical cases. The results indicated that GPT-4 demonstrated superior diagnostic accuracy compared to GPT-3.5, with its differential diagnosis lists more closely aligning with those generated by human experts31.
Recent advancements in generative artificial intelligence have the potential to enhance the diagnostic capabilities of large language models (LLMs), with techniques such as prompt-based learning and fine-tuning playing crucial roles32. Chain-of-thought (CoT) prompting has been used to decompose complex diagnostic tasks into linear steps, which aids in integrating context and delivering comprehensive diagnostic reasoning33. Fine-tuning methods, especially supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF), are employed to align LLMs with domain-specific knowledge and user expectations. Studies have demonstrated that fine-tuning enhances the diagnostic precision of models through task-specific data and domain-specific knowledge34,35. Additionally, one study showed that RLHF can improve model responses to be more accurate and aligned with human-like diagnostic reasoning36. However, even with these technological advancements, LLMs still face significant challenges when diagnosing complex and rare diseases, and their effectiveness lacks validation in real clinical applications.
Diagnosing rare diseases remains a global challenge, one that even human experts struggle with, and it is unlikely that LLMs will surpass human capabilities in domains requiring extensive medical knowledge and sophisticated analytical skills in the short term. Therefore, even with the advent of more advanced models, it is reasonable to deduce that the multi-agent collaboration model will continue to offer significant advantages in solving complex medical tasks. Although existing benchmarks offered comprehensive evaluation of LLMs’ medical knowledge, challenges remain in assessing their application in clinical senarios1,37. Our study tried to address this issue by obtaining a collection of standardized rare disease data, manually curated by professional physicians to meet the need in clinical practice. This dataset can also serve as a benchmark for future research.
Timely diagnosis of rare diseases has always been challenged by a lack of high-quality medical resources in many regions of the world, and delays in diagnosis lead to delays in treatment and poor prognosis7,8. MAC provides valuable diagnosis suggestions and recommend further diagnostic tests during different stages of clinical consultation, and is applicable to all types of rare diseases. It may serve as a valuable second opinion tool when doctors face challenging cases. The framework also holds the potential to be generalized to other medical challenges, which warrants further exploration.
Given the vast number of rare diseases, the sample size in this study was relatively small, representing only a preliminary exploration. However, normalized random sampling was employed to enhance the representativeness of the selected cases. The primary consultation was manually extracted from the patient information to simulate the initial patient consultation. Although this was performed by medical professionals, the extraction was subjective and may not always accurately reflect the actual consultation. The rationale for this design was to reflect varying diagnostic needs at different stages of patient care. Future studies should aim to expand the sample size and incorporate a wider range of diseases to further validate and refine the MAC framework’s performance in diverse clinical settings.
MAC provided insights into how the models performed medical reasoning and handled different opinions during multi-agent conversations, which may serve as interpretation on how LLMs reasoned through the task. However, it should be noted that mere output explanations do not fully capture the model’s inherent interpretability. Previous study has indicated that models may sometimes provide incorrect explanations alongside correct answers, or vice versa38. Conversely, techniques such as Chain-of-Thought (CoT) enable models to generate more extensive outputs detailing their reasoning processes. In most cases, this enhancement can improve model performance39,40. The reasoning process can thus be considered an explanation, offering valuable insights into how the model arrives at its answers. In general, the limitations of explanations provided by large language models (LLMs) in their outputs should be noted, as the issue of explainability remains a persistent challenge that necessitates ongoing research41. The MAC system should be seen as a supportive tool for clinicians, rather than a replacement for clinicians.
To provide insights for future researchers conducting similar studies, it is important to understand the role of human effort involved in this research. In this study, human effort was involved in two tasks: case acquisition and curation, and evaluation of output results. Case acquisition required manually screening published case reports from the PubMed database to ensure accurate and relevant data for rare diseases. Curation involved clinical expertise to organize the data according to the patient’s condition during different consultation stages. The evaluation process also relied on physicians to assess the reliability of LLM evaluations. However, more complex tasks, such as analyzing diagnostic dialogue, required human involvement due to the advanced medical reasoning needed. As LLM technology continues to advance, we expect the scope of tasks they can autonomously handle to expand, thereby reducing the need for human input in the future.
