State estimation with quantum extreme learning machines beyond the scrambling time

Introduction
The capability of complex systems to store, propagate, and process information is at the core of reservoir computing (RC)1,2,3,4 and extreme learning machines (ELM)5,6,7,8,9. RCs and ELMs are supervised machine learning techniques that leverage a complex unknown fixed dynamic, referred to as “reservoir” in this context, to quickly process data in order to make target features easier to retrieve via a simple linear regression, with RCs also capable of processing temporal data thanks to their use of reservoirs with memory. The simplicity of the training and the heterogeneity of systems that can be used as reservoirs10,11,12,13,14,15,16, are at the core of the success of ELMs. Classical ELMs (RCs) are quantized replacing classical functions with physical quantum dynamics, giving rise to so-called quantum extreme learning machines (QELMs) and quantum reservoir computing (QRCs)17,18,19,20,21,22,23,24,25,26,27,28,29,30,31. QELMs, among other things, have shown significant promise for experimental state estimation tasks24,32,33. In this context, the fact that information is most often collected from local measurements on the output states, naturally raises questions about the relations between QELM-based state estimation protocols and the spreading of information throughout its reservoir.
On the other hand, quantum information scrambling (QIS)34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49 is a framework to investigate the retrievability of information from local measurements on output states. Dynamics are said to be scrambling when they hide information in the internal correlations of the system, thus rendering it irretrievable through local measurements50,51. Several quantifiers have been proposed to study this phenomenon, including out-of-time-ordered-correlators (OTOCs)41,44,46,52, tripartite information41,42,53,54, and generalized channel capacities43,50,53,55,56.
Since QELM-based architectures commonly rely on the information retrieved by measuring a set of local observables on the reservoir, understanding how QIS affects information retrievable from such measurements provides valuable insights, which can guide the search for dynamics suitable for experimental implementations. Furthermore, given the nature of QIS, one might expect that because of scrambling, performing task via local measurements beyond the scrambling time—the time after which OTOCs saturate to their asymptotic value36,41,46,57—would be highly inefficient due to the loss of information in correlations. On the other hand, previous studies22,58 have pointed out that systems exhibiting ergodic to non-ergodic phase transitions influence both the information processing capabilities and short-term memory of reservoirs in the context of QRC. These studies also show a connection to the scrambling capabilities of the system. Deepening our understanding of QIS in local-measurements-based QELM can thus be a resource also in the context of QRC, helping to search for reservoir topologies that maximize the information retrieved with a weak measurement approach25.
In this work, we investigate the interplay between QELM-based state estimation and QIS. We find, in particular, that information remains consistently retrievable from local measurements even far beyond the scrambling time. This observation highlights that the crucial property for state reconstruction is information spreading, rather than information scrambling per se. These results run counter to the standard notion that beyond the scrambling time, all information about input states is lost into non-local correlations. Instead, we observe that even when OTOCs would indicate the presence of scrambling, the amount of residual local information is sufficient to reconstruct input states efficiently, and remains so even at longer timescales. These results have two significant implications. First, they reveal that analyzing scrambling systems through the lens of QELM-based state estimation offers new insights into the nature of QIS and its quantifiers. Second, they suggest that even scrambling systems can support efficient and robust input state reconstruction, providing experimentally viable platforms for quantum state estimation.
Furthermore, we observe two different regimes characterized by different behaviors of the estimation accuracy as a function of time. In a first transient regime, characterized by the OTOC linearly increasing with time—which signals that information is still spreading through the system—the estimation accuracy depends on the reservoir structure, and is reflected by the behavior of the Holevo information. On the other hand, beyond the scrambling time—defined by the saturation of the OTOC—these differences disappear, and the estimation accuracy stabilizes to a constant value. We thus find while OTOCs correspond to the scrambling time of the system, entropic quantifiers provide a more fine-grained insight into the estimation accuracy of QELMs.
The article is organized as follows: we begin by briefly reviewing ELMs, QELMs, and QIS. The two Sections “Reservoir dimension” and “Estimation accuracy and QIS” are dedicated to the presentation of our main results, while we draw our conclusions in Section “Discussion”. Finally, in section “Methodology” we include more details about the methods used throughout the paper.
