Implementing large language models in healthcare while balancing control, collaboration, costs and security

Integration of LLMs in healthcare infrastructure
Large Language Models (LLMs) and other AI systems are expected to have a considerable impact on future healthcare1. While the pace of development and progress in the field is remarkable, it is crucial to be aware of fundamental limitations as well as technical, ethical and regulatory challenges2. A controlled usage framework is necessary to ensure accountability and compliance with ethical and privacy standards when handling sensitive medical data. LLMs have been shown to be useful in various clinical tasks, including writing clinical letters3, clinical decision-support4, extracting information from unstructured medical text5, medical education6, and screening medical literature7. Overall, LLMs and agentic AI are rapidly becoming integral to healthcare infrastructure.
The current transition phase of integrating LLMs into clinical practice is critical, as generative AI represents a transformative technology that differs in certain ways from traditional information systems. The implementation of LLMs is particularly challenging, as it requires high-performance computational hardware to run the models and specialized expertise for adjustment to individual use cases. Moreover, the inherently unpredictable nature of generative AI behavior necessitates careful and cautious application in healthcare settings. In principle, the output of an LLM depends on multiple factors, including its training data, architecture, input prompt, and model parameters. Without specific safeguards, there is a risk of models generating inaccurate statements that may appear to be based on real-world facts, a phenomenon known as “AI hallucinations”8. Furthermore, as the output of generative AI is directly linked to the training data, models may adopt unwanted features such as gender or ethnic biases9,10, or may make clinically harmful recommendations. Anticipating and mitigating such undesirable behaviors remains a major challenge.
Defining access and control over LLMs is therefore vital for ensuring stability, data security, and accountability. Different levels of openness can be distinguished for LLMs: open-source code, open training data, and open model (with downloadable and reusable weights). The greatest level of user control over a model is achieved when all three forms of openness are available, and users can adjust model outputs directly on their own systems. However, state-of-the-art models offered by private companies often do not provide these levels of openness.
Closed vs. open LLMs
Closed LLMs provided by major tech companies are usually accessible via direct web interfaces or APIs (Fig. 1a). These companies may offer control mechanisms such as “stable releases” which enable the user to depend on stability in model performance for a given release, and customizable frameworks or enterprise solutions addressing concerns around data privacy and data leakage11,12. State-of-the-art LLMs, including the ChatGPT models by OpenAI, Claude by Anthropic, and Gemini by Google, offer remarkable capabilities13. For healthcare facilities with limited resources, applying these state-of-the-art models via the provided APIs can be a convenient and straightforward approach to test LLMs within clinical workflows. Arguments for their implementation include rapid deployment and scalability while outsourcing support and maintenance. Furthermore, the cost of using these closed models via API calls might be more manageable than investing in the hardware and personnel required for customizing and maintaining in-house systems. Since the field is rapidly evolving, a deployed system needs to be constantly updated and maintained to keep up with the latest developments. Notably, many electronic health record (EHR) providers, such as EPIC or Oracle Cerner, are already implementing or have announced plans to imminently implement LLMs via this route14. If the same models are used across the healthcare landscape, this furthermore enhances interoperability and might allow for seamless integration across different systems and providers.

a A closed LLM runs on an external server of a private company. The LLM is controlled by the commercial partner. b An open LLM runs within the local environment of the healthcare facility. Private companies may be referred to for setting up and maintaining the local infrastructure. The LLM is controlled by the healthcare facility.
While using such solutions has some clear advantages, this convenience may come with potential risks, such as data leakages and dependency on external entities. Having to rely on external vendors can limit the control that healthcare facilities have over their own data and AI infrastructure. This dependency can lead to challenges related to data sovereignty and vendor lock-in, where the institution becomes reliant on a single provider for its AI needs, rendering a healthcare facility incapacitated in mitigating changes in the AI-provider’s policies, pricing, or service availability, which may directly impact the facility’s operations, depending on the degree of AI implementation.
Data privacy and security are also critical concerns when using a closed LLM via API. Transmitting sensitive patient data to external servers, even in pseudonymized or partially anonymized formats, raises the risk of data breaches and unauthorized access. The damage of such data breaches can have severe consequences, potentially affecting millions of individuals15. A recent analysis by Pool et al. investigated factors contributing to failed protection of personal health data and identified data protection failure in third-party sources as well as organizational characteristics as two of the main data breach facilitators16. There have been several incidents of data breaches of LLM-providers showing that such a risk is not a merely hypothetical problem17. While many facilities implement strong privacy policies and security protocols, transferring sensitive EHR data to external servers inherently increases the risk of unauthorized access or reidentification as complete anonymization in most clinical settings is not possible18. Closed models are in principle black boxes, making it difficult to ascertain how data is processed or stored. In general, ensuring compliance with stringent healthcare regulations, such as the Health Insurance Portability and Accountability Act or the General Data Protection Regulation, can be more challenging when data is processed and stored outside the institution’s control.
