Immersive auditory-cognitive training improves speech-in-noise perception in older adults with varying hearing and working memory

Introduction
Ageing is accompanied by changes in hearing sensitivity, whereby the prevalence of high-frequency hearing loss increases with age1. Consequences associated with such age-related hearing loss include increased risk of depression2, social isolation3, as well as cognitive decline4,5, and are particularly detrimental as they contribute to a reduction in quality of life. Comprehending spoken language in difficult listening situations is a related challenge that increases with hearing loss and further promotes these consequences6,7. However, the difficulty of understanding speech in noise is not exclusively associated with hearing impairment, as it is also experienced among individuals with normal or corrected-to-normal hearing8,9,10. While interventions such as hearing aids provide a substantial support for the sensory decline experienced by hearing loss, this solution might therefore not be entirely sufficient to address the experienced challenges with speech in noise perception11,12. Furthermore, hearing aids are rather underutilized, partially because of high costs, low accessibility, and technological challenges13,14,15. Therefore, the interest in additional interventions targeting the support of speech perception in adverse listening situations has emerged, resulting in increased interest in auditory and cognitive trainings.
Auditory trainings aim to improve auditory skills by actively listening to varying acoustic content and learning a more accurate distinction, ideally resulting in improved acoustic sensitivity16,17. Empirical evidence has demonstrated improvement through auditory trainings in target detection for degraded18,19 and non-degraded acoustic information in noise20,21. However, comprehending natural continuous speech, particularly in noise, is not solemnly dependent on distinction of acoustic cues alone, as it requires perceptual processes of multisensory information (e.g., acoustic speech signal, visual information provided by the speaker), linguistic, and cognitive processing within the working memory system22,23,24.
The link between speech in noise perception and working memory has been established by multiple studies24,25,26,27,28,29,30. Cognitive trainings generally aim to improve cognitive functions through engagement with cognitively challenging tasks31. Based on the relationship between speech in noise and cognition, the idea has emerged that cognitive trainings may have a transfer effect that goes beyond cognitive task improvement and translates into improved speech perception. Ferguson and Henshaw32 investigated potential transfer effects of a commercially available working-memory training program (Cogmed RM) and reported a near-transfer effect (e.g., improvement in untrained working memory tasks) but no far-transfer effects (e.g., speech perception). The authors concluded that an integrated auditory-cognitive approach might result in the most benefit regarding speech in noise perception. This conclusion has also been made by a state-of-the-art review conducted by Stropahl and colleagues33, suggesting that a combined auditory-cognitive training approach might result in enhanced communication skills among older hearing-impaired individuals. This idea is supported by the assumption that successful comprehension of speech requires a combination of sensory and cognitive processing. Schneider and Pichora-Fuller34 proposed an integrated perceptual-cognitive system theory, suggesting a direct link between sensory processing and higher-order cognition regarding speech. The model emphasizes the importance of sufficient allocation of processing resources to enable successful speech perception, which has been demonstrated empirically35,36,37,38. Therefore, combining both, auditory and cognitive training might provide a better representation of skills necessary to fulfill the requirements of speech perception and therefore might represent a better training approach compared to isolated auditory or cognitive trainings.
While combined auditory-cognitive training appears promising, it is important to focus on a training design that offers the potential for far-transfer effects which are reflecting elements from real-world listening. Particularly, a training should target cognitive processes which support speech perception and add a natural speech task to promote potential transfer to real-world listening. Furthermore, more realistic and natural speech tasks have a higher chance to increase the perceived relevance and ideally improve motivation for adherence16.
In real-life listening situations, speech perception is often presented in a multisensory modality, conveying auditory information and visual information, provided by the speaker’s jaw- and mouth movement, face, and body. Empirical evidence has demonstrated a potential audio-visual speech perception benefit, particularly in adverse listening situations for speech intelligibility39,40,41,42,43,44,45. As such, a training that aims to improve speech perception in adverse listening situations might not only benefit from a combination of auditory and cognitive components but also from embedding speech in a multisensory realistic environment to target far-transfer effects to real-world listening (e.g., speech in noise perception).
The current study aims to investigate if speech in noise perception improves after a short-term naturalistic auditory-cognitive training in a population of older adults with varying hearing acuity and cognitive capacities (N = 39). Furthermore, we aim to evaluate if a potential training effect can be enhanced through immersive multisensory speech presentation and how individual capacities interact with such a multisensory modality. To this end, we developed a speech-memory paradigm that allowed us to manipulate the memory load of the presented speech material (e.g., the cognitive component) and the presentation modality between mere auditory- and immersive audio-visual speech presentation (e.g., the sensory component). This paradigm was implemented as a short-term auditory-cognitive training session (~42 min), while before and after the training individual speech reception thresholds in noise were established. During the training sessions, participants heard natural continuous speech and were required to answer comprehension questions regarding the presented content. Memory load was manipulated by varying the amount of presented verbal information during the training session. This manipulation was chosen, as it reflects a more realistic cognitive demand when presented with natural continuous speech in a real-world listening situation. Furthermore, such a manipulation aims for an enhanced selective attention, which potentially could result in improved speech in noise perception (e.g., the relationship between selective attention and speech in noise perception46,47). As such, we decided to incorporate a manipulation of cognitive load by using a task that would potentially increase selective attention, while also targeting working memory capacity. Furthermore, we wanted to investigate such a manipulation in the context of individual working memory capacity, in order to gain a better understanding of potential mechanisms that would contribute to a training effect. We decided to manipulate speech presentation modality by introducing an immersive and naturalistic visualization of the speaker through a virtual reality (VR) headset. Important to note, the speaker was not embodied by a virtual avatar but rather through a stereoscopic recording, which provides a three-dimensional immersive visualization of the speaker which is very natural. Immersion refers to the extent to which a situation is perceived as realistic and how much the external environment is suppressed by the representation48. Immersion in the context of social interactions is characterized by the fidelity of the environment and the extent to which a social actor is perceived as real49,50. By introducing visual speech cues through an immersive set-up, we create a multisensory environment mimicking a conversational experience, while providing high controllability. By using a cross-over design, we were able to use within-subject data (e.g., the influence of speech presentation modality on individual performance), while also controlling for potential exposure effects. Considering that a potential change in speech in noise perception after a training might just be based on attentional or exposure effects, the design allowed us to investigate if the observed effect was across both trainings (for the same individual) or particularly strong after the immersive training.
