Enhancing precision agriculture through cloud based transformative crop recommendation model

Introduction
One of the first pillars of human civilization, agriculture has changed a lot over the years. As the earth’s population explodes, demand for this vital sector has soared. Agriculture is now a tech-driven industry. It focuses on data-based innovations and decisions. Manufacturers can help meet the urgent need for more food in agriculture. In recent years, many new technologies have emerged since the agricultural revolution. It aims to equip farmers for modern farming1,2. A quickening transformation in the agriculture sector is being driven by the growth of Internet of Things (IoT) technology3. The need for food production is growing quickly because it is predicted that by 2050 there will be 9.7 billion people on the planet4. Agriculture is now a tech-driven industry. It focuses on innovations and data-based decisions. Manufacturers must use these to meet the urgent need for food5. These technologies are key to high, sustainable agricultural yields to ensure efficient farming. At the heart of this overhaul is the use of data. Researchers collect it with care from various sources and analyze it. This data will inform decisions with high accuracy and speed6. A novel, cloud-based crop recommendation platform for precision farming is being designed. At the heart of precision farming is a mantra. It says that we can optimize farming by making it site-specific to each field’s uniqueness. Using machine learning7 algorithms such as decision trees, random forests, extra trees, logistic regression, SVM (support vector machines), KNN (k-nearest neighbor), DT (decision tree), XGBoost (extreme gradient boosting), Gaussian naive Bayes, AdaBoost, and bagging classifiers. It aggregates and preprocesses raw data to combine several datasets from multiple sources. The researchers want to find the best algorithm. It should give farmers personalized crop suggestions. The recommendations come from a vast database. It includes environmental factors, agronomic variables, and past farm performance data. It is hoped to provide farmers with the information they need. This will help them make timely, data-driven decisions. 8 proposed a rise in using advanced ensemble learning in precision agriculture. This was especially true for crop recommendation systems. Traditional machine learning often fails with complex, high-dimensional agricultural data. New methods, like stacking, an ensemble of ensembles, and federated learning, are now strong alternatives. It offers better accuracy, adaptability, and scalability. These methods use diverse models. Methods aim to improve predictions and reduce bias. It also tackles issues like data diversity and privacy. Combining these ensemble techniques with user-friendly platforms like Streamlit boosts their use. It enables efficient, interactive decision-making for sustainable agriculture. 9 discussed the lack of labeled data in crop recommendations. It noted that generative models like VAEs and GANs could help. These models create synthetic data that mimics real-world crop data. This improves the training and performance of agricultural recommendation systems.
10 proposed a cloud-based crop recommendation platform. It would provide a wealth of real-time recommendations. It has an SMS alert system. It will keep farmers, especially in remote areas. This new technology could revolutionize agriculture. It would improve efficiency and sustainability. Farmers can thus be equipped with actionable, data-based, real-time insights. It can use resources better to boost crop yields. It supports a global goal of safe food for future generations11. The next posts will cover the why, how, and lessons learned from a paradigm-shifting approach to modern agriculture. The growing human population raises the demand for farming. It poses a global food security challenge. With the human population expected to rise by 9.7% in a few decades, our agricultural systems face immense pressure. Arab Spring, a need to feed people, and a youth surge in fast-growing regions. However, we will need new farming methods to feed them. They must produce sustainable food for future generations.
12 explored using Explainable AI (XAI) in crop recommendation systems. It highlighted XAI’s potential to make AI-driven recommendations transparent and reliable. XAI methods, like SHAPE and LIME, can help. These methods improve the interpretability of machine learning models in agriculture. These approaches enable farmers to comprehend and trust AI-generated insights, thereby improving decision-making. Also, studies stress the importance of feature importance and visualization techniques, like dependency and summary plots, in explaining model behaviors. Counterfactual explanations, integrated gradients, and layer-wise relevance propagation methods boost these systems’ explanatory power. The reviewed literature shows a need for transparent AI tools. They can promote sustainable agriculture and build trust among stakeholders. People must use precision agriculture technology to boost food security. It can optimize crop yields and resource use through data. This paper’s focus on a cloud-based TCRM for precision agriculture is very relevant to supercomputing. Advanced machine learning (ML) algorithms and data-driven insights use large, diverse datasets. These algorithms contain environmental and agronomic factors. The Transformative Crop Recommendation Model (TCRM) fills gaps in existing systems. It uses advanced machine and deep learning to provide accurate, tailored crop recommendations. It has a 94% accuracy rate. It can scale for real-time, cloud-based, SMS-enabled farmer assistance. It connects traditional agronomy and modern data-driven insights. It ensures sustainable, context-specific farming practices. To address the challenges and opportunities highlighted, this study proposes the Transformative Crop Recommendation Model (TCRM), designed to bridge gaps in traditional farming with data-driven precision agriculture.
Motivation and contribution
The Transformative Crop Recommendation Model (TCRM) is a novel model that is proposed in this paper. It aims to boost sustainability and productivity in Punjab, India. The region faces soil degradation, water scarcity, and population pressures. Traditional farming and modern solutions, like GMOs(genetically modified organism) and new irrigation, can’t meet the demands of food security, climate change, and resource scarcity. The Transformative Crop Recommendation Model (TCRM) uses advanced machine learning and a cloud-based system. It gives real-time, data-driven crop recommendations based on environmental and agronomic factors. TCRM uses IoT sensors, live data, and an SMS alert system. It enables precision agriculture by giving remote farmers insights. It can optimize yields, conserve resources, and promote sustainability. This work helps develop a precision agriculture solution. It uses AI(Artificial Intelligence), IoT(Internet of Things), and cloud computing. The aim is to boost productivity, support sustainable farming, and benefit all in the agricultural value chain. Figure 1 demonstrates the general steps in precision farming, from data collection via IoT sensors to tasks executed by agricultural robots using understandings of the analyzed data. Table 1 sheds light on machine learning algorithms.

Steps involved in precision agriculture10.
Aims and objectives
Empowering precision farming: To empower farmers with data-driven recommendations that enhance the efficiency, sustainability, and productivity of their agricultural practices.
Evaluation of machine learning algorithms: To thoroughly evaluate and compare the effectiveness of machine learning methods for making correct crop recommendations, such as logistic regression, KNN, AdaBoost, and the transformative crop recommendation model (proposed).
Development of a cloud-based crop recommendation platform: To plan and build a cloud-enabled agricultural recommendation tool for farmers.
Integration of real-time data and alerts: To integrate SMS alert generation technology and real-time data sources into the platform to facilitate prompt decision-making.
With these objectives as a guiding framework, the organization of this paper lays out the methodology, results, and discussions systematically to ensure clarity and focus.
