Enhancing yeast cell tracking with a time-symmetric deep learning approach

Introduction
For several decades, tracking of solid objects in video recordings has been a partially solved problem. Classical image processing-based pattern matching approaches, such as scale-invariant feature transform (SIFT)1 combined with random sample consensus (RANSAC)2, have the potential to track objects with fixed shapes invariantly to shift, scale, rotation, and partially to lighting conditions. Furthermore, the extension of such methods with variants of the Kalman filter3,4 can introduce object velocity or other degrees of freedom into the estimation, which can substantially reduce the position estimation noise, particularly when the introduced additional parameters tend to be continuous. However, these methods base their estimation on prior assumptions, which greatly reduces their capabilities when the assumptions do not hold true. These limitations are especially apparent in live cell tracking on videomicroscopy recordings, as cells tend to change shape and morphological description rapidly, unpredictably, and in a highly nonlinear manner. Additionally, cells can grow and divide with time, have no real velocity, and often exhibit unpredictable behavior as a living, non-rigid object. Furthermore, cells on the same recordings tend to be very similar, making the task even more challenging. Therefore, the most promising solution to address these issues is using machine learning, where the feature importances and other estimates are learned by the model and depend mainly on the distribution of the training dataset.
In recent years, several cell tracking software and libraries have switched to machine-learning-based solutions, mainly utilizing convolutional neural networks (CNNs), as they generally perform well on image processing tasks. Some of these tools, such as CellTracker5, Usiigaci6, and YeaZ7, separate segmentation and tracking and use deep learning only for high-quality segmentation. However, they use classical methods, such as the Kalman filter, bipartite graph matching, or other methods for tracking, which ultimately rely on a rigid metric system. In contrast, other tools, such as CellTrack R-CNN8, and Ilastik9, adopt deep learning or other forms of machine learning for tracking either in an end-to-end manner or as a separate segmentation followed by tracking. This approach shows advantages both theoretically and empirically, as demonstrated by the often superior performance of machine learning-based and other data-driven methods when a sufficient amount of training data is available10,11. However, to the best of our knowledge, all of these tools rely on a frame-by-frame identity-matching approach, utilizing only consecutive frames for tracking. This approach is a major simplification and disregards a large amount of useful information that could be present in the temporal neighborhood of the given video frames.
Therefore, we developed a complete tracking pipeline that separates segmentation and tracking because end-to-end training with our method was unfeasible. Our method uses deep learning for both stages, utilizing the temporal neighborhood of consecutive frames for prediction, which enables skipping of frames up to the size of the temporal neighborhood, making the tracking substantially more robust. The pipeline uses metrics only between different predictions for the same cell on the same frame, minimizing the introduction of methodical assumptions via the choice of the similarity metric. The most similar method in the literature that we know of is DeepTrack12, which was recently developed for tracking cars. However, while this method utilizes the local temporal neighborhood via encoding objects using temporal convolutional networks (TCNs), the network architecture and the metric system for object matching are substantially different, making our solution architecturally novel.
Results
For evaluation purposes, we opted to calculate F-scores based on binary decisions of correctness for segmentation and tracking, instead of utilizing continuous regression metrics. This approach offers a clear numerical evaluation of the capabilities of the compared tools and tool versions. F-scores for segmentation were computed using Intersection over Union (IoU), with a minimum similarity threshold of 0.5. We selected this threshold as it is strict enough to assess the accuracy of correct cell detection while disregarding minor segmentation discrepancies that hold minimal biological significance. In the case of tracking evaluation, F-scores were also calculated based on the segmentation IoU, with the additional inclusion of ID matching. True positive values, also referred to as “links” were registered if the segmentations matched on the same frame and the IDs matched consecutively for both the prediction and the ground truth. This tracking evaluation method of link matching is described in the work of M. Primet (2011)13.
Yeast data source
The training and validation data used to generate the primary results in this paper are videos of budding yeast cells dividing in a microfluidic device. Cells are S. Cerevisiae wild-type-like, with W303 genetic background. Yeast is a unicellular eukaryote, which shares many essential genes and phenotypes with multi-cellular eukaryotes, such as mammals. On the other hand, its relatively small genome (~12 × 106 base pairs), short doubling time, and easy genetic tools allow it to perform experiments in a short time and with limited costs. Such experiments would be very costly or even impossible to do in higher eukaryotes. Not surprisingly, many discoveries performed in higher eukaryotes were inspired by original studies performed in yeast.
In the experiments, cells were grown overnight at 30 °C in a complete YPD medium and synchronized by the use of the pheromone α-factor. Imaging started when they were released from this stimulus. Cells were free to grow and duplicate, trapped in the microfluidic device to prevent them from moving in the field of view. Images were acquired every 3 min for 3.5 h using a DeltaVision Elite imaging system equipped with a phase-contrast objective. The field of view is a square of 111.1 μm size, resulting in 512 × 512 pixel images. The duration of the cell-cycle of the analyzed cells is ~1.5 h, while their size is ~5 μm.
The segmentation and tracking models were trained on a dataset comprising 314 movies, and for validation purposes during model design, 35 additional movies were used. These movies were acquired using the same microscope, objective, and image size but with varying durations and time-lapses. On average, each movie contained 35.8 frames and 20.2 individual cells to be tracked. The ground truth labels were initially generated using Phylocell14 in a semi-automated, semi-manual manner. They were then manually corrected and curated by multiple experts, who removed incorrect segmentations (such as dead cells, segmentations of empty space, and multiple segmentations per cell) and corrected cell tracking. The training and validation sample numbers of the segmentation model were independent of model parameters, while for the tracking model, the model parameter tracking range (TR) substantially influenced the number of available samples, as shown in Table 1. Further details on the model parameter TR will be discussed in the section “Tracking”. For final testing and evaluation of the tools and model parameters, 5 additional independent recordings were used, containing a total of 4629 identified cell instances.
Comparative datasets definition
While our architecture was initially designed for the segmentation and tracking of yeast cells, we also claim that it is capable of generalization to diverse data types, including those featuring faster-moving objects, given an adequate amount of training data. Additionally, in contrast to numerous other methods, our tracking architecture seamlessly integrates both morphological and kinematic information, making it entirely data-driven and retrainable without requiring any substantial architectural changes.