Based on the existing evidence regarding the effect of auditory- and cognitive trainings, we hypothesize that a short-term auditory-cognitive training with naturalistic speech material improves speech in noise perception (quantified by increased signal-to-noise ratio). Furthermore, we assume that training-induced improvement is moderated by modality, whereby stronger improvement in speech in noise is expected after an immersive training session compared to an auditory training session. This hypothesis is based on the assumption that a naturalistic training environment might induce stronger transfer effects, particularly since the learning environment reflects a real-life listening situation.
Results
Performance change during the training across modalities
To ensure that potential training-induced effects were not due to different levels of difficulty, and accordingly due to exhaustion during the training sessions (AU vs. IM), we compared the comprehension performance during each training session. As such, we used the first- and the last block during both sessions (each session consisted of six blocks, each block contained ten trials) and compared the performance between beginning and end of the training session using a generalized linear mixed model. The model contained comprehension response (correct vs. incorrect) as a binary outcome variable and modality (AU vs. IM) and block (first vs. last) as categorical predictors, two-way interaction, and by-subject random effects. The model revealed a significant main effect of modality (Δχ²(1) = 8.077, p < 0.004), suggesting a significantly better performance during the immersive training session (averaged performance across the first and last block), compared to the auditory training session (AUperformance – IMperformance: Δβ = −0.488, SE = 0.181, t = −2.688, p = 0.007). Furthermore, the training revealed a significant interaction between modality and block (Δχ²(1) = 4.463, p = 0.035), indicating significantly decreased performance at the end of the auditory training compared to the end of the immersive training (AUlast – IMlast: Δβ = −0.873, SE = 0.254, t = −3.439, p = 0.003), while the performance within training modality did not significantly decrease from the first to the last block in both modalities (AUfirst – AUlast: Δβ = 0.534, SE = 0.233, t = 2.296, p = 0.098; IMfirst – IMlast: Δβ = −0.236, SE = 0.278, t = −0.847, p = 0.832). These results suggest that processing of both, sensory and cognitive elements, was facilitated during an immersive training, resulting in stable performance across the whole session. Concurrently, during the auditory training session the performance decreased towards the end, suggesting a more effortful processing of sensory and cognitive demand of speech. The comprehension performance during both training sessions and across the two blocks is visualized in Fig. 1, while the detailed estimates of the model can be found in Table 1.

The left panel visualizes the difference in performance between auditory and immersive training during the first block, whereby performance does not substantially differ. The right panel visualizes the performance between the auditory and the immersive training in the last block, whereby the performance in the immersive training is significantly higher compared to the auditory training. The change within training is not significantly different (e.g., no significant difference between the first and the last block within each training). The mean performance for each training modality and in each block is marked with a diamond symbol. n.s. = not significant, *p < .05, **p < .01, ***p < .001.
Training-induced change in speech in noise perception
To investigate if a short-term exposure to a multisensory immersive auditory-training session would result in a significant change in more generalized speech in noise perception compared to a mere auditory training session, a linear mixed model was calculated. The model revealed a significant main effect of time (Δχ²(1) = 12.175, p < 0.001), showing significantly lower SRTs after the training compared to before. On average, participants SNR decreased by 0.35 dB after either short-term training compared to before (a decreased SNR is reflecting an improved speech perception in noise, since speech is perceived despite increasing noise). Regarding modality, no significant main effect was revealed (Δχ²(1) = 0.313, p = 0.576), indicating no substantial difference in SNR across the two training sessions. The two-way interaction, however, was significant (Δχ²(1) = 6.111, p = 0.013), indicating a significant difference in SNR change from pre to post as a function of modality. Post-hoc comparisons revealed that SNR significantly improved, but only after the immersive training session (IMpost – IMpre: Δβ = −0.592, SE = 0.135, t = −4.395, p < 0.001, see Fig. 2B), while no significant change in SNR was observed after the auditory training session (AUpost – AUpre: Δβ = −0.118, SE = 0.135, t = -0.875, p = 0.817, see Fig. 2A). Participant’s SRT decreased ~0.6 dB after an immersive training meaning that participants were more tolerant towards background noise, while after an auditory training session the average decrease was only at 0.12 dB. Since everyone participated in both sessions, and the order of training modalities was counterbalanced across each participant, this interaction further supports the assumption of a training-induced improvement speech in noise perception, particularly after an immersive training. The model further contained individual PTA, age, MoCA scoring as well as auditory and visual working memory capacity as control variables. Individual PTA was significantly associated with speech in noise performance (Δχ²(1) = 28.61, p < 0.001), while none of the other variables significantly explained variance in speech in noise performance (p > 0.094). The results regarding training-induced changes are visualized in Fig. 2. The detailed estimates and the final model specification can be found in Table 2.
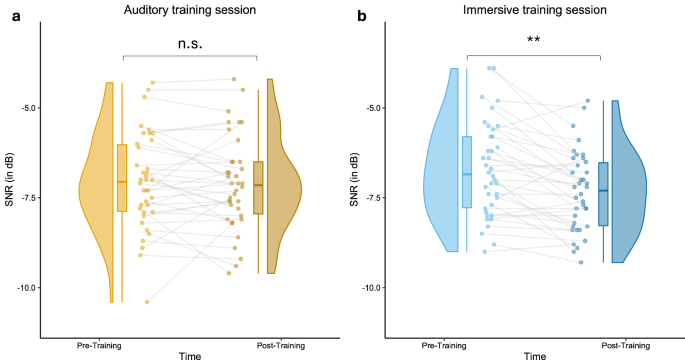
a Individual signal-to-noise ratio did not substantially change after the auditory training session. b Individual signal-to-noise ratio improved significantly after an immersive training session (expressed in more negative SNR).