Organization of paper
The paper introduces the Transformative Crop Recommendation Model (TCRM). It’s a cloud-based platform to improve precision agriculture using machine learning. The study reviews the role of IoT and ML in precision farming. It emphasizes the need for tailored crop recommendations. It then details the methodology. This includes data collection, preprocessing, feature engineering, and model selection. It shows that the TCRM outperforms traditional algorithms on key metrics. The results show TCRM’s high accuracy and scalability. It can send personalized SMS alerts, especially to resource-limited areas. Finally, the paper discusses the implications for sustainable agriculture. It outlines future improvements that includes using IoT data and explainable AI for transparency and adoption. Table 2 sheds light on related work in the context of description, methodology, findings, benefits, and gaps. The following section delves into the existing body of work, highlighting recent advancements and identifying gaps that this study seeks to address.
Related work
Building upon these findings, this paper introduces a robust methodology for implementing a cloud-based crop recommendation system powered by TCRM.
Role of machine learning in internet of things and precision agriculture in crop recommendation
Machine Learning is key to IoT and precision agriculture. One use case is crop recommendation28. Machine learning provides a single interface to aggregate data from tens of thousands of IoT devices and sensors in remote farms. 29 The devices measure many variables, such as soil moisture, temperature, and humidity, as well as crop health. With their integration, ML algorithms help organizations fully understand their data. Feature selection is one of the few machine learning skills. It can identify the key factors that most affect crop yield. They cause the largest variations in changes to gateway-destined crops. Machine learning clears these paths. It helps only with the strongest variables to make recommendations and evaluations. ML algorithms encourage each farmer to decide what crop is to be picked by analyzing previous data related to soil nutrients, climate, and agricultural practices. Recommendations are then adapted to fit local information, like soil type and crop yield potential30. Such algorithms use data on past pest and disease outbreaks, bad weather, and market shifts. This data analysis can help the farmer. It can aid in better, more informed decisions about risks and losses.
A key feature is that ML models can adapt to changing conditions. It is seasonal to provide you some and modify its suggestions. In a dry time, it may suggest drought-tolerant crops or it may recommend crop rotation to improve soil fertility31. The model also turns and returns on recommendation systems based on machine learning. The system itself honed its algorithms as farmers then iterated based upon what really happened versus what the original recommendation was. This feedback loop of learning helps to make future suggestions more accurate and relevant. ML-powered crop recommendation systems32 own the traits of scalability and accessibility. This leverages extremely well on its deployable solutions and opens up farmers over the world to the tools2. This democratization also allows smaller farmers to have access to data-driven recommendations. Not only this, ML also helps in sustainability and environmentally friendly farming practices. 33 recommended crop rotation, cover cropping, and soil improvement to manage watersheds. This helps to save resources and reduce environmental impact. The above discussion, a brief intro of machine learning and IoT, is revolutionizing precision agriculture by providing advanced crop recommendations. The ML model gives farmers personalized, context-aware recommendations. It helps them make data-driven decisions. This increases crop yields and reduces risks. It also contributes to global agricultural sustainability34. Future food systems could be more resilient, effective, and sustainable due to this tech convergence.
Materials and methods
To enhance crop recommendation accuracy, a cloud-based TCRM (Transformative Crop Recommendation Model) with SMS alert generation system framework is designed and proposed by integrating state-of-the-art deep learning and traditional machine learning algorithms together. TCRM development and application target context-specific, sound predictions and recommendations for agricultural needs. TCRM architecture fuses tree-based machine learning algorithms (i.e., random forests and extra trees) with deep learning layers implemented via TensorFlow and Keras. This deep learning component includes layers such as dense layers, normalization layers, multi-head attention mechanisms, and custom to capture these complicated relationships in the data. By utilizing multi-head attention, the model is able to attend to important interactions and dependencies between features, which improves predictive power.
All the parameters are tuned using all the folds of TCRM, which gets better performance and best accuracy for our model. Training-specific hyper-parameters such as the number of epochs, which are usually set to 200, and the batch size of 32, 64, and 128 represent how many training examples to work through before updating the model parameters in iterations. Learning rate is the most well-known hyperparameter that balances oscillations and convergence, typically set at 0.001 or 0.01. In the case of deep learning layers, it may be set to 0.2 or 0.5 because the dropout is used, which randomly sets a fraction of input units to zero. This is done at training time in order to prevent overfitting.
Activation functions like ReLU (Rectified Linear Unit), Sigmoid, and Softmax help in transforming the outputs of each neuron, and optimizers such as Adam, SGD (Stochastic Gradient Descent), and RMSprop minimize loss during training. Tree-based algorithms such as random forests and extra trees have hyperparameters that are fine-tuned. For example, the number of estimators (trees) in a model is commonly between 100 and 500, the maximum depth of trees will be set at 10, 20, or none, and the minimum samples required to split a node can often accept values such as 2, 5, or even 10. In attention-based models, you can mention the number of heads, e.g., 4 or 8. It can also modify the architecture of the model by specifying a few layers (between three and five is common) to represent complex relationships within our data.
Together, these parameters ensure the robust functioning of the TCRM, enabling accurate and tailored crop recommendations. Figure 2 sheds light on a cloud-based transformative crop recommendation model (TCRM), showcasing four phases: data acquisition, preprocessing & analysis, feature engineering & modeling (including tree-based and deep learning models), and deployment & alerting through cloud integration and SMS notifications to farmers.
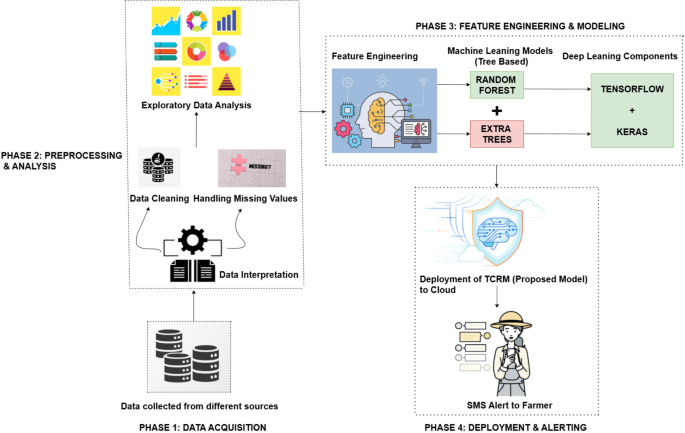
Cloud-based transformative crop recommendation model.
The proposed work is a cloud-based crop recommendation system based on ML algorithms to solve these problems. The platform aggregates, integrates, and analyzes various data streams, such as soil characteristics, climate records, and past crop behavior to recommend the most precise crop for a specific field. The system determines the best-suited crops for particular areas and growing conditions, maximizing their yield potential while minimizing waste. In addition, there is an SMS alert system for real-time recommendations. Farmers can receive timelier data-driven insights even in the remotest places. This feature maintains scalability and continuous updating and development of its predictive capacity as a cloud-based web platform. This solution combines precision agriculture techniques with modern technologies. It does not just help in better utilization of resources and aids sustainable agriculture, but it is also able to continue the production of major staples like wheat, rice, and maize that are crucial for livelihoods in the region. Getting down to Punjab also enables a regionalized approach to data gathering and analysis, which is de facto in the case of actual precision agriculture solutions. By providing information in a localized area, this approach generates valuable data that can be replicated in similar regions of the world to establish a model for sustainable agriculture in densely farmed and resource-limited areas. Algorithm 1 pseudocode provides a concise summary of the methodology adopted in developing the Transformative Crop Recommendation Model (TCRM), detailing the steps from data collection to deployment and continuous improvement.

