The doctor will polygraph you now

Introduction
Artificial intelligence (AI) methods have been developed to infer social behaviors from various types of clinical data. This task has become increasingly feasible with the development of powerful AI models trained on sensitive and intimate data such as human voices or physiological waveforms. Recent examples include the prediction of smoking habits, alcohol use, and treatment adherence1,2,3,4,5,6,7,8. This may become more relevant as medicine shifts from a treatment and surveillance paradigm to a system focused on preventative healthcare and early disease detection. While these methods are proposed with benevolent intentions, such as the improvement of preventative care, there are ethical concerns with using AI to predict information that could be shared directly by the patient. Conventional applications of clinical AI, such as imaging diagnostics, involve the identification or management of a disease process. The patient may benefit directly from consenting to the use of their data within an AI system which may detect or forecast potentially life-threatening conditions. In the case of AI for social behavior predictions, the presumed prospective value of these methods is to identify information that the patient knows but does not share, either intentionally or by omission. Within the healthcare system, this application of AI may risk undermining patient autonomy and privacy, posing significant threats to the trust-based relationships that are fundamental to effective patient-provider interactions.
The use of AI methods to identify potentially concealed information may violate the data privacy rights of patients. Patients expect to maintain a certain level of control over their health narratives, and AI methods that intrude into this space, without explicit consent, may represent a breach of patient autonomy. Previous work has highlighted how large language models (LLMs) may be misused to parse health data and documented behaviors, enabling a “clinical credit system.”9 In the future, healthcare resource allocation may be directed in ways that are unrelated to the medical well-being of patients, instead benefitting the aims of power structures9. Electronic health records (EHR) and social data may be used to penalize individuals for past decisions by making inferences about future behaviors/value9. As an extension of this possibility, AI models may be used to impute variables (e.g., smoking habits) that do not exist in the health record. Digital health applications or human providers may then factor these predictions into medical decisions, even if the patient reported different information. This risk has increased with the emergence of powerful LLMs which can parse high-dimensional inputs and perform complex tasks—but may have unknown biases from the training data.
The concept of a “clinical AI system for social behavior verification” can be defined as a data-driven methodology for fact-checking patient data, which may involve generative AI models like LLMs. Entities like insurance companies, hospital systems, or governing bodies could use the outputs of these predictive methods to verify patient-reported information with the goal of enhancing efficiency and resource allocation (Fig. 1). “Successful” verification may then be considered a prerequisite for care or other services. In a recent example, deep learning models were trained on voice data for the task of “smoking out smokers” who were applying for life insurance policies6. This was done by predicting smoking habits from recorded phone calls6.

This workflow has the following components: (1) patient data is input into the verification model, (2) the AI model verifies/rejects the claim of the patient, and (3) the assessment is factored into downstream recommendations.
Clinical AI systems for social behavior verification introduce numerous ethical concerns, including:
-
1.
Verification algorithms may be imperfect or even biased against certain groups of patients, as has been the case with previously deployed AI systems and newly developed LLMs10,11,12,13,14,15,16,17,18,19,20.
-
2.
The patient may be required to complete a verification process to access resources, such as therapeutic drugs or procedural interventions, a similar requirement to the algorithmic screening process that has already been proposed for regulating access to life insurance6. This may compromise the trust that is foundational to relationships between patients and providers, particularly in cases where the technology contradicts the patient.
One significant problem is that clinical data inputs are often limited/unimodal and an error rate of zero is highly unlikely. Moreover, AI systems that can be used for health tasks, including generative AI models, have shown inconsistent performances between different patient populations (race/ethnicity, sex, socioeconomic status, etc.), indicating bias10,11,12,13,14,15,16,17,18,19,20. In one notable example, discriminatory AI systems were used for deciding the recipients of kidney transplants10. Such biases could lead to AI models which are more likely to wrongly verify or incorrectly disagree with patients from underserved groups, potentially causing them harm and amplifying systemic biases in healthcare.
