Evidence for compositional abilities in one-year-old infants

Introduction
In “A Treatise of Human Nature”, Hume1 describes the city of New Jerusalem with streets paved with gold and walls decorated with rubies. Like Hume, we find it easy to form mental images of extraordinary cities, because our minds can combine familiar concepts (streets, gold, rubies), to imagine unfamiliar places and objects. This exemplifies one of the most powerful features of human thought: the ability to combine existing concepts in novel ways to construct an exponentially large number of thoughts. Fodor2,3,4, and many before him5,6, has suggested that the creativity of the mind is best explained by a “language of thought”, which holds that mental representations are formatted like sentences: they compose in the manner of formal language symbols, allowing us to build complex mental structures out of a small set of initial primitive operations.
In language, compositionality is defined as the possibility to determine the meaning of a message (e.g., a sentence or a constituent) from the meaning of its (immediate) smaller parts (e.g., sub-constituents, words, or morphemes) in a systematic manner7, see discussion in. One important way in which the meanings of some parts can be combined is through functional application8. As a somewhat artificial example, one can say that the meaning of ‘It’s not the case that it’s raining’ is the meaning of ‘it’s raining’, to which negation (the meaning of ‘It’s not the case that’) has been applied. As another stylized example, the meaning of ‘small car’ can be derived by the meaning of ‘car’, the set of all potential cars, by applying the meaning of ‘small’. Here, ‘small’ is simplified as a function that filters out all elements in the set that are above average size. Arbitrarily complex linguistic meanings can be obtained in the same way, and some frameworks (but not all) in syntax/semantics have argued that most (if not all) meaning combination operations reduce to function application (as in categorial grammar, see discussion in Keenan et al.9). We take function application to be a key element in compositionality even beyond language, it is the abstract definition of a way to mould, transform and complexify representations, be they representations of meanings, thoughts, or events.
Even if compositionality starts from rather minimal capabilities, such as function application, the question of its ontology remains nonetheless. Is it through extensive experience with language that compositional mechanisms develop, and make it possible to entertain compositional thought? Another possibility is that compositionality is an earlier capacity of the mind, that is consolidated outside of language initially, and that form a prerequisite to obtain any reliable ability to process even mildly complex elements. Progress on this question can be achieved by investigating compositionality in non-human animals, either in their native communication system or in their cognition through lab experiments10,11,12,13,14,15,16,17,18,19, and in infants, as targeted by the present work, asking whether their compositional abilities are in place before significant language experience. Current evidence finds that compositional language is mastered relatively late; this study revisits and broadens this question, asking whether compositionality is present earlier, possibly in simpler forms than previously assumed.
When do children use compositionality to understand language? Until recently, our understanding of when children acquire the ability to use compositionality in language was limited. However, recent research by ref. 20 has demonstrated that 12 month-old infants can combine newly learned numerals with object labels (e.g., “two ducks”), providing the first trace of compositional understanding at this early age. Beyond this finding, there remains a scarcity of robust evidence, and the extent to which compositionality is used by young children remains an open question. While several studies indicate that children in their second year of life understand multiword sentences under some circumstances21,22,23,24, these results are inconclusive since they can be explained by alternative, lower-level explanations that do not involve compositionality. Most of this research uses the looking-preference comprehension task that relies on children’s tendency to look at scenes that match the sentence they hear25. For instance, upon hearing “the duck is gorping the bunny”, 19 month-olds prefer a scene where a duck is acting on a rabbit than a scene where the animals’ roles are reversed, suggesting an understanding of the English sentence structure –a case of compositional understanding24. However, success in this task, and others, could stem from simpler strategies, such as interpreting the first noun as the agent24, matching the number of nouns in the sentence to the number of actors in the scene22, focusing on the last word of the sentence and matching it to the most salient object in the scene21 and processing words sequentially rather than composing them. While studies with children over 2 years of age generally support compositional understanding26,27 (but see ref. 28), studies with younger children confirm several of these alternative comprehension strategies29,30.
Outside language, the study of compositionality has been indirectly informed by studies testing the ability to engage in logical reasoning4,31. Logical inferences, such as the disjunctive syllogism (a or b; not b; therefore a), require the ability to manipulate logical operators (or, not), which are paradigmatic cases of compositional operations: they combine mental representations to form other, more complex, representations. Evidence for primitive logical operators is limited: while there is suggestive evidence for reasoning according to the disjunctive syllogism in preverbal infants, as well as great apes, monkeys or parrots32,33,34,35,36, these results are intensively debated37,38,39. Beyond logical reasoning (and outside the case of the disjunctive syllogism), we know little about the compositional abilities of preverbal infants.
