Integrating machine learning into business and management in the age of artificial intelligence

Introduction
Machine Learning (ML), a facet of artificial intelligence (AI), utilizes computational methods to boost system performance by learning from experience, underpinned by mathematics, statistics, and computer science (Zhou 2021). Arthur Samuel of IBM coined the term in 1959, defining it as the study of enabling computers to learn without explicit programming. In the past, solving computer-based problems required intricate algorithm development, often posing significant challenges. In contrast, ML empowers programmers to craft problem-specific learning algorithms, enabling computers to autonomously acquire knowledge. Here, the machine leverages data and the algorithm’s learning framework to construct effective problem-solving models.
Throughout history, the concept of enabling computers to learn has taken on various names, including pattern recognition, data mining, knowledge discovery, predictive analytics, statistical modelling, adaptive systems, data science, and self-organizing systems. In this work, we broadly categorize these concepts as ML. Scholars have made significant contributions to the field of machine learning (ML) in business administration. ML applications in this area are well-established and have evolved across various domains. For instance, Wenzel et al. (2019) explored ML’s role in supply chain management (SCM), while Paschek et al. (2017) highlighted its adoption in business process management (BPM) and digital transformation within enterprises. Pallathadka et al. (2023) discussed ML’s impact on agriculture, healthcare, and management, among others. In risk management, ML has been extensively examined, as evidenced by Aziz and Dowling (2019) and Bertolini et al. (2021). The literature also covers ML’s integration in marketing (Ngai and Wu, 2022), human resources management (Menon et al. 2024), and Industry 4.0 processes (Bertolini et al. 2021).
While studies highlight practical applications, they also acknowledge limitations. For example, Wenzel et al. (2019) provided an extensive overview of ML methods in SCM but noted gaps in the business, data understanding, and evaluation phases. Kraus et al. (2020) pointed out limitations in deep learning, such as extensive tuning requirements and challenges in modelling behaviours. Non-technical limitations in risk management, including data access barriers and lack of transparency, were emphasized by Aziz and Dowling (2019).
Although these studies advance our understanding of ML in business processes, there is still a need for a comprehensive taxonomy or overview of ML applications across all fields of business administration. The literature has provided in-depth insights into specific areas like marketing and supply chain, but a broader study visualizing ML applications in various business domains is lacking. Hence, this study uniquely contributes to the literature by providing a comprehensive taxonomy of machine learning applications across all fields of business administration, an area previously lacking holistic analysis.
Moreover, the contemporary surge in ML applications, exemplified by the exponential growth of the user base witnessed by ChatGPT since its launch on November 20, 2022 (Hu 2023), has sparked inquiries encompassing ethical considerations, usability concerns, and the anticipated impact of ML and AI across various industries. Notably, one significant enquiry revolves around the transformation of existing business models and process optimization within the domain of business and management. Yet, the fusion of artificial intelligence and algorithm development for process optimization, enhanced decision-making, and streamlined data management within companies is not new and, as pointed out before has been in progress for years.
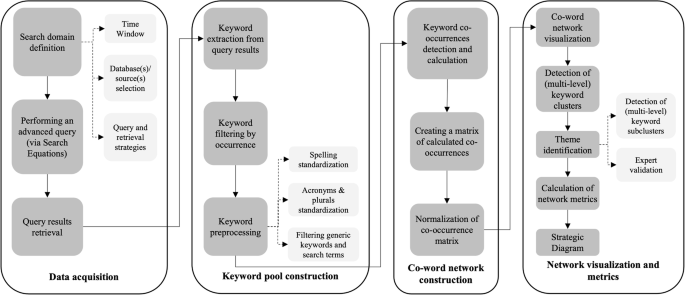
Hence, our research aims to holistically examine the multifaceted applications of ML in the business and management domains, shedding light on emerging thematic areas at the forefront of this dynamic landscape. To achieve this, we analyse scientific and academic publications spanning the past decades in this field. Employing co-word analysis, a bibliometric algorithm with a proven track record in unveiling salient topics and themes (Callon et al. 1991; van Eck and Waltman, 2007), we aim to construct a comprehensive map of the subject. Our curated database provides a valuable foundation for addressing three pivotal research questions:
-
1.
How is the intellectual landscape of machine learning in business and management research organized and structured?
-
2.
What are the primary applications of machine learning in business administration?
-
3.
What strategic considerations should companies adopt to effectively leverage machine learning in their business applications?
The first question seeks to map out and categorize the various research themes and areas where machine learning is applied within the fields of business and management. It aims to provide a comprehensive overview of the current state of academic research in this domain. Consequently, the second question aims to identify and describe the key areas where machine learning techniques are being effectively utilized in business administration, highlighting practical implementations and their impact on business processes. Lastly, the third question seeks to explore the critical factors and best practices that companies need to consider to successfully integrate machine learning technologies into their business operations. It covers aspects such as technological infrastructure, skill development, data management, ethical considerations, and organizational change.
To address the research questions outlined above, we first retrieved scholarly articles and papers related to machine learning in Business and Management from the SCOPUS database—which encompasses a comprehensive collection of highly ranked, peer-reviewed journals—as detailed in the “Methods” section. We then applied co-word analysis to construct a network based on the authors’ keywords extracted from these publications, enabling the identification of clusters formed by the co-occurrence of keyword pairs within individual articles. As elaborated in the “Results” section, this analysis revealed 15 distinct clusters, each representing a unique domain where machine learning techniques are applied. These clusters were plotted on a strategic diagram according to their centrality and density metrics, facilitating the detection of mainstream areas, emerging themes, and domains declining in relevance. Finally, to present a comprehensive taxonomy of machine learning applications in the field of business and management, we consolidated these clusters into five major macro-topics: finance, customer relationship management, decision-making support, innovation and public policy, and data management and sustainability. This taxonomy provides a valuable foundation for future research endeavours and practical implementations, reflecting the current state of how machine learning and artificial intelligence are reshaping business landscapes.
Methods
To answer our research questions effectively, we utilize co-word analysis to examine the interplay between ML and the fields of Business and Management. This analysis relies on academic and scientific papers found in citation databases, assuming that the keywords selected by the authors accurately represent the essence of their research (Callon et al. 1991). In Fig. 1 we provide a detailed overview of our methodological approach for conducting co-word analysis.

Source: Author’s own elaboration.
Data acquisition
Our approach begins with the systematic retrieval of scientific literature on ML in the context of Business and Management. We use the SCOPUS database, which indexes high-quality and highly-ranked journals, and most papers indexed by the Web of Science databases and collections are already indexed by SCOPUS (Singh et al. 2021). As of August 2022, the literature indexed by SCOPUS, published from 2000 onwards, consists of 6940 articles and 2459 conference papers written in English, for a total of 9399 peer-reviewed documents found by the search query (1), and limited to business and management (4834), economics and finance (2422), decision sciences (3074), and social sciences (3158) outlets. Data retrieved for each paper was stored in CSV files, including author names, keywords and affiliations, titles and abstracts, number of citations, and references.

The SCOPUS search query (1) focuses on ML and eleven related concepts and techniques, namely reinforced learning, supervised and unsupervised learning, dimensionality reduction, clustering, anomaly detection, structured and unstructured prediction, deep learning (DL), artificial neural networks, and data mining. No additional restrictions were set at this point, domain-wise.
The work of Kemper et al. (1983) is one of the earliest use cases of ML in business and management. Hierarchical clustering (HC) and multidimensional scaling (MDS), two ML approaches, were used in this study to examine tourism as a cultural domain (Kemper et al. 1983). From then on, different ML applications in tourism have been studied by academia. Conversely, pioneer ML applications in finance can be found in the early 1990s (Kaastra and Boyd, 1996). Figure 2 depicts the distribution of retrieved articles over time and demonstrates that 5077 out of 9399 manuscripts, or more than half, have been published since 2018. The growing trend shown over the past 4 years is anticipated to continue.