Moderation through individual variables
After establishing the relationship between SNR and training, we were interested in investigating if the extent of the training-induced change in SNR was moderated by training modality and individual capacities. The change in SNR from pre- to post-training for both training modalities was quantified by subtracting the pre-training SNR from the post-training SNR. A linear mixed model was calculated using this difference as the outcome variable, with training modality, age, MoCA scores, auditory and visual working memory (AWM, VWM) scores, and hearing loss (PTA) included as fixed effects. The model also incorporated interactions between training modality, AWM, and hearing loss. The motivation for this model was to investigate if the extent of change in SNR (e.g., the differential resulting from the subtraction of the post-SNR from the pre-SNR) varied as a function of individual processing capacities and whether this moderation differed across training modalities, indicating who would benefit the most from each modality.
The model revealed a significant main effect of training modality (Δχ²(1) = 18.378, p < 0.001), suggesting a stronger training-induced change in SNR after the immersive training session (e.g., better speech in noise perception) compared to the auditory session. This result reflects the above-described interaction between time and training modality. Neither age, MoCA scores, AWM, VWM nor hearing loss were significantly associated (p > 0.214) with the extent of training-induced change. The three-way interaction between training modality, hearing loss, and auditory working memory was not significant (Δχ²(1) = 0.225, p = 0.635), while the two-way interaction between training modality and auditory working memory was (Δχ²(1) = 9.143, p = 0.002), suggesting a moderation of the training modality induced effect.
Post-hoc pairwise comparisons were conducted using the emmeans package in R51 to explore the interaction between training modality and AWM at specific values of AWM (e.g., at 1 standard deviation above and below the mean of the z-standardized AWM variable). These analyses revealed that in a participant with higher AWM capacity (i.e., 1 SD above the mean), the training-induced change in SNR did not differ significantly between auditory and immersive training sessions. In contrast, a participant with lower AWM capacity (i.e., 1 SD below the mean) experienced a significantly greater improvement in SNR following the immersive training compared to the auditory training (AWM 1 SD below average: ChangeAU – ChangeIM: Δβ = −0.677, SE = 0.148, t = −4.561, p < 0.001). It is important to note that these comparisons were made without grouping participants into high and low AWM categories, as AWM was treated as a continuous variable. The reported estimates reflect hypothetical participants with higher and lower AWM based on these post-hoc tests.
Additionally, the model revealed a significant two-way interaction between training modality and hearing loss (Δχ²(1) = 8.168, p = 0.004). Post-hoc analyses showed that in participants with higher PTA (i.e., PTA 1 SD above the mean), the training-induced change was significantly greater for immersive training compared to auditory training (PTA 1 SD above average: ChangeAU – ChangeIM: Δβ = −0.729, SE = 0.163, t = −4.481, p < 0.001). In contrast, participants with better hearing (i.e., PTA 1 SD below the mean) did not show significant differences in training-induced change across the training modalities (PTA 1 SD below average: ChangeAU – ChangeIM: Δβ = -0.251, SE = 0.148, t = −1.688, p = 0.094). In summary, participants with more hearing loss or reduced auditory working memory capacity benefited more from immersive training, while those with better hearing or higher auditory working memory capacity showed no substantial difference in SNR improvement between training modalities (see Fig. 3A, B). The detailed model estimates are provided in Table 3.
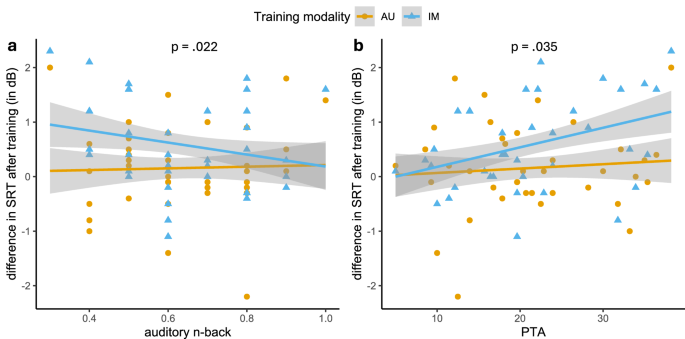
a Individual auditory working memory (quantified by auditory n-back accuracy) significantly moderated the relationship between training-induced change after an immersive training session. Individuals showed stronger improvement in speech in noise perception after an immersive training session, particularly those individuals with lower auditory cognitive working memory capacity. b Individual hearing acuity (quantified by PTA) significantly moderated the relationship between training-induced change after an immersive training session. Particularly individuals with more pronounced hearing loss benefitted from an immersive training session regarding speech in noise perception.
Discussion
In the current study, we investigated potential far-transfer effects of short-term auditory-cognitive training towards speech in noise perception in a sample of older individuals (N = 39), while not particularly training speech in noise perception. Furthermore, individual hearing acuity among the sample was assessed by quantifying individual pure-tone average across 0.5 to 4 kHz, resulting in mild to moderate hearing loss (<40 dB) on average across the frequency range, with a stronger decrease in hearing acuity in the high-frequency range. We investigated if a potential training-induced transfer effect increased in an audiovisual immersive training modality, providing a more real-world listening environment compared to a typical auditory speech presentation modality. Finally, we investigated if potential training-induced changes in speech reception thresholds in noise would be moderated by individual hearing acuity and auditory working memory capacity. As such, the assessed sample was exposed to two training sessions in a cross-over design presented in an auditory- and separately in an audio-visual immersive modality, while the individual 50% speech reception threshold was assessed before and after each training session. The training consisted of a speech-memory paradigm, whereby participants heard natural continuous speech, followed by a comprehension question. The cognitive component of the auditory-cognitive training consisted of varying memory loads of the presented speech material (low vs. high memory load). The results reported in the current study indicate that the individual 50% speech reception threshold in noise decreases, suggesting that participants were able to tolerate higher levels of background noise while maintaining the same level of speech recognition performance after an auditory cognitive training. Furthermore, the data revealed a significant interaction between time and training modality, suggesting a significant improvement in SNR after an immersive training, while no substantial change was observed after an auditory training session. By quantifying the change in SNR after the training, we further were able to establish a relationship between the extent of training-induced improvement and individual sensory and cognitive capacities. To summarize, participants with higher PTA levels (e.g., showing reduced hearing acuity) or lower auditory working memory capacity benefitted particularly from immersive auditory-cognitive training compared to a training session conducted in a mere auditory presentation modality.