In contrast, in-house implementation of open LLMs offers a different set of benefits and challenges (Fig. 1b). One of the most considerable advantages is the level of control that healthcare facilities can maintain over their AI systems. By using openly available models, institutions can host and manage LLMs within their own secure environments, minimizing the risks associated with data privacy and security. Of course, data breaches remain possible, as the AI infrastructure’s security ultimately depends on the robustness of the overall IT infrastructure in which it is deployed. While also other problems like inherent model biases, misinformation and hallucinations cannot directly be avoided, they can at least be mitigated if model, source code and training data are open-source and therefore transparent.
Furthermore, running LLMs on an institution’s local hardware facilitates additional control mechanisms like adaptation of the source code, and implementation of systems to better manage, interpret, or constrain the output of the model (e.g., via frameworks and libraries like LangChain19 or Guidance20), and embedding custom logging and monitoring solutions to track usage and compliance with ethical guidelines, privacy requirements, and organizational standards.
This approach also allows for greater customization, enabling healthcare facilities to optimize the models specifically for their local context, clinical needs, and workflows.
The relationship between collaboration and control among stakeholders
Investing in the creation and maintenance of a local AI infrastructure can also foster innovation and collaboration. The open-source community is often vibrant and active, with researchers and developers continually contributing improvements and new features based on clinical or academic requirements in a bottom-up approach21. This collaborative environment can accelerate the development of specialized models that are better suited to the unique demands of healthcare applications. Additionally, the higher level of transparency when using open models can enhance trust and accountability, when the underlying algorithms, training data, and data processing methods are openly available for scrutiny.
Healthcare facilities may still refer to private companies with expertise in machine learning to set up and maintain local infrastructure, but ultimately keep full control over the models and the data (Fig. 1b).
Leading AI companies are often not primarily involved in healthcare but may also participate in collaboration to harness the technological potential for medicine. While AI is already transforming various sectors, its application in healthcare is particularly promising and important for society, as it offers the potential to alleviate human suffering and save many lives.
For instance, researchers at the Dana Faber Cancer Institute in Boston successfully implemented GPT-4 with support from Microsoft’s Azure OpenAI teams13. They shared their work including source code and documentation, under an open-source license, demonstrating the potential of collaborative efforts22. Microsoft has also joined a consortium of healthcare leaders to form the Trustworthy & Responsible AI Network, aiming to operationalize responsible AI principles in healthcare23.
Achieving the best patient outcomes through LLMs and other forms of generative AI requires high levels of expertise in both machine learning and healthcare. Collaboration is therefore essential. However, it is important to define the delicate relationship between collaboration among stakeholders and control over AI infrastructure. Clinicians must be actively involved in integrating these powerful technologies. While they cannot be expected to fully grasp the technical intricacies of machine learning, over-reliance on proprietary solutions should be avoided. Simultaneously, machine learning experts require clinical input to ensure LLM-based systems meet real-world requirements and ultimately lead to the best possible outcome for patients. Thus, for the best outcomes, clinicians and technical experts need to work closely together.
The initial setup and ongoing maintenance of a local institutional infrastructure are resource-intensive, requiring investment in hardware, software, and skilled personnel. While the long-term costs of a closed solution might ultimately come to the same amount, these are often incurred after the implementation has started delivering the anticipated value and therefore can be mitigated, while in contrast the upfront costs and effort associated with open solutions can be a barrier for some institutions. With closed solutions part of the control is given to external stakeholders. Yet, the burden of managing and maintaining the AI infrastructure is higher if healthcare facilities have to set up and maintain their own models.
Consideration of tasks, scenarios, and solutions when deploying LLMs in healthcare
The technical requirements of an LLM-based system can vary depending on the specific task for which LLMs are used. A key consideration is whether sensitive data is needed and, if so, what type, as data privacy concerns and potential breaches become more pressing. Moreover, the technical requirements vary depending on the intended task. An LLM used in a general form, such as a basic chatbot (like in web interfaces such as ChatGPT or Gemini), has different needs compared to an LLM integrated into a sophisticated system where additional data is incorporated, and the output may require direct modulation or post-processing.
In the case of an educational chatbot, where an LLM provides general information on medical topics (e.g., asking, ‘How does an MRI work?’), sensitive data typically does not need to be shared, and no complex frameworks are required. In contrast, tasks like extracting structured data from clinical notes to analyze or classify individual medical cases or provide clinical decision support rely on personal patient data and may require a sophisticated framework where the LLM performs specific, well-defined actions. Figure 2 schematically illustrates various tasks, based on their technical requirements and the level of sensitive data involved. Of course, independent of the tasks, the issues of model biases, hallucinations, data breaches, and model dependence remain and may be more or less problematic depending on the scenario and on the specific model weaknesses.