Source: Author’s own elaboration.
Keyword pool and network construction
From the literature gathered using the search query (1), we initially extracted 22,103 author keywords, following which we refined the dataset by excluding keywords that appeared in fewer than four papers, aligning with Zhao et al.‘s recommendations (2018, p. 3). Using the VOSViewer Software (Waltman et al. 2010) and its Thesaurus File functionality, which is used to replace, merge, or remove author keywords, we performed the following preprocessing tasks over the keyword pool: (1) singulars and plurals were standardized (e.g. sensor → sensors), (2) British spellings were merged with their American equivalents (e.g. consumer behaviour → Consumer Behaviour), (3) abbreviations were expanded (e.g. DNN → deep neural network, CART → classification and regression trees), (4) research-related terms were removed (e.g. questionnaire, systematic review), (5) as well as geographical references, (6) the terms employed in the search query were removed, and (7) hyphenated expressions were normalized (e.g. energy-efficient → energy Efficient), resulting in 1162 keywords overall, with 1156 co-occurring in the retrieved papers. A co-occurrence matrix was then constructed, and these co-occurrences were normalized using Noack’s LinLog method (2007).
Network visualization
From the pre-processed keyword pool in its normalized co-occurrence matrix form, the co-word network was elaborated with the VOSviewer software. This network is depicted as an undirected graph (co-word graph), where the nodes represent author keywords, and the edges their co-occurrences. Therefore, bigger nodes depict higher keyword appearances in retrieved papers (that is, keyword frequencies), and thicker nodes depict more frequent keyword co-occurrences (that is, link strengths).
As the Visualization of Similarities (van Eck and Waltman, 2007) approach built into VOSViewer allows for a simultaneous depiction of co-word networks (VOS mapping) and community detection of keyword groups (VOS clustering), fifteen groups, or clusters of ML in business and management, were detected using the Modularity variant of VOS mapping based on the work of Newman and Girvan (2004), with Attraction and Repulsion parameters set to 1 and −1, respectively. The Attraction and Repulsion parameters are used by VOS mapping to find the optimal location of each keyword in the co-word graph based on their frequencies and co-occurrences (Waltman et al. 2010), and are mostly used to improve the readability of the co-word graph. Furthermore, the clustering Resolution is involved in this stage as a third parameter, where higher values would reveal more, smaller clusters at the expense of interpretation. The default Resolution value of 1.0 is sufficient in most cases to reveal coherent clusters. In ours, however, a higher value of 1.5 was investigated, and after evaluating the separation and semantic coherence of revealed clusters, by reviewing the keywords with the most co-occurrences in each, we opted for this value, as it yielded better clusters than those found with Resolution 1.0.
Cluster metrics and trends
From the co-word graph and keyword clusters revealed by VOSviewer, two metrics of interest can be obtained, namely Cluster Centrality and Cluster Density. VOSViewer, however, lacks the required functionality to calculate these metrics within the software. Hence, we developed a computer script for extracting the required data from VOSViewer outputs to calculate both centralities, each defined as follows:
-
Cluster centrality for a given cluster L –({C}_{L})–, as modelled by Eq. (2), measures how influential a given cluster is over the research field based on co-occurrences with keywords located elsewhere (Callon et al. 1991).
$$begin{array}{c}{C}_{L}=sum _{iin L}sum _{jnotin L}{w}_{{ij}}{e}_{{ij}}\ {e}_{{ij}}=left{begin{array}{c}1,{{rm {if}}},{w}_{{ij}} > 0\ 0,{{rm {otherwise}}}end{array}right.end{array}$$(2)For each co-occurrence of keywords located in L with those from other clusters (condition modelled by ({e}_{{ij}})), the corresponding link strength –({w}_{{ij}})– is incorporated into the ({C}_{L}) summation.
-
Cluster Density for a given cluster L –({D}_{L})-, as described by Eq. (3), is a ratio of the observed keyword co-occurrences within, over the maximum theoretical co-occurrences allowed for it (Callon et al. 1991). Therefore, the more co-occurrences between the keywords conforming L, the higher the density, and the more developed is the theme described by it.
The cluster metrics modelled above describe the maturity and cohesion of themes identified in the co-word network via a Strategic Diagram (Callon et al. 1991). In this diagram, keyword clusters are arranged over a two-dimensional plane, where the horizontal axis (X) depicts the cluster densities and the vertical (Y) the cluster densities. Clusters are arranged left to right based on their centralities, where the right-most clusters are the most central ones, and top to bottom after their densities, where the top-most ones are the densest. From the resulting X–Y placement of clusters over the diagram and the average cluster centrality and density, four strategic quadrants emerge, each revealing the current and future trends for ML in business themes: The major themes are placed at the top right quadrant (quadrant I), whereas the complementary and peripheral themes are located on the left side of the diagram (quadrants II and III). Lastly, emerging and developing themes are found at the bottom quadrants of the diagram (quadrants III and IV), highlighting them as themes with research potential.
Results
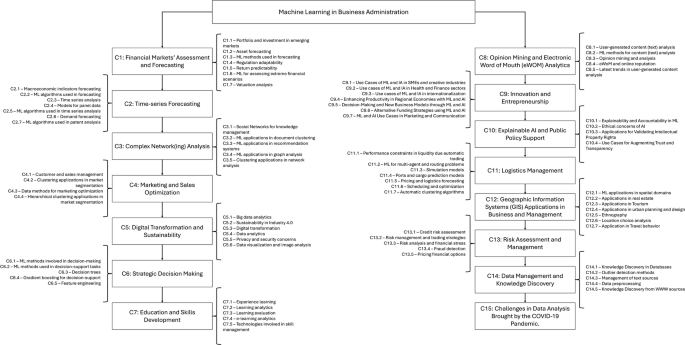
The co-occurrence map of keywords, illustrated in Fig. 3, shows keywords as circles (nodes) and their correlations as curved lines (arcs). A correlation between keywords is indicated when a pair of keywords appears together in at least one retrieved paper (co-occurrence). The literature is organized into 15 distinct clusters: (1) financial markets assessment and forecasting; (2) time-series forecasting; (3) complex network analysis; (4) marketing and sales optimization; (5) digital transformation and sustainability; (6) strategic decision making; (7) education and skills development; (8) opinion mining and Electronic Word of Mouth (eWOM) analytics; (9) innovation and entrepreneurship; (10) explainable AI and public policy support; (11) logistics management; (12) geographic information systems (GIS) applications in business and management; (13) risk assessment and management; (14) data management and knowledge discovery; and (15) challenges in data analysis due to the COVID-19 pandemic.
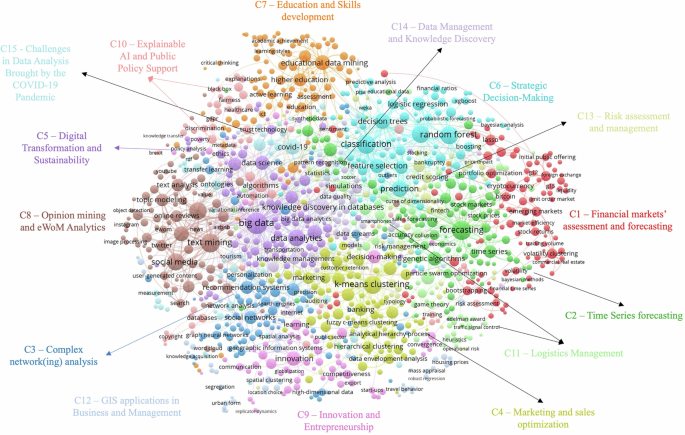
Unique correlations are hidden to improve legibility. Note: The colour of each node denotes the cluster they belong to, and node sizes are proportional to the degree centrality of keywords, that is, the number of correlations each keyword has, both according to the VOS clustering algorithm (van Eck and Waltman, 2007). Source: Author’s own elaboration.