One notable exception is a recent set of studies by Piantadosi and colleagues40,41,42 (see ref. 43), where compositionality is operationalized as the ability to represent and compose functions, as we suggested above. In these studies, infants and children first learnt two functions independently, i.e. transformations that can be applied on an object. For instance, they would learn that when an object goes behind a red/spotted occluder, it becomes red/spotted. Next, they were tested on their ability to compose these two previously learned functions (e.g., the object passes behind the red occluder, then the spotted occluder, without being visible in between these two transformations). While 3–4 year-olds, i.e. children having a good command of their natural language, correctly predicted the composition of these two functions41, language-novice 9 month-old infants failed40. This failure suggests that compositionality may emerge late, once language is already in place. But there is always the possibility that a different testing process could have revealed more of the children’s abilities, for instance because in that case infants might have had difficulty using newly learned functions, or processing the specific properties manipulated by these functions (i.e. colour and texture44). The present set of studies shares an important insight with this earlier work: We take mere function application to be the core ability involved in compositionality. This approach allows us to investigate the developmental origin of compositionality in linguistic and non-linguistic domains alike, in and outside communication settings, and with infants younger than those usually considered. Study 1 tested whether 14 month-old infants can display compositional skills to understand simple multiword expressions of the form “I don’t want X” where “not want” is combined with an object label X (Fig. 1). We tested 14 month-olds because, while infants begin understanding nouns referring to objects around 6–9 months45,46, it is not before 14 months that they reliably understand other types of words, such as verbs referring to actions47, which could potentially combine with object labels. Success in this task would provide evidence that infants can combine the meanings of words (potentially an object and an action) as soon as they reliably recognize each, suggesting that they do not need an extended learning period to learn this skill. Study 2 tested 12 month-old infants in a non-verbal version of Study 1 where “I don’t want X” was replaced by a “not face”48 directed towards an object (Fig. 2). The not face is a stereotypical facial expression of negation that is used as a co-articulator in speech and is readily produced and understood by adults of various cultural backgrounds48. We reasoned that 12 month-olds, who are beginning to exhibit early signs of refusal49 may start comprehending the widespread not face and its full compositional aspect (see ref. 50 in 18 month-old infants), offering an early test case of non-verbal compositionality. Study 3 built on evidence from core cognition in the physical domain51 to test 10 month-old infants’ ability to apply functions to transform their representation of a (hidden) physical scene (Fig. 3). In contrast to previous studies who taught infants novel functions that could be applied to objects40,41, Study 3 capitalizes on infants’ core knowledge of naive physics, thereby eliminating task demands that could have hidden infants’ compositional abilities outside of language.
Studies overview and predictions
Study 1 Compositionality with negative phrases
In study 1 (preregistered), infants (n = 32, aged 13 months to 15 months) were presented with 8 trials. Each trial was a short recorded video featuring an actress, see an example in Fig. 1. The actress was presented with two objects A and B that she labelled in turn, before producing either an affirmative, positive, sentence “I want the A” or a negative sentence “I don’t want the A”. The actress then picked one of the objects with a contented face. The object chosen was either congruent with the sentence the actress produced (object A after saying “I want the A”; object B after saying “I don’t want the A”) or incongruent with it (object A after saying “I don’t want the A”; object B after saying “I want the A”). During familiarisation, infants were exposed to 4 congruent trials, 2 in the positive condition and 2 in the negative condition, with each trial using a different pair of A/B objects. During test, infants were exposed to 2 trials in the positive condition (one congruent and one incongruent) that used one novel pair of objects not seen during familiarisation, and 2 trials in the negative condition (one congruent and one incongruent) that used another novel pair of objects. The novelty of the objects ensured that success in the task would be due to the productive composition of these positive/negative sentence frames with the relevant object. We predicted that, at test, infants should look longer at incongruent trials than at congruent trials if they can compose “want” or “don’t want” with an object label.

Still frames from videos shown to participants in study 1. In each video, an actress is presented with two objects that she labels in turn (e.g., “Oh a dog!”, “Oh a bunny!”), before producing either a negative sentence (e.g., “I don’t want the dog”) or an affirmative, positive, one (e.g., “I want the dog”). The actress then picked one of the objects (the dog or the bunny) that is either congruent with the sentence she produced (picking the dog after saying “I want the dog”, picking the bunny after saying “I don’t want the dog”) or incongruent (picking the bunny after saying “I want the dog”, picking the dog after saying “I don’t want the dog”). Consent for publication was obtained from the actress.
Study 2 Non-verbal compositionality with the not face
Do infants deploy compositional abilities outside the native language they learn, and possibly earlier? Study 2 (preregistered) tested 12 month-olds (n = 33, aged 11 months to 13 months), for which compositionality does not surface in language comprehension, nor certainly in language production. Infants were presented with a non-verbal version of study 1 (Fig. 2): instead of labelling the objects presented to her, the actress communicated her preference, or absence of preference, for one of the objects using facial expressions. In the negative condition, she looked at one of the objects with the facial expression of negation or “not face”48: frowning and pressing the lower and upper lips against one another, together with a horizontal headshake and a disapproving “↓Hmmm…” sound. In the positive condition, the actress looked at one of the objects with a constrasted “positive face”, characterized by elongated eyes and a smile (visible teeth) together with a vertical headshake and a cheerful “↑Hmmm!” sound. In contrast to the not face which serves as a grammatical marker of negation in American Sign Language and is recognized as a universal and spontaneous co-speech marker of negation in spoken language48, there is no evidence for a “pos-face” in natural speech. Similalry to study 1, we predicted that infants should look more towards trials where the actress would pick the object that is incongruent with the facial expression she made than to trials where she would pick the congruent object.