Pseudocode representation of the methodology for developing the transformative crop recommendation model (TCRM).
Analysis of data and methodology
The database collection process, methodologies, and computing tools are covered in the data analysis and methodology. 35 designed to accomplish the study’s stated objectives (see Fig. 2).
Data gathering
Sources of data used for the purpose and research include the FAO, USDA NASS, and the World Bank data repository36 seeking to carry out the objectives of this study. ESA Data Archives, World Bank Sustainable Development Metrics, NASA Earth Data Archives, CIAT, and GODAN databases are specifically where the properties of the dataset come from. Additionally, reliable data source websites, including Data.gov, UN Comtrade, and Kaggle, were used to acquire data37.
Data pre-processing
Data received from multiple sources is first combined. The integration of the information makes it easier to manage it effectively and to accomplish the study’s stated goals, which include examining the relationships between the crop recommendation indicators. Filtration is part of the preprocessing of data. Many times filtration and purification of data are done as part of cleaning and transforming the data. This process can be applied to the data set, and removing the outliers becomes easier38. Real-world data is sporadic, inconsistent, and scarce. This results in wrong data collection, which in turn leads to making incorrect models using the data. Data preparation tasks are used to resolve these problems by data mining and configure the information in a way that makes it more familiar. As part of the cleaning phase, it tackles data outliers, consistency issues, noisy data standardization, and the missing values restoration. Faulty, insufficient, or wrong data can potentially lead to the validity of study findings at risk. So, it is a necessary step in the data preparation process39. It prepares our data in two different ways before starting further research.
The dataset used in this study comprises 3000 rows and 8 columns, representing soil and environmental factors relevant to crop recommendations. The features include nitrogen (N), phosphorus (P), and potassium (K) content in the soil, along with temperature (°C), humidity (%), soil pH level, annual rainfall (mm), and the target variable such as crop type (label). The dataset contains no missing values, ensuring completeness and reliability for analysis. All features are numeric, except for the categorical crop type column.
To prepare the dataset for machine learning, several preprocessing steps were undertaken. A thorough data quality check confirmed the absence of missing values and validated the consistency of data types. Features were scaled and normalized to standardize their ranges, enhancing model compatibility. The categorical label column was encoded to numeric format using label or one-hot encoding, depending on the model requirements. Outlier detection and handling were performed to ensure robustness, while imbalances in crop type distribution were addressed through resampling techniques such as oversampling or undersampling. Additionally, derived features like nutrient ratios were considered for feature engineering to improve the model’s predictive power. These preprocessing steps ensured the dataset’s quality and representativeness, laying a strong foundation for effective machine learning analysis. As indicated in Table 3, the gathered information is divided into the following indicators (I1 to I8).
Handling the missing values
The elimination of missing values is one of the pivotal steps in data preprocessing, particularly during mathematical and statistical analysis. Data with missing values can cause bias, errors in results accuracy, and degradation of a model’s performance. There are lots of mathematical equations and methods to deal with this issue. Imputation is one of the common methods to work with missing values39. The numbers are substituted with the predicted values based on available data.
Mean imputation is a very simple method of missing variable imputation. The mean imputation equation is given below:
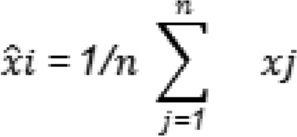
In Eq. (1):
(hat{x}i) represents the corresponding imputed value for the omitted data point xi. n is the total number of data points with non-missing values. xj represents the values of the known data.
Mean imputation simply assigns the mean (average score) of all the available values for each missing item. While this method is fast and conceptually simple, it is not always the most accurate due to the non-uniform distribution of data. It might want to consider median imputation when the data distribution is skewed or has outliers.
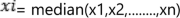
In this case, the imputed value will be the median of the data.
Salgado et al.40 use regression imputation, where missing values are imputed by fitting a regression model with other variables as predictors. The mathematical formula for regression imputation will vary depending on the type of regression model used (e.g., linear regression, multiple regression).
The way in which the data are to be utilized and how imputation may affect the study must both be carefully considered. 41 proposed a helpful approach, but it should be used judiciously and there should be an understanding of its constraints. Sometimes more complex imputation techniques such as multiple imputation, K-nearest neighbor, or machine learning models may yield better results and accurate imputations.
Data normalization
A key step in preprocessing is data normalization, which tries to bring all the data into some common range42. This kind of strategy is mostly necessary while working with or dealing with several unit types and distribution magnitudes. Normalization creates balance in all features so one feature does not dominate the analysis. Standard Scaler is a preferred type of data normalization that scales down the values of the different features, often values being between 0 and 143. The Min–Max scaling formula is given below:
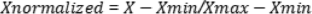
In Eq. (3):
(Xnormalized) represents the normalized value of the data point X. X is the original data point. (Xmin) is the minimum value of the feature in the dataset. (Xmax) is the maximum value of the feature in the dataset.
Scaling the original data points to a range of 0 to 1 makes the smallest size in the dataset represent 0 and the largest size present as 1. This transformation standardizes the data and makes it easier to compare and analyze the values because all data points will be on the same appreciable scale. Other normalization techniques include Z-score normalization (standardization). This method normalizes the features. The normalized data have a zero mean and unit variance.
The mathematical equation for Z-score normalization is:
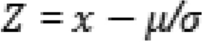
Here: The standardized (normalized) value is denoted by Z. The initial data point is x. The feature’s mean (average) in the dataset is (mu). The feature’s standard deviation within the dataset is (sigma). When the data distribution is substantially normal, Z-score normalization is helpful.
The normalization method is based on the criteria for the analysis and features of the data. These methods assist in preventing the biases or distortions from being introduced into the data after preprocessing and help the data fuel different machine learning algorithms and statistical analysis.
Exploratory data analysis (EDA)
In the process of data analysis, a key step is exploratory data analysis (EDA), where the aim is to understand and summarize the main features of a dataset. The mean is a key ingredient of centrally tended measures and is an important mathematical relation involved in EDA44, although this fact is mostly obvious with the use of visualizations and descriptive statistics. The mean ( μ ) of a dataset is:
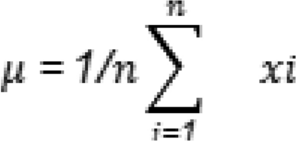
There are a number of data points (n), and between and indicates the number of each unique data point. It gives the value of the average in the numbers; it works to understand the basic or core value of your data set. EDA uses the mean, along with different visualizations, to look for patterns, trends, and outliers within your data. In addition, this full cycle enables guided decisions about data preparation, feature selection, and statistical analysis using high-level information.