Results
Review of ELMs and QELMs
From a broad mathematical perspective, given a parametrized family of functions fθ, the goal of a machine learning algorithm is to “learn” the values of the parameters θ that implement a target relation between input and output data. The function fθ is referred to as the “model” in this context, and θ are the parameters to train. In particular, for supervised machine learning models, a training dataset(({bf{S}},{bf{Y}})equiv {{({{bf{s}}}_{k},{{bf{y}}}_{k})}}_{k = 1}^{{N}_{{rm{train}}}}), with ({{bf{s}}}_{k}in {{mathbb{R}}}^{{N}_{{rm{in}}}}) and ({{bf{y}}}_{k}in {{mathbb{R}}}^{{N}_{{rm{feat}}}}), is used to find θ corresponding to which fθ(sk) ≃ yk for all k. Here Ntrain, Nin, and Nfeat are the number of training vectors, input vectors, and features, respectively. To quantify how well a given model is performing, we define a loss function L(f(sk), yk), and seek to minimize its expectation value over the training dataset, and then test its performance on a testing dataset of previously unseen data. A common choice of such loss function is the standard Euclidean distance, whose expectation value is then just the mean-squared error (MSE)59. The optimization of the model is then typically, but not exclusively, performed using stochastic-gradient-descent-based methods, which iteratively tune θ to minimize the loss60.
ELMs
An ELM is a particularly simple type of machine learning model which involves a complex but untrained function (R:{{mathbb{R}}}^{{N}_{{rm{in}}}}to {{mathbb{R}}}^{{N}_{{rm{out}}}}), referred to as the reservoir function, followed by a trained linear layer W, so that the overall model can be formally written as ({f}_{{bf{W}}}^{,text{ELM},}={bf{W}},{circ}, {R}.) The reservoir function is often implemented as a recurrent neural network with randomly initialized weights1. The advantage of this model is to reap the generalization benefits of highly nonlinear functions, while at the same time avoiding the high computational cost of training them.
Training an ELM thus amounts to solving a linear regression problem, which is generally much simpler than training a traditional deep neural network1. More precisely, given a training dataset (Strain, Ytrain), we want to find an exact or approximate W such that
where R(Strain) is the matrix whose k-th column is (R({{bf{s}}}_{k}^{{rm{train}}})). Here, R(Strain) is an Nout × Ntrain matrix, while Ytrain is Nfeat × Ntrain. The least squares solution to eq. (1) is
where (R{({{bf{S}}}^{{rm{train}}})}^{+}) denotes the Moore-Penrose pseudo-inverse, which can be computed via the singular value decomposition (SVD) as (R{({{bf{S}}}^{{rm{train}}})}^{+}=U{{{Sigma }}}^{+}{V}^{dagger }), if R(Strain) = UΣV† is the SVD of the original matrix, with U, V isometries and Σ > 0 positive diagonal squared matrix with the singular values as diagonal elements61.
Although linear systems are generally relatively easy to solve, there are many situations where the solution can be numerically unstable. A common way to quantify the stability of the solution for A of a linear system Y = AX, with X, Y matrices, is the condition number κ(X) defined as62
where ({lambda }_{max }) and ({lambda }_{min }) are the maximal and minimal singular values of X. The condition number quantifies how perturbations in X result in errors in the estimated A. High condition numbers, typically corresponding to a near-singular X, indicate that small errors in X could result in large errors in A, and thus that the linear system is ill-conditioned.
QELMs
In QELMs, the vectors sk become input quantum states ρk, and the reservoir function R is replaced by the combination of a quantum dynamic Φ and a measurement17,32. The measurement can be modeled as either some POVM or, as we will do here, some set of observables ({{{{bf{O}}}_{{bf{j}}}}}_{j = 1}^{{N}_{{rm{out}}}}). The classical matrix R(Strain) becomes for QELMs the matrix of probabilities Ptrain defined as
with ({{{rho }_{k}^{{rm{train}}}}}_{k = 1}^{{N}_{{rm{train}}}}) the states in the training dataset. The matrix Ptest is defined analogously from the testing states ({{{rho }_{k}^{{rm{test}}}}}_{k = 1}^{{N}_{{rm{test}}}}). Note that Ptrain has dimensions Nout × Ntrain with Nout the number of measurement outcomes and Ntrain the number of training states. Training the QELM involves again solving the linear system (2), upon replacing R(Strain) → Ptrain. The matrix Ytrain in the quantum case contains the set of Nfeat features associated to each of the Ntrain training input states. We will focus on the case where the target features are expectation values of target observables, meaning that ({[{{bf{Y}}}^{{rm{train}}}]}_{ij}={rm{Tr}}[{{bf{O}}}_{i}{{Phi }}({rho }_{j}^{{rm{train}}})]) with Oi the i = 1, . . . , Nfeat labeling the target observables, and similarly for Ytest.