Still frames from videos shown to participants in study 2. In each video, an actress is presented with two objects. When the first object is presented to her (here the teddybear) she looks at it with a neutral/curious face (second frame). When the second object is presented to her (here, the dog) she either looked at it with a facial expression of negation (not face; top third frame), or with a positive facial expression (pos-face; bottom third frame). The actress then looked in front of her before picking one of the objects (the dog or the teddybear) that is either congruent with her previous facial expression (picking the dog after a pos-face toward the dog, picking the teddybear after a not face toward the dog) or incongruent (picking the teddybear after a pos-face toward the dog, picking the dog after a not face toward the dog). Consent for publication was obtained from the actress.
Study 3 Non-verbal compositionality in naive physics
Study 3 (preregistered) used an habituation task to investigate the conceptual pre-conditions for compositional language outside of a communicative context. In language, compositionality is often simply obtained as the ordered application of a series of functions, each transforming a representation into another representation8. We go back to this atomic definition here to test non-linguistic versions of compositionality, that is, of function application. Previous studies tested compositionality through function application in the physical domain40,42,43 (e.g., an object goes behind a red occluder and becomes red). In contrast to these studies, we did not teach new functions to our participants, and focused on using natural cases of function application from naive physics, a domain where infants have been shown to have early knowledge from 2 to 3 months of age51. To illustrate, suppose that E is the mental representation of an environment, and that this environment is now out of sight. Seeing that a wall is added to the environment behind the occluder, one needs to update E to wall(E), here wall is a function that yields a representation with a wall added. Similarly if a ball rolls behind the occluder, E needs to be updated to ball(E), where ball is a function that adds a rolling ball to E. If the functions are applied to E in a specific order, different interactions between the ball and the wall may occur, and one may thus expect different final outcomes: ball(wall(E)) vs. wall(ball(E)). One can thus test the proper use of function application by examining expectations about the sequence of transformations applied to an environment, rather than focusing, as previously40,42,43, on transformations applied to an object.
Ten-month-old infants (n = 34, aged between 9 months and 12 months) were presented with computer animated events (Fig. 3). These events featured a wall on the right hand of a stage (the initial state of an environment E), followed by the placement of an occluder that fully concealed the wall. Subsequently, a ball rolled horizontally from left to right behind the occluder and presumably all the way to the wall (application of the function ball). Upon removing the occluder, the ball was accordingly revealed on the stage, resting against the wall which had stopped its trajectory (ball(E)). The duration of infants’ gaze was recorded immediately after the occluder was removed, and this sequence was repeated until infants habituated to the events. Infants were then presented with 6 test trials, 3 congruent and 3 incongruent, involving a sequence of two events. In congruent trials, the ball started rolling from left to right (the function ball), entering the space hidden by the occluder. Once the ball had ample time to hit the right-hand side of the display (i.e. the initial wall), a new wall was positioned from top of the screen (where it is visible) to behind the occluder in the center of the normal trajectory of the ball (the function wall). When the occluder was removed, the ball was shown resting against the initial, rightmost wall, consistent with the sequence of events (wall(ball(E))). In incongruent trials, the events were reversed: the intervening wall was first placed at the center of the (hidden) path (function wall), and then the ball started rolling from left to right function ball. The occluder was then removed to reveal the ball resting on the initial, rightmost wall, as if it went through the center wall (this is the outcome wall(ball(E)), inconsistent with the order in which the functions are applied which should have resulted in the ball resting on the center wall, ball(wall(E))). In both congruent and incongruent trials, the way the ball and the wall interacted occcured behind the occluder, and infants observed the same final outcome. Therefore, for congruency to have an effect, one would need to mentally compute the effect of transforming the environment by adding a wall to it, or by rolling a ball through it, in different orders.