Feature selection
Feature selection in data analysis and machine learning is the process of selecting those features that are more informative or useful for predictive or classification tasks45. Earlier, it explored a subset of features to meet some criteria in ML. However, the feature selection is defined as choosing the best feature from all available features. Common mathematical techniques for feature selection are the Pearson correlation coefficient r (correlation coefficients). The formula for Pearson correlation is given below:
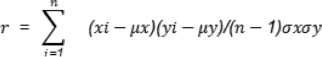
where r is the linear correlation between x and y, μx & μy are standard deviations of variables x and y, and x̅, y̅ are averages of variables x and y, respectively. One is to make a matrix of correlation between each feature and other features and the target variable as well to find out which are the features that can be a major contribution towards my solution. Possible removal of parameters that induce multicollinearity are weakly correlated during feature selection. This approach is complemented by other mathematical tools, for instance, statistical analyses and machine learning algorithms, which allow the selection of the most useful features to enhance model interpretability and performance46.
Machine learning approach
This includes a systematic approach to creating and testing models for prediction, selecting the model with the best performance. It is a strategy that requires machine learning to reach research aims with artificial intelligence powers. The dataset is split into subsets of train and test, which will make it easier to evaluate the model. Subsequently, various machine learning algorithms are applied to develop prediction models with their respective parameters47. Those models need to be trained by the training dataset before they can grade their performance through the testing dataset. Thilakarathne et al.10 assess model efficacy with metrics such as accuracy, precision, recall, and F1-score as well as cross-validation scores. Researchers often play with these hyperparameters to maximize the prediction power of their models. Through this iterative process, the model delivering the best performance will eventually surface. For example, the result of selecting the best model is based on your own study goals while balancing characteristics of models such as complexity, interpretability, and performance of a model on X (functionality) to get good accuracy in function Y (target). To increase the accuracy of prediction, a few assembling methods like bagging and boosting48 may also account for these. In general, this machine learning technique49 helps in better data-driven decision-making. It helps enable making your research results more effective as well as act as a basis for all the insights and recommendations.
Deploy the model as a web app to a local server
Deploying a machine learning model as a web application on the local server makes the developer-friendly version of the same model. Step 1 is one in a chain of steps to serialize the trained model, which means converting it into any easy-saving and known format. Next, this web-based framework is deployed on the backbone of the web framework to construct a web application50. Designing the user interface for an engaging and fluid user experience that is created using a combination of HTML, CSS, and JavaScript. The API exposes the ML model, which runs serverless on AWS Lambda, using scalable and often free processing power. Finally, this deployment gives you the ability to go from a simple base ML algorithm configuration to an interactive live front-end tool able to serve predictions or knowledge in real time through a user-friendly online face, greatly enhancing their already accessible utility for more use-cases.
Deploy machine learning model to cloud
A machine learning model has been pushed into the cloud to provide recommendations on crops. It is a strategic move hinging on their Amazon Web Services to abstract the cloud’s scalability, availability, and processing power. This deployment process includes a few important steps: The trained model is serialized and prepared to be used. Then, a deployment environment has been chosen in the cloud, be it Google Cloud Platform (GCP), Amazon Web Services (AWS), or Microsoft Azure. The model is in such cases, shipped to the cloud server together with all requisite data pretreatment and post processing pipelines51. Once the model is deployed, it exposes a web API that consumers can use to interact with the model using other applications like web or mobile apps. For example, a user will input local information like soil qualities or weather conditions into the system and receive instant crop suggestions based on the model predictions. Some of the benefits provided by cloud usage include: unlimited user accommodation, security features, and opportunities for very resource-intensive tasks to be executed quickly and efficiently52. On the other hand, cloud-based solutions allow for a far simpler update and maintenance of systems, as well as ensuring that the crop recommendation model remains correct through time. In common, transferring device finding out fashions into the cloud complements their availability and provides a better person interface that may make crop suggestions information pushed to reinforce farmers and different agricultural stakeholders.
SMS alert generation system
Using Twilio as a bureau to create an SMS alerting system, many applications and services gain a valuable notification/alert layer. One of these platforms that is providing great support for programmatically sending SMS messages in a cloud-based way comes from one of the most robust Twilio. 23 used Twilio’s APIs and services to send out SMS alerts using this system to specific recipients for various reasons or situations. This technique is quite flexible, as it can be applied in many scenarios and businesses. For example, to keep farmers informed about the weather and when their field requires watering or if a disease has broken out on the crops. For healthcare, it can be handled to push emergency notifications or for medication schedules and appointment reminders.
The same can be used in logistics and eCommerce to notify customers about the delivery status of packages, offers on promotions, or status updates related to orders53. This typically includes configuring the provider system that will send messages automatically with event triggers, setting up Twilio with its API and credentials required for authentication, as well as defining what SMS alert body you want to be sent. An SMS Alert Solution is stable and automated to promote communication, reduce Time-To-Action response periods And notify the users in real-time for a better user experience and improved operating efficiency. The methodology outlined has been rigorously applied to evaluate the TCRM, and the results offer valuable insights into its effectiveness and scalability.
Results and discussion
The different measures used to evaluate the performance of these algorithms include accuracy, precision, recall, f1 score, and K-fold cross-validation scores, which provide some insights on their performance and ability to generalize. TCRM (our proposed method) early shows good performance based on key evaluation metrics compared to baseline algorithms such as logistic regression, K-nearest neighbors, and AdaBoost. In particular, this method obtains precision, recall, and F1-score of 94.46%, 94.462%, and 93.97%, respectively. An impressive fivefold cross-validation score of 97.67% is also obtained. This exhibits a clear improvement over the performance of traditional algorithms when understood in statistics quantitatively. These metrics are compared to the relatively lower performance of traditional algorithms, highlighting a clear improvement. However, establishing true novelty in a machine learning context requires more than just superior performance. It may include unique data preprocessing methods, unique architecture designs, or new model improvements that set approaches apart from the existing ones. Moreover, the clear contrast with AdaBoost is that significantly lower scores require careful analysis, providing insights into why your method excels where traditional methods struggle, thereby further emphasizing its impact and innovative nature.
Based on these results, the TCRM (proposed method) model is opted to use in our model. It has presented the highest level of accuracy and generalization capabilities due to disappointing results with a fivefold cross-validation score compared to other models. It is required to deliver the most accurate and dependable crop recommendations to farmers. Moreover, the additional tuning or feature engineering is used. This seems to be a scope for performing more on the classification problem. Our deployed cloud-based platform with the TCRM (proposed method) model is a significant step towards the democratization of precision farming. The platform that connects them includes real-time access to customized crop recommendations, backed by an SMS alert system. These functionalities are most important in resource-limiting regions as they enable farmers to utilize their resources efficiently, reducing waste and increasing the yield of crops.