C1: Financial markets’ assessment and forecasting
Figure 4a explores Cluster 1 (C1), focusing on the application of ML techniques in evaluating and predicting financial assets and market performance. Prominent ML algorithms in this cluster include Linear discriminant analysis (LDA), latent class analyses, and least absolute shrinkage and selection operator (LASSO), which have increasingly supplanted traditional econometric methods such as autoregressive integrated moving average (ARIMA), generalized autoregressive conditional heteroskedasticity (GARCH), and Gaussian mixture models (GMM) (Ghiassi et al. 2005; Pai and Lin, 2005; Ahmed et al. 2010; Mullainathan and Spiess, 2017).
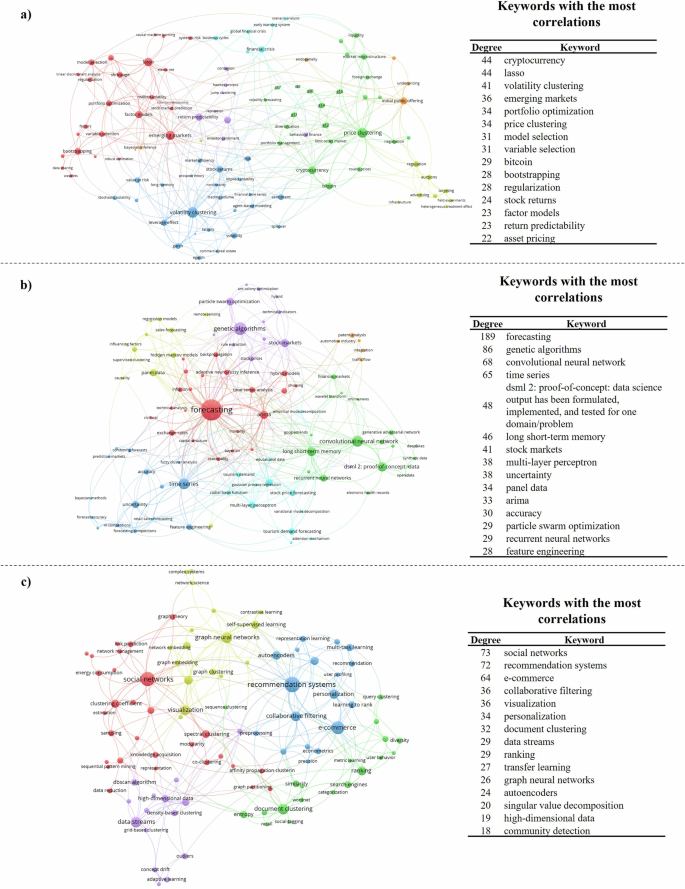
Detail of a Cluster 1: Financial markets’ assessment and forecasting. b Cluster 2: Time-series forecasting. c Cluster 3: Complex network(ing) analysis. Note: The colour of each node denotes the cluster they belong to, and node sizes are proportional to the degree centrality of keywords, that is, the number of correlations each keyword has, both according to the VOS clustering algorithm (van Eck and Waltman, 2007). Source: Author’s own elaboration.
Recent developments, especially in cryptocurrency markets like Ethereum and Bitcoin, have seen ML applied to forecast short-term dynamics of these volatile assets, leveraging both historical and real-time data (Urquhart, 2017; Zhang et al. 2018). A notable application is in predicting stock behaviours for bootstrapped enterprises, aiding in portfolio optimization and investment strategies (Manela and Moreira, 2017; Gu et al. 2020).
C2: Time-series forecasting
Figure 4b provides an overview of Cluster 2 (C2), which centres on ML techniques for time-series forecasting. This cluster is pivotal in predicting short-term fluctuations in business metrics such as financial KPIs, including sales and stock prices, and is influenced by macroeconomic variables like unemployment, inflation, and exchange rates (Ghiassi et al. 2005; Ahmed et al. 2010; Ferreira et al. 2016; Manela and Moreira, 2017; Mullainathan and Spiess, 2017; Vidya and Prabheesh, 2020).
Key ML frameworks in this area include long short-term memory (LSTM), convolutional neural networks (CNNs), recurrent neural networks (RNNs), and generative adversarial networks (GANs), which have gained traction for their ability to handle complex temporal data (Law et al. 2019; Fotiadis et al. 2021). GANs, in particular, are noted for their effectiveness in anomaly detection within time series data (Geiger et al. 2020; Zhang et al. 2021). Additionally, traditional algorithms such as particle swarm optimization (PSO), support-vector regression (SVR), ant colony optimization (ACO), and genetic algorithms (GAs) continue to be vital for addressing a wide range of time-series forecasting (Ahmed et al. 2010).
C3: Complex network(ing) analysis
Figure 4c illustrates Cluster 3 (C3), which is primarily focused on complex network analysis. This cluster involves ML techniques rooted in graph theory, including, graph neural networks (GNNs), convolutional neural networks (CNNs) applied to graphs, as well as clustering methods like density-based, grid-based, and affinity propagation clustering.
These methods are applied across diverse areas such as social network analysis (both real-world and online), collaborative filtering, and recommendation systems tailored for e-businesses and e-commerce. In particular, these algorithms support applications like link prediction, user modelling, and adaptive learning, making them crucial for enhancing community-driven recommendations in e-commerce (Wei et al. 2012). Additionally, this cluster includes research into fraud detection using ML techniques and document clustering (Dou et al. 2020).
C4: Marketing and sales optimization
Cluster 4 (C4), depicted in Fig. 5a, focuses on the application of ML in marketing and sales optimization. This cluster centres on the discovery and analysis of market segments and consumer profiles, leveraging clustering techniques and algorithms such as K-means, fuzzy C-means, and hierarchical clustering methods (Larson et al. 2005). These ML algorithms enhance customer relationship management (CRM) processes by enabling more precise segmentation and profiling of customers.
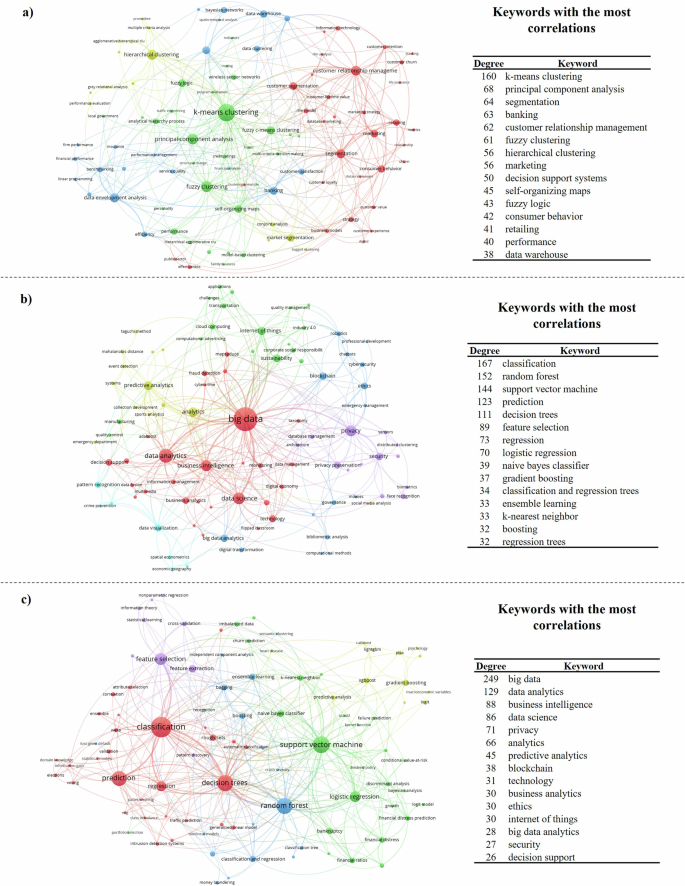
Detail of a Cluster 4: Marketing and sales optimization. b Cluster 5: Digital transformation and sustainability. c Cluster 6: Strategic decision-making. Note: The colour of each node denotes the cluster they belong to, and node sizes are proportional to the degree centrality of keywords, that is, the number of correlations each keyword has, both according to the VOS clustering algorithm (van Eck and Waltman, 2007). Source: Author’s own elaboration.