The behavioral data from the current study suggested that short-term immersive auditory-cognitive training results in improved speech in noise perception. Our model revealed a significant decrease in speech reception thresholds after a short-term immersive auditory-cognitive training session compared to before, suggesting a training-induced improvement in speech in noise performance. Concurrently, no substantial change in SRTs was observed after the auditory training session, indicating that the observed effects were due to the training and not mere exposure. These results support the idea of creating more naturalistic training environments, including additional sensory information through immersive visualization, to improve speech in noise perception. By creating such multisensory environments and using speech material that reflects the demand of real-world listening more closely, participants need to efficiently distribute processing capacities among sensory and cognitive demand. A training of such efficient allocation might facilitate the perception of speech despite background noise, resulting in better speech in noise perception. Considering this conclusion, two aspects need to be discussed in more detail, namely the advantages of an immersive combined auditory-cognitive training approach over one-sided auditory- or cognitive trainings and the association between efficient resource allocation of sensory and cognitive processing with speech in noise perception. Empirical evidence has demonstrated that auditory trainings have the potential to increase auditory perceptual sensitivity in older normal hearing and hearing-impaired individuals. While on-task improvement is reported to reflect the strongest training effect52,53,54,55,56, more generalized learning effects on untrained objective speech measures have been demonstrated as well17,57,58,59,60,61,62,63. However, beyond mere auditory perceptual sensitivity for tones or syllables, the benefit of auditory trainings for sentence recognition is more ambivalent, whereby some studies do show increase in the trained task62,64,65, while others report no effect66, particularly no far-transfer effects.
Concurrently the idea has been proposed that cognitive training might result in broad improvements reflected in increased speech perception in transfer tasks. Ferguson and Henshaw32 investigated if a commercially available working memory training program, targeting verbal and visuospatial working memory functions, might result in improved speech perception, as previous studies had demonstrated a post-training effect for untrained tasks of attention67, and improved sentence repetition for hearing-impaired children68. While the authors did observe transfer effects to untrained cognitive tasks, no significant effects on speech tasks were reported, corroborating the results from more recent reviews considering auditory- and cognitive training effects33,69. As such, the auditory and cognitive training literature suggests that combined training targeting both sensory and cognitive abilities required for successful speech comprehension might represent the most effective approach to improve speech perception. Considering our training design and the reported results, our data corroborate this notion, showing that the benefit of a combined approach might be extended by including naturalistic speech material and varying cognitive demands, potentially representing more realistic and relevant training material for the listener.
Further support for the conclusion that combined auditory-cognitive training might target elements that reflect more real-world listening abilities resulting in stronger transfer effects, lies in the positive relationship between working memory capacity and speech in noise perception22,23,25,26,27,28,29,30,70,71. While the reported results have been mostly correlational, it has been argued that stronger working memory capacities might compensate for the increased processing demand by enabling more efficient cognitive processing of the perceived information and thereby reducing the ambiguity induced through degraded input30,72,73. With the results from the current study, we can now extend these findings by a direct relationship between immersive auditory-cognitive training that targets particularly the parallel processing of sensory and cognitive demand of speech.
Taken together, we propose that being confronted with an immersive speech task that contains natural speech material and requires cognitive flexibility due to varying memory loads, targets more relevant skills for real-world listening. Furthermore, we speculate that by providing natural speech material and by applying a task that reflects the demands of speech comprehension in more realistic environments, participants perceive the training as more relevant. Our design only allowed to investigate short-term training effects and therefore we cannot establish maintenance effects for speech in noise improvement. However, we believe that by demonstrating a short-term effect and increasing the perceived relevance, the current study provides important insights for future training designs and recommend including more naturalistic training material. Furthermore, we recommend investigating the potential of immersive environments in more detail in future studies. The multisensory environment chosen here served to expand an audio-visual modality while maintaining traditional visual speech cues. A systematic investigation of perceived immersion was not conducted, as the experimental design (e.g., randomization of modalities) might have biased perceived immersion. Nevertheless, we recommend evaluating the degree of immersion experienced in future studies to draw further conclusions about the potential benefits of immersive multisensory training environments.
The reported improvement in speech in noise perception after the training was only significant after the training was conducted in a multisensory environment, providing additional sensory information through the three-dimensional visualization of the speaker. We suggest that the additional sensory information increased the intensity of the training, by elevating the necessary allocation of sensory and cognitive processing resources to complete the comprehension task. Considering multimodality in the context of speech perception, it has been demonstrated extensively that adding visual speech cues to auditory information can result in facilitated target detection and speech recognition in adverse listening situations42,43,44,74,75,76. Considering the interplay between sensory and cognitive load of a given listening situation, the question arises how the multisensory information provided by an immersive environment will be processed in the context of varying cognitive load. The catalyst for this idea can be attributed to the theoretical assumptions from the integrated perceptual-cognitive system theory proposed by Schneider and Pichora-Fuller34. The theory assumes a direct link between sensory and cognitive processing, based on a shared pool of processing resources. The efficient allocation of these resources towards sensory and/or cognitive demand of speech leads to successful comprehension, while increased load or decreased individual capacities limit the potential success. In this context, the position that additional visual speech cues represent a further increase of sensory load rather than support, particularly in favorable listening situations, has been proposed by several empirical works77,78,79,80,81.