To support these claims, we aimed to train and evaluate it using microscopic recordings of other cell types. However, we found that such data is not readily available in the required quantity and quality. Our architecture demands extensive training data due to its size and complexity, as a trade-off for tracking quality and stability, which poses a challenge compared to simpler tracking solutions. For instance, the Cell Tracking Challenge15 or the CTMC-v1 dataset16 could have been suitable for evaluation purposes. However, they lack the necessary intra-class variance required for the successful training of complex models without severe overfitting of the training data. This issue was also noted in the publication of Toubal et al. (2023)17.
To address this issue, we synthetically created multiple toy datasets comprising objects with various morphological and motility patterns. To introduce a level of difficulty and realism to the tracking tasks, each simulated recording includes a randomized background composed of 10 Gaussian density functions, with a maximum relative brightness level of 0.39, and a similar framewise-random noise with a maximum relative brightness level of 0.078.
Synthetic arrows
The objects designated for tracking are triangular arrows, with a maximum size difference ratio of 6, an average speed equivalent to 40% of the mean object size, uncorrelated with the size of the individual object, allowing for speeds even greater than the object size. Additionally, these objects have a maximum angular rotation of 10∘ for each frame, allowing for object crossing and, thus, the occlusion, and random uniform grayscale values exceeding a brightness level of 0.39. Furthermore, the objects may also expand from one frame to the next by 1.6–10.0% of their original size, with a probability of 0.33 at each time step. The average density of objects in this scenario is ~11.39 per frame.
Synthetic Amoeboids
This object-tracking task is similar to ”Synthetic Arrows”. However, the objects to be tracked are more complex amoeboids with semi-random initial shapes and shape changes from one frame to the next. Both the initial shapes of these objects and the iterative shape changes are generated using Perlin noise18 in a 50-point polar coordinate system with an octave value of 6, a persistence value of 0.5, and a lacunarity value of 2.0. Furthermore, the shape changes are governed in a Gaussian manner based on the distance from the object centroid to avoid complete filling of the object space or the disappearance of an object due to random chance. This approach creates amoeboid-like objects with randomized boundaries allowing for highly concave contours and even the short-term splitting of an object in extreme cases. Additionally, while the individual shape changes are gradual from one frame to the next, the objects can be nearly unrecognizable over larger temporal distances. Lastly, unlike the ”Synthetic Arrows”, the objects perform perfectly rigid collisions with no velocity loss, making occlusion impossible. The main reason for this choice is that the following other datasets featuring synthetic amoeboids would require a realistic simulation of occluded object light transference, which would be mandatory but exceedingly challenging if object occlusions were allowed. Furthermore, object occlusions are generally less important in microscopy compared to macroscopic cameras, due to the focal plane specificity of microscopes. The average density of objects in this scenario is ~9.18 per frame.
Synthetic Amoeboids-PC
The aim of this dataset is to simulate object tracking on phase contrast microscopy recordings with objects displaying substantially different morphological and motion characteristics compared to yeast cells. The behavior of the objects in this dataset is identical to that of “Synthetic Amoeboids”. However, instead of displaying objects with uniform grayscale color, the Canny edge detector19 is applied to the binary object mask, followed by a Gaussian blur with a large kernel size of 51 pixels, mimicking phase contrast microscopy visual characteristics in a simplistic manner. The average density of objects in this scenario is ~8.87 per frame.
Synthetic Amoeboids-PCC
The objects in this dataset behave similarly to those in “Synthetic Amoeboids-PC”, with the only notable difference being that the objects undergo non-rigid collisions, resulting in a 10% velocity loss for each collision involving both objects. This seemingly minor change leads to the clumping of objects, making the tracking task simultaneously easier and more challenging. Object identification and segmentation become substantially more difficult due to the clumping, while the reduced momentum simplifies assignment. Additionally, a small force is applied to each object towards the center of the field of view. Although this force does not visibly alter object motility, it ensures that the object clump is likely to form within the field of view. The average density of objects in this scenario is ~20.27 per frame, much higher than in the previously discussed scenarios, as expected.
Synthetic Amoeboids-PCCA
This dataset does not exhibit any differences in terms of object behavior compared to “Synthetic Amoeboids-PCC”. Instead, each recording is augmented with a highly disruptive artifact, which poses challenges for both object detection and tracking, even for the human eye. These artifacts consist of 100 white lines placed in a uniform random manner between the edges of the field of view, obscuring both the objects and the background. The artifact patterns generated in this way are static but unique to each recording, rendering it impossible for models to learn their positions. The average density of objects in this scenario is ~21.18 per frame, similarly high as in the case of “Synthetic Amoeboids-PCC”.
Comparative tool evaluation
For comparative evaluation, we selected Phylocell14,20 and YeaZ21 as the two other cell tracking tools. The reason behind this choice was that the ground truth training and testing data were generated using Phylocell and were later manually corrected by experts. On the other hand, YeaZ provides a fair comparison to our solution as it employs a similar segmentation pipeline and a somewhat comparable tracking pipeline, utilizing the Hungarian method22. As the ground truth data excludes cells that eventually leave the microscope’s field of view throughout the recording (from now on referred to as “border tracks”), we conducted two evaluation scenarios for the tools. In one scenario, border tracks were removed in post-processing from all predictions to ensure an unbiased comparison, while in the other scenario, the prediction results were left unaltered.
The segmentation and tracking F-measure results are depicted in Fig. 1. It is evident that our solution substantially surpasses both other tools in terms of segmentation and tracking quality, particularly in the more equitable scenario where the border tracks were eliminated. In the unaltered prediction case, the performance of Phylocell remained comparable to its prior results since the tool already automatically removes most border tracks. Conversely, YeaZ and our solution exhibited notably lower performance due to domain discrepancy between the predictions and ground truth data. Nevertheless, even in this case, our solution outperformed Phylocell in terms of expected F-score values, although with a substantially higher degree of variance on the lower side.

Comparative evaluation of segmentation and tracking performances of Phylocell, YeaZ, and our pipeline based on F-measures of segmentation IoU and tracking link matches with enabled and disabled border track predictions. Disabled border tracks present an unbiased comparison between the tools, while enabled border tracks show results with unaltered outputs. The evaluation was conducted on the final test subset of the yeast dataset described in the section “Yeast data source”, containing 4629 identified cell instances. The whiskers represent the minimum and maximum values, the lower and upper box boundaries indicate the first and third quartiles, the middle line shows the median value, and outliers are depicted as white circles.