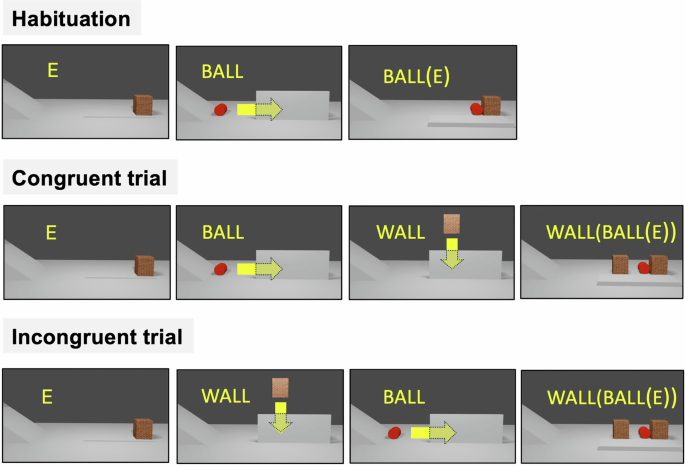
Still frames from the three video stimuli presented to participants in study 3 during habituation and test (congruent and incongruent trials). The yellow arrows (not visible in the actual videos) represent the direction of the movement of the ball and the wall. E stands for the initial representation of the environment before it gets occluded. wall is a function that adds a wall to the environment and ball, a function that adds a ball to the environment. The final outcome of both test trials is wall(ball(E)) which is consistent with the sequence of function application ball then wall (congruent trial) and inconsistent when the order in which the functions are applied is reversed (incongruent trial).
Methods
All studies were pre-registered. The pre-registration are available here:
Study 1 (26/02/2024): https://osf.io/zpb5u
Study 2 (26/02/2024): https://osf.io/9aeut
Study 3 (16/02/2022): https://osf.io/j7m64
All studies were approved by Ethical committee of Aix-Marseille University (number 2021-04-08-10).
Study 1 Compositionality with negative phrases
Participants and exclusions
Participants were 32 full-term infants (M = 441 days; (,{mbox{SD}},=17;min =402;max =469); 18 females and 14 males; information provided by their caretakers). All infants were French monolinguals (hearing at least 90% of French on w weekly basis according to their caretakers). According to their caretakers, 27 infants were producing the word “no”. Infants were recruited in the Paris area and tested online.
In this experiment and in the subsequent ones, participants were excluded from the analysis based on a set of preregistered criteria including fussiness, technical failure, delayed connexion (as reported by the parents) and less than 2 valid test trial per condition. Trials were excluded when (a) participants looked away for more than 2 s consecutively during the video before it froze (see design below); (b) parents interfered or where any environmental distraction occurred, (c) connexion was lost or delayed or (d) trials were aborted by the experimenter. 14 additionnal infants were excluded from the analysis: 5 because of connexion problem as reported by the parents (lag between the video and the audio), 5 because of fussiness (infants uninterested by the screen; these infants were rejected without looking at their data), 2 because of technical issues and 2 for failing to provide 4 valid test trials.
Material and design
Participants were presented with a total of 8 trials: 4 familiarisation trials and 4 test trials. Trials were short video clips of ~16 s in which an actress first greeted the infant (“coucou bébé”/“hi baby”) before turning to two sequentially presented objects. The first object (e.g., a dog toy) was always introduced on the right of the actress by a second experimenter whose hand was the only visible part in the video clip. The actress directed her gaze towards the right-object and labelled it (e.g., “Oh un chien!”/“Oh a dog”). She then shifted her focus back towards the infant (center) before the second object was introduced on her left (e.g., a rabbit toy). Similarly, she looked at the left object and labelled it (e.g., “Oh un lapin!”/”Oh a bunny”) before returning her gaze to the infant (center). While maintaining eye contact with the infant, the actress uttered either a positive sentence (the positive condition, e.g., “je veux le chien”/“I want the dog”) or a negative sentence (the negative condition, e.g., “je veux pas le chien”/“I don’t want the dog”) with a neutral facial expression. The actress then selected one of the objects with a contented expression and the video froze at that time.
There were two trial types: in the congruent trials, the actress selected the object that is congruent with the sentence she uttered (e.g., choosing the dog after saying “I want the dog” in the positive condition or choosing the rabbit after saying “I don’t want the dog” in the negative condition). Conversely, in the incongruent trials, the actress selected the object that conflicts with her statement (e.g., opting for the rabbit after saying “I want the dog” in the positive condition or opting for the dog after saying “I don’t want the dog” in the negative condition).
All the 4 familiarisation trials were congruent and featured different pairs of objects (book/ball, hat/shoe, toy flower/toy car, cake/bottle). The objects were chosen such that their label is likely to be known to infants of that age, and they were paired such that both objects of the pair belonged to the same broad semantic category (clothes, toys, food) to increase pragmatic felicity (as it seems more natural to make a choice among two related options) with the additional constraint that there should be no, or minimal phonological overlap between their labels. Within the 4 familiarisation trials, the side of the object selected by the actress was counterbalanced. There were two trials in the negative condition and two trials in the positive condition. The condition assigned to each pair of objects and the object labelled within each pair was counterbalanced across the infants. The order of the familiarisation trials was randomized for each infant.