In the current study, participants were presented with an auditory-cognitive training in an immersive environment providing additional but potentially redundant sensory information (due to the very favorable listening situation), that had to be processed on top of the auditory and cognitive processing of the speech stream. The immersive environment predominantly increased the (redundant) sensory information, while the supportive role of congruent visual speech cues potentially became secondary. Facing this increased amount of information, we speculate that participants were required to efficiently allocate processing resources towards necessary sensory information, while maintaining sufficient resource availability to meet the cognitive demands (i.e., the varying memory load). By increasing the sensory information, the immersive environment particularly provoked this allocation process, compared to the mere auditory environment, potentially resulting in stronger training-induced improvement in speech in noise perception. Further support for this conclusion is provided by the observed moderation of the interaction between time and modality through individual working memory capacity and hearing loss. The reported results suggest that the decrease in SRTs after an immersive training session is particularly strong for individuals with lower auditory working memory capacity or more pronounced hearing loss. Considering the idea, that additional sensory information provided by the immersive environment might increase the need for resource allocation, we believe that this becomes even stronger when individual capacities are limited (e.g., hearing impairment, lower working memory capacity), resulting in more challenging training. Furthermore, an immersive environment potentially provides additional support by increasing engagement, facilitating focused attention towards the speaker and facilitating audibility through visual speech cues. However, it is important to mention that these results are purely based on behavioral changes in a speech-in-noise task. Future research should further pursue the aim of identifying the allocation of processing resources in the context of sensory and cognitive speech demand, while carefully accounting for individual capacities. Moreover, such investigations could greatly benefit from including neurophysiological correlates to establish potential changes in multisensory integration of speech information in the brain and to investigate potential facilitation of varying cognitive functions, such as attention. Lastly, important additional insight could also be gained from considering subjective perception of training environments, such as the degree of immersion as well as the potential increase in engagement. In the current study, we particularly focused on transfer effects to a more general speech-in-noise task and were not able to draw conclusions regarding maintaining such effects. As such, longitudinal training designs are needed to further evaluate the maintenance of training effects, but also evaluate mechanisms that lead to such training effects.
Furthermore, the question inevitably arises as to when a critical point of such an increased challenge is reached, resulting in overstraining. While this question needs to be further explored, the here presented results provide important insights into future training designs. Including additional sensory information seems to improve the training outcomes through intensifying the training mechanism.
The design of the study provided a short-term intervention and an immediate assessment of potential transfer effects right after the training session, while not allowing to draw any conclusions about motivational aspects or maintenance of observed improvements. A significant decrease in speech reception thresholds (meaning better speech in noise perceptual abilities) was observed after the immersive training (but not after the control training with mere auditory exposure), with a decrease of 0.5 dB on average immediately after the training session. The Netherlands Longitudinal Study on Hearing82 investigated the change in speech reception thresholds over a period of 10 years across multiple age groups within data from 1349 participants. Speech reception thresholds were assessed by presenting three-digit sequences in stationary background noise which had to be repeated by the participants. After adjusting for age, sex, and lifestyle factors, the mean increase in speech reception thresholds across 10 years was estimated to be at 0.89 dB. Considering the age groups, the study revealed a significantly larger decline amongst the older age groups, estimating a decline of 1.69 dB within the age group of 61–70 years. Considering the results from this longitudinal study, particularly the oldest age group which reflects the mean age in our sample, a decrease in speech reception thresholds by 0.5 dB would be approximately the equivalent of reducing the deterioration in speech in noise perception by 3 years. Comparing our data with this existing evidence is promising regarding the effectiveness of a more natural training design. We therefore highly recommend including natural and relatable speech material and multisensory speech presentation in future training studies and particularly focus on the potential and the limitations within such natural designs to establish the optimal degree of challenge for maximizing the benefit.
In the current study, we were able to demonstrate that a short-term immersive auditory-cognitive training, that targets both sensory and cognitive processing in the context of natural continuous speech can result in decreased speech reception thresholds in noise, suggesting a similar speech perception performance while tolerating more noise. This training-induced improvement in speech in noise perception is significant after an immersive training, while no substantial difference in speech in noise perception was observed after the auditory training session. This observation suggests a training effect based on the immersive environment, whereby individuals with more pronounced hearing loss as well as participants with lower auditory working memory capacity appear to gain a particular benefit from an immersive training session. These results demonstrate the potential for training and transfer effects using more naturalistic training environments. Beyond the measured effects of improved speech in noise perception, providing listeners with more multisensory immersive training environments targeting real-world listening potentially also increases the perceived relevance of the training material, ideally resulting in more pronounced training and transfer effects. We strongly recommend that future training designs should consider a more realistic and engaging training environment while designing a training that challenges sensory and cognitive processing in the context of natural continuous speech, to produce the best possible far-transfer effects.
Materials and methods
Sample
The current study included 40 healthy older participants (Mage = 70, RangeAge = 61–80, SDAge = 4.92, male = 20), whereby one participant had to be excluded, as they did not complete both training sessions (auditory and immersive), resulting in a final sample size of 39 participants. None of the participants reported preexisting neurological, psychological, or psychiatric disorders. Furthermore, all participants were native Swiss German speakers with no prior speech or language disorders and had not learned a second language nor were they exposed to a second language in a considerable amount before the age of seven. Participants were right-handed, had normal or corrected-to-normal vision, did not experience hearing loss exceeding left and right ear average pure-tone thresholds of ≥40 dB across the frequencies of .5, 1, 2, and 4 kHz nor did they wear a hearing aid at the time of the data collection. All participants provided written informed consent and were compensated for their participation. The study was conducted ethically, in compliance with the Declaration of Helsinki, and approved by the Ethics Committee of the Faculty of Arts and Social Sciences of the University of Zurich (approval number 22.9.7).