These results indicate the effectiveness of our method but also suggest a strong connection between segmentation and tracking quality due to the apparent correlation between metric results. To investigate further, we used Phylocell instance segmentation inputs for our tracker. In this case, the mean tracking F-score of our method was 0.868 ± 0.015, showing a negligible difference compared to the tracking F-score of Phylocell at 0.878 ± 0.02. While our tracking method did not surpass the performance of Phylocell on the measured samples, this may be attributed to a highly non-uniform segmentation error distribution of Phylocell, which leads to certain track predictions being mostly incorrect while others are mostly correct. Although our tracker is theoretically capable of correcting sparse errors in mostly correct tracks, it is unable to rectify tracks composed predominantly of faulty or missing instance predictions. To verify this, we conducted an experiment detailed in the section “Tracking robustness”, introducing segmentation errors in a more uniform manner.
Hyperparameter dependencies
The parameters we considered to have a major impact on tracking performance for both local and global tracking are the local tracking range, the complexity of the local tracker model backbone, and the metric used for global consensus. For a more detailed description of these parameters and their functions in the architecture, please refer to the section “Tracking”.
The differences in tracking F-scores resulting from these parameters are presented in Fig. 2. Somewhat surprisingly, we observed minimal differences in performance based on the local tracking range and model complexity. Furthermore, smaller local tracking ranges exhibited marginally better performance, suggesting that the benefits of larger tracking kernels were outweighed by the increased model complexity, which slightly hindered training. On the other hand, these results also indicate that lightweight models with smaller local tracking ranges and simpler backbones are suitable for tracking predictions, resulting in substantially shorter inference times. As an additional benefit, while performing inference without GPU acceleration remains slower by orders of magnitude, it is more reasonable with such lightweight models, making initial pipeline testing more accessible. As anticipated, the use of IoU as the metric for global consensus substantially outperformed Euclidean distance, underscoring the importance of incorporating cell morphology in short-term tracking.
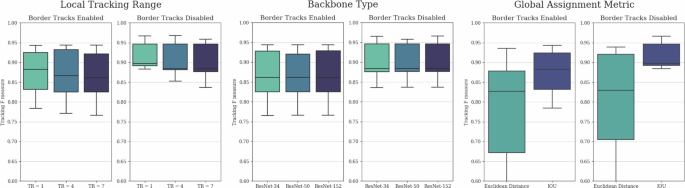
Comparative evaluation of tracking F-scores in the function of local tracking ranges, backbone model complexities, and global consensus metrics with enabled and disabled border track predictions. Disabled border tracks present an unbiased comparison between the parameters, while enabled border tracks show results with unaltered outputs. The evaluation was conducted on the final test subset of the yeast dataset described in the section “Yeast data source”, containing 4629 identified cell instances. The whiskers represent the minimum and maximum values, the lower and upper box boundaries indicate the first and third quartiles, the middle line shows the median value, and outliers are depicted as white circles.
Tracking robustness
To comprehensively demonstrate the tracking stabilization and segmentation interpolation capabilities of our architecture, and to show that tracking quality is not solely reliant on initial instance segmentation quality, we conducted an ablation study. In this study, we removed every 1:15 (Noise 1:15) and 1:5 (Noise 1:5) segmentation instances in a uniform random manner before tracking. Furthermore, to showcase the potential advantage of longer local tracking ranges, we created a scenario where segmentation instances were removed in 7-frame-long blocks, with these elimination blocks also positioned in a uniform random manner with a 1:5 average chance of segmentation instance elimination (Box Noise 1:5). This box noise scenario presents a different but equally realistic challenge compared to the fully uniform noises, as in various applications, objects can disappear for several frames due to occlusion and limited field of view.
The applied noises substantially impacted both segmentation and tracking outcomes, as segmentation instances were removed and the previously continuous tracks were broken up. Therefore, it was the task of the tracker module to create continuous tracks despite the missing segmentation instances and to interpolate the removed instances as effectively as possible. The resulting F scores before and after re-tracking are presented in Fig. 3 for Noise 1:15 and Noise 1:5, with the thus far best performing local tracking range of 1. For Box Noise 1:5, we measured the performance of the architecture for local tracking ranges of 1, 4, and 7. These F scores are presented in Fig. 4.
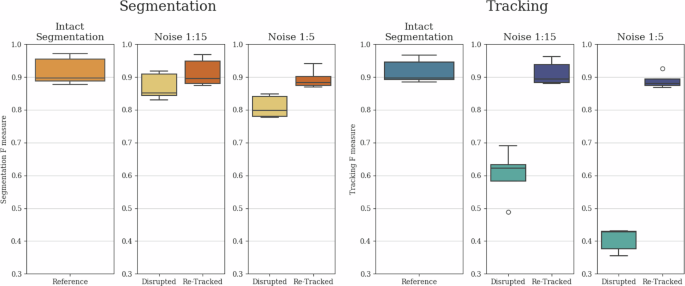
Comparative evaluation of segmentation and tracking F-scores for Intact, Noise 1:15, and Noise 1:5 cases. Both segmentation and tracking results include baseline values disrupted by the given noise, as well as re-tracked values initiated with the disrupted segmentation. The evaluation was conducted on the final test subset of the yeast dataset described in the section “Yeast data source”, containing 4629 identified cell instances. The whiskers represent the minimum and maximum values, the lower and upper box boundaries indicate the first and third quartiles, the middle line shows the median value, and outliers are depicted as white circles.
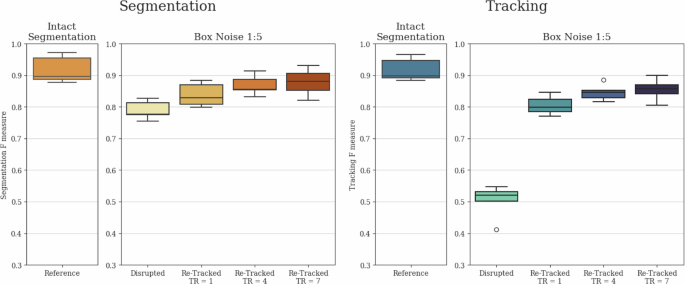
Comparative evaluation of segmentation and tracking F-scores for Intact and Box Noise 1:5 cases. Both segmentation and tracking results include baseline values disrupted by the noise, as well as re-tracked values initiated with the disrupted segmentation using local tracking ranges (TR) of 1, 4, and 7. The evaluation was conducted on the final test subset of the yeast dataset described in the section “Yeast data source”, containing 4629 identified cell instances. The whiskers represent the minimum and maximum values, the lower and upper box boundaries indicate the first and third quartiles, the middle line shows the median value, and outliers are depicted as white circles.