This study revealed that Multi-Agent Conversation (MAC) framework significantly enhanced the diagnostic capabilities of Large Language Models (LLMs) in clinical settings. While single-agent models like GPT-3.5 and GPT-4 possess extensive knowledge, they show limitations in applying this knowledge to real-world medical cases. The MAC framework substantially improved diagnostic outcomes, effectively bridging the gap between theoretical knowledge and practical clinical application. These results underscore the value of multi-agent LLMs in healthcare and warrant further investigation into their implementation and refinement for clinical use.
Methods
Study design
In this study, we first developed a Multi Agent Conversation (MAC) framework based on GPT-4, utilizing the structure provided by Autogen11. This framework facilitates consensual oriented discussion among one supervisor agent and three doctor agents. Subsequently, we assessed the knowledge and diagnostic capabilities of GPT-3.5, GPT-4, and the MAC for 302 rare diseases using real-world clinical case reports sourced from the Medline database. Different settings within the MAC framework were also investigated to see how they would influence MAC’s performance. Reliability analysis and cost analysis were also performed. This study utilized published literature to curate the test dataset, and no actual human participants were involved. Therefore, the need for institutional approval was waived.
To evaluate the clinical effectiveness of these models, two scenarios were designed for each case. The first scenario simulates a primary consultation where only basic patient information is available, testing the models’ clinical ability with limited data to provide suggestions for further diagnostic workup. The second scenario represents a follow-up consultation, where patients have undergone all diagnostic tests. This scenario aims to assess whether the LLMs can reach correct diagnosis with complete patient information. The disease selection and testing process is shown in Fig. 1.
Data acquirement
This study involved 302 rare diseases selected from a pool of over 7000 across 33 types in the Orphanet Database, a comprehensive rare disease database co-funded by the European Commission42. Owing to the varied distribution of rare diseases among different types, a normalized weighted random sampling method was used for selection to ensure a balanced representation. The sampling weights were adjusted based on the disease count in each type and moderated by natural logarithm transformation43,44.
After the diseases were selected for investigation, clinical case reports published after January 2022 were identified from the Medline database. The search was conducted by one investigator and reviewed by another investigator.
Clinical case reports were included if they 1) presented a complete clinical picture of a real patient diagnosed with a rare disease, including demographics, symptoms, medical history, and diagnostic tests performed. 2) were published in English. Case reports were excluded if they 1) lacked information required to make a diagnosis, 2) were not published in English, 3) were animal studies, 4) contained factual errors that would influence the diagnosis, and 5) reported diseases other than those in the intended literature search.
Two specialist doctors independently screened the search results using defined criteria. The first investigator selected case reports for the test, followed by repeated screening by the second investigator. Any disagreements were resolved through a group discussion.
For each disease, the search results were screened until an eligible case report was identified. If no suitable reports were identified, new random sampling within the same disease category was conducted to select a different disease.
Data extraction
One investigator manually extracted data from each clinical case report, which was subsequently reviewed by a specialist doctor for extraction accuracy. The extracted information includes patient demographics, clinical presentation, medical history, physical examination results, and outcomes of tests (e.g., genetic tests, biopsies, radiographic examinations), along with the final diagnosis.
Final and possible differential diagnoses from the original texts were extracted for evaluation purposes.
Data curation
The primary goal of data curation is to employ the data in simulating various stages of the clinical consultation process, thereby evaluating the practical utility of Large Language Models (LLMs) in clinical settings. Two clinical scenarios were created for each case, primary consultation and follow-up consultation. The primary consultation tests if the LLM would be helpful in the patient’s first clinical encounter where there is only limited information available. It simulates a situation in which a patient first seeks help at a primary healthcare facility and is attended to by a primary care physician. (Fig. 2a). The follow-up consultation tests if the LLM would provide correct diagnosis with the patient’s complete picture, including any results from advanced diagnostic tests, were given. It simulates a fully informed diagnostic scenario, aiming to evaluate the capacity of the LLM to perform medical reasoning and reach a final diagnosis with comprehensive data (Fig. 2b).