Audiometry
Hearing acuity was measured by pure-tone hearing thresholds separately for both ears across the frequencies of 0.125, 0.25, 0.5, 1, 2, 4, and 8 kHz. The Affinity Compact audiometer (Interacoustics, Middelfart, Denmark), with a DD450 circumaural headset (Radioear, New Eagle, PA, USA) was used to determine individual thresholds at the corresponding frequencies. To define the general hearing acuity, thresholds at each frequency were compared across both ears (<15 dB interaural threshold differences), averaged across both ears, resulting in a single threshold for each frequency and each participant. A total of 11 participants showed interaural differences above 15 dB when presented with pure tones at 8 kHz. However, none of these participants showed speech perception performances below 83% correct, suggesting that the interaural differences at 8 kHz did not interfere with the audibility nor the speech comprehension during the experimental presentation. Lastly, pure-tone average (PTA) across the frequency range of 0.5–4 kHz was calculated by averaging these thresholds for each participant across both ears (MPTA4 = 21.52, RangePTA4 = 5.48–38.21, SDPTA4 = 8.83). Participants were seated in an electrically shielded and sound-treated booth during the audiometric assessment. The individual thresholds of all the participants across the complete frequency range (averaged over both ears) are visualized in Fig. 4.
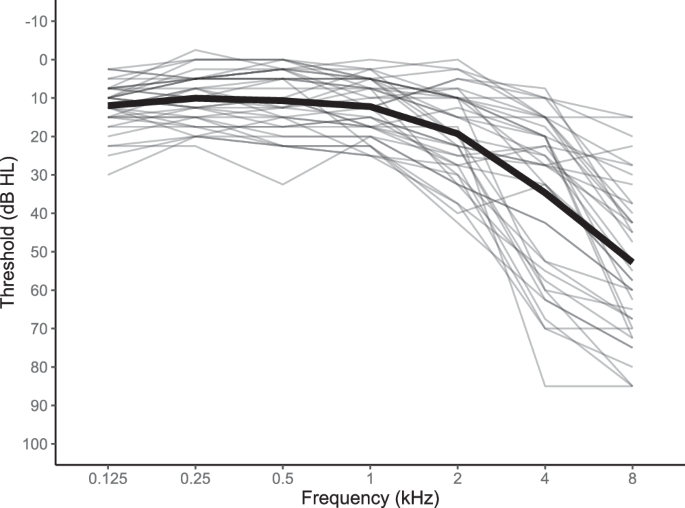
Visualized are individual pure-tone thresholds across the frequency range of 0.125–8 kHz (thresholds were measured separately for each ear and then averaged at frequency, resulting in one line per participant). The mean hearing threshold across the full sample is depicted as a black line.
Speech in noise assessment
To assess individual thresholds of speech in noise comprehension, a German Matrix Sentence Test (Oldenburger Sentence Test OLSA83🙂 was used, which quantifies the 50% speech perception threshold (SRT) for speech in noise. During the test, 20 sentences were presented in speech-shaped background noise, whereby noise levels are at a constant presentation level of 65 dB SPL and the stimulus level was adapted across the 20 sentences to determine the 50% SRT for each participant. For the current study, a female speaker was chosen to present the speech material since the speech material from the training sessions was also presented by a female speaker. The test contains a total of 40 randomized sentence lists (which were randomized across participants, to ensure that no participant was exposed to the same list twice), whereby the sentences follow the same structure (name-verb-number-adjective-object) but are put together randomized from an inventory of ten items per category (e.g., ten different names, ten different verbs etc). To determine the 50% SRT, the SNR at which 50% of the presented words are understood was established. As such, an adaptive procedure described by Brand and Kollmeier84,85 was used. The measurement starts with a signal-to-noise ratio (SNR) of 0 dB. If more than 2 words are correctly understood and repeated, the speech signal was decreased by 0.3 dB, or increased in case of misunderstanding. This procedure was adaptively applied accordingly across the 20 sentences to establish the 50% threshold84. The measurement took place in an electrically shielded and sound-treated booth through a computerized OLSA implementation provided by the Oldenburger Measurement Applications (Hörzentrale Oldenburg, Germany). The Affinity Compact audiometer (Interacoustics, Middelfart, Denmark), with a DD450 circumaural headset (Radioear, New Eagle, PA, USA) was used to present the speech material (identical to the audiometry assessment).
Cognitive screening
The Montreal Cognitive Assessment Score (MoCA, German Version 8.183) was used to establish general cognitive capacity, whereby scores range from 0 to 30 points (higher scores indicate better cognitive capacities). The MoCA is a frequently used screening instrument for mild cognitive impairment (MCI), whereby in the clinical context a performance score of ≤26 points suggests further evaluation for MCI. In the current study, participants were included with a cut-off of ≥23 points, based on a recent review by Carson and colleagues86, suggesting a lower false positive rate. Furthermore, lowering the cut-off allowed for a broader range of cognitive capacity within the sample, which was desired to investigate potential training-induced effects in a representative sample of older individuals with varying cognitive capacities. A total of 11 participants scored below 26 points (MMoCA = 27, RangeMoCA = 23–30, SDMoCA = 2).
Furthermore, working memory capacity was assessed by using a computerized sequential n-back paradigm. In general, the n-back task requires participants to store and update information that has been presented in positions back with a given target stimulus. While this task is frequently used to probe working-memory functions87, it is important to highlight that it does not fully reflect working memory capacity, but rather updating and maintaining information. However, these specific aspects of working memory are important for speech perception, particularly in the context of natural speech, which is why we used this task to assess working memory capacity. Furthermore, we chose to assess working memory accuracy in both visual and auditory modalities, as these reflect two important elements of the training sessions. However, considering the used outcome measure, namely the speech in noise task, we expected to find a stronger relationship between auditory working memory capacity and training-induced effects. As has been shown in previous studies, modality-specific auditory working memory capacity appears to have the potential to explain variance in speech perception in noisy environments88,89,90. The presented n-back task included two modalities (visual and auditory), which were administered in a counterbalanced order across participants. Colored squares were used as visual stimuli, presented on a white screen (~50 cm distance between screen and eyes), while spoken German letters were used for the auditory n-back task. The letters were spoken by a male voice via an RME Fireface UCX II audio interface (RME, Haimhausen, Germany) and delivered through ER-1 insert headphones (Etymotic Research, Elk Grove Village, USA) at a fixed presentation level of 70 dB. To ensure that working memory performance was not affected by individual hearing loss, spearman Rank’s correlation was used to evaluate the relationship. While there was a trend, indicating reduced n-back performance, the correlation was not significant (r(37) = −0.31, p = 0.061). The relationship between n-back performance and PTA4 is visualized in Fig. 5. A total of three levels of difficulty were assessed (0-, 1-, and 2-back), whereby the blocks containing the difficulty levels (a total of 40 items for each block) were randomized. At the beginning of the task a general verbal instruction was provided for the participants and before each block, an additional written instruction was given regarding the following n-back level. In general, participants had to respond whenever the current stimuli matched the one presented n positions back. Within the 0-back control condition, participants were instructed with a target stimulus and had to respond whenever the target was presented. Before the start of each modality, a practice trial was administered to ensure that the participants had understood the task properly. The presentation rate was set to 2.5 s (stimulus length, 500 ms; interstimulus interval, 2000 ms). The n-back task was programmed and presented through the Presentation® software (version 23.0, Neurobehavioral Systems, Inc., Berkeley, CA). The completion of the n-back assessment took approximately 10 min (including both modalities and practice rounds). From the obtained data, n-back accuracy for the 2-back condition was used for auditory working memory capacity (MAWM = 0.63, RangeAWM = 0.2–1, SDAWM = 0.18) and visual working memory capacity (MVWM = 0.47, RangeVWM = 0.1–0.9, SDVWM = 0.17) as a primary indicator for auditory- and visual working memory.