The training process produces a linear map W which applied to measurement probabilities recovers the target observables. To evaluate the performance of the trained reservoir we use Ptest to compute the predicted features Ypred = WPtest, and compute the MSE as
The output expectation values can always be written as ({{bf{Y}}}_{ij}^{,text{train},}={rm{Tr}}[{{{Phi }}}^{dagger }({{bf{O}}}_{i}){rho }_{j}^{{rm{train}}}]) with Φ† the dual of Φ. This amounts to describing measurements in the Heisenberg pictures, and allows to concisely describe QELMs as involving a direct measurement on input state. It follows that a target observable O can be accurately estimated iff it can be written as a linear combination of the operators Φ†(Oj)32.
Review of QIS
Quantum information scrambling (QIS) studies the spread of local information across a many-body system, and its retrievability from local measurements34,35,36,37,38,39,40,41,42,43,44,45,46,47,49. Two main approaches to quantify QIS are out-of-time-ordered-correlators (OTOCs)41,44,46,47,48,49,52, and entropic quantifiers such as Holevo information55,56 and tripartite information41,42,53. We focus on the first two, due to them being easier to compute and relate to the estimation accuracy of QELMs. In this section, we will briefly review these two methods, in order to set the stage for the next sections.
OTOCs
The idea behind OTOCs41,44,46,47,48,49,52 is to quantify QIS via the non-commutativity of observables at different times. OTOCs have been measured experimentally on digital quantum computers based on trapped ions and on nuclear magnetic resonance quantum simulators63,64,65,66.
Consider two disjoint subsystems ({{mathcal{H}}}_{A}) and ({{mathcal{H}}}_{B}) of a larger Hilbert space ({mathcal{H}}) and suppose our goal is to encode information in ({{mathcal{H}}}_{B}) and retrieve it from ({{mathcal{H}}}_{A}) after a time t, while the overall system undergoes a unitary evolution U. OTOCs quantify the viability of this process through the correlator between OB and the Heisenberg-evolved ({{bf{O}}}_{A}(t)equiv {{{Phi }}}_{t}^{dagger }({{bf{O}}}_{A})), for different pairs of local operators OA and OB, with Φt the dynamical map describing the evolution, and ({{{Phi }}}_{t}^{dagger }) its adjoint. In the case of unitary evolution, this simplifies to ({{{Phi }}}_{t}(rho )={U}_{t}rho {U}_{t}^{dagger }) with Ut = e−iHt, and thus ({{{Phi }}}_{t}^{dagger }({{bf{O}}}_{A})={U}_{t}^{dagger }{{bf{O}}}_{A}{U}_{t}). The non-commutativity is quantified as44
When OA and OB are both Hermitian and unitary, Eq. (6) simplifies to44,67
To relate OTOCs to QELMs, we will take OA, OB to be Pauli operators.
Holevo information
The Holevo information between input and individual output states has been shown to be a viable alternative quantifier for QIS55,56,68.
In general, the Holevo information provides an upper bound to the accessible correlations between a sender and a receiver, in situations where quantum states are used as a medium for classical information transmission. More specifically, suppose Alice sends a classical message to Bob, encoding it into the choice of a state taken from an ensemble (eta equiv {{({p}_{i},{rho }^{i})}}_{i = 1}^{M}) for some integer M. Bob wants to recover the message from the measurement results on the state he received. Then, the appropriate quantifier for the correlations between Alice and Bob is the accessible mutual information Iacc(A: B)68,69,70. This is defined as the classical mutual information of the joint probability distribution
maximized over all POVMs ({boldsymbol{Pi }}equiv {{{{rm{Pi }}}_{k}}}_{k}) that Bob can perform on the state he receives. Further maximizing Iacc(A: B) over all possible ensembles η, gives the classical capacity of the channel representing the dynamics71. However, the accessible information is often hard to compute, due to the optimization involved in its definition. Nonetheless, Holevo’s theorem upper bounds Iacc(A: B) in terms of the Holevo informationχ(η), whose computation notably does not require to perform an optimization70,71:
where S(ρ) denotes the von Neuamm entropy of ρ.