Within the domain of Segmentation, ML is employed to improve business-to-customer (B2C) and business-to-business (B2B) relationships (McCarty and Hastak, 2007; Paschen et al. 2020a). Techniques like K-means clustering and Gaussian mixture models facilitate the customization of high-value-added products and services tailored to specific customer needs, thereby enhancing customer satisfaction and loyalty (Syam and Sharma, 2018). Additionally, ML algorithms support the provision of supplementary services that elevate the overall customer experience.
Another significant application within this cluster is the use of ML for personalized advertising on social media platforms and Google Ads. By leveraging customer profiling through algorithms such as logistic regression, decision trees, and random forests, businesses can deliver more personalized and effective marketing strategies (Lee et al. 2018).
The banking industry prominently utilizes clustering algorithms for customer segmentation and service targeting, distinguishing its ML applications from other sectors that focus on areas like risk assessment, asset management, and stock market analysis (e.g., clusters C1 and C13).
Within C4, ML clustering techniques also complement analytic hierarchical process (AHP), multi-criteria decision-making (MCDM), and decision support systems (DSS) in strategic management. ML algorithms enhance the segmentation, targeting, and positioning (STP) process in marketing by providing data-driven insights that inform more effective segmentation and targeting strategies (Huang and Rust, 2021).
C5: Digital transformation and sustainability
Cluster 5 (C5), illustrated in Fig. 5b, centres on Digital Transformation and Sustainability within the context of Big Data analytics and Business Intelligence (BI). This cluster emphasizes the pivotal role of data-driven decision-making processes in driving enterprise digital transformation (Zaki 2019; Paschen et al. 2020a).
From a management perspective, digital transformation encompasses various Information and Communication Technologies (ICTs) and strategic concepts, including privacy preservation, data analytics, information security, blockchain, and the Internet of Things (IoT). While specific ML algorithms are not the primary focus of this cluster, ML plays a supportive role in several areas. For instance, classification and regression models are used to analyse vast datasets, enabling businesses to derive actionable insights and foster sustainable development (Fuchs et al. 2014; Tabesh et al. 2019; Paschen et al. 2020a). In sustainability efforts, ML contributes through predictive analytics and optimization algorithms that help in creating environmentally conscious business models. Techniques such as regression analysis, time-series forecasting, and unsupervised learning algorithms like principal component analysis (PCA) and clustering are employed to identify patterns and trends that inform sustainable practices (Goralski and Tan 2020; Di Vaio et al. 2020).
Cluster 5 involves high-level strategic discussions on sustainable digital transformation, with ML providing tools and methodologies that enhance data-driven decision-making and support the development of sustainable business models (Zaki 2019; Canhoto and Clear 2020; Di Vaio et al. 2020).
C6: Strategic decision making
The sixth cluster (C6), illustrated in Fig. 5c, delves into strategic decision-making, with a strong emphasis on classification and decision trees. This cluster highlights the use of ML decision tree algorithms and frameworks, including gradient boosting, random forests, and ensemble learning methods, which are pivotal in strategic management contexts (Samoilenko and Osei-Bryson, 2013).
In addition to decision tree-based algorithms, classification algorithms such as support vector machines (SVMs), Naïve Bayes, and K-nearest neighbours (KNNs) are extensively employed for strategic decision-making purposes. As defined by some scholars (Ferreira et al. 2016; Bertsimas and Kallus, 2020) these ML methods are instrumental in predictive scenarios, including:
-
Forecasting financial churn and distress: Using logistic regression and SVMs to predict customer churn and financial distress.
-
Evaluating bankruptcy possibilities: Applying random forests and gradient boosting to assess the likelihood of bankruptcy.
-
Identifying failures: Utilizing KNNs and Naïve Bayes classifiers to detect potential failures within business processes or strategies.
These ML algorithms provide robust frameworks for making informed strategic decisions by analysing complex datasets and uncovering patterns that might not be apparent through traditional analytical methods.
C7: Education and skills development
The seventh cluster (C7), depicted in Fig. 6a, focuses on education and skills development. Enterprises are increasingly adopting ML-driven techniques and frameworks for online learning, particularly in training and onboarding procedures. Reinforcement learning algorithms and predictive analytics models are commonly used to personalize learning experiences, enhance assessment processes, and optimize retention rates. These ML methods facilitate performance measurement and increase engagement among trainees and newly onboarded employees, thereby improving the overall onboarding and skills development process (Bakhshinategh et al. 2018; Hellas et al. 2018; Fernandes et al. 2019).
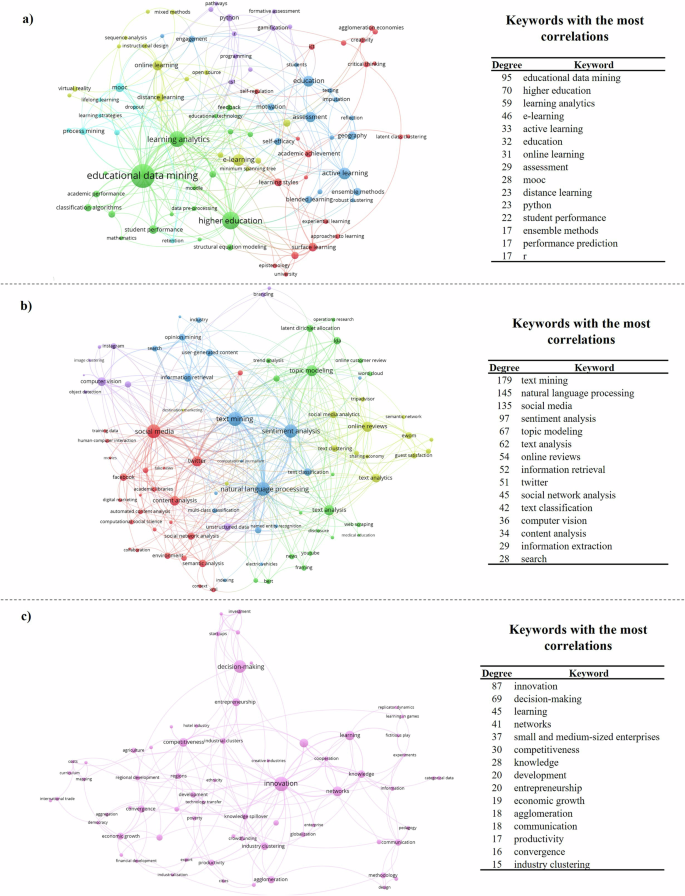
Detail of a Cluster 7: Education and skills development. b Cluster 8: Opinion mining and eWOM analytics. c Cluster 9: Innovation and entrepreneurship. Note: The colour of each node denotes the cluster they belong to, and node sizes are proportional to the degree centrality of keywords, that is, the number of correlations each keyword has, both according to the VOS clustering algorithm (van Eck and Waltman, 2007). Source: Author’s own elaboration.