The transformative crop recommendation model (TCRM) was selected as the final model due to several key advantages that make it highly suited for agricultural datasets and real-time decision-making. TCRM showed an appropriate trade-off between efficiency and accuracy that looked to be well-suited for the rapid analysis of massive agricultural data, allowing quick turnarounds on recommendations. Models such as AdaBoost, K-Nearest Neighbors (KNN), & logistic regression were able to achieve comparable performance, but TCRM had the important benefits of speed (quick processing times are needed for an application in agriculture).
Additionally, the interpretability of TCRM makes it easy to know how different features affecting soil nutrition, weather data, and crop requirements lead to the final recommendations. Such interpretability is important in the context of agriculture since it can help provide farmers and agronomists with meaningful insights to inform their decisions. Moreover, due to the high performance of TCRM, it is able to outstand well with the extreme changes often seen in different agricultural data that reflect varying environmental conditions. The benefits of the crop recommendation model are speed, interpretability, and robustness. It serves precision agriculture well by providing accurate recommendations in a timely fashion to minimize loss of yield or nutritional quality for crops during their critical window between planting and harvesting, where optimal growth must be achieved.
Secondly, the non-field affect of this platform extends into developments that other parts of agriculture can leverage and already enables policy development. It promotes the efficient use of resources and reduces wastage of inputs, contributing to global food security and environmental sustainability while encouraging more sustainable farming by doing so. This data-driven approach has immediate socioeconomic benefits for farmers, providing them with better predictability on yields and policymakers the ability to work with an evidence base to develop sustainability-focused policies aimed at the agriculture sector.
Moreover, the system is capable of being generalized with other datasets. It has good potential as the basis for precision farming research in the future. This work provides applicable solutions and a lasting pathway to address agricultural resilience for present-day impact to farmers, scientific knowledge, as well as policymakers.
Research Objective I: To empower farmers with data-driven recommendations that enhance the efficiency, sustainability, and productivity of their agricultural practices.
To achieve Research Objective I to provide farmers with data-backed recommendations for increased efficiency, sustainability, and productivity of their agricultural practices, the research paper uses a rich dataset consisting of eight important columns. The columns are nitrogen, phosphorus, potassium, temperature, humidity, pH, rainfall, and label. This dataset provides the basic infrastructure for our exploration, allowing us to reach several goals. Again, nutrient levels (N, P, and K) being presented separately in the data set acknowledges soil fertility as crucial to crop cultivation. Nitrogen, phosphorus, and potassium are essential major nutrients for plant growth. The accurate determination of these are critical to optimizing fertilizer recommendations that provide sufficient nutrient content in India. The distribution of features as shown in Fig. 3 in order to determine the type of data count per indication. The correlation matrix reflecting the correlation between various features on the dataset was then presented as a correlation heatmap, as seen in Fig. 4.
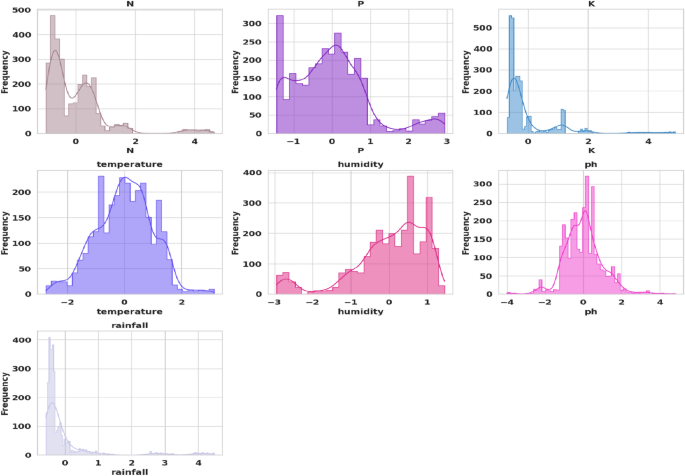
Count per indicator (I1 to I7) in the dataset.
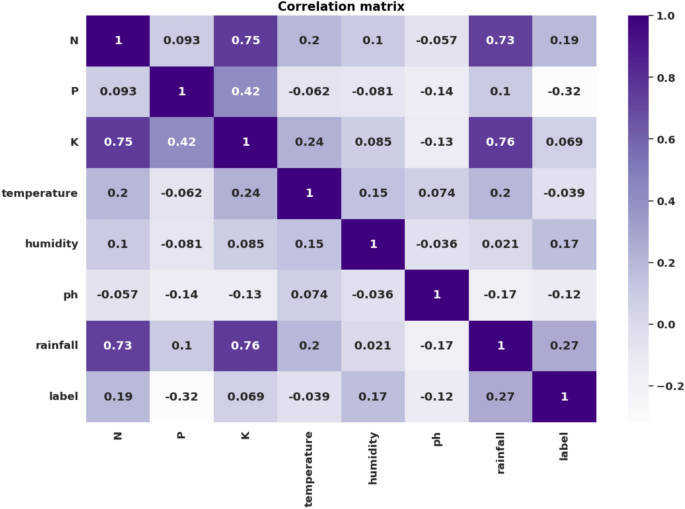
Correlation matrix displaying the relationship between the dataset’s various aspects.
The correlation heatmap analysis offers valuable insights into the relationships among the various features within the dataset. One notable observation is the presence of strong positive correlations, where a few features have a correlation score that is near 1. When one increases, the other follows suit, and when one decreases, the other exhibits a corresponding decrease. Such strong positive correlations are indicative of a direct and often predictable relationship between these features.
Conversely, almost all features in the dataset have very low and negative correlations; the correlation values of most features are around zero or below it. Weak correlations indicate that the features are not linearly related, meaning changes in one do not always mean corresponding changes with another feature. Given that the correlations tend to be negative—that is, as one attribute grows, another seems more likely to shrink-it may lead you inevitably towards questions about trade-offs among these qualities.
Visualization of ease can classify the samples in less than 30 member class labels with our crop recommendation model confusion matrix as shown on Fig. 5. A confusion matrix is an important tool to evaluate the performance of a machine learning model, in particular for classification problems. To further optimize the parameters of a model for better predicting crop recommendations to farmers and other agricultural stakeholders, it is crucial that we have this data. It is a good tool to determine the performance of the model and provide direction towards improving its efficiency in tasks related to crop classification and recommendation. As indicated by attributes of this dataset, the soil N, P, and K levels assume an essential role from a biological viewpoint since they are the principle macronutrients that plants take amid the development stage. In general, these macronutrients have the greatest input into subcategories:
-
N—Nitrogen promotes the growth of plant leaves.
-
P—Phosphorus is mostly needed for the growth of roots, flowers, and fruits.