The results reveal that for all examined noises, both the segmentation and tracking F scores showed substantial improvement compared to the disrupted tracks due to the interpolated segmentation instances and the reconnected tracks. Furthermore, in the case of Box Noise 1:5, the longer local tracking ranges were preferred, as they provided better coverage for the continuously missing segmented instances. These findings clearly demonstrate that while there is a substantial correspondence between instance segmentation and tracking results, both modules of our method strongly support each other, leading to simultaneous improvements in both, thus contributing to the observable correspondence.
Moreover, during this experiment, we observed a substantially greater influence of tracking parameters compared to previous trials. Specifically, the accuracy of the segmentation confidence threshold of the tracking model and the minimal similarity threshold of the global assignment step became notably more crucial, particularly in scenarios of reduced instance segmentation quality. This was especially evident with more complex models featuring larger local tracking ranges. An illustration of this relationship is depicted in Fig. 5 for Noise 1:15. While this observation might imply that extensive and costly hyperparameter tuning is necessary for the tracker module in case of lower-quality instance segmentation results, in practice, these parameters can be readily and efficiently adjusted based on visual assessment of segmentation quality of the local tracker model and a global tracking sanity check on only a few consecutive frames. Conversely, the heightened significance of the accuracy of these parameters further underscores that while tracking may be straightforward in cases of good-quality instance segmentation, achievable by nearly any model, in scenarios of poorer-quality instance segmentation, a well-designed tracking architecture can play a pivotal role, substantially impacting both segmentation and tracking quality.
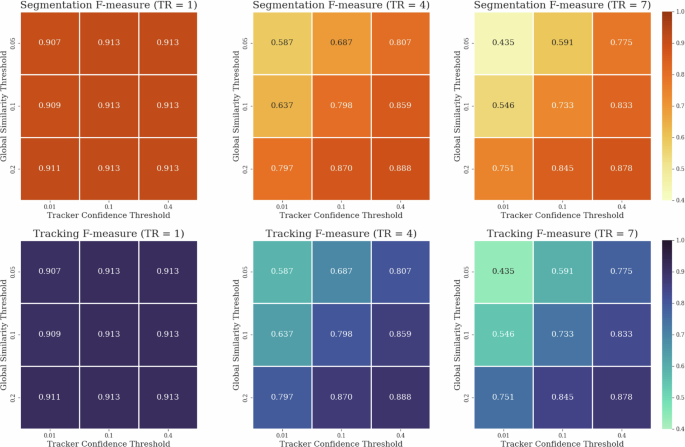
Illustration of the interdependence of hyperparameters: segmentation confidence threshold of the tracker model and minimal similarity threshold of the global assignment as a function of local tracking range (TR).
Comparative datasets evaluation
Using the five synthetic datasets described in the section “Comparative datasets definition”, our yeast tracking architecture was trained on 80 synthesized videos for each type, each comprising 100 frames, and subsequently evaluated on 20 videos. The only modification applied to the architecture was the utilization of bounding box marking instead of centroid marking for the tracked objects. This adjustment was necessary due to the potential intersection of object paths and, thus, the possibility of occlusion, rendering centroid marking ambiguous in certain scenarios. The chosen TR value for each training was 4, as it provides a good balance between missing instance interpolation and prediction quality. The resulting segmentation and tracking F scores are displayed in Table 2, while sample prediction results are displayed in Fig. 6 with raw inputs for the given samples displayed in Fig. 7. These sample displays were chosen in an unbiased manner by always selecting the first training sample, regardless of prediction quality. However, the frames chosen for display were selected to best showcase the differences between the datasets.
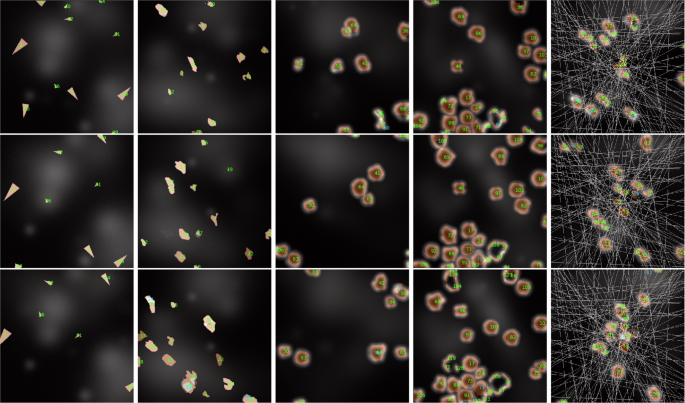
A display of segmentation and tracking results on various synthetic datasets with highly different object behaviors, ordered from left to right as ”S. Arrows,” ”S. Amoeboids,” ”S. Amoeboids-PC,” ”S. Amoeboids-PCC,” and ”S. Amoeboids-PCCA.” The displayed consecutive images are only 4 frames apart to show understandable results, even in cases of extremely fast-moving objects.
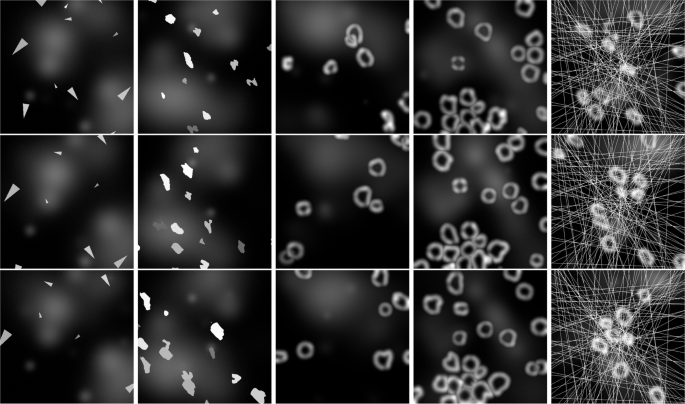
A display of raw input samples on various synthetic datasets with highly different object behaviors, ordered from left to right as ”S. Arrows,” ”S. Amoeboids,” ”S. Amoeboids-PC,” ”S. Amoeboids-PCC,” and ”S. Amoeboids-PCCA.” The displayed consecutive images are only 4 frames apart to show understandable results, even in cases of extremely fast-moving objects.