C8: Opinion mining and electronic Word of Mouth (eWOM) analytics
Cluster 8, depicted in Fig. 6b, revolves around opinion mining and electronic Word of Mouth (eWOM) analytics. The maturation of natural language processing (NLP) algorithms has significantly advanced the automated analysis of user interactions on websites, e-commerce platforms, and news reports (Fuchs et al. 2014; Manela and Moreira, 2017; Guo et al. 2017).
ML frameworks for opinion mining frequently utilize algorithms like latent Dirichlet allocation (LDA) for topic modelling and bidirectional encoder representations from transformers (BERT) or Word2Vec for word embeddings. These techniques enable the classification of opinions into pre-defined categories, allowing for the analysis of large volumes of social media content with minimal human intervention (Xiang et al. 2017; Guo et al. 2017; Hartmann et al. 2019). Additionally, content analysis and semantic analysis approaches are enhanced by computer cision techniques, such as image clustering and object detection, to automatically review multimedia content (Ma et al. 2018; Zhang et al. 2019).
C9: Innovation and entrepreneurship
Figure 6c highlights Cluster 9, which centres on Innovation and Entrepreneurial opportunities driven by ML. Although this cluster primarily engages in high-level strategic discourse, without extensive practical applications of ML, there are key areas where ML plays a role. In Financial Technology (FINTECH), enterprises leverage predictive analytics, machine learning-based forecasting models, and decision support systems to navigate rapidly changing market conditions and to innovate in business strategies (Paschen et al. 2020b; Gu et al. 2020).
The use of ML in innovation is also discussed in the context of user experience (UX) design tools (Dove et al. 2017), where algorithms such as reinforcement learning (Rojas-Córdova et al. 2020) and recommendation systems (Graham and Bonner 2022) could potentially enhance user engagement and product development processes. While the exact applications of ML in entrepreneurship remain somewhat ambiguous, ongoing research suggests that ML could play a pivotal role in understanding and forecasting innovation trends and entrepreneurial success.
C10: Explainable AI and public policy support
The tenth cluster (C10), depicted in Fig. 7a, focuses on Explainable AI (XAI) and its critical role in supporting public policies through ML. Researchers in this cluster have developed frameworks to design ML algorithms that are transparent, fair, and high-performing. Key algorithms include SHapley Additive exPlanations (SHAP) and local interpretable model-agnostic explanations (LIME), which help in making ML models more interpretable and understandable by policymakers and the public (Adadi and Berrada, 2018; Preece, 2018; Miller, 2019; Barredo Arrieta et al. 2020). Mitigating biases in ML algorithms is central to XAI, as biases can contribute to public scepticism and distrust in data-driven decision-making. This concern extends to various sectors, including businesses, where biases impact employees and stakeholders (Kaplan and Haenlein, 2020; Paschen et al. 2020b). The ethical implications of ML algorithms, particularly regarding the potential reinforcement of biases against marginalized groups, have led to discussions on the responsible use of ML. Responses to these ethical challenges include regulatory frameworks like the European Union’s General Data Protection Regulation (GDPR) and the ongoing development of XAI methods (Preece, 2018; Kaplan and Haenlein, 2020; Canhoto and Clear, 2020).
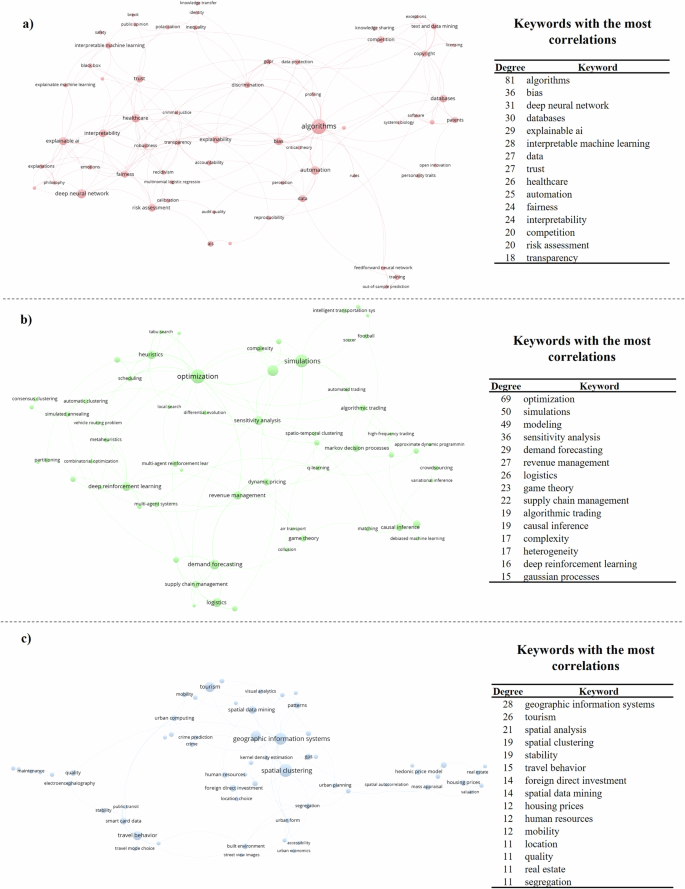
Detail of a Cluster 10: Explainable AI and public policy support. b Cluster 11: Logistics management. c Detail of cluster 12: GIS applications in business and management. Note: The colour of each node denotes the cluster they belong to, and node sizes are proportional to the degree centrality of keywords, that is, the number of correlations each keyword has, both according to the VOS clustering algorithm (van Eck and Waltman, 2007). Source: Author’s own elaboration.
C11: Logistics management
The eleventh cluster (C11), illustrated in Fig. 7b, examines ML applications in logistics management, emphasising the optimisation of operations and cost reduction. Key ML frameworks in this cluster include deep reinforcement learning and multi-agent systems, which are applied to solve complex logistics problems such as vehicle routing problems (VRP) and travelling salesman problems (TSP) (Chen and Wu, 2005; Luo et al. 2009; Ferreira et al. 2016).
Traditional optimization methods like simulated annealing and Tabu search are increasingly being complemented or replaced by advanced ML techniques, including spatial–temporal clustering and debiased ML. These methods are critical in supply chain management (SCM) tasks, such as identifying optimal delivery routes, forecasting product demand, agile supplier selection, dynamic pricing, and scheduling. By incorporating ML, businesses can enhance their logistics efficiency and reduce operational costs (Huang et al. 2011).
C12: Geographic information systems (GIS) applications in business and management
Cluster 12 (C12), depicted in Fig. 7c, is dedicated to the integration of geographic information systems (GIS) with ML techniques to enhance business and management applications. This cluster includes the use of spatial clustering and spatial data mining algorithms to develop and coordinate multimodal supply routes, assess housing prices for optimal location selection, and re-evaluate business investment values (Grekousis et al. 2013; Chen and Tsai, 2016). Beyond traditional GIS applications, this cluster explores the impact of criminal and gang activity, traffic patterns, and real estate dynamics on business operations. By integrating GIS with ML, such as K-means clustering and density-based spatial clustering of applications with noise (DBSCAN), businesses gain valuable insights that inform decision-making and improve operational efficiency. These ML-driven GIS applications are crucial for strategic planning, including workforce performance management, recruitment, onboarding processes, and asset valuation (Morency et al. 2007; Chang et al. 2010; Grekousis et al. 2013).