-
K—Potassium is important for being able to carry out the general functions of a plant properly.
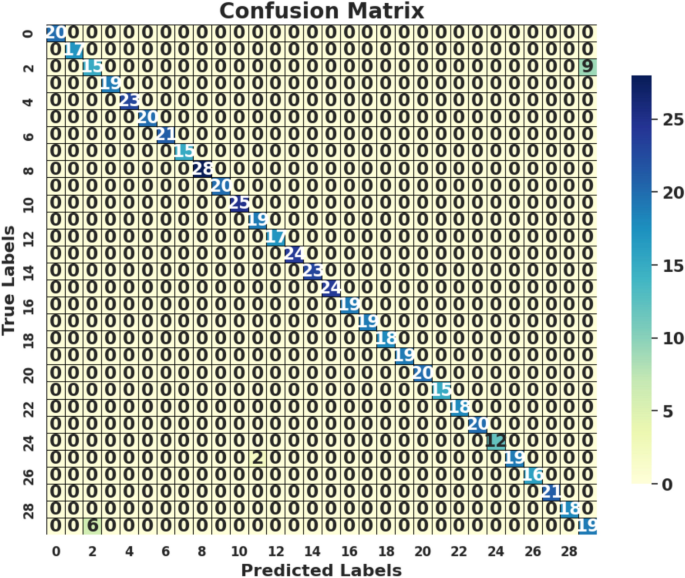
Confusion matrix.
Fertilizer can supply these macronutrients, and different kinds of crops will benefit from it more depending on the N, P, and K concentrations in the fertilizer. In addition, a lot of N, P, and K are required for crops to grow and thrive, and strong, nourished plants bear more fruit. But in the absence of fertilizer, the soil might not contain enough nutrients to encourage healthy growth. By controlling fertilization, farmers may promote optimal plant development and productivity by understanding the NPK ratios that crops require. The nutrients that the soil needs are delivered to the soil through fertilizer. An analysis of the N, P, and K requirements for various crops in our dataset is shown in Fig. 6. Based on our data in the dataset, it is clear that sugarcane, potatoes, and dates require high nitrogen levels, apples and grapes require high phosphorus levels, and sugarcane, dates, apples, grapes, and litchi require high potassium levels in comparison to all other crops.
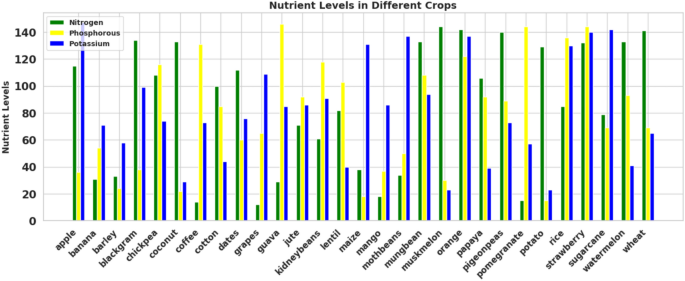
Comparison of NPK requirements of different crops.
Furthermore, environmental factors such as temperature, humidity, pH levels, and rainfall play a significant role in determining crop suitability and performance. These all affect crop impact, disease infection, and yield. The research paper builds on the collection of information relating to these parameters to provide those holistic insights with regards to crop recommendations, ensuring that the climatic and soil conditions were in coherence with one another. The remaining features from this dataset are rainfall, soil pH, air temperature, and air humidity.
The pH of the soil affects the presence of microorganisms, harmful chemicals, and important nutrients. Plants require rainwater to survive on their nature. A plant may require different amounts of water for photosynthesis to occur; the air must be at a certain temperature; when the temperature rises, photosynthesis may also increase; and air humidity is necessary for plant transpiration. For example, when the temperature rises, these characteristics also help determine which crop to harvest. When considered collectively, each of these characteristics is crucial in deciding which crop should be harvested. As the recommended crop type based on the study of all the aforementioned parameters, the ‘label’ column in the dataset is of utmost significance. The final result of the study is this proposal which can help farmers choose the right crops, plant them, and choose the right management techniques. In essence, this comprehensive and multidimensional information is the foundation of the study, allowing for data-driven analyses and suggestions that enable farmers to improve their farming methods, increase crop yields, and promote sustainability in contemporary farming.
Research Objective II: To thoroughly evaluate and compare the effectiveness of machine learning methods for making correct crop recommendations, such as logistic regression, KNN, AdaBoost, and TCRM (proposed model) (Table 4).
Python programming was used to develop a collection of predictive machine learning models in order to fulfill Research Objective II, which calls for a thorough evaluation and comparison of the efficacy of various machine learning algorithms for making correct crop predictions. These are the models that we built with lots of love on top of a large and diverse dataset consisting of parameters like N-P-K nutrient levels, temperature-humidity-pH-rainfall values, along with the important “label” column, which tells us what crop to recommend. For each method, the performance was thoroughly analyzed and benchmarked with respect to several different parameters like scores of F1-score, recall, accuracy, precision, and fivefold cross-validation. The scores obtained for F1, accuracy, precision, recall, and five fold cross-validation are shown in Table 4 for easier comparison.
Figure 7 sheds light on accuracy achieved by various classifiers. The proposed transformative crop recommendation model (TCRM) achieved the highest accuracy among all compared classifiers, reaching an accuracy rate of 94%. This outperformed K-Nearest Neighbors (KNN) and Logistic Regression, which scored 92.84% and 91.16%, respectively. AdaBoost lagged significantly behind with only an 11.50% accuracy rate, indicating that it is less suitable for this application. The high accuracy of TCRM highlights its strength in making precise and reliable predictions tailored to agricultural data.
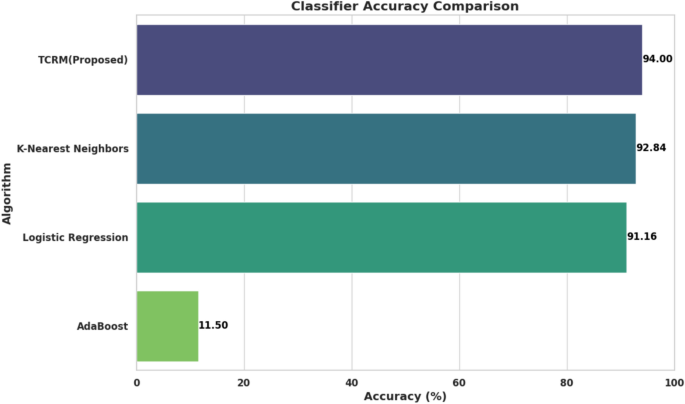
Accuracy comparison of machine learning algorithms.
In terms of precision, which measures the correctness of positive predictions. In Fig. 8, TCRM led with a score of 94.46%. KNN followed closely with a precision of 93.11%, and logistic regression scored 91.44%. AdaBoost demonstrated a much lower precision at 7.92%. The high precision of TCRM indicates its effectiveness in reducing false positives, which is crucial for accurate recommendations in agriculture, minimizing unnecessary or incorrect interventions.