Multi-agent conversation framework
GPT-3.5-turbo and GPT-4 are commonly tested for medical purposes and were selected as the base model for the Multi-Agent Conversation Framework (MAC). The MAC framework, aimed at diagnosing and generating knowledge about rare diseases (Fig. 3), was developed under AutoGen’s structure11. This setup simulated a medical team consultation with doctor agents and a supervising agent.
To initiate the multi-agent conversation, the admin agent first presents the patient’s information and tasks to the conversational agents. This conversation utilizes a consensual framework without a predetermined speaking order. Each agent fulfills its designated roles while responding to the input from previous agents. The tasks for doctor agents include:1) Providing diagnostic reasoning and recommendations based on expertise. 2)Evaluating and commenting on other agents’ opinions with reasoned arguments. 3)Addressing comments from other agents and improving output accordingly. The tasks of the supervisor include: 1) Overseeing and evaluating suggestions and decisions made by doctor agents. 2) Challenging diagnoses and proposed tests, identifying any critical points missed. 3) Facilitating discussion between doctor agents, helping them refine their answers. 4) Driving consensus among doctor agents, focusing solely on diagnosis and diagnostic tests. 5) Terminating the conversation when consensus has been reached. The dialogue continues until the agents reach a consensus or the maximum number of conversation rounds is met, which, in this study, was set at thirteen.
Generating disease specific knowledge
GPT-3.5, GPT-4, and MAC were assessed for their knowledge of each rare disease covered in the study. Each model is tasked to generate disease specific knowledge including disease definition, epidemiology, clinical description, etiology, diagnostic methods, differential diagnosis, antenatal diagnosis, genetic counseling, management and treatment, and prognosis.
Generating diagnosis and recommended tests
For the primary consultation, the LLMs were tasked with generating one most likely diagnosis, several possible diagnoses, and further diagnostic tests. For follow-up consultations, the LLMs were tasked with generating one most likely diagnosis and several possible diagnoses. Mirroring real-world diagnostic procedures, no specific numerical constraints were placed on the potential diagnoses and diagnostic tests recommended.
Subgroup analysis within MAC
Subgroup analyses were performed within the MAC framework, including comparing MAC’s performance when using GPT-4 versus GPT-3.5 as the base model to assess the impact of the base model; examining the effect of varying the number of doctor agents (ranging from 2 to 5) involved in the framework; evaluating whether excluding the supervisor agent would negatively impact MAC’s performance; and investigating whether assigning case-specific clinical specialties to each doctor agent would influence performance outcomes. The specialties are listed in Supplementary Table 14. During implementation, GPT-4 analyzes patient cases to identify the most relevant specialties. Specific prompts were then employed to instruct each doctor agent to assume the role of the corresponding specialist and engage in discussion.
Performance evaluation
The performance of GPT-3.5, GPT-4, and MAC were evaluated across several tasks including performance in generating knowledge, generating most likely diagnosis, possible diagnoses and further diagnostic tests.
Disease specific knowledge was evaluated using Likert Scale. The Likert scale is a psychometric scale commonly used in questionnaires to measure attitudes or opinions. The evaluation metrics covered five aspects, which included: inaccurate or inappropriate content, omissions, likelihood of possible harm, extent of possible harm, and bias, which are shown in Table 437.
Diagnostic performance was evaluated using accuracy and rating scales. For the most likely diagnosis and possible diagnoses, the answer was considered accurate if it included the exact correct diagnosis. For further diagnostic test recommendations, the answer was deemed accurate if it was helpful in reaching the correct diagnosis. For the rating scales, the most likely diagnosis and possible diagnoses were evaluated using a five-point scale described by Bond et al. 45, which is shown in Table 5. The further diagnostic test recommendations were evaluated using a Likert scale, which is shown in Table 6.
Considering the number of outputs to be evaluated exceeded thirty-five thousand, evaluation was performed using a large language model (GPT-4o) with the correct answer provided, to investigate whether GPT-4o was able to perform accurate and reliable evaluation. Human evaluation was performed for 302 cases, and the consistency between human and LLM evaluation was analyzed. Human evaluation was conducted through panel discussions among three physicians who were blinded to the model conditions and reviewed the content in a randomized order. The physicians discussed each case and reached a consensus score. GPT-4o showed high consistency with human evaluation, as shown in Table 7.