To relate QIS to the estimation accuracy of QELMs we want to study how the information accessible locally from the output qubits evolves over time. Let us then consider the dynamical maps ({{{Phi }}}_{t}^{(j)}) which describe the evolution up to time t, followed by a partial trace over all but the j-th output qubit. Denoting with
the ensemble obtained applying ({{{Phi }}}_{t}^{(j)}) to each state in η, the local Holevo informations ({chi},({{{Phi}}}_{t}^{(j)}(eta ))) then quantify the information recoverable from the j-th output qubit, at time t, for each reservoir qubits j = 1, . . . , N. The channel ({{{Phi}}}_{t}^{(j)}) thus captures how input states evolve into the j-th marginal reservoir qubit over time, with the Holevo information (chi ({{{Phi }}}_{t}^{(j)}(eta ))) providing an upper bound on the information about the input states that can be recovered by measuring that reservoir qubit. The connections between mutual information, Holevo χ, and QIS, have been further explored in42,53,55. In particular, the extreme values of the Holevo χ reflect into deeply different behaviors of the channel: namely, when the Holevo χ vanishes, input states become indistinguishable at the output, so that no useful information can be extracted. By contrast, for larger values of χ, there are measurement choices that allow to distinguish different input states with minimum error rate.
Following55, we consider the Holevo information with unbalanced prior probabilities pi = 1/M. Using unbiased priors more closely relates to the task of parameter estimation in QELMs, where the estimation is performed without assuming any prior knowledge of the input states.
It is to be expected that the local Holevo information is closely related to the reconstruction performances of QELMs, as it quantifies the maximum achievable asymptotic transmission rate when maximized over input ensembles71. While we do not perform this optimization explicitly, there is a clear link between achievable transmission rates and state reconstruction efficiency. Consequently, the Holevo information serves as an effective and easily computable measure of correlations for our purposes. Namely, the Holevo information provides a straightforward quantifier of the correlations between input states and local output states, serving as a natural indicator of the information about the input state recoverable from the outputs.
Reservoir dimension
The estimation accuracy of QELMs was previously shown to depend on the reservoir dynamics23,32,33, and in particular, for time-independent Hamiltonian dynamics, on the topology of interactions32. However, as we will show, if systems are left to evolve beyond the scrambling time most of these differences disappear. We find that in all the cases we studied, shown in Fig. 1, reconstruction remains possible beyond the scrambling time with a good level of accuracy without the need to fine-tune the interaction time. Furthermore, we find that the Holevo information correlates with the reconstruction MSE even where the OTOC does not, highlighting a difference in the QIS features they measure.

The different interaction topologies, chain (C), ring (R), and fully connected (FC) correspond to different Hamiltonian terms ({H}_{{rm{res}}}), while the two input couplings, single link (SL) and multi-link (ML) to different Hamiltonian terms Hinj. The dashed black lines in the figures represent interaction terms between input and reservoir qubits, while the solid blue lines represent interaction terms between reservoir qubits.
In Fig. 2 we report the reconstruction MSE as a function of the reservoir dimension—from 3 to 7 qubits—for the different interaction topologies, with the SL input coupling, for short (t = 0.25) and longer (t = 5) interaction times. This choice of injection scheme ensures a constant number of injection links while increasing the dimension of the reservoir. Note that when the reservoir contains less than 4 qubits there is not enough information to retrieve the input state, which explains the higher MSEs for those points. The data shows that although at short times we reproduce the distinction between the different interaction topologies reported in32, for longer times these differences disappear. This suggests that the propagation of information through the reservoir relatively quickly compensates and cancels out possible initial differences in the structure of interactions. These findings are further corroborated by studying the reconstruction MSE corresponding to instead letting the whole input+reservoir system evolve unitarily. As shown in the figure, if instead of random Hamiltonian evolution we consider Haar random unitary evolutions, which generally result in highly correlated systems, we get the same results given by different Hamiltonians at long evolution times. This suggests that the long-time behavior of generic types of Hamiltonians approaches the behavior given by Haar random unitaries, which are known to be optimal to estimate arbitrary observables of input states32,72,73.