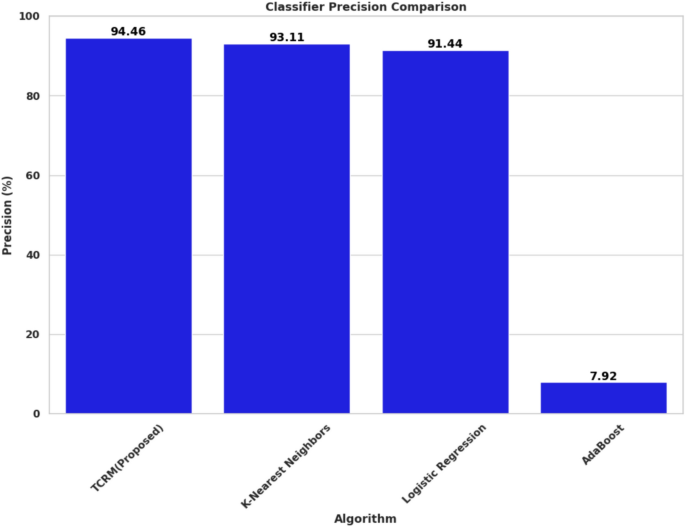
Precision comparison of machine learning algorithms.
Recall measures the model’s ability to identify all relevant instances correctly. Figure 9 represents recall achieved by various classifiers. TCRM excelled with a recall score of 94%, showing its proficiency in capturing true positives. KNN and Logistic Regression performed well with scores of 92.83% and 91.17%, respectively, but AdaBoost fell short with a recall rate of only 11.50%. TCRM’s strong recall makes it particularly effective for ensuring critical cases in agricultural recommendations are not missed.
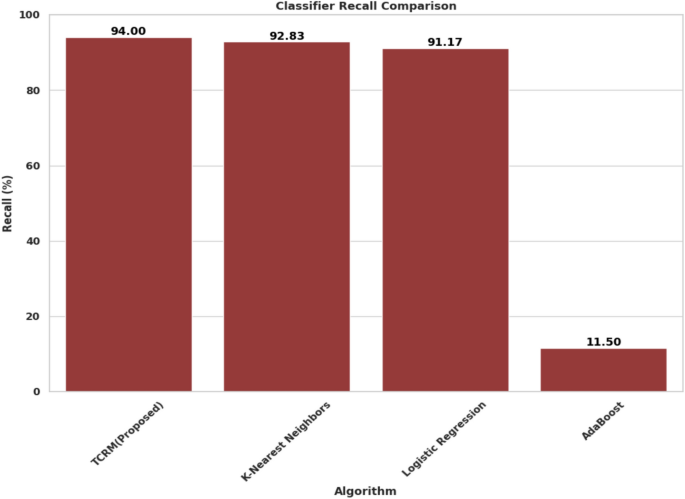
Recall comparison of machine learning algorithms.
For the F1-score, which balances precision and recall. Figure 10 shows TCRM emerged as the top performer with a score of 93.97%. KNN followed with an F1-score of 92.74%, and logistic regression scored 90.99%. The significantly lower F1-score of AdaBoost at 8.45% highlights its poor balance between precision and recall compared to the other models. The superior F1-score of TCRM further emphasizes its consistent reliability and balanced performance.
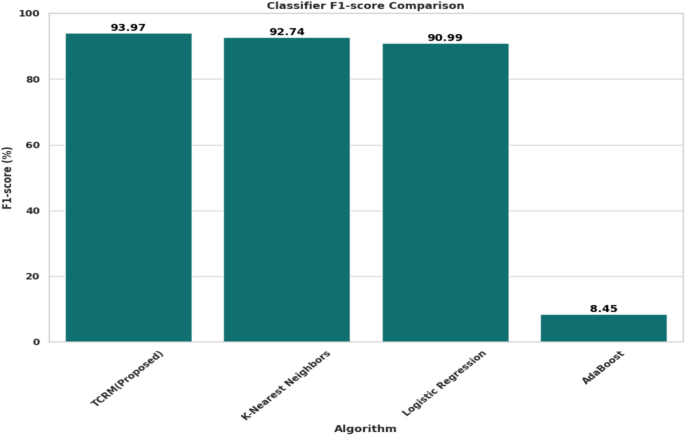
F1-score comparison of machine learning algorithms.
In Fig. 11, a fivefold cross-validation test of TCRM demonstrated its robustness and consistency with a score of 97.67%. This was notably higher than KNN (92.74%) and logistic regression (90.99%), while AdaBoost maintained a low score of 8.45%. The strong performance of TCRM across multiple folds underscores its ability to generalize well and maintain stability when presented with varied data, making it ideal for the dynamic conditions of precision agriculture. TCRM excels in all the parameters used such as accuracy, precision, recall, f1-score, and Cross Validation with fivefold.
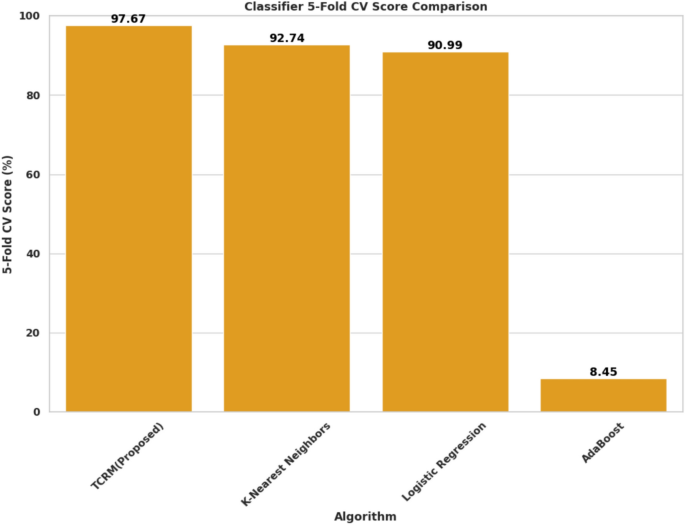
5 fold cross validation comparison of machine learning algorithms.
Research Objective III: To design and construct a cloud-enabled platform for recommending crops to farmers.
This deployment of the TCRM (proposed model) was a significant step in reaching one of the research objectives, Research Objective III to be precise, which involves building and implementing a cloud-based platform for crop recommendation service personnel. This highly sophisticated predictive machine learning model is maintained with a strict curation process to provide accurate and robust crop recommendations. Figure 12 depicts the cloud-hosted crop recommendation interface. In order to provide this technology in an easy-to-access and user-friendly manner, the TCRM (proposed model) was deployed on a cloud architecture (specifically Amazon Web Services (AWS) servers). Because AWS offers a secure and flexible cloud computing environment, it is an ideal platform for web application or model hosting. Figure 13 shows crop and fertilizer recommendations for a given crop displayed in the cloud-based crop recommendation interface. During deployment, the TCRM (proposed model) needed to be exposed as a web API. This especially allows farmers who can feed soil properties, climatic regions, location, etc. via the interface of this API into the system. The deployed TCRM in turn responds with a prediction that can be based on the specifics of this instance to present appropriate crop suggestions, again providing personalized help and solutions.