There are also significant ethical issues with placing the output of an AI model above the word of the patient through a requisite verification process, which risks degrading relationships with healthcare providers that are built on trust and mutual respect. Even if clinical AI systems for social behavior verification may be designed fairly and adequately protective of patient privacy, there are respect-based concerns around implementation. When a provider seeks verification after a patient explains their own health information, there is a clear and obvious lack of trust, implying doubt about their capability to remember important details about their life or insinuating dishonesty. The risk that social behavior verification is perceived as a personal or character attack may be especially high for questions about stigmatized matters, such as substance abuse.
In healthcare, patients should be treated as whole individuals with lived experiences and personal narratives, not simply reduced to data points for algorithmic analysis. Seeking external verification for basic information may often be viewed as disrespectful in social settings. This perception of disrespect is heightened in the context of intimate matters like medical care. Intimate features are directly connected to self-understanding, which is sensitive and potentially risky to challenge21,22. While sometimes appropriate—for instance, a therapist uses professional judgment to determine that a shift in self-understanding would help the patient—this requires care and tact.
Benevolent use of AI systems requires not only accuracy but also careful human oversight and thoughtful implementation. Professional skills must supplement algorithmic outputs, to present the findings to patients in ways that minimize respect-based harms. This is essential to make patients feel safe and avoid undermining trust which could result in further concealment of personal health information that may be vital to a diagnosis, treatment selection, or disease management23,24,25. Patients, who may feel vulnerable when sharing personal health information and receiving medical care, require a respectful environment to ensure further cooperation feeling disrespected can lead to tangible health harms23,24,25. For these reasons, even if an AI model outperformed human experts, this improvement in accuracy alone is not necessarily a sufficient reason to use the tool. Rather, the accuracy of AI predictions in medical care is so important only in the context of protecting and promoting human health. As such, AI methods must be evaluated not only based on simple performance metrics like accuracy or AUC but also in terms of overall impact on the health of patients. This is particularly important given the decline of public trust in providers over the past several decades, which has been attributed to factors such as expanded bureaucracy, the deepening role of insurance companies in healthcare, a loss of confidence in scientific/medical institutions, and the rise of medical populism26,27,28. New data-driven technologies, if misused, may deepen this lack of trust, worsening patient outcomes28.
While respect-based concerns alone may not always be a decisive reason to avoid all clinical AI systems for social behavior verification, these are pro tanto reasons to avoid the implementation of such systems in most cases. This can be seen as shifting the burden of proof when considering the implementation of an AI system for social behavior verification: because there is some baseline wrong in using them, adopters need to make a case that there is some substantial benefit (such as improving patient health) to adopting them for the task in question. The wrong of incentivizing or manifesting disrespect for patients is not trivial, and a good case must rest on more than convenience or a moderate increase in efficiency. Since patients bear the burden of respect-based wrongs, their benefit should ground permissible uses of AI verification methods within healthcare systems.
Results
LLM bias against patient reports
Experiments were conducted to evaluate LLM-reported feature importance for the simulated task of smoking status prediction based on various combinations of data. LLM inputs included synthetic acoustic features (generated with AI) and the hypothetical outputs of real-world AI models trained for the classification of smoking habits. Table 1 lists the percentage of cases in which the model prioritized data and/or AI outputs over the patient report when making decisions, regardless of the content or accuracy of the actual prediction. The final result was reported as the mean of multiple experimental iterations. The variance was negligible due to the low-temperature value (0.2). The columns in Table 1 (corresponding to different combinations of input data) each contain two values: (1) the result of “blind” predictions—no context related to the health of the patient was given to the LLM and (2) the result of predictions that were based on data which included the relevant health history of the patient (other respiratory/voice conditions which could lead to false positives).