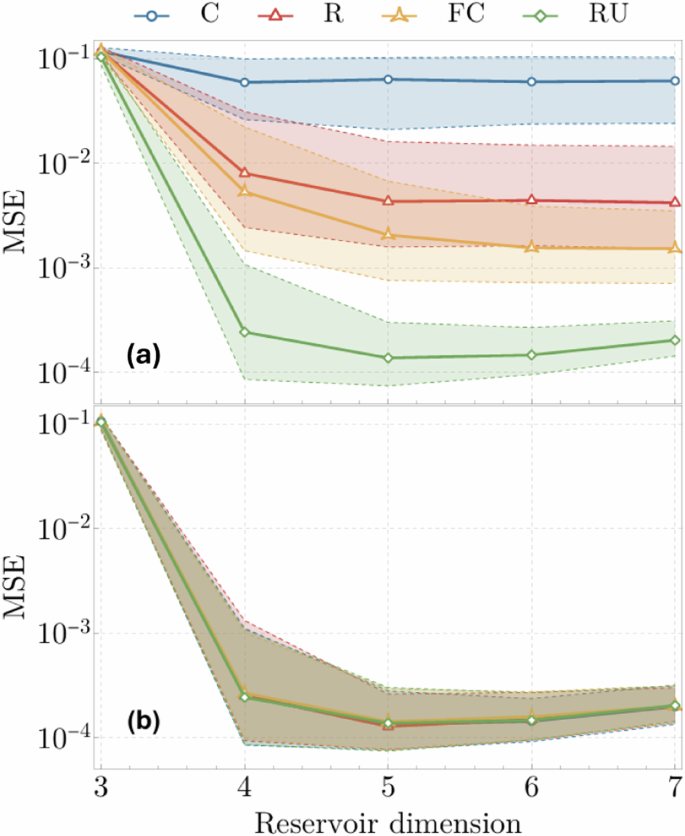
The evolution time in the upper panel (a) is t = 0.25 and in the lower panel (b) is t = 5. Each point represents the median of the MSEs computed on an ensemble of 500 random Hamiltonians, with sampling statistics of 106 for both training and testing in each case. Training and testing sets were each comprised of 50 random states. Errors bars represent first and third quartiles of the data. In addition to the standard topologies C, R, FC defined in Fig. 1, we also report the MSE obtained letting the whole input and reservoir system evolve unitarily with a Haar random unitary (RU).
Estimation accuracy and QIS
We then study in Fig. 3 the time-dependence of the MSE, and relate it with OTOC and local Holevo information. Doing so reveals that the different topologies converge to the same behavior for evolution times longer than the scrambling time, as defined by the saturating OTOC. This data also shows that simply studying the OTOC is not sufficient to predict the reconstruction MSE, as the OTOC always monotonically increases until saturation. On the other hand, the Holevo information more closely follows the MSE, as expected from it quantifying correlations between inputs and local output qubits. In all topologies, the MSE eventually saturates to an asymptotic value of (1.8 ± 0.5) × 10−4, the averaged χ to (2.5 ± 1.2) × 10−3, and the OTOC to C = 0.997 ± 0.003. We also note how having more interaction terms in the network shortens the scrambling time, and thus how long it takes the system to reach the saturation regime. This can be traced back to the additional interaction terms allowing information to spread faster throughout the reservoir. In Fig. 4 we report the time-dependence of the condition number κ for all different topologies. The condition number quantifies the degree to which relative stochastic errors are amplified in the testing stage, and is another easily computable quantity that gives insight into the numerical stability of the linear problem associated with a QELM, and therefore its associated estimation performances.