Reliability analysis
The reliability of the MAC framework was evaluated, which involved three repeated rounds of testing across six distinct settings, assessing MAC’s performance consistency with different base models, with and without the supervisor agent, and with and without specialty assignments to doctor agents. To quantify the inter-run agreement, Fleiss’ kappa, a statistical measure for assessing reliability among multiple tests, was employed. Fleiss’ Kappa values were interpreted as follows: <0.00 indicates no agreement, 0.00–0.20 slight, 0.21–0.40 fair, 0.41–0.60 moderate, 0.61–0.80 substantial, and 0.81–1.00 almost perfect agreement46. Kappa values were calculated for the accuracies of most likely diagnosis, possible diagnoses, and recommended tests in primary consultation, and for most likely diagnosis and possible diagnoses in follow-up consultation.
Error analysis
Error analysis was performed by categorizing and analyzing incidences of inaccurate answers. For the most likely diagnosis and possible diagnoses, we have classified errors into four categories: 1) Very close to the correct diagnosis, but not exact, 2) Closely related to the correct diagnosis and potentially helpful, 3) Related to the correct diagnosis, but unlikely to be helpful, 4) No suggestions close to the correct diagnosis. Regarding errors in recommended tests, we have further categorized them as follows: 1) Questionable utility of the suggested tests, 2) Disagreement with the helpfulness of the suggested tests, 3) Strong disagreement with the appropriateness of the suggested tests.
Cost analysis
Cost analysis was performed to calculate the average cost to run a case when using GPT-4 and GPT-3.5 as the base model.
Comparison with other methods to improve diagnostic performance
The effect of Input/Output (I/O) Prompting, Chain of Thought (CoT) prompting, Self-Consistency, and Self-Refine methods were evaluated. The detailed CoT prompts are provided in the Supplementary Note 2. For self-consistency, following established literature, we implemented a framework with 10 distinct reasoning paths and set the temperature parameter to 0.723. The self-refine approach was configured with four iterative refinement rounds at a temperature of 0.7, as adopted in prior research22. Each refinement cycle consisted of three steps: first, the LLM generated an initial answer; second, it produced self-feedback by assigning a score (0-50) to the answer and providing specific improvement suggestions; and third, it revised the answer according to these suggestions. This process repeated for four rounds, with each revised answer receiving a new score. The final output was selected based on the highest-scoring version among all iterations.
Influence of output token on model performance
The effect of output token scaling on all methods used in this study was evaluated by varying the output token count for each method to assess its impact on model performance. For CoT prompting, the output token count was increased by modifying the standard prompt to include: “Please allocate additional time and effort to provide a comprehensive and detailed reasoning process for this task.” Conversely, the token count was reduced by adding: “Please reduce the time and effort to provide a short reasoning process for this task.” For Self-Refine, the model’s output token length was controlled by varying the number of refinement rounds, with configurations of 2, 4, and 10 rounds. For Self-Consistency, the output token length was adjusted by varying the number of reasoning paths, testing 5, 10, and 20 paths. For MAC, the agents’ configuration was modified to continue the conversation until a predetermined number of conversation rounds was reached, with settings of 13 and 25 rounds. Output tokens were recorded for each method, and performance was subsequently evaluated.
Statistical analysis
Statistical analyses were performed using SPSS version 25 (IBM, Armonk, NY, USA) and GraphPad Prism version 8 (GraphPad Software, San Diego, CA, USA). The results from human evaluation framework were recorded as continuous variables and they are presented as means and standard deviations. The Shapiro–Wilk test was used to check if the data followed a normal distribution. Depending on the distribution, an ANOVA, or Kruskal–Wallis test, was applied to test for difference in performance among the models. The accuracy of most likely diagnosis, possible diagnoses and the helpfulness of diagnostic tests were recorded as incidence and rate. For these discontinuous data, chi-square test was used to test for differences among the models. Flessi-Kappa was used to assess the consistency of model’ outputs among multiple runs.




Responses