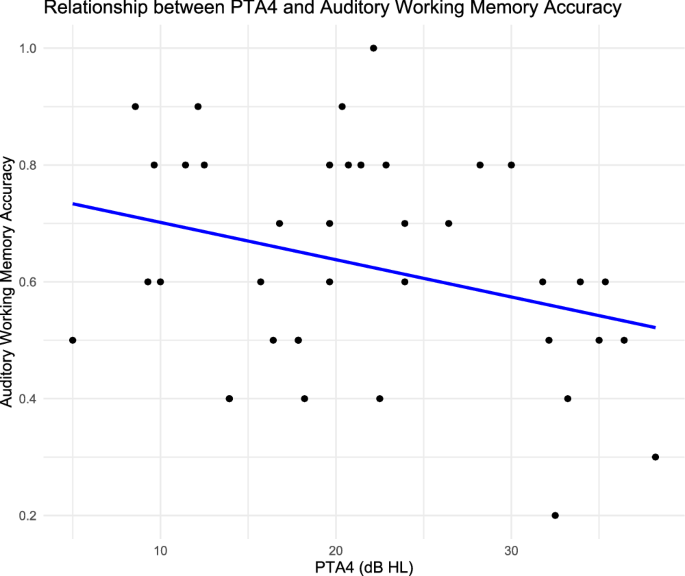
While the data does show a trend, suggesting reduced n-back performance with more hearing loss, the correlation does not become significant.
Procedure
Participants were invited to the laboratory a total of three times. During the first appointment, the screening assessment was conducted, including a general health questionnaire, audiometry, and the cognitive screening. The second and third appointment consisted of training sessions. Each participant performed two trainings which were randomized using a cross-over design: One session took place in an auditory modality (AU) and one session in an immersive audio-visual modality (IM). The training sessions were conducted one week apart, at the same time of day to minimize fatigue and daytime perception effects. Both training sessions were generally identical regarding the procedure. First, the OLSA was performed to determine the pre-training 50% SRT. In the next step, participants received verbal instruction regarding the following task. After ensuring that participants fully understood the assignment, the training session was started, which approximately had a duration of 40–45 min. After the training session, the post-training 50% SRT was assessed by repeating the OLSA. Exactly one week later and at the same time of day the second training session took place. The training sessions were conducted in a sound-treated booth.
Auditory-cognitive training: auditory (AU) and audio-visual immersive (IM) approach
The AU and IM approach used the same training task and consisted of a speech-memory task, whereby participants were presented with natural continuous sentences with varying memory loads and were required to answer a comprehension question after each sentence. The questions were presented visually, and the participants had to answer the questions verbally, while their answer was recorded by a microphone and evaluated by the experimenter. Also, the speech material for AU and IM was presented using an RME Fireface UCX II audio interface (RME, Haimhausen, Germany) and delivered through ER-1 insert headphones (Etymotic Research, Elk Grove Village, USA) at a normalized sound pressure level (SPL) of 70 dB to ensure audibility. The presentation level was measured with a Brüel & Kjær Type 4157 ear simulator, the signal from which was analyzed with a Brüel & Kjær LAN XI Type 3677 acquisition system (Brüel & Kjær, Virum, Denmark). While during the AU training, speech material was presented through headphones, and questions were displayed on a computer screen, the IM training session was accompanied by a congruent visualization of the speaker.
As such, a stereoscopic, three-dimensional video of the speaker was presented through an HP Reverb G2 virtual reality head-mounted display (HMD). To ensure high-quality resolution, the HMD displayed a visual on 2160 × 2160 LCD panels per eye through 9.3-million-pixel resolution. A stereoscopic video displays a realistic recording of an environment, while displayed through an HMD, which allows to perceive the portrayed scenario in three dimensions and across 180° for the viewer. To create such recordings, the speaker was filmed using a Canon EOS R5 Camera, with 45-megapixel resolution combined with the RF 5.2 mm L Dual Fisheye camera lens, with 190°-angled perspective to capture a 180° immersive visual. The recording of the speaker took place in a professional film studio at the University of Zurich. The recordings showed the speaker sitting in a chair, with the camera placed at head level (eliciting a viewer’s perspective as if one is sitting across from the speaker). The speaker was placed in a neutral room, to minimize environmental distractions. By presenting this recording through the HMD, the participants were able to move their head around the room to perceive 180° and realistic depth perception of the speaker across them, which induced a highly immersive experience. The training procedure, including a two-dimensional visualization of the immersive setup, can be found in Fig. 6.