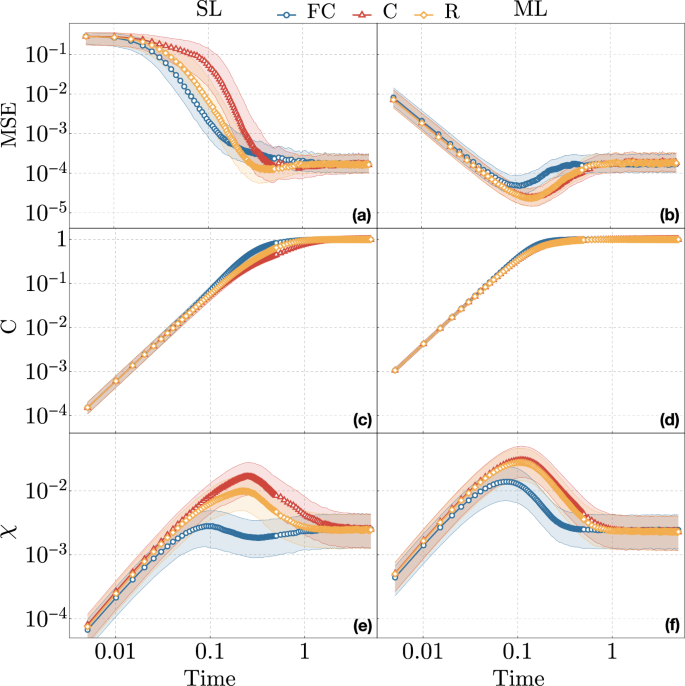
Reconstruction MSE in the upper panels (a)-(b), two-point correlation function C in the central panels (c)-(d), and local Holevo information χ in the lower panels (e)-(f), as a function of time, for different interaction topologies, as a function of time in the interval t ∈ [0, 5]. In each plot we present the data corresponding to the three interaction topologies, FC (blue circles), C (red triangles), R (orange diamonds), outlined in Fig. 1. The left realizations (a)–(c)–(e) refer to the SL scheme, while the right realizations (b)–(d)–(f) the ML scheme. In each case, we present the median results over 500 realizations of random Hamiltonians with the corresponding topology, with a reservoir of N = 7 qubits plus a single input qubit. The error bars show the first and third quartiles around the median. For the MSE we used sampling statistics of 106 in both training and test, both of which were performed with training and testing dataset comprised of 50 random states each.
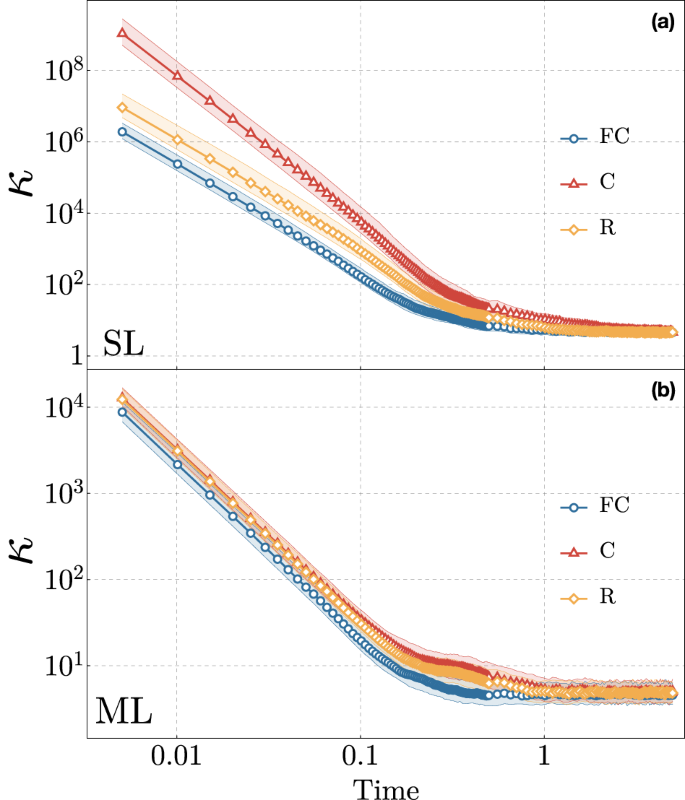
Condition number of Ptrain for the topologies of Fig. 1 with SL in the upper panel (a) and ML in the lower panel (b) coupling schemes, for different evolution times t ∈ [0, 5]. In each topology and coupling scheme, each point gives to the condition number averaged over 500 random Hamiltonians, a reservoir with N = 7 qubits, and sampling statistics of 106 for both training and testing. The error bars represent the first and third quartiles. Training and testing were conducted with 50 states each. The long-time condition numbers are κ = 4.6 ± 1.1 and κ = 5.1 ± 1.2 for SL and ML schemes, respectively.