In the 4 test trials, there were two trials in the positive condition (one congruent and one incongruent) that used one pair of objects and two trials in the negative condition (one congruent and one incongruent) that used another pair of objects. Each pair of objects were thus seen twice within the same condition (and using the same object label), one time with a congruent outcome and one time with an incongruent outcome. The conditions were presented alternatively (positive-negative-positive-negative or negative-positive-negative-positive). Similarly the congruency of the trials also alternated, with this alternation pattern starting either with a congruent or an incongruent trial. Two pairs of objects (banana/bread, dog/rabbit) were selected for their lack of phonological overlap and likelihood to be known to infants of that age. The order of the test trials (consistent-first or inconsistent-first) as well as the assignment of each pair of objects to each condition (positive or negative) and object labelled within the pair were counterbalanced across infants.
Procedure
Infants were tested remotely via video call. Before the session, parents were asked to place their infant on their lap or on a high chair. They were also asked to use a computer (and not a phone or a tablet), to be in a room with sufficient light and away from potential distractions (siblings, pets…). Before the study started, the experimenter shared one of their screens and asked the parents to set this screen in full-screen mode and hide their video vignette and the video vignette of the experimenter ensuring only the experiment’s screen was visible. Parents were requested not to interact with their infant or redirect their attention towards the screen during the study. Then, the study started. The study was conducted using a home-made python script, with the experimenter monitoring the infant’s gaze by pressing a key when the infant looked at the screen and releasing it when they looked away. The experimenter was unaware of the trial condition (the shared screen was covered or faced the opposite direction). Trials ended automatically after the infant looked away for 2 consecutive seconds or after 45 s, which ever came first. An attention-getter, featuring moving bubbles accompanied by soft music, was then played to regain the infant’s attention. Once the infant looked at it for 2 s, the experiment proceeded automatically to the next trial.
At the end of the study, the experimenter briefed the parents about the hypothesis of the study, addressed any questions they had, and inquired about the video and sound quality during the experiment.
Analyses
The dependent measure was the amount of time infants looked at the video after it was frozen (the still image of the actress having selected one of the objects). Looking times were calculated online and automatically by the python script used to display the experiment. Following our pre-registration, we log-transformed the looking times52 but plots and descriptive statistics feature raw values for ease of interpretation. We used linear mixed models53 in R54 to test whether infants’ looking time was affected by the congruency of the outcome given the sentence the actress produced in each condition. P-values for main fixed effects are based on likelihood ratio tests, simple effects are reported from the summary table of the model. The model was specified as LogLookingTime ~ Outcome * SentenceCondition + (1 ∣ Participant). There was no main effect of trial order (first trial is positive-congruent vs. positive-incongruent vs. negative-congruent vs. negative-incongruent; χ2(1) = 0.006, p = 0.94) so this predictor was not kept in the model.
Study 2 Non-verbal compositionality with the not face
Participants and exclusions
Participants were 33 full-term infants ((,{mbox{M}}=388;{mbox{days}};{mbox{SD}},=12;min =368;max =417); 13 females and 20 males; information provided by their caretakers). According to their caretakers, 17 infants were producing some form of negation, either the word “no” or some head shake. Infants were recruited in the Paris area and tested online.
The exclusion criteria were pre-registered and the same as in Study 1. Data of 5 additional infants were excluded for the following reasons: fussiness (2), technical issue (1), significant lag in the audio relative to the video according to the parent (1), because the video angle was inadequate for coding (1; the participant used a tablet oriented horizontally and the camera was thus on the side). Two of the infants provided data only for the negative condition.
Material
The time course of a trial closely mirrored that of study 1, except that the actress used facial expressions instead of spoken language to communicate her preference, or dispreference, for one of the two objects presented to her. Each trial was 11.3 s long and similarly started with the actress greeting the infant (“coucou bébé”/“hi baby”) before directing her attention to the first object, introduced on the right or on the left by a second experimenter off-camera. Upon looking at this first object, she always displayed a neutral/curious facial expression accompanied by a corresponding “Mmmm” sound. The actress then looked back to the infant (center) before shifting her attention towards the second object presented to her. Upon looking at the second object, she either made a positive facial expression along with a cheerful “Mmmm!” sound (the positive condition) or a negative expression accompanied by a disapproving “Hmmm…” sound (the negative condition). She then looked back towards the infant (center) before selecting one of the objects with a happy expression and a positive “Mmm Mmm” sound distinct from the one used in the positive condition. The video then froze at that moment. For the 4 familiarization trials, we used 4 pairs of objects: tennis ball/spiky ball, white hat/pink hat, toy flower/toy car, cake/bread. For the 4 test trials, we used two pairs of objects: stuffed bear/stuffed dog, banana/grape.
Design, procedure and analysis
The design, procedure and analysis were the same as in Study 1. The model was specified as LogLookingTime ~ Outcome * FaceCondition + (1 ∣ Participant). There was no main effect of trial order (first trial is positive-congruent vs. positive-incongruent vs. negative-congruent vs. negative-incongruent; χ2(1) < 0.001, p = 0.98) so this predictor was not kept in the analysis.