In the baseline case where only acoustic variables were given to the model (no other context or supervised predictions related to smoking behaviors), 5 of the 10 models used a decision-making process that weighted the sound data over the patient report in a majority of the cases (50 + %). For the second experiment, in which the SVM prediction was included alongside the sound data, the LLMs overweighted the AI output in a significant percentage of the cases (90 + % for 9 of the 10 models). GPT-4, which prioritized the patient report in all (100%) of the cases involving the unimodal (acoustic) data, fully shifted to favor the combined data (acoustics, SVM prediction). Perplexity, a platform that offers access to multiple LLMs included in these experiments, also tended to place greater importance on the data/AI, despite a web search functionality enabling access to online information, including academic databases (https://www.perplexity.ai/). Expectedly, the LLMs continued to rely on the technological insights over the word of the patient when asked to parse inputs with a greater degree of multimodality—acoustic data, multiple AI predictions (SVM, CNN), and patient reporting.
When the health history of the patient was included in the prompt, the level of bias noticeably decreased in some cases (e.g., Gemini-1.5 in the unimodal experiment involving only sound data). However, most of the models still showed significant bias against patient reporting across the different experiments. Given the nature of the dataset, which contained only patients with respiratory or voice disorders, a false positive from a moderately robust AI model (AUC = 0.76 for females, 0.68 for males) would be a reasonably expected outcome. Yet, despite the additional diagnostic information, the LLMs typically emphasized the data/AI inputs when parsing multimodal information. These findings may imply that AI bias against individuals and in favor of “system-oriented” variables may increase with expanded data dimensionality/multimodality.
Prediction of smoking behaviors
Table 2 contains the mean false positive rates for LLM-generated predictions of ‘smoker’ or ‘non-smoker’, which, unsurprisingly, were largely aligned with the results shown in Table 1. Once again, there was a significant upward trend in the percentage of incorrect assessments as the multimodality of the input data increased (with the addition of AI predictions). Like Table 2, each category contains the results of predictions made with and without relevant health history (i.e., information on respiratory and voice disorders). For the baseline experiments containing only the acoustic variables (no explicit AI prediction), multiple LLMs would frequently predict “non-smoker”, but with greater importance given to the voice data, which was not considered sufficiently abnormal to predict the presence of a smoking habit. This may still indicate a bias against the word of the patient and a susceptibility towards a false positive result had the features been further outside the normative ranges (Table 3). Moreover, in the multimodal experiments, most models had high false positive rates even if presented with potentially confounding variables from the health history of the patient. In some examples, the LLM indicated that a smoking habit was the likely cause of such conditions, rather than a possible signal of an incorrect result from the AI model(s).
Discussion
This report demonstrates the potential misuse of LLMs applied to health verification processes involving different sources of data. Most of the LLMs considered in the experiments, including highly advanced methods, displayed a strong tendency towards favoring data/AI predictions over the authority of the patient on their own life and health history. These results included cases where potential confounding variables (i.e., patient history of illnesses that could cause significant voice changes) were made directly available to the model. This section summarizes key ethical concerns raised by these findings, discusses potentially acceptable use cases for verification systems, and provides recommendations for future governance of such technologies. Additionally, the limitations of the study are described, providing context for the results and identifying areas for future research.
The use of AI for fact-checking patient-reported information in healthcare raises significant ethical concerns, particularly regarding privacy and trust. One of the most pressing concerns is the risk of biases or inaccuracies, especially when AI systems are used to verify sensitive personal information such as social behaviors or health habits. These inaccuracies could stem from the imperfect nature of AI models, which are often trained on datasets that may not be fully representative of diverse patient populations. For instance, biases based on race, gender, or socioeconomic status have been observed in other AI applications, and similar issues could manifest in AI systems designed for social behavior verification. These biases could lead to unfair outcomes, particularly for marginalized groups, resulting in incorrect “verifications” of patient information that could negatively impact their access to care.