C13: Risk assessment and management
Cluster 13 (C13), depicted in Fig. 8a, focuses on risk assessment and management, particularly within the financial sector. ML plays a critical role in this domain, especially in assessing customer credit risk and managing debt risks. Traditional methods, such as Monte Carlo simulations, are increasingly being complemented by advanced ML algorithms like random forests, support vector machines (SVMs), and neural networks (Khandani et al. 2010; Bekhet and Eletter, 2014; Koutanaei et al. 2015).
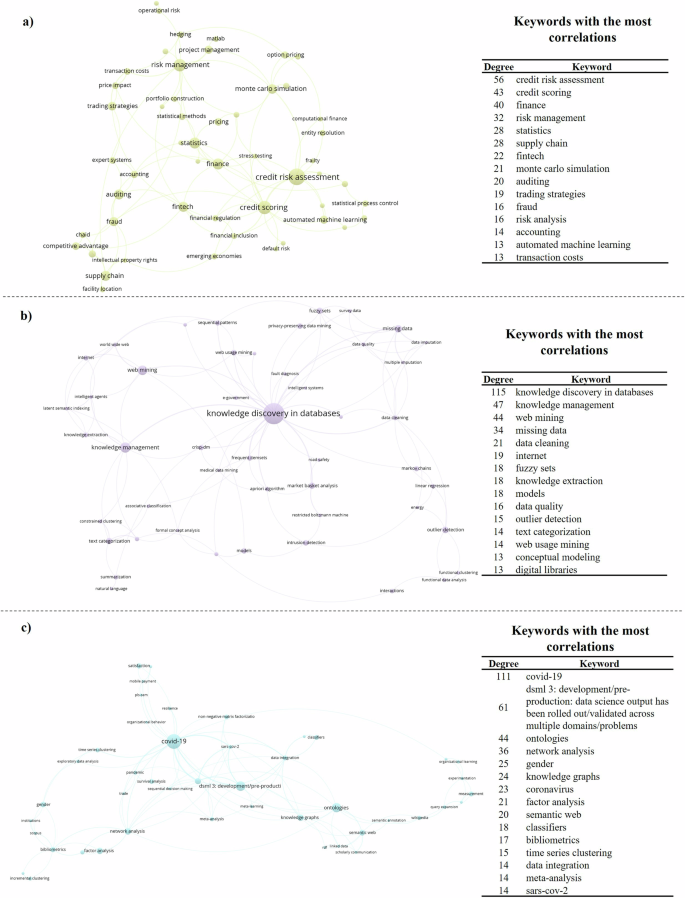
Detail of a Cluster 13: Risk assessment and management. b Cluster 14: Data management and knowledge discovery. c Detail of Cluster 15: Challenges in data analysis brought by COVID-19. Note: The colour of each node denotes the cluster they belong to, and node sizes are proportional to the degree centrality of keywords, that is, the number of correlations each keyword has, both according to the VOS clustering algorithm (van Eck and Waltman, 2007). Source: Author’s own elaboration.
This cluster extends beyond financial risks, encompassing business risks in project management, fraud detection, auditing, and investments, particularly in emerging economies. ML-driven techniques such as anomaly detection and predictive analytics are widely used in these areas to identify and mitigate potential risks (Thiprungsri and Vasarhelyi, 2011; Jin and Zhang, 2011; Gray and Debreceny, 2014). The FINTECH industry’s influence is notable, relying heavily on ML and ICTs to offer innovative financial services, although specific ML applications within FINTECH are often intertwined with those in clusters like C1 and C2 (Kalinic et al. 2019; Gu et al. 2020).
C14: Data management and knowledge discovery
The cluster depicted in Fig. 8b (C14) focuses on data management and knowledge discovery, a critical area for ML applications in business. This cluster highlights the processes involved in acquiring, preprocessing, and analysing data to maximize business value. The cross-industry standard process for data mining (CRISP-DM) remains the dominant framework in this area, guiding the knowledge discovery in databases (KDD) process (Fernandes et al. 2019).
ML techniques central to this cluster include constrained clustering, functional clustering, restricted Boltzmann machines, latent semantic indexing (LSI), and a priori algorithms. These algorithms are applied to continuous data streams from sources like web content, surveys, and market baskets, enabling businesses to perform tasks such as data cleaning, outlier detection, and data imputation (Chen and Wu, 2005). Additionally, non-ML techniques like linear regressions, Markov chains, and conceptual modelling complement these ML methods to ensure data quality and privacy in business operations.
C15: Challenges in data analysis brought by the COVID-19 pandemic
The last cluster, C15, centres on the challenges in data analysis brought by the COVID-19 pandemic, as depicted in Fig. 8c. ML algorithms have been pivotal in predicting the pandemic’s impact on businesses, with models like time-series forecasting and Bayesian networks being employed to assess the effects of lockdowns and restrictions (Vidya and Prabheesh, 2020; Baek et al. 2020; Fotiadis et al. 2021).
The pandemic has accelerated digital transformation across various industries, pushing businesses towards extensive digitization and the adoption of remote work policies. These changes have created new opportunities for ML applications in digital transformation projects, particularly those detailed in Cluster C5. Semantic networks and meta-analysis techniques, along with bibliometric analysis, have become essential tools for businesses navigating this new landscape, facilitating their transition to more digital operations (Sedera et al. 2022; Miklosik and Krah, 2023).
Discussion
Analysis from the strategic diagram
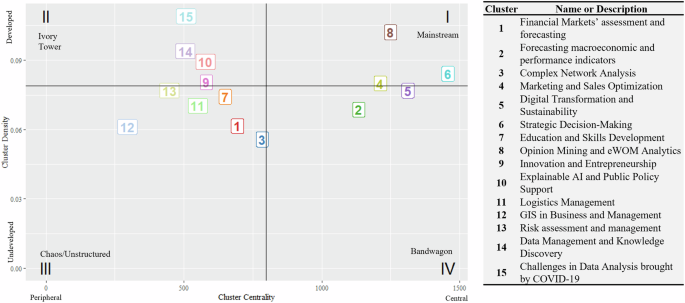
Machine learning (ML) is increasingly central to business administration, with applications that span a wide array of domains. A co-word network analysis revealed fifteen distinct clusters, each representing a unique area where ML techniques are applied. These clusters, visualized through a strategic diagram (Fig. 9), highlight the diverse and interconnected landscape of ML in business and management. The strategic diagram further categorizes these clusters based on centrality and density metrics, offering insights into their development and potential impact.
Source: Author’s own elaboration.
A pivotal aspect of this analysis is the strategic diagram delineating ML applications in business and management, which visualizes centrality and density metrics within keyword clusters on a two-dimensional graph as described in Table 1. Centrality measures the sum of correlation frequencies or ‘link strengths’ between cluster keywords and those elsewhere in the co-word map (Callon et al. 1991). Meanwhile, cluster density gauges the ratio of cluster keywords to their correlations, signifying the conceptual development within a theme (Callon et al. 1991).
Advanced and sought-after applications
The strategic diagram identifies marketing and sales optimization (C4), opinion mining and eWOM analytics (C8), and strategic decision-making (C6) as the most advanced and sought-after ML applications, located in Quadrant I (mainstream). These clusters demonstrate mature use cases with ongoing research and practical application. For instance, ML’s role in marketing and sales optimization is evident in the refinement of customer segmentation and targeted advertising strategies, enhancing customer relationship management (CRM). Similarly, in strategic decision-making, ML techniques like decision trees and ensemble learning are crucial for predictive analytics, such as forecasting financial distress and bankruptcy.
Emerging and promising themes
Emerging themes like time-series forecasting (C2) and digital transformation and sustainability (C5), found in Quadrant IV (Bandwagon), indicate their growing relevance and potential for broader adoption. ML’s significance in time-series forecasting is underscored by its application in predicting short-term business metrics, such as sales and stock prices, which are crucial for strategic planning. The diversity of ML frameworks, from LSTM networks to particle swarm optimization, illustrates ML’s adaptability in addressing various forecasting challenges across industries. Meanwhile, digital transformation and sustainability are becoming increasingly vital as businesses shift towards data-driven decision-making, integrating advanced ICTs for sustainable development.