Study 3 Non-verbal compositionality in naive physics
Participants and exclusions
Participants were 34 full-term infants ((,{mbox{M}}=305;{mbox{days}};{mbox{SD}},=22;min =279;max =350); 10 females and 24 males; information provided by their caretakers). Infants were recruited in the Paris area and tested online.
The exclusion criteria were pre-registered and the same as in Study 1. Data of 10 additional infants were excluded for the following reasons: fussiness (4), connexion issues (3), not enough valid trials (2), too many distractions around (1).
Material and design
The experiment consisted of a familiarization phase and a test phase. In the familiarization phase, the same familiarization trial was repeated. The familiarization trial (11 s) started with an attention-getting sound (“Regarde!”/“Look!”) before a wall fell on the right of a stage, accompanied by an impact sound and a camera shake effect. An occluder then rose on the right of the stage with a door-like noise, such that the wall was entirely hidden behind it and that the left portion of the stage was visible. Next, a red cylinder rolled horizontally with a rolling sound from the left to the right of the stage behind the occluder. The occluder was then removed, revealing the cylinder resting on the wall which has stopped its trajectory. The onset of looking time measurement coincided with the occluder’s removal, marked by a bell sound. The familiarization phase continued until 14 trials were presented or until looking time decreased by 50% on 3 consecutive trials relative to the first 3 trials.
Once this criterion was reached, the test phase followed. The test phase consisted of 6 trials: 3 congruent and 3 incongruent trials (13.4 s) presented alternatively. The order of trials (incongruent first or congruent first) was counterbalanced across infants. As in the familiarisation trials, an attention-getter was played before a first wall felt on the right of the stage which was then hidden by an occluder hiding the right portion of the stage. Infants then observed two events sequentially (function ball: the red cylinder ball rolled from left to right behind the occluder; function wall: a wall felt at the center of the stage behind the occluder) before the stage was revealed. In the incongruent trials, infants saw a second wall falling in the center of the stage behind the occluder (function wall) before seeing the red cylinder rolling from left to right behind the occluder (function ball). The occluder was then removed to reveal that the cylinder was resting on the right wall as if it passed through the center wall, a result inconsistent with the laws of physics. In the congruent trials, the order of the events was reversed: infants first saw the cylinder rolling from left to right (function ball) then, once the cylinder had logically hit the right wall, a second wall fell at the center of the stage hidden by the occluder (function wall). When the occluder was removed, the cylinder was in the same position as in the incongruent trials: resting against the right wall, as expected by the sequence of events.
All the video animations were created using Blender™ .
Procedure and analysis
The procedure and the analysis were identical to the ones of Study 1 and 2, except that the maximal looking time during test trials was set to 30 s. Infants took on average 8.61 trials to habituate (({mbox{SE}},=0.49;min =6;max =14)). Six infants failed to meet the habituation criterion (14 habituation trials). These infants were included in the final analysis (excluding them did not change the interpretation of the results). The statistical model was specified as LogLookingTime ~ TrialType + (1 ∣ Participant). There was no main effect of trial order when added to this model (first trial is congruent vs. first trial is incongruent; χ2(1) = 1.078, p = 0.299) so this predictor was not kept in further analyses.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Results
Study 1 Compositionality with negative phrases
As shown in Fig. 4A, there was a main effect of outcome congruency (χ2(1) = 14.03, p < 0.001): Infants looked more when the actress chose the object that was incongruent with respect to the sentence she previously uttered, both when the sentence was positive [Mcongr = 9.99s (SE = 0.96s) vs. Mincongr = 13.14s (SE = 1.20s); β = 0.36, SE = 0.12, t = 2.91, p = 0.004] and when it was negative [Mcongr = 9.02s (SE = 0.96s) vs. Mincongr = 12.03s (SE = 1.08s); β = 0.31, SE = 0.12, t = 2.5, p = 0.014]. There was no statistically significant evidence for an effect of sentence condition (χ2(1) = 0.46, p = 0.50) nor interaction between sentence condition and outcome (χ2(1) = 0.1, p = 0.75).
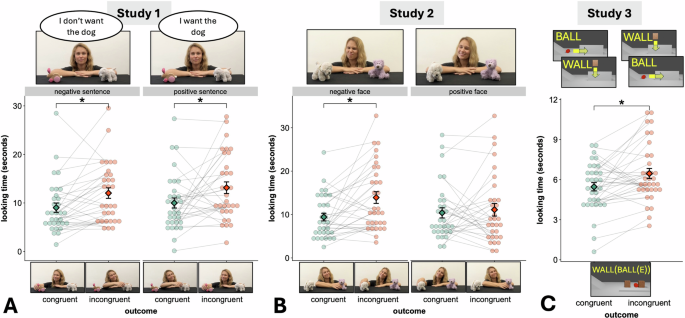
Looking times in seconds towards the congruent (green) and incongruent (orange) outcomes in study 1 (A), n = 32, study 2 (B, n = 33) and study 3 (C, n = 34). Images show the video display critical to each condition (above the graph) and outcomes (below the graph). Diamonds indicate means and error bars represent standard errors of the mean. Dots represent individual means. The asterisks indicate significance between outcomes (alpha level of 0.05).