A phenomenon characteristic of ML-coupled systems seen in Fig. 3 is a transient regime where reconstruction accuracy is better than its asymptotic value, which is also reflected in higher values of the average χ corresponding to the same evolution times. This is due to the direct couplings in ML systems allowing information to initially spread and become locally retrievable from all reservoir qubits, to then become partially lost to the correlation at longer times, as can be seen from Fig. 5d–f. Furthermore, for both injection schemes, right before the saturation, C and R topologies counter-intuitively achieve somewhat better accuracies than the FC one—this can be traced back to more information being accessible locally for these schemes.
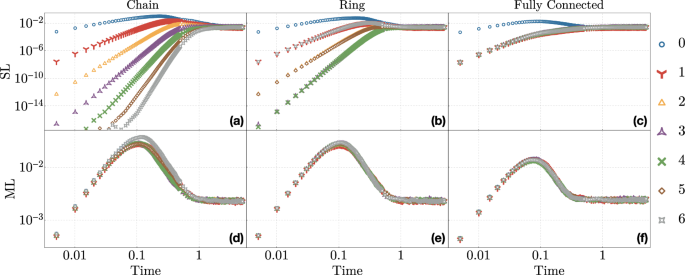
Distribution of the Holevo information among the nodes of the reservoir for SL (upper panels a–c) and ML (lower panels d–f) input coupling, and for chain (left panels a, d), ring (central panels b, e), and fully connected (right panels c, f) interaction topologies. Each figure reports the Holevo χ corresponding to each of the N = 7 reservoir qubits, here labeled from 0 to 6, for different evolution times t ∈ [0, 5]. Each data point is the median of the dataset obtained over an ensemble of 500 random Hamiltonians.
A feature worth pointing out in the results of Fig. 3 is how in some cases the average χ seems to contradict the value of the MSE. This is particularly evident for FC topologies with SL coupling in the transient regime, which display a lower averaged χ and at the same time a lower MSE. This apparent paradox can be traced back to this data reporting only the averaged Holevo χ. To gain further insight into this phenomenon we report in Fig. 5 the time-dependence of χ corresponding to each node, averaging only over the three input ensembles discussed in section “Holevo information”. This data shows that in the transient regime information can be asymmetrically distributed across the reservoir nodes. In particular, χ tends to be much higher for reservoir nodes close to the input. Having few such nodes with a high χ and many other nodes with vanishingly small χ results in a relatively large average χ even in situations where the number of reservoir qubits correlated to the input is not sufficient for state reconstruction. On the other hand, for ML-coupled systems information spreads much more symmetrically, and thus also the average χ is inversely correlated with the MSE, as expected. Beyond the scrambling time every single χ saturates to the same value of χ ≃ (2.5 ± 1.2) × 10−3, as expected from Fig. 3.
Overall, all the reported data shows a robust convergence to a regime where state estimation is possible with the same performances granted by random unitary dynamics, without the need to fine tune the interaction times. The initial differences between interaction topologies — attributable to different rates of information spreading — gradually converge to a uniform behavior over longer timescales, once information has spread evenly across the network. Furthermore, if such fine-tuning is feasible, even higher performances are possible for some types of interactions in the transient regime before the scrambling time.
Discussion
We provided strong evidence that QELM-based accurate reconstruction32,33 with local measurements is possible well beyond the scrambling time for several types of dynamics. In fact, we showed that for such evolution times, the reconstruction performance is identical to the one obtained with Haar-random local unitaries, which result in the maximum amount of distributed correlation across a system. These findings are interesting for both their experimental implications, and for the insights they provide into the relations between QELMs and QIS.
From an experimental perspective, our findings mean that for many types of dynamics there is no need to fine-tune the evolution time for the purpose of reconstructing properties of input states via QELMs. As long as the system is left to evolve long enough for the information to spread uniformly, accurate reconstruction is always possible. The evolution time must still remain fixed across different measurements, but its precise value does not need to be known to the experimenter.