These results clearly display the difficulty difference between objects with more predictable behaviors, such as yeast cells or synthetic arrows, and comparatively more challenging and unstable objects, such as the synthetic amoeboid versions. While the numerical results for amoeboids are lower compared to those for yeast cells or synthetic arrows, they are still acceptable, given the difficulty of the tasks. The errors mostly arise from instance segmentation, as tracking F scores are never substantially lower than the segmentation F scores. The empirical assessment also shows that the predictions are mostly correct and would serve as a valuable baseline for later manual corrections if necessary. Furthermore, these results could be substantially improved through specialized augmentation techniques, hyperparameter tuning, using more complex backbone architectures for feature extraction, and increased training data. Therefore, based on our assessment, these results demonstrate the adaptability of our architecture in various object-tracking scenarios with vastly different object morphologies and behaviors. However, they also highlight the different training requirements and expectations for different datasets. A more detailed analysis of this aspect is described in the section “Data requirement analysis”.
Data requirement analysis
The training of neural network-based prediction models always requires a varied set of training samples, ideally covering all possible scenarios that may arise during inference. Furthermore, the number of sample points should be high enough to minimize dataset-specific learning, commonly referred to as overfitting to the training dataset. While both sample variety and the avoidance of overfitting can be improved through artificial data augmentation and other generalization techniques, there is a highly task-dependent limit for the minimal required amount of training data. Assessing this limit numerically before initial training and evaluation can be very challenging or nearly impossible. Thus, we provide example evaluation results using training sets with varying sample numbers as potential guidelines on the yeast tracking dataset, as well as the synthetic datasets described in the section “Comparative datasets definition”. The results using randomly selected subsets of the original dataset for the training of both instance segmentation and local tracking models are presented in Fig. 8. For the proper interpretation of these results, it must be noted that individual model training can vary to a certain degree due to the stochastic nature of the training process, which is especially true for datasets with lower sample sizes. Nevertheless, some clear patterns are still noticeable. Based on these, it appears that yeast cells are by far the easiest of these objects to segment and track, as only 2% of the 314, ~35.8-frame-long videos can lead to nearly identical results as training on the full dataset. Conversely, the various examined synthetic datasets showed varied results, clearly displaying how challenging the unique features of the given dataset are.
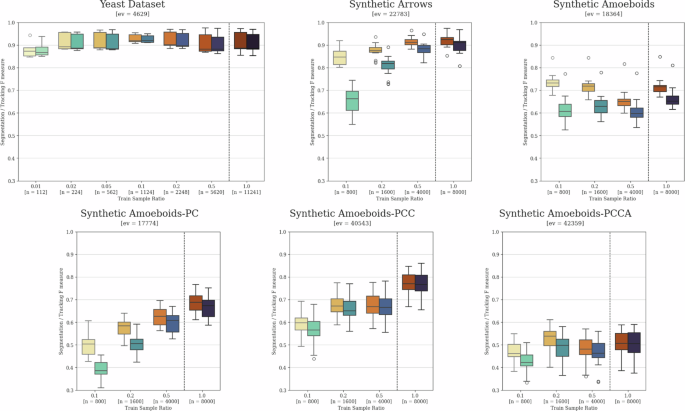
A comparison of training data requirements and the impact of reduced sample sizes on yeast cell tracking and various synthetic datasets. The left boxes show segmentation F scores, while the right boxes show tracking F scores for each individually trained model pair. The dashed lines separate results obtained using the full training set reference models from those trained on randomly selected subsets. The x-axis upper number indicates the relative training set size ratio, while “n” represents the number of images in each set. The “ev” value denotes the number of object instances in each evaluation dataset contributing to the results. The whiskers show the minimum and maximum values, the lower and upper box boundaries indicate the first and third quartiles, the middle line represents the median value, and outliers are depicted as white circles.
Discussion
To display the capabilities and characteristics of our architecture, we performed a comparative evaluation against other tools specifically designed for budding yeast cell segmentation and tracking. Additionally, we analyzed the hyperparameter sensitivity of our architecture. We also measured the reconstructive capabilities of the tracker module in cases of lower-quality segmentation to demonstrate the robustness of the architecture as a whole. Furthermore, we evaluated the architecture on various synthetic datasets to display its retrainability and to provide guidelines for the difficulty of particular visual and motility patterns. Finally, we analyzed the training data requirements of the architecture on the available natural and synthetic datasets to aid potential future applications that require the retraining of the models.
Our architecture demonstrated outstanding state-of-the-art performance compared to other evaluated yeast segmentation and tracking tools in terms of both instance segmentation and tracking results, substantially outperforming Phylocell and YeaZ. Remarkably, our architecture even outperformed Phylocell in the scenario where border tracks were not removed, a condition that is biased towards Phylocell.
The results of the hyperparameter dependency analysis of our architecture indicate that shorter local tracking ranges are slightly preferred if segmentation results are stable, as training less complex models is easier in terms of data intensity. However, as the tracking robustness analysis shows, longer local tracking ranges are preferred if the detection or segmentation of objects is imperfect, especially if objects are lost for multiple consecutive frames. In more difficult datasets, such scenarios can easily occur naturally due to object occlusion and various visual artifacts. It should be noted that, according to our results, the acceptance threshold values of the tracking architecture must be tuned more precisely for larger local tracking ranges.
Furthermore, the hyperparameter dependency analysis reveals that the low-complexity encoding backbones of the local tracker model are sufficient for tracking yeast cells, making the model lightweight in terms of computational requirements, although GPU-accelerated inference is still highly recommended. Additionally, the analysis of the global assignment step shows that Intersection over Union (IoU) is the preferred metric for prediction similarity-based local track matching.