Clusters situated in Quadrant III (chaos/unstructured), such as risk management (C13), logistics management (C11), and complex network analysis (C3), show promise for future research. Risk management, for example, benefits from ML’s capabilities in assessing financial risks and optimizing investment strategies. In logistics, ML enhances supply chain efficiency through advanced optimization and simulation methods. The application of ML in complex network analysis, particularly in social networks and recommendation systems, demonstrates how businesses can leverage community behaviours to refine marketing strategies and customer interactions.
Challenges and ethical considerations
Explainable AI and public policy support (C10), positioned in Quadrant II (Ivory Tower), emphasize the importance of transparency, fairness, and trust in ML applications. The growing focus on explainable AI (XAI) reflects the need to ensure that ML algorithms are not only effective but also ethically sound, particularly in public policy and business decision-making. Ethical considerations, such as mitigating biases in algorithmic outcomes, are critical to maintaining public trust and ensuring that ML’s deployment in sensitive areas, like financial markets or social services, is both fair and just.
Evolving and declining relevance
Certain themes, like innovation and entrepreneurship (C9) and data management and knowledge discovery (C14), although historically significant, are seeing a decline in relevance as their use cases mature. Positioned in Quadrant II, these themes have garnered substantial academic attention but are becoming less central to current applied research. For instance, the challenges in data analysis due to COVID-19 (C15) are becoming less relevant as businesses adapt to the post-pandemic landscape. However, there remains potential to integrate these maturing themes with more dynamic ones, such as linking knowledge discovery to strategic decision-making, to sustain their relevance in the rapidly evolving field of business ML applications.
Discussion on machine learning applications in various domains of business administration
Machine learning (ML) has become integral to modern business administration, providing solutions that enhance efficiency, decision-making, and customer satisfaction across various sectors. Thus, as illustrated in Table 2, we delve into the various algorithms to uncover their practical applications in the fields of business and administration.
Finance (Clusters C1, C2, C13)
In the financial sector, ML algorithms are employed extensively for risk management and market forecasting. For example, linear discriminant analysis and latent class analysis are used to predict stock market returns and identify high-risk investments, particularly in volatile markets like cryptocurrencies. Companies use these techniques to optimize their investment portfolios, ensuring better returns by balancing risk and reward. Additionally, genetic algorithms and recurrent neural networks (RNNs) are applied in asset price forecasting, allowing financial institutions to make informed decisions on stock purchases and sales. In risk assessment, automated machine learning helps banks evaluate creditworthiness and detect potential fraud, significantly reducing financial losses and improving credit scoring processes.
Customer relationship management (Clusters C3, C4, C8)
ML plays a crucial role in enhancing customer relationship management (CRM). Graph neural networks are leveraged in e-commerce platforms to create personalized shopping experiences. For instance, Amazon uses recommendation systems that analyse user behaviour and purchase history to suggest products, increasing customer satisfaction and sales. In marketing, K-means clustering is utilized to segment customers based on purchasing habits, allowing businesses to tailor marketing campaigns effectively. Natural language processing (NLP) and latent Dirichlet allocation (LDA) are employed in sentiment analysis to monitor social media platforms and customer reviews, helping companies like Starbucks to adapt their products and services based on real-time customer feedback.
Decision-making support (Clusters C6, C11)
Strategic decision-making is another area where ML has significant applications. Random forests and support vector machines (SVMs) assist companies in making data-driven decisions. For example, in logistics, businesses like FedEx use spatial–temporal clustering to optimize delivery routes, reducing transportation costs and improving delivery times. In revenue management, airlines like Delta Airlines use multi-agent reinforcement learning to dynamically adjust ticket prices based on demand, maximizing profits while maintaining customer satisfaction.
Innovation and public policy (Clusters C7, C9, C10)
In the field of education and corporate training, latent class clustering is used to personalize learning experiences, improving outcomes in online learning platforms such as Coursera. For public policy support, governments use explainable AI to ensure transparency in automated decision-making, especially in areas like criminal justice where bias mitigation is critical. For instance, public health agencies during the COVID-19 pandemic utilized multinomial logistic regression to predict infection spread and guide policy decisions, such as lockdown measures.
Data management and sustainability (Clusters C14, C5, C12, C15)
ML-driven data management is vital for businesses seeking to extract meaningful insights from vast datasets. Latent semantic indexing (LSI) is used by companies like Google to enhance search engine capabilities, ensuring users receive the most relevant results. In the real estate sector, spatial data mining helps companies analyse location data to determine optimal sites for new developments, considering factors like housing prices and traffic patterns. During the COVID-19 pandemic, time-series clustering enabled businesses to track the impact of the virus on supply chains, allowing companies like Walmart to adjust their logistics strategies and maintain product availability.
Conclusion
This study offers an understanding of the widespread integration of machine learning (ML) across diverse domains within business and management. Our analysis uncovers a distinct approach to employing ML, diverging from the usual classifications found in the literature, which typically highlight four typical business domains: Finance, Marketing, Firm Strategy, and Human Resource Management (Zhang et al. 2021). Hence, this work presents a comprehensive taxonomy, delineating fifteen thematic clusters. Detailed applications of ML in various business contexts, systematically presented in Table 2, categorize thematic clusters and the specific ML algorithms, methods, or techniques employed within each context. This comprehensive resource, a synthesis of various studies, provides a valuable reference point for managers confronting challenges aligned with each thematic cluster. It enables them to explore cited algorithms and technologies, offering insights and potential strategies tailored to their specific managerial domains.
Moreover, based on the analysis and classification of clusters in business and administration, it is evident that machine learning (ML) and artificial intelligence (AI) are increasingly integral to optimizing various domains, from financial markets to education, logistics, and public policy. Each cluster highlights the growing reliance on ML algorithms to enhance decision-making, risk management, and operational efficiency across industries. For instance, financial markets benefit from advanced forecasting techniques, while logistics management is revolutionized through ML-driven optimization and scheduling. Furthermore, the integration of ML in education and skills development underscores the technology’s potential in personalized learning and performance assessment.
The taxonomy of clusters illustrated in Fig. 10, displays the diverse applications of ML and AI, demonstrating their transformative impact on traditional business processes. As these technologies continue to evolve, their ability to provide actionable insights, streamline operations, and support strategic decisions will be paramount. The clusters reveal a holistic view of how ML and AI are reshaping business landscapes, offering a roadmap for future research and practical implementations that can drive innovation and sustainable growth across sectors.
Source: Author’s own elaboration.
Recommendations for Managers
In the realm of machine learning (ML) and intelligent automation (IA) technologies, managerial roles play a pivotal role in conducting thorough evaluations tailored to specific business cases (Tabesh et al. 2019; Miklosik and Krah, 2023). It is crucial to allocate resources while mitigating potential impacts on social, labour, financial, and regulatory facets inherent in the implementation of these technologies (Miller, 2019; Miklosik and Krah, 2023). Hasty adoption of ML or IA, driven by industry trends or competitive pressures, may result in unintended consequences beyond immediate financial implications.
It is recommended avoiding extreme decisions in ML adoption (Tabesh et al. 2019). The implementation of ML technologies should not entail outright replacement of existing structures or paradigms, nor should it lead to a wholesale rejection of transformative tools. Instead, a nuanced, gradual, and consensus-driven approach is recommended. This involves strategically and ambitiously integrating ML into existing frameworks, recognizing that embracing this technology demands careful calibration.