To detect the incongruency of the trial outcome, infants must have accessed the meanings of the constituents of the sentence (“want”/“don’t want” and the object label) and compose them to predict which object the actress is going to pick. Moreover the co-presence of trials with positive sentences and trials with negative sentences ensured that infants cannot solely rely on the object label to predict the choice of the actress (i.e. always selecting the object that matches the label or always selecting the object that does not match the label). Compositional abilities are thus deployed in language as early as 14 months of age.
Study 2 Non-verbal compositionality with the not face
As shown in Fig. 4B, infants looked more at incongruent choices than at congruent choices in the negative condition [Mcongr = 9.41s (SE = 0.88) vs. Mincongr = 13.91s (SE = 1.35); β = 0.37, SE = 0.13, t = 2.83, p = 0.006], but not in the positive condition [Mcongr = 10.39s (SE = 1.17) vs. Mincongr = 11.10s (SE = 1.45); β = 0.02, SE = 0.14, t = 0.15, p = 0.88]. The interaction between facial expression condition and outcome was significant (χ2(1) = 4.39, p = 0.036), there was no evidence for an effect of facial expression condition (χ2(1) = .27, p = 0.13) and a marginal effect of outcome (χ2(1) = 3.56, p = 0. 06).
Similarly to study 1, to detect the congruency of the outcome, infants must integrate the facial expression with the object it is directed to. 12 month-olds effectively predicted which object the actress would pick after displaying the not-face, but not after a positive face. The lack of evidence for an effect in the positive condition is unsurprising for two reasons. First, the contrast between the not face and the facial expression used for the other object (expressing curiosity, thus mildly positive) was greater than for the positive face. Specifically, if the actress displays a positive face towards an object and a mildly positive face towards another, it is harder to predict which object she is going to pick. A second important aspect is that the positive face was an invention of ours here, and not documented to be a natural, universal signal, unlike the not face. In sum, our results suggests that 12 month-old infants comprehend the functional property of the not face well before they are known to understand the truth-functional meaning of linguistic negation55,56.
Study 3 Non-verbal compositionality in naive physics
As shown in Fig. 4C, infants looked longer, indicating surprise, in incongruent trials compared to congruent trials [Mincongr = 6.46s (SE = 0.38) vs. Mcongr = 5.47s (SE = 0.31); β = 0.22, SE = 0.09, t = 2.45, p = 0.015]. Ten month-olds were thus presumably capable to mentally calculate the physically expected outcome, that is, to apply a sequence of transformations (functions) to their mental representations of a scene.
Discussion
Compositionality is the ability to build complex representations by incrementally combining and transforming simpler ones. It is a defining feature of human language and thought. How tied to language are the necessary compositional processes? Our work provides evidence that these processes arise early in acquisition, and have equivalent processes outside of language. Across three studies, we show that, by their first birthday, infants can combine abstract representations of labelled objects or physical scenes to make inferences about possible outcomes.
Study 1 establishes that by 14 month-olds, infants can compose the expression “veux”/“veux pas” (want/don’t want) with an object label, already lowering the age bar by which infants are shown to understand compositional language. To our knowledge, the earliest attested evidence for compositional understanding in language was the comprehension of negation at 17–18 months of age. But then how to reconcile this finding with previous failures at younger age? For instance, Feiman and colleagues57 used an experimental design that is very similar to ours: infants are presented with two options (one bucket and one truck), a ball is then covertly hidden in one of these two items before the experimenter states “the ball is NOT in the bucket” or “the ball is in the bucket”. The authors then measured whether children were more likely to approach the location that matched the sentence they heard. Their findings showed robust success in this task starting only at 20 months of age, with no significant success at earlier ages. We suggest that previous failures may be due to task demands: requiring infants to make a concrete choice may have masked their ability to combine “not” with an object label. In contrast, our task, which only required detecting an action-context mismatch, was less demanding and likely revealed this ability. Does this mean that 14 month-olds have mastered linguistic compositionality? We remain cautious. Demonstrating that infants can combine “don’t want” with an object label does not imply mastery of all functions available in language (e.g., combining “small” with “cat,” which requires subseting). Our results show early compositional abilities, but not full mastery at this stage.