Lastly, the analysis of performance on synthetic datasets, as well as the analysis of training data requirements on both synthetic and yeast datasets, showcases the general versatility of the architecture if a sufficient amount of annotated training data is available. As our architecture contains re-trainable models as predictors, these results show promise for applying the same architecture for other cell types after retraining on appropriate data. The results also indicate that all the analyzed synthetic sets are more challenging than yeast cells, but mostly valid predictions are still achievable on most of them with comparatively larger amounts of training data. Furthermore, we believe that while the analyzed synthetic sets differ from reality in many aspects, their characteristic features and the associated training data requirements and metric results can serve as a guide for the retraining of the models in terms of data requirements and performance expectations.
Methods
Instance segmentation
In the case of tracking pipelines not trained in an end-to-end manner, segmentation is commonly employed as a preliminary stage before tracking. The reason is that the detection of the objects is mandatory for tracking, and detection via segmentation can provide essential information about the objects present, simplifying and improving the manageability of the tracking task. In the context of cell tracking, high-quality segmentation of cells is also important from a biological perspective as it offers valuable information regarding the size and shape of cells, as well as serves as a quality check for the tracking process.
From both the target and solution architecture perspectives, segmentation can be classified into semantic segmentation and instance segmentation. In the realm of CNN-based image processing, semantic segmentation is typically considered the easier task and can be accomplished using relatively simpler network architectures like SegNet23, U-Net24, and others. However, accurately separating objects of the same category after semantic segmentation can be highly challenging and may necessitate the utilization of classical image processing methods, which we previously discussed as being less desirable. On the other hand, recent advancements in deep learning, particularly the introduction of Mask R-CNN-like architectures25, have made it possible to achieve instance segmentation solely based on deep learning techniques. Although these architectures tend to be more complex and rigid due to the combination of convolutional, fully connected, and potentially other network connection types, they are highly valuable when it is essential to separate instances of objects belonging to the same category.
In our approach, we employ a distinct step of Mask R-CNN-based instance segmentation prior to tracking, grounded in the previously described arguments. This step serves two purposes: to provide accurate segmentation results and to serve as initialization for the tracker. As high-quality environments are publicly available for Mask R-CNN architecture training, instead of focusing on developing a novel architecture, we trained an instance segmentation model using the Detectron226 environment. To improve the performance and robustness of the model, we employed multiple data augmentation techniques during the training process.
The specific model we chose was a Mask R-CNN architecture with ResNet-50 feature pyramid backbone pretrained on the COCO instance segmentation dataset27 with 128 ROI heads for the single ”cell” object type. The model was trained through 120,000 iterations with a base learning rate of 0.0025, minibatch size of 4 and otherwise the default parameters of the Detectron2 environment. For artificial data augmentation, we employed various transformation options provided by the Detectron2 environment and the Albumentations library28. The chosen transformations and their respective parameters are summarized in Table 3. The transformations and their parameters were determined in a qualitative manner to ensure that the resulting outcomes closely resemble biologically plausible samples while maximizing variance. However, conducting an extensive data-specific parameter search could potentially yield even better results.
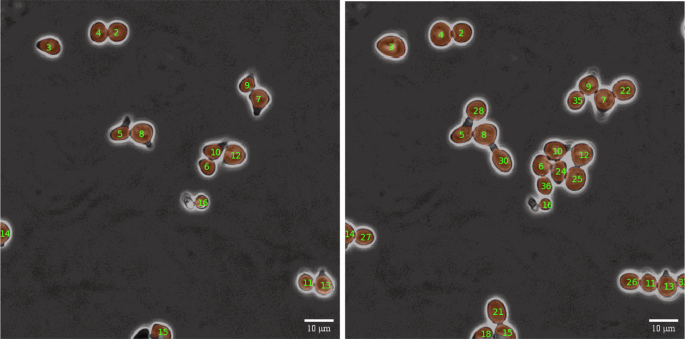
The trained instance segmentation model showed exceptional performance in both object detection and shape recognition. Therefore, we decided to not only use its results as inputs for the subsequent tracking method in the pipeline but also utilize them as the final segmentation output. This decision was made in contrast to the option of using segmentation estimates of the tracking method. Examples of such instance segmentation results can be seen in Fig. 9. Using these initial instance segmentation predictions as segmentation instances in tracking effectively combines the strengths of both stages of the pipeline: the segmentator module produces more accurate segmentations, while the tracker connects them.
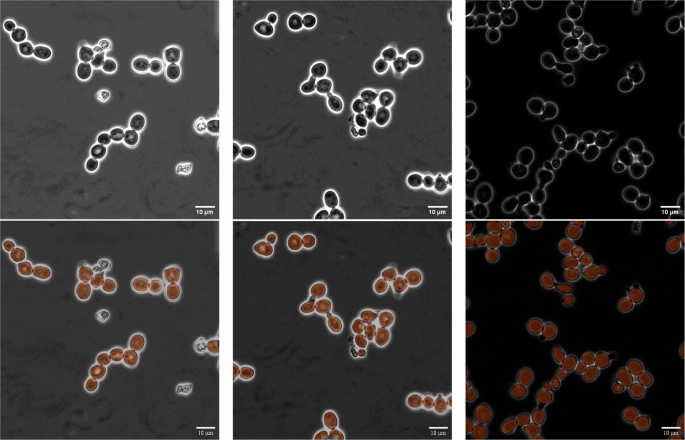
A showcase of robust segmentation results, depicting accurate cell detection and segmentation under varying lighting conditions, while effectively avoiding detection of obviously dead cells. The upper row displays the raw input samples, while the lower row shows the predicted segmentation instances overlaid.
Tracking
While deep-learning-based segmentation has gained popularity in modern cell tracking software, tracking often relies on comparing consecutive frames using metrics like Euclidean distance or Intersection over Union (IoU). In contrast, more advanced but still rigid methods, such as variants of the Kalman filter, consider motility patterns along with position and shape for tracking. Following such frame-to-frame similarity measures, various techniques, including variants of the Hungarian method22 can be employed for optimal assignment without repetition.
However, these methods are sensitive to several hyper-parameters, artifacts, and unusual cases. Even with perfect segmentation and correct assignment, frame-to-frame metrics are not expected to yield a perfect match unless the object moves in a completely predictable way, with the estimable process and measurement noises4. This sensitivity arises due to the movement, speed, shape changes, and other descriptors of the object, as well as environmental factors such as lighting conditions. Consequently, manual fine-tuning of parameters on a per-recording basis, or even adopting different parameters within a single record, is often necessary.