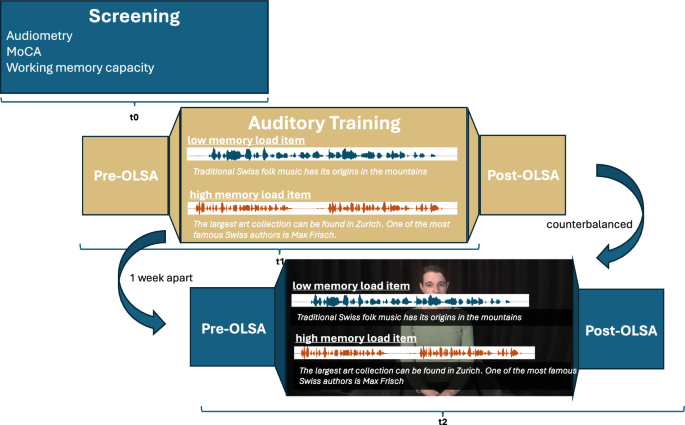
Participants were invited a total of three times to the laboratory, starting off with a screening session, followed by two training sessions. The order of the training modality was counterbalanced across participants and scheduled one week apart at the same time of day.
Speech material and cognitive load
During the auditory-cognitive training participants were required to listen to sentences and answer comprehension questions regarding the heard content. The presented speech material was spoken by a trained actress (who was also visualized during the immersive training) in standard German. The average speech rate was 4.34 syllables per second (ranging from 3.46 to 4.93), which was determined using the Jong and Wempe91 algorithm for syllable nuclei detection in Praat (version 6.1.40). Speech material content consisted of 10 different thematic blocks, including different aspects of general knowledge assumed to be generally interesting (topics: Flora, Fauna, Culinary, Swiss History, Transportation, Geography, Culture, Traditions, Economy, General Knowledge). While we are aware, that presenting general knowledge might bias speech comprehension performance due to existing knowledge by the participants, we wanted to present realistic speech material. In real-life listening situations, listeners are usually confronted with speech material that is to a certain degree known, while other aspects might be unfamiliar. To investigate if naturalistic training might induce far-transfer effects, we deemed this speech material as appropriate, since it reflects naturalistic speech content. A total of 120 speech items were presented, whereby 60 items consisted of one sentence (~9.02 s duration on average), representing low memory load items, and 60 items consisted of two sentences (~17.65 s duration on average), representing high memory load items. In each training session, a total of 60 items were presented (30 low- and 30 high memory load items). The order of these items was randomized across training sessions and each item was presented to the participant only once (reducing the potential for training effects). The variation of the memory load within the presented speech material reflects the cognitive component of the training sessions and is generally based on the natural requirements reflected by real-life listening situations. However, by varying between one- and two sentences, we aimed to ensure a systematic variation within this manipulation. After each item, a comprehension question was presented which participants had to answer verbally (the answer was recorded using a microphone and used to quantify behavioral performance). Only one correct answer was possible, while a verbal answering format was chosen to minimize cognitive demands related to answering and generating a more natural response situation. To ensure that high memory load elicited more cognitive load, the questions corresponding to those items always referred to the first heard sentence. To control that participants did not develop a listening strategy and only focus on the first sentence in all trials, after every 10th trial a mock item was presented, which consisted of a high memory load item, but the question referred to the second sentence. Due to the randomization across each training sessions participants were not aware as to when a mock trial would be presented. To familiarize and ensure task understanding, each session started with five practice trials.
Statistical analysis
Training-induced change in speech in noise perception
To estimate if a brief training exposure might induce training-related changes in speech in noise perception, a linear mixed model was conducted with individual SRTs of all the OLSA assessments as continuous outcome variables. For computing linear mixed models, the lme4 package was used92. All statistical analyses were conducted in R (R version 4.1.2 (2021-11-01)). The model contained fixed effects of time (categorical variable with two levels: Pre-training and post-training) and fixed effects of training modality (categorical variable with two levels: Auditory Training and Immersive Training). Additionally, the model included age, MoCA scores, auditory and visual working memory scores as well as individual PTAs as continuous control variables (all z-standardized). Lastly, the model contained by-subject random intercepts and slopes. To avoid overparameterization, non-convergence, and singular fit, a model with a maximum random effects structure was estimated93 and iteratively adjusted until a non-singular fit was achieved. This process includes estimating a model with a maximal random effect structure and reducing this structure (by first omitting interactions across random effects and subsequently omitting random slopes with the lowest explanation of variance). Using the formula notation in R, the maximum model was defined by the following specification:
As interaction terms were present in the model, we used an orthogonal sum-to-zero coding scheme, which allows to estimate the main effects at the grand mean level and interpret them as such, while also allowing to interpret the interaction. Likelihood ratio tests were used for statistical interference, comparing an encompassing model with a reduced model. For the final model, restricted maximum likelihood was used, while degrees of freedom and associated p-values were estimated using Satterthwaite’s method of approximation.
Moderation through individual capacities
To investigate if a potential training-induced effect can be moderated by individual sensory and cognitive capacity, we conducted an additional analysis. The aim was to test if the amount of change differed regarding individual capacities and presentation modality. Therefore, we quantified the change in SRT from pre- to post training for both training sessions, resulting in a single value for each participant in each training. A positive value indicates an increase in SRT (e.g., pre-SRT: −5 dB, post-SRT: −7 dB, difference: 2 dB; Therefore, the SRT increased by 2 dB), a negative value indicates a decrease, and values close to zero indicate no substantial change after the training. This differential served as the response variable for an additional linear mixed model, which was computed to estimate if training modality or individual variables might influence the extent of training-induced change. The model contained the fixed effects of training modality (AU and IM), as well as age, MoCA scores, auditory & visual working memory accuracy (AWMz, VMWz) and hearing acuity (expressed by PTAz). Furthermore, we included a three-way interaction between modality, PTAz, and AWMz, as we were interested in potential moderation effects. Otherwise, the same model estimation steps were applied as has been described above. Using the formula notation in R, the maximum model was defined by the following specification:
The custom scripts generated for the statistical analysis described in the methods section are provided in the study’s Open Science Framework repository (https://osf.io/brxmg/ scripts will be provided in case of acceptance).

Responses