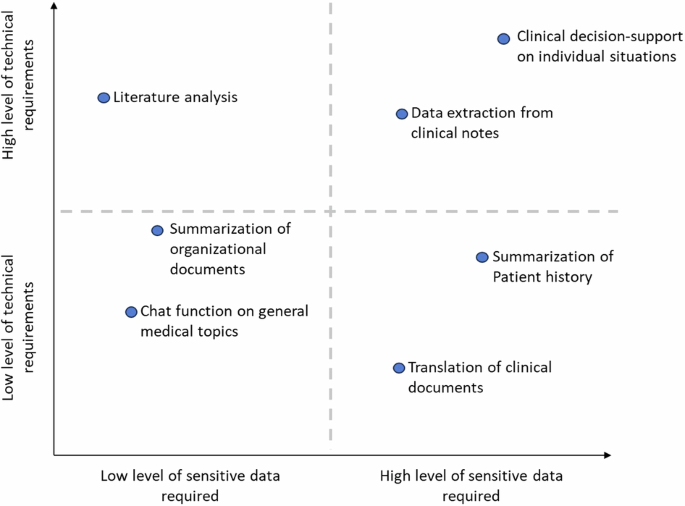
Schematic illustration of various clinical tasks where LLMs may be utilized, based on the level of sensitive data required and level of technical requirements.
In principle, both open and closed frameworks can be applied across various tasks. On the one hand, when using an LLM on an institution’s own hardware, the output of a model can be constrained or analyzed using dedicated frameworks. On the other hand, private companies may offer functionalities to structure the output of an LLM24. While open LLM systems may offer greater technical control, the solutions provided by private companies through APIs may be entirely sufficient for certain use cases. Depending on the specific application, it may be more practical to use an open-source LLM in an integrated environment or an API-based LLM from a private company.
When deploying LLMs in healthcare, numerous factors must be considered, as the technology is still emerging, and proven solutions are not yet fully defined. In countries with centralized healthcare systems, such as France or the UK, establishing a national AI health infrastructure may be an interesting and advantageous option. This approach could involve creating a centralized AI platform to enable secure data sharing and access, developing standardized national datasets to address biases transparently and enhance model reliability, and maintaining a public repository of validated AI models and weights. Additionally, it could provide computing resources to run these models, with API access available to national healthcare institutions.
Furthermore, a strict, one-time decision between open or closed LLM frameworks may not be practical, as the suitability of each depends on the specific context or task. In some cases, even hybrid systems could be the most effective solution. Additionally, the distinction between open and closed frameworks can be blurred by systems like cloud services, where open-source models are hosted on private company servers and accessed via API (e.g., ref. 25). Using such a setup can be useful when hardware resources are limited, while still enabling the use of models with transparent training data, design, and architecture and to address data security.
Clinicians must take an active role in defining the role of LLMs and AI agents in medicine
Overall, numerous factors, challenges, and benefits must be considered when implementing LLMs and other forms of generative AI in healthcare. It is essential for clinicians to be aware of these considerations and to actively engage in the discussion.
While using closed LLMs via APIs offers convenience and access to powerful models, healthcare facilities should carefully consider the benefits of maintaining a higher level of control over their AI systems by using open models. The overall topic of using LLMs and AI agents is relatively new and evolving26. Collaboration among clinicians, researchers, technicians, and commercial partners is essential to ensure that these technologies enhance patient care and uphold ethical standards. Now is the time to do this. Patient safety, data privacy, and ethical considerations must remain priorities. Rigorous testing and validation of systems, along with continuous education for healthcare professionals, are necessary for effective implementation.
In summary, the adoption of LLMs in healthcare is transformative. By defining the needed requirements from a clinical perspective and consciously participating in the discussion on how LLMs should be implemented, we can ensure generative AI is responsibly used in healthcare. Here private companies could play a crucial role in accompanying the deployment of open LLMs and warehousing in clinical environments, contributing frameworks for software development, regulatory compliance, and data security. This way it can be ensured that LLMs are not only effective but also safe and reliable for medical use. Companies could collaborate with healthcare providers to customize and integrate these models into existing workflows, addressing specific needs such as diagnostics, treatment planning, and patient monitoring. We as a community should be wary of one-size-fits-all all approaches, especially if standards of safety remain undefined and data structures unresolved. Let us lay the foundation for the wealth of exciting applications yet to be discovered.


Responses