At a more fundamental level, our findings offer a novel perspective into the nature of QIS and its relations to QELMs and state reconstruction tasks. Even though a scrambling system is considered to be one where information is hidden in the correlation and is locally irretrievable, our results highlight that—at least for relatively small systems—the opposite is true from a state estimation perspective: when information is left to spread uniformly throughout the reservoir qubits, the residual local information is still sufficient to retrieve arbitrary properties of input states.
In summary, our results pave the way for robust experimental state reconstruction schemes that do not rely on accurate knowledge of the underlying dynamic or fine-tuning of the experimental apparatus, and furthermore suggest that the way information spreads locally for scrambling system might be a useful resource for quantum state estimation purposes.
Methodology
In this section, we will give the technical details on how we generated the tested dynamics and computed reconstruction MSE and QIS.
As reservoirs, we consider (N + 1)-qubit systems undergoing a time-independent unitary evolution, with the first N qubits making up the reservoir, and the “in” qubit accommodating the input state. The overall evolution is generated by the Hamiltonian (H={H}_{{rm{res}}}+{H}_{{rm{inj}}}), with ({H}_{{rm{res}}}) the interaction between the reservoir qubits, and Hinj the interaction between input and reservoir. The interaction between reservoir qubits is modeled by a general Hamiltonian of the form
where the indices k, j = 1, . . . , N run over the reservoir qubits, and ({{{sigma }_{j}^{alpha }}}_{alpha = 1}^{3}) are the Pauli matrices acting on the j-th-qubit. To study how different topologies affect estimation accuracy, we consider systems where the reservoir qubits are arranged in a chain (C), a ring (R), or are fully connected (FC). The interaction between input and reservoir has the form
We consider two types of interaction between input and reservoir: a “single link” (SL) coupling scheme (({J}_{k,{rm{in}}}^{alpha ,beta }={J}_{k,{rm{in}}}^{alpha ,beta }{delta }_{1,k}), where the input qubit interacts with a single reservoir qubit, and a “multi link” (ML) coupling scheme where the input directly interacts with all reservoir qubits. These different interaction topologies are summarized in Fig. 1. In each case, the interaction parameters (scriptstyle{J}_{ij}^{alpha ,beta }) and ({{rm{Delta }}}_{i}^{alpha }) are sampled uniformly at random in the range [− 1, 1] and [− 0.1, 0.1], respectively. For each topology, we tested 500 random Hamiltonians. Unless differently specified, we considered a reservoir comprised of N = 7 qubits. The sampling statistics is fixed to 106 in each case. As the MSE is known to scale as 1/N with N the sampling statistics, there is no loss of generality in fixing this value, since we are only interested in the topology effects on the performances.
For QELMs we focus on the on a single qubit state tomography, that is, we fix ({{bf{Y}}}_{ij}^{,text{train},}={rm{Tr}}[{sigma }_{i}{rho }_{j}^{{rm{train}}}]), from the estimated expectation values of σz on the reservoir qubit after the evolution.
To relate this with QIS, we then compute the OTOC using eq. (7) with ({{bf{O}}}_{A}={sigma }_{i}^{z}), i = 1, . . . , N, and ({{bf{O}}}_{B}={sigma }_{{rm{in}}}^{alpha }), α = 1, 2, 3 as input node operators:
We will then consider the average of this quantity over i and α37, to quantify the average correlation between the output local measurements and target observables we mean to reconstruct:
Finally, following the notation in section “Holevo information”, we compute the average Holevo information fixing as input states the eigenstates of the three Pauli matrices. More explicitly, we compute the Holevo information with respect to input ensembles {(p1, ρ1), (p2, ρ2)} with pi = 1/2 and ρ1, ρ2 the eigenstates of one of σx, σy, and σz. As dynamical maps we use ({{rm{Phi }}}_{t}^{(k)}(rho )={{rm{Tr}}}_{bar{k}}[{e}^{-iHt}rho {e}^{iHt}]) with ({{rm{Tr}}}_{bar{k}}) denoting the trace over all but the k-th qubit. These choices ensure we obtain a quantity which directly relates to the amount of information about the expectation values of σx, σy, σz retrievable from local measurements on the reservoir. We finally compute the average for each k, obtaining a local Holevo information corresponding to each reservoir qubit. The resulting quantifier thus provides an easily computable upper bound for the correlations between the input state at t = 0 and the j-th output qubit at time t.
Responses