Crop recommendation interface hosted in the cloud.
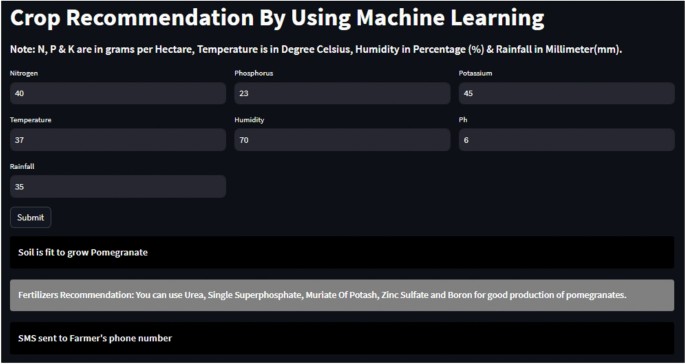
Crop recommendation interface hosted in the cloud with recommendations.
With the hosting platform provided by AWS, it ensures that this research project maintains scalability and availability for more users along with data inputs to be processed in our crop recommender system. That provides farmers with an easy way to use data to make better decisions that will help drive efficiency into agriculture well beyond many other techniques currently in practice today.
Research Objective IV: To integrate SMS alert generation technology and real-time data sources into the platform to facilitate prompt decision-making.
This intends to power the functions of an agriculture platform by integrating live data sources (weather forecasting services) and triggering SMS alerts for real-time assistance in decision-making farm-level suggestions. As an important part of this objective, a system for sending SMS alerts has been added to the platform in order to deliver vital information straight into farmers’ mobile phones. The system is aimed at sending SMS alerts containing crop recommendations and fertilizer recommendations specific to the recommended crop.
Using real-time data sources like weather, soil quality, and other ecosystem factors to identify the optimal crop for that field as per season based on our platform algorithms. It can be made to trigger an SMS alert generation system to farmers about a favorable crop on their land and the type of fertilizer they need for its maximum yield in Fig. 14. This real-time tailored assistance provides farmers with insights that they can act upon, allowing for informed and rapid decision-making to adapt to changing weather phenomena and optimize the productivity and sustainability of their agricultural practices.
SMS sample to farmer showing crop and fertilizer recommendation.
Comparison with the existing work
Table 5 highlights various methodologies, including neural networks, support vector machines, and deep learning architectures like CNNs. The datasets range from satellite imagery and weather data to field-specific soil reports and crop-specific RGB images. The studies show diverse applications, such as soybean yield forecasting, wheat prediction, and soil nutrient classification, with accuracies ranging from 61 to 94%, showcasing the evolution and advancement in precision agriculture methods.
Figure 15 visually compares the accuracy of these studies, emphasizing the performance of the proposed TCRM (Transformative Crop Recommendation Model), which achieved the highest accuracy of 94%. This indicates the robustness of TCRM in providing personalized, data-driven crop recommendations using advanced ML/DL approaches and real-time data integration.
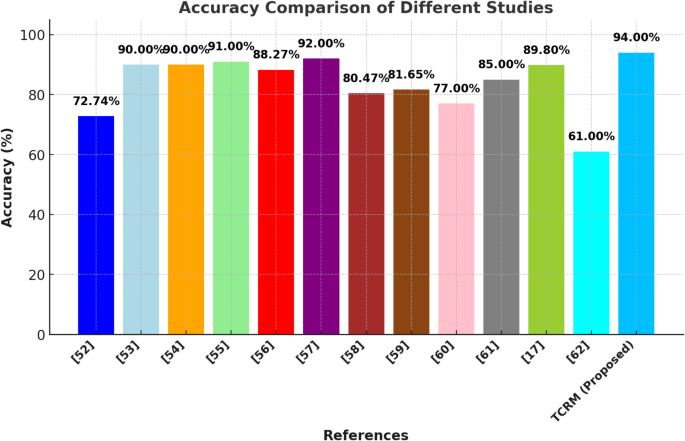
Accuracy comparison of different studies on crop recommendation.
The findings not only validate the efficacy of TCRM but also pave the way for future innovations, as discussed in the concluding section.
Conclusion and future scope
In this work, the Transformative Crop Recommendation Model (TCRM) is presented that combines scientific machine learning and deep learning to provide temporal, context-aware, and scalable crop recommendations in the era of precision agriculture. By deploying the model on a cloud platform and using SMS alerts to notify farmers regarding the content of the data-driven insights, remote farmers can be served with better information for their farming activities. By leveraging multi-head attention mechanisms, tree-based algorithms, and scalable cloud infrastructure. It not only augments predictive power but also helps in connecting traditional agronomy with modern data-driven approaches. By focusing on data preprocessing, normalization, and feature selection. It provides robustness, scalability, and generalizability to different agricultural settings and input data. TCRM embodies the transformative potential of precision agriculture to optimize yield efficiency and food security by emphasizing sustainable agronomy, resource use, and resilience to stressors such as climate change and water limitation. Punjab, India. The Punjab case study demonstrates the ability of TCRM-driven precision agriculture to enhance water and soil health, optimize crop sectors and realize yield potential under resource-constrained conditions.
In the future, TCRM could be improved by developing region-specific models that include climate, soil, and crop data on a local scale in order to increase its prediction abilities and relevance for different agricultural contexts. Using IoT-based monitoring devices to collect real-time data can be implemented as an extension for accurate and timely recommendations. The addition of proper sustainability measures, including but not limited to measures on water use, carbon footprint, and resource efficiency, will complement the broadband delivery of environmentally friendly farm practices. Multilingual interfaces and mobile applications can make the platform easier to use for farmers in multiple demographics. Utilization of state-of-the-art data augmentation strategies and steady updates to the model will enable TCRM to be proactive with respect to emerging trends and challenges in agriculture. A feedback loop where farmers can provide feedback on suggestions would refine the model even more, making it smarter and more human-centric. Working with public officials, researchers, and extension services can help ensure the expansion and fine-tuning of TCRM for widespread impact. The model can also be fortified by looking at new technologies such as blockchain for secure data sharing and AI-based disease prediction models, ensuring it remains an invaluable instrument based on data to potentially revolutionize agriculture, improve food security, and promote sustainable farming globally. Future work could integrate explainability techniques like SHAP and LIME to make crop recommendation models more transparent. These methods provide insights into feature influence, fostering trust and informed decision-making among agricultural stakeholders.
Responses