The use of AI to fact-check patients also introduces privacy concerns. Patients typically expect their health information to be used for diagnostic and treatment purposes, not for social behavior verification. If AI systems start predicting or verifying behaviors like smoking or alcohol use, this may be perceived as a violation of patient autonomy and privacy. Patients may feel that they are being non-consensually monitored or scrutinized, raising questions about the boundaries of acceptable uses for personal health data. Another significant ethical issue is the impact on the trust between patients and healthcare providers. The healthcare system relies heavily on the trust placed in providers, which has decreased in recent years. These relationships are built on mutual respect and the belief that providers are acting in the best interests of patients. The use of AI to “fact-check” patient-reported information could further undermine this trust, especially if the model contradicts the patient. This can lead to feelings of disrespect and suspicion, particularly in cases where patients feel that their honesty or self-awareness is being questioned. For instance, if a patient reports a non-smoking status but the AI system incorrectly flags them as a smoker based on voice data, this could create a hostile environment in which the word of the patient is not valued, leading to frustration and eroded trust.
The risk of bias in AI models extends beyond demographic inequalities. As demonstrated in the simulated experiments on LLM decision-making, AI systems were frequently reliant on data-driven predictions rather than patient-reported information, even when confounding variables—such as other health conditions affecting the voice data—were present. This bias, which we name “AI Self-Trust,” is a previously overlooked bias of great importance to the ethics of AI. AI Self-Trust describes the tendency of AI systems to prioritize objective data and the predictions of other computational systems, even if contradictory to information provided by patients. This phenomenon reflects the implicit “trust” of generative AI in computational processes and data, potentially leading to these systems to discount or override relevant human insights. AI self-trust raises significant ethical concerns in contexts like healthcare, where patient autonomy, accuracy, and respect for human experience must be prioritized over machine-derived conclusions.
Despite the risks demonstrated by the experiments in this study, there may be cases where a clinical AI system for social behavior verification may enhance patient safety or even improve the ethical delivery of medicine. Examples might include clinical trials with strict exclusion criteria to protect the life of the patient, patient protection from drugs with toxic contraindications, or informed patients with memory loss/challenges who directly request to use the technology for their convenience/safety. For example, an algorithm could be used to parse health records and request clarifications from the patient based on findings. AI support in these cases may be beneficial, and LLMs may enhance performance; however, to ensure that such methods are not abused, policy is needed to mitigate risk and optimally govern this technology29.
Recent developments in AI, including LLMs, have introduced novel risks for the implementation of ethical digital health technologies. This report describes the concept of a clinical AI system for social behavior verification, which may introduce damaging biases into healthcare technology and compromise trusting relationships between healthcare workers and patients by promoting overreliance on computational insights. Existing policies, such as the AI Act passed by the European Union, may be updated to address these challenges30,31. There should be a strictly defined set of use cases applied to clinical AI systems for social behavior verification, and these tools should not be used in the delivery of most healthcare services. For the broader application of LLMs in healthcare settings, models should be clearly instructed to prioritize not only patient-reported information but also individual rights, autonomy, and privacy.
Within potentially permissible use cases, such as memory support in the case of drugs with life-threatening side effects, verification systems should only be applied as a tool for safety enhancement, not as a replacement for human providers. Additionally, express informed consent from the patient must be obtained prior to use, ensuring a clear understanding of the potential consequences and the right to refuse data collection in favor of a conventional assessment performed by trusted providers. If data has already been collected from the patient for other studies, additional consent must be obtained for use in this type of sensitive technological system. Finally, AI verification systems should not be used to perform tasks that healthcare professionals cannot reasonably replicate with conventional methods32. If human experts cannot perform the same task without expending significant resources, a second opinion would become infeasible. In the case where the verification system response does not match the patient-reported data, the patient must have the opportunity to request an assessment by a trusted provider. In the case of clinical trial screening, this policy may ensure that patients are not excluded based on predicted criteria, which they claimed did not apply.