The caution extends beyond financial considerations, encompassing awareness of the dynamic shifts in popularity and the increased regulatory scrutiny directed at specific technologies such as ChatGPT and large language models (LLMs). Managers are strongly advised to transcend trends, directing their attention to the specific needs of their industry and sector. This strategic focus ensures the enduring sustainability and resilience of their chosen machine learning (ML) strategies, fostering adaptability in the face of evolving technological and regulatory landscapes.
Finally, the judicious incorporation of ML can enhance profitability and competitiveness (Luo et al. 2009; Zaki, 2019; Sedera et al. 2022). Striking a balance between ambition and realism ensures technological advancements bolster productivity without rendering individuals obsolete. A strategic ML deployment should empower individuals within the organization, fostering a sense of support and collaboration, rather than instigating anxiety about being replaced.
Recommendations for developers and academia
Table 2 illustrates the varied applications of ML within these domains, highlighting its significance in contemporary business landscapes. However, despite its widespread integration, persistent challenges hinder the complete realization of ML algorithms’ potential.
First, an ongoing area of enquiry revolves around the comparative performance of heuristic models versus specific ML algorithms. Questions remain regarding whether heuristic models might outperform ML algorithms in certain scenarios, particularly given concerns about the potentially slow convergence of ML algorithms within complex systems. This enquiry calls for a deeper analysis of contexts where heuristic approaches could provide more efficient solutions and the optimal scenarios for deploying ML algorithms to their fullest potential. Additionally, further research should focus on evaluating the efficiency and effectiveness of various AI and ML algorithms across different domains of business management, recognizing that AI and ML may not always be the most suitable or effective solutions for some of the challenges faced in this field. Moreover, although in certain domains, ML continues to demonstrate efficacy, year-over-year improvement in most benchmarks is marginal (Vial, 2019; Sedera et al. 2022).
Second, beyond algorithmic performance, the underpinning infrastructure poses critical challenges in realizing the complete implementation of ML algorithms. Infrastructure considerations encompass diverse facets, including computational capacity, processing capabilities, and security protocols (Sullivan et al. 2001; Canhoto and Clear, 2020). Addressing these infrastructure challenges becomes imperative for the seamless integration and effective utilization of ML algorithms within real-world business contexts.
Third, the pragmatic aspects of cost-effectiveness and the challenges associated with the practical integration of these algorithms within existing business frameworks emerge as focal points for further exploration. Understanding the economic viability of implementing ML solutions and navigating the hurdles inherent in their seamless integration into operational systems represent critical aspects demanding closer scrutiny.
Fourth, ML algorithms not only integrate into established businesses across various fields but also play a pivotal role in fostering new enterprises and innovative business models (Atlantico, 2023). However, addressing the digital divide between small and medium-sized enterprises (SMEs) and larger corporations is crucial. Further research should be directed toward evaluating the effectiveness of public policies in supporting SMEs to manage the transitions involved in adopting ML and AI. Additionally, it should explore the potential for SMEs to leapfrog their larger counterparts by strategically adopting these technologies. Addressing these challenges necessitates collaborative efforts among scholars and practitioners across disciplines, especially to support the needs of SMEs. Designing ML algorithms and AI solutions that are responsive to real-world market demands requires considering a broader spectrum of resources, elements, processes, and products. This also involves examining various cooperation levels within business and management processes, particularly those involving multiple agents, to ensure comprehensive and effective implementation.
Certain thematic clusters, like financial markets’ assessment and forecasting (C1), complex network analysis (C3), education and skill development (C7), and logistics management (C11), have garnered significant academic interest. Notably, recent startups, especially in developing regions, focus on addressing challenges within these clusters by incorporating ML algorithms into their solutions (Atlantico, 2023). This trend indicates the growing gap between industry and academia in ML algorithm development, as observed in recent reports (Atlantico, 2023; Stanford “AI Index Report”, 2023).
Finally, the study acknowledges the crucial role of human interactions, both in the development and utilization of these algorithms. The human element, whether in designing, refining, or utilizing ML algorithms, significantly influences their effectiveness and ethical considerations (Miller, 2019; Miklosik and Krah, 2023). Future research should focus on examining the interplay between human involvement and machine-driven decision-making processes to ensure the responsible and effective application of machine learning (ML) in business and management contexts. Furthermore, the adoption and development of these algorithms necessitate additional skill development among employees and structural changes within businesses, impacting operational models, profit structures, and other fundamental aspects of business frameworks. Closing this gap will be essential in ensuring a more inclusive and effective integration of ML into diverse business landscapes.
Recommendations for policymakers
Based on our analysis, there are significant public policy implications regarding the integration of machine learning (ML) in business and management. Policymakers should prioritize the development of regulatory frameworks that address ethical considerations such as transparency, fairness, and bias mitigation in ML applications. This is particularly crucial in sectors like finance, healthcare, and public services, where algorithmic decisions can significantly impact societal well-being. Regulations should be oriented to promote the use of Explainable AI to ensure that ML algorithms are understandable and accountable, thereby fostering public trust and preventing discriminatory or unintended outcomes.
Additionally, policies should support small and medium-sized enterprises (SMEs) in adopting ML technologies to bridge the digital divide with larger corporations. Governments can facilitate this by providing financial incentives, technical support, and training programs to help SMEs adopt ML technologies effectively. Investing in digital infrastructure, especially in underserved regions, is also essential to enable equitable access to advanced technologies and promote inclusive economic growth.
Public policy should also prioritize enhancing infrastructure, education, and workforce development. Integrating machine learning (ML) and artificial intelligence (AI) education into curricula and offering reskilling programs can prepare the labour force for the evolving job market, thereby mitigating potential unemployment due to automation. Furthermore, establishing mechanisms to strengthen collaboration among academia, industry, and government is essential, as such synergies can accelerate the development of ML solutions that are ethically sound and aligned with real-world needs. Simultaneously, policymakers must address infrastructure challenges associated with ML implementation, including providing adequate computational resources and addressing data security and privacy concerns. Developing innovative approaches to ensure compliance with standards and guidelines for data management and cybersecurity is also important to safeguard individual rights and promote the responsible use of ML technologies.
Limitations and future work
In discussing the limitations of this study, it is important to acknowledge the recent mainstream emergence of generative AI-based applications. Our research reveals the intellectual structure and identifiable trends of machine learning (ML) and artificial intelligence (AI) applications in business and management as of August 2022, just before large language models (LLMs) and generative AI applications (e.g., ChatGPT) became prevalent. While our results indicate that these generative AI technologies were not yet significant in business and management contexts at that time, we recognize their rapidly expanding use cases since 2023.
This acceleration suggests that the current intellectual structure of ML and AI could become heavily skewed toward research focusing exclusively on generative AI, potentially overshadowing other established ML and AI algorithms and methods. Therefore, our study offers a “pre-generative AI boom” snapshot of proven, mature, and stable ML-based technologies and applications in business and management. It serves as a valuable reference for practitioners and academics to apply in their business cases and to guide future research and development.
For researchers aiming to replicate this work to capture an updated intellectual structure of ML and AI applications in business and management using a co-word analysis approach, it is crucial to be mindful of the timeless and non-historical nature of the clustering and graph algorithms involved. Without careful consideration, there is a risk of obtaining misleading results dominated by the surge of generative AI-focused publications from the past two years, which could obscure other historically significant ML and AI methods.
Given this context, we suggest that a balanced and realistic up-to-date intellectual structure of ML and AI research in business and management should distinguish between generative AI technologies and use cases and those not utilizing generative AI. This differentiation would lead to a two-part structure that provides a comprehensive taxonomy of ML and AI applications in business contexts, ensuring that both emerging and established technologies are appropriately represented.


Responses