Machine-learning-based techniques offer an alternative to address these challenges, as they can learn the movement patterns of the tracked object and adapt to environmental changes when provided with diverse training data. Artificial data augmentation can also be used to enhance data variety or simulate specific anomalies. However, in popular cell tracking software, these solutions are usually implemented on a frame-to-frame level, potentially leading to sensitivity to unexpected temporally local anomalies, such as changes in lighting conditions or administration of drugs that alter cell movement patterns or morphology.
Instead, we propose a novel multi-frame-based assignment method that predicts the position of a marked cell on several consecutive frames using a state-of-the-art semantic segmentation architecture. Our method is based on the concept that, although the direction of time is important in cell tracking, certain morphological changes, such as cell growth, generally occur in the positive temporal direction. Therefore, having information about the future position of the cell can be advantageous for tracking. As a result, we have developed a time-symmetric tracking method that utilizes the local temporal neighborhood in both the negative and positive temporal directions. Based on this architecture, the model learns to capture the direction of time and temporally unidirectional changes from the data, instead of relying on a temporally biased architecture. Our approach draws notable inspiration from the 2019 study of X. Wang29. However, instead of using cycle consistency losses, we sought to create an architecture that remains invariant to the direction of time itself. After the predictions are generated by this architecture, the resulting local tracks can be optimally matched and linked together based on prediction information within their temporal overlaps using the Hungarian method.
Local tracking
The local tracking around a single frame is performed on all cells individually distinguished by the previous instance segmentation step via a neural network designed for semantic segmentation. The channel parameters of this network can be defined as the tracking range (TR) parameter. The segmentator model input for a single cell instance consists of (TR + 1 + TR)+1 images as channels of the single input where TR + 1 + TR images are raw video frames centered around the frame on which the given cell is to be tracked, while on the additional 1 channel a single white dot marks the cell to be tracked at its centroid and the rest of the image is black. The determination of the centroid coordinates (xc, yc) is based on the segmentation instance for the given cell using image moments. The equations are as follows:
The target outputs for the local tracker consist of n + 1 + n frames, containing the segmentation of the cell marked on the last channel of the input. An illustration of this local tracking architecture is presented in Fig. 10.
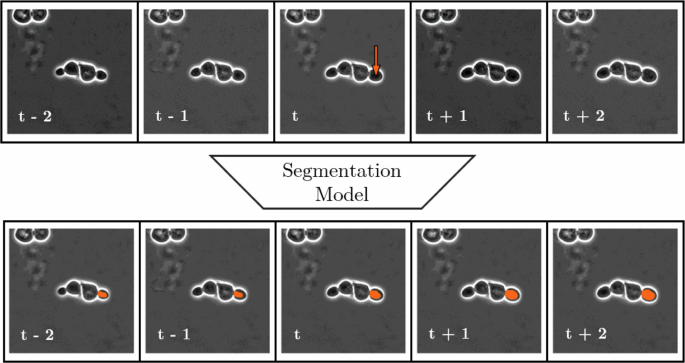
Depiction of input and output information structure of local tracking via segmentation with local tracking range (TR) = 2. Notice that while the left-to-right positive temporal direction of the data is recognizable from cell growth, and the model learns this during training, the architecture itself has no built-in directional preference, resulting in a completely data-driven estimation for local tracking.
The reason for using the centroid of the segmentation and not the segmentation itself in the input is that, according to our experiments, if the segmentation information was present there, the local tracker would not learn how to perform semantic segmentation. Instead, it would copy the input segmentation to all outputs, providing false segmentations to all outputs except the middle one. However, via using the centroid as a marker, the local tracker is forced to learn how to perform segmentation for the single marked cell on all temporal instances present, and thus it will be able to perform tracking via segmentation. Furthermore, if a cell instance is temporally close to the beginning or end of the recording, such that it is within n frames of the boundary, direct forward or backward tracking using a kernel size of n + 1 + n is not feasible. Nevertheless, the number of channels, which determines the local tracking distance, is a fixed parameter of the network architecture. To address this issue, we incorporate temporal padding by repeating the first or last frame. Additionally, we ensured that such instances were included during training to make the network capable of handling such edge cases and maintain its temporal invariance.
Based on empirical evidence, we found that among the tested semantic segmentation models, variants of the DeepLabV3+30 architecture from Pytorch Segmentation Models31 yielded the best performance for this task. The models were trained through 20 epochs with a minibatch size of 10 in all experiments using stochastic gradient descent optimizer with cosine annealing learning rate scheduling having warm restarts during the first 15 epochs and a gradual cool down during the last 5 epochs. The model output had sigmoid activation with binary cross-entropy loss.
Artificial data augmentation of the local tracking samples was performed using the torchvision transformations library32. For positional transformations random horizontal flip [p = 0.5] and random affine [degrees=(−40, 40), scale=(0.7, 1.3), p = 0.4] transformations were uniformly applied to the input and ground truth data. For color transformations color jitter [brightness = 0.5, contrast = 0.5, p = 0.4] transformation was applied for each input frame individually to improve model robustness for unexpected lighting artifacts.
Global tracking
As the output of local tracking, a single cell instance marked by the video frame and its position is tracked forward and backward through TR frames. This local tracking output can be obtained for each cell instance detected by the instance segmentation step, serving as the input for global tracking. Therefore, the aim of global tracking is to match local tracks based on the semantic segmentation predictions in their overlapping areas and chain them together based on ID matching, creating a full cell track based on a globally optimal consensus.
In practice, at first, we obtain this global consensus on a t to t + 1 level, as usually, the cells can be tracked from one frame to the next. However, if a cell instance does not receive any matches above the minimal requirement threshold, the matching can be repeated for larger temporal distances. This secondary matching is performed after all t to t + 1 matching is done, and only between the remaining candidates. Secondary matching is also performed hierarchically in terms of temporal difference, meaning that temporally closer instances get matched first, and only the remaining ones can get matched later with larger temporal differences. The maximal possible matching distance is 2TR, but matches over TR are unreliable as they are based on relatively few segmentation predictions, and only indirectly contain information about the segmentation of the central cell instances to be matched. Therefore, we believe using TR as the maximal temporal distance between local track matching is logically the most sound choice, but in practice, other choices could have minor benefits depending on the dataset.