Study 2 extends Study 1 and shows that by the even younger age of 12 months, infants can make compositions with the so-called not face, a universal co-speech facial expression marking negation. Specifically, infants can predict that an actor will not pick an object to which the actor associated a not face. Critically, this was not because of properties of the objects, neither their inherent properties (objects were randomized) nor circumstantial properties (target objects were always those presented last, target objects sometimes had a ‘pos-face’ associated with them). Thus, it was truly the combination of the not-face and the object it was directed at that was understood. How do we reconcile our findings with mixed results from disjunctive syllogism (A or B; not A; therefore B37,38,39) and non-match-to-sample tasks (choose the non-matching option58), which suggest infants struggle with negation? A key strength of our task is its use of familiar social signals from everyday interactions. As noted earlier, simplifying task demands can reveal hidden abilities, especially when tasks require learning entirely new functions without clear ties to prior knowledge, like non-match-to-sample tasks. In addition, our task embeds negation within a specific social signal: the “not-face,” which infants interpret in relation to the referenced object. This compositional unit, where the not-face negates the object representation, sets our study apart, as previous tasks did not embed negation in non-linguistic signals, likely making it harder for infants to process and apply.
Is the not face an early form of propositional negation then? Our results cannot go as far. Maybe the not face can mark all sorts of negativity, such as ‘avoid this’, or ‘this is unlikable’, etc. Maybe its use is restricted to specific contexts such as objects while a general operator like “not” would be expected to apply across all types of representations. In all reasonable cases however, it has to be composed with a target object to succeed at the task, thus revealing an early capacity for such compositions.
While function application is best exemplified by logical operations, such as negation as in Study 1 and 2, it does not have to be so, as function application can be studied outside the logical domain and outside communication. Study 3 examines an even younger age group, focusing on 10 month-old infants, by using a task that does not rely on communicative skills. Specifically, it shows that infants can successfully predict the outcome of a sequence of physical transformations made to a hidden environment. Operationally, our results suggest that infants can form a first representation E1 of a scene, and then update E1 into E2 = f(E), where f is a function that adds a wall or a ball to E1. And they can apply yet another function g to the result E2, to obtain ({E}_{3}=gleft(f(E)right)). Critically this shows that infants were not only able to do function application, but even ordered, iterative function application (since the critical test relies on the fact that (gleft(f(E)right)ne fleft(g(E)right))).
Limitations
While our studies were motivated by functional application, a classic way to describe similar successes may be in terms of object tracking or simulations38,59. In these approaches, a mental model is updated based on operations grounded in perceptual systems (e.g., add adds information to the representation from the visual scene). In our view, this “model update” approach based on perceptual input is a case of functional application, updating is a function which can be applied several times as more events or objects are taken into account. For this reason, we argue that function application, when conceptualized at this abstract level, is very widespread.
If we admit that infants have the capacity for mental function application, this has significant implications for how we understand development at later stages. For instance, it makes it less problematic to understand how older children can assign a functional meaning to a word, without the need to acquire the concept of a function at the same time60. Supporting this many experiments from the literature can be advantageously reinterpreted using this perspective, offering a more abstract framework to capture model updates, as well as other instances of function application. This could be the case for naive physics experiments51, theory of mind experiments61, object individuation experiments62, simulations38,59 or numerical tasks63,64,65. However, most of these experiments were not designed to provide conclusive evidence regarding compositionality, and either the environment is revealed between each function application (e.g., in previous naive physics experiments, a wall function is applied but the wall is not fully concealed by the occluder, so infants do not need to mentally update their representation of the environment51), or in fact infants struggle to repeatedly update their representation of the environment (e.g., 8 month-old infants failed to predict the number of objects behind an occluder after the addone function was performed twice63 possibly because the interaction of counting and transformation is just too much). These experiments could suggest that infants younger than 1 year old cannot track the result of two operations applied sequentially behind an occluder40,63. But contrary to these studies, we used functions from the physical domain, which infants are familiar with as early as 3 months of age51, and focus the workload as much as possible on the need to track the transformations applied. In such a setting, infants revealed their atomic ability for function application and their readiness to compositionality.
Conclusion
In three studies, infants demonstrated their very early ability for compounding signals and representations. To show this, we focused on the most central and fundamental aspect of compositionality, i.e. function application, so that it could be applied to linguistic material (Study 1), but also to other non-linguistic communicative signals (Study 2 which requires the composition of people’s ostensible expression of feelings with world objects), and to naive physics (Study 3). Infants then revealed an ability for compositionality before mastering many components of language, a key domain for compositionality. These findings thus reveal that key aspects of compositionality may emerge in domains outside of language.
This raises a key question: how does compositionality arise? Does it emerge in language or in other domains and, in each case, how is it bootstrapped? Practically, this calls for discovering in what domain compositionality can be found first, and at what age (in the sense of other bundles of abilities being present). The current results push the age bar much lower than before. Another important question that our results touch upon is whether non-human animals exhibit similar compositional abilities. Given that very young children master a form of compositionality, animals may exhibit some form of it as well, and this could help us understand how it is acquired without committing to it being related to language. However, we could ask why other animals do not take advantage of such an ability in their communicative systems, and why humans do66. But recognizing it outside of language makes compositionality per se a less critically human behaviour.

Responses