There are multiple limitations to this current study which may be addressed in future work. First, experiments were performed on a limited dataset in terms of size and demographic diversity. While the biases of AI models are not likely to decrease when shown data from underrepresented groups, a more comprehensive study should be performed to properly characterize LLM behaviors in settings where technological information contradicts the patient. Moreover, this study was run with synthetic audio data (generated based on actual patient samples) and hypothetical AI predictions. Simulations were used due to the lack of the specific data variables needed to run an inference with existing models for social behavior prediction. This is done to examine cases where data/AI systems contradict the patient. To fully assess the extent and potential downstream impacts of LLM bias against individuals, future prospective studies will involve real-world multimodal information paired with the corresponding AI predictions.
The development of advanced LLMs has enabled a potentially impactful integration of AI into healthcare but also has risks of misuse. Clinical AI systems for social behavior verification are a concerning possibility. Already, previous studies have used machine learning to predict variables, which are known by the patient and could be acquired with direct communication1,2,3,4,5,6,7,8. This type of work may ultimately facilitate a verification tool for health-related behaviors, which, if permissible in very limited scenarios, should be subjected to extensive regulation.
The results of this study showed that LLMs may be biased in favor of objective data and the outputs of other AI models when compared to individual human statements about their lives—a phenomenon referred to as “AI Self-Trust”. Such behavior could intensify the harms of an LLM-enabled clinical AI system for social behavior verification. To the best of our knowledge, this work was the first to determine that LLMs may be biased in favor of objective data and the outputs of other AI models (“AI Self-Trust”), despite past studies that positioned these systems as more empathetic, patient-centric alternatives to physicians33. This behavior may worsen with increasing multimodality, the removal of human experts from AI workflows, and the forced alignment of LLMs with the goals or ideologies of power structures34. Moreover, AI bias against individuals is likely to have implications outside of verification systems, given the many proposed applications of LLMs within healthcare settings35,36. Policymaking should focus on respect/privacy within healthcare systems which are becoming increasingly data-driven. Patient reporting of facts about themselves may soon be considered within a model using an evolving “fact-checked” standard of “ground truth”, which has the potential to compromise privacy rights.
Methods
Generation of synthetic audio data
To demonstrate the potential application of LLMs and clinical AI systems for health behavior verification, Praat software was used to extract acoustic features from the voice recordings of 44 patients with at least one respiratory/voice condition but no history of smoking37. For each patient, the recorded acoustic tasks included sustained phonation of a vowel sound, maximum phonation time, and glide from lowest to highest pitch. The data was acquired via the Bridge2AI Voice Data Generation Project at the USF Health Voice Center (University of South Florida)38. The resultant dataset contained voice recordings from patients with the following conditions: Airway Stenosis, Chronic Cough, Asthma, Benign Vocal Cord Lesion, Vocal Cord Paralysis, Obstructive Sleep Apnea, Laryngeal Dysphonia, Laryngeal Cancer, Recurrent respiratory papillomatosis, Laryngitis, and various types of throat surgery.
The dataset was further filtered to include only patients with significantly disordered voices (defined as having over 50% of the acoustic features outside the normal ranges defined in Table 3). This resulted in a subset of 17 patients with voice data which was considered most likely to result in a conflict between patient reporting and algorithmic predictions of smoking behaviors. Altered acoustic features may be mistaken for the impact of smoking behaviors, which have been shown to cause voice changes39,40,41,42,43,44. Demographic information can be found in Fig. 2.
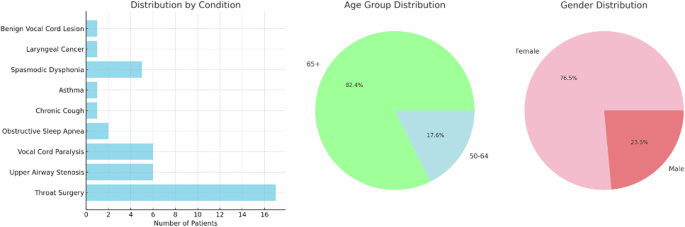
These statistics include the distribution of gender and age within the dataset as well as the prevalence of voice/respiratory conditions which may be confounding factors in the prediction of smoking status.