Based on this methodology, the global consensus of ID matching can be turned into a one-to-one assignment problem for N × M candidates, where N is the number of candidates in frame t and M is the number of candidates in frame t + Δt where 1 < Δt ≤ 2TR. Such assignment problems can be optimally solved by variants of the Hungarian method in polynomial time, even for non-square matrices, but this requires a sound metric choice to measure the goodness of the candidate matches. In our case, these candidate matches are the 2TR + 1−Δt segmentation pairs in the overlapping temporal region of the local tracks to be compared. Therefore in an ideal scenario where perfect segmentations are achieved in local tracking, any metrics that solely compare segments within the same frame and calculate the average of these comparisons could be employed. This is because segmentation instances belonging to the same cell should result in a perfect match. However, in practice, the mean of Intersection over Union (IoU) turned out to be the best metric choice as it takes both the positional and morphological differences of the segmentations into account, and gives 0 similarity for segmentations with no overlap regardless of the distance. This process of calculating the metric similarity measure based on local tracks is depicted in Fig. 11.
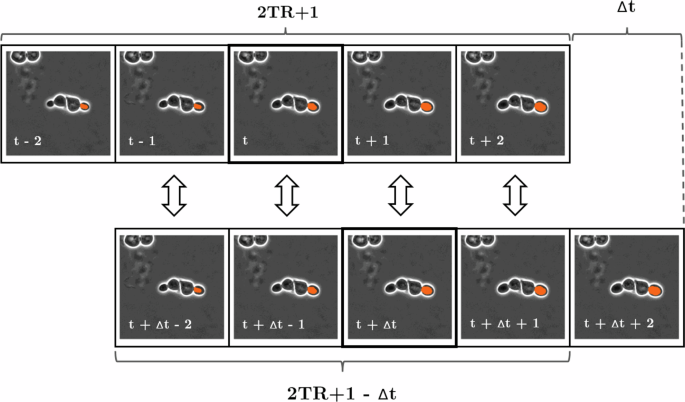
Schematic structure of the metric similarity measurement step between 2TR + 1 long local tracks of different cell instances on frames with a temporal distance of Δt. The solid lines indicate the central segmentation instances with a Δt temporal distance to be matched, while the arrows indicate the similarity metric between the segmentation estimates for each time frame. Subsequently, the individual metric results are averaged to obtain a single measure of similarity.
After computing the selected metric between all global tracks of frame t and t + Δt, a threshold can be employed to establish a minimum required similarity based on the metric results. This step eliminates candidates that do not meet the desired level of similarity. Subsequently, the Hungarian method can be applied to determine the optimal global consensus for ID matching between frame t and t + Δt, as depicted in Fig. 12. Via performing these steps in the hierarchical approach as described earlier, complete global tracks are constructed based on a global consensus of similarity, which solely relies on the prediction capabilities of the local tracker. The construction of global tracks is performed using the depth-first search graph algorithm33 to cover all existing branches arising from connections with a higher temporal distance than one frame. An example of successful global tracking using this pipeline is presented in Fig. 13.
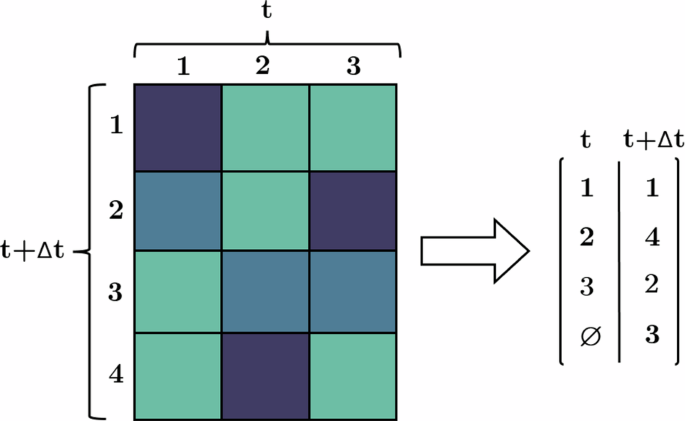
Illustration of the metric similarity-based assignment step using the Hungarian method for non-square matrices. Newly unassigned cells, such as cell number 4, receive a new ID, while the previously assigned cells retain the ID of their corresponding previous instances.
A side by side display of tracking results, demonstrating successful tracking of all cells in the same recording with a temporal difference of 8 frames. New cells were appropriately assigned new IDs while maintaining consistent tracking of existing cells.
Skipped instance interpolation
By employing the aforementioned methodology for global tracking, we can effectively address inconsistency errors in segmentation that commonly arise in realistic scenarios when Δt > 1. In such cases, although the resulting tracks will be complete, they may not be continuous, and segmentations for missed frames will be absent. To tackle this issue, we use a positional linear interpolation method, which is described by the following equations:
Here, S(x, y) and t represent the interpolated segmentation and its corresponding time, respectively. Slast(x, y), clast(x, y), and tlast denote the segmentation, centroid, and time of the last occurrence of the cell with the given ID, while cnext(x, y) and tnext represent the centroid and time of the next occurrence of the cell with the given ID. Although this method only shifts the segmentation from the last occurrence to the linearly interpolated position without altering its shape, in practice, the results have proven satisfactory. Still, in the future, incorporating a method that linearly interpolates the shape of the segmentation by considering both the last and next occurrences could potentially yield minor improvements.
Ancestry assignment
Our architecture currently does not include an integrated solution for assigning newly born cells to their ancestors. However, the stability and continuity of the predicted cell tracks suggest the feasibility of implementing such a feature later if required. Initial tests show that a basic prediction method using Euclidean distance, combined with positional and morphological heuristics like maximal newborn cell size, can produce satisfactory results for ancestry assignment when the predicted tracks are unbroken. For example, a somewhat similar simple distance-based method was employed in the Cell Tracking Challenge submission by A. Arbelle (2021)15,34. However, for more complex samples, additional morphological factors may need consideration, such as connectedness, or machine learning-based solutions could be utilized as a separate module if an ample amount of training data is available. Additionally, there is the option of integrated object instance classification of division, akin to the approach described in the publication by I.E. Toubal (2023)17. However, this would further increase the data intensity of architecture training and could introduce a potential weakness in the tracker module due to false positive cell division predictions dissecting some of the tracks.

Responses