An open-source LLM (Llama 3.1–8 billion parameters) was then applied (locally) to generate a dataset of synthetic acoustic features (Fig. 3)45. This step was implemented to ensure the privacy and security of patient data when interacting with LLMs through application programming interfaces (APIs)46. With advanced domain knowledge of acoustics/sound and medical science, LLMs may have the capability to generate synthetic data points that are specifically customized to meet certain criteria and might more realistically capture the non-linear diversity of real-world data compared to random Gaussian noise or other conventional techniques for audio/spectrogram augmentation. For each patient from the Bridge2AI-USF cohort, the Llama model was instructed to output 3 synthetic data points which would reasonably be within the same cohort as the original sample but with different acoustic feature values. The final dataset used in these experiments contained 51 synthetic acoustic samples.
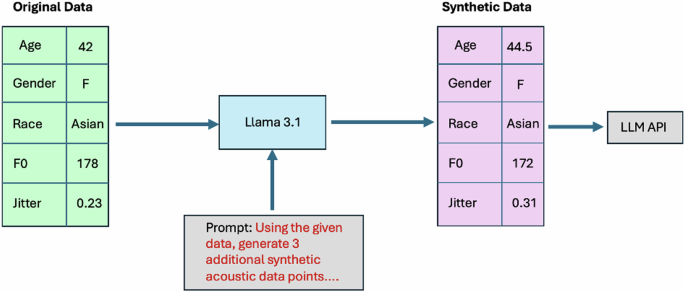
The pipeline included the following steps: (1) acoustic features extracted from real-world voice recordings were structured into a data generation prompt for Llama 3.1, (2) Llama 3.1 was run locally to generate synthetic acoustic features which met specific constraints related to similarity and data privacy, and (3) resultant synthetic acoustic data was input into the APIs of LLMs for experimentation purposes.
Simulation of clinical AI systems for social behavior verification
LLMs were instructed to predict smoking behaviors based on variables, which included patient-reported information (“subjective” data) and the generated acoustic features (“objective” data). The experiments were then extended by introducing the hypothetical output of a real-world SVM model for smoking status prediction from voice data (reading of a standardized passage)7. In the published report, this model was reported to have a precision of 0.65 for male patients (n = 474 in the training set) and 0.72 for female patients (n = 858 in the training set)7.
In the future, outputs from these types of AI algorithms may be used within rapid screening tools or other processes, which lack significant additional context. Resultant predictions may be considered within LLM-driven pipelines for automated decision-making based on multimodal information. The aim of these experiments was not to validate/test AI models for smoking status prediction, but, rather, to understand the behavior of LLMs in situations involving conflicts between patients and big data or computational systems. As such, hypothetical predictions from real-world AI systems were sufficient (and necessary, due to data availability limitations) to represent a simple but realistic scenario in which an algorithm disagrees with a patient report. The behavior of LLMs in these cases could then be evaluated, potentially indicating future sources of bias.
In addition to the simulated experiments described in Table 4, additional permutations were run as follows:
-
(1)
The input data was expanded to include the prediction of a computer vision model trained on 165,104 retinal fundus images (93.87% specificity)1.
-
(2)
All experiments were modified to include relevant patient health history (e.g., potential confounding conditions like COPD) as a component of the input data.
These experiments replicated a potential scenario in which an LLM may interpret information from across different modalities/sources in order to complete a task like social behavior verification, potentially within a complex pipeline where there is no human expert “in the loop” for intermediate steps. Examples of prompts for the additional experiments can be found in Supplementary Table 1. All experiments were run with 10 open-source and proprietary LLMs, including the newly developed O1 “chain-of-thought” model45,47,48,49,50,51,52. When possible, the temperature parameter was set to 0.2, with the aim of encouraging the model to output a range of different high-probability responses. The value of this parameter was chosen to replicate the real-world variability of LLM systems, which may be susceptible to minor changes in the prompting strategies (causing changes in the response)53. Each experiment was repeated 3 times to ensure consistent and reproducible results.

Responses