The effect of sport in online dating: evidence from causal machine learning
Introduction
Human interactions that traditionally occurred in physical settings have increasingly shifted to the online world, a trend substantially accelerated by the COVID-19 pandemic. This shift has also impacted human mating, leading to the emergence of numerous novel online dating formats (Wu and Trottier, 2022). Consequently, online dating has become a pivotal instrument for human mating. Rosenfeld et al. (2019), for instance, demonstrated that online dating has become the predominant method for heterosexual couples to meet in the US. Similarly, a study by the Pew Research Center found that online dating has become a mainstream method for forming romantic relationships, facilitating more diverse interactions (McClain and Gelles-Watnick, 2023). Indeed, Cacioppo et al. (2013) found that over one-third of marriages in the US can be traced back to an initial connection made through online dating platforms.
Understanding the mechanisms behind human mating in online dating environments is crucial for elucidating societal evolution and developing algorithms that enhance the efficiency of matching potential partners. Human mating dynamics in these settings rely heavily on the information users share on their profiles. Details such as interests, preferences, and personal characteristics shape interactions and decisions within digital platforms, influencing initial attraction and relationship development. This information serves as a fundamental basis for studying how individuals present and perceive themselves in virtual dating landscapes. While the role of socio-demographic (e.g., age; Hitsch et al. 2010a) and psychological (e.g., extroversion; Cuperman and Ickes, 2009) characteristics have been extensively studied (for a summary, see: Cuperman and Ickes, 2009; Hitsch et al. 2010a), empirical evidence on the impact of behavioral traits remains sparse (Schulte-Hostedde et al. 2012). In particular, the impact of sports activity on human mating is not yet fully understood.
This paper aims to address this gap and, to the best of our knowledge, is the first to investigate the causal effect of sports activity on human mating within online dating environments. In particular, it considers sports activity as measured by sports frequency in the following four levels: weekly, monthly, rarely or never. Its effect on human mating is studied via contact chances defined as message probability within the online dating platform. Furthermore, it uniquely analyzes the heterogeneity of this causal effect by employing novel causal machine learning methods, offering a comprehensive and nuanced understanding of how sports activity influences mating behavior online.
We study the effect of sports activity on human mating based on the data from an online dating platform focused on the search for a potential partner for a serious relationship. We leverage a unique dataset from an online dating platform, consisting of a sample of more than 16,000 users that form altogether almost 180,000 interactions. The data allows us not only to map all online interactions among users, including visiting a user profile and contacting a user via private message, but also to observe more than 600 user characteristics describing the socio-demographic, psychological, and, notably, behavioral traits, including the frequency of the sports activity. This setting provides a credible research design by eliminating potential sources of endogeneity, focusing on initial one-way interactions between users, and observing essentially the same information that an actual user would see. Hence, we identify the effect of sports activity, as measured by its frequency, on contact chances, as measured by message probability, by relying on the unconfoundedness assumption. We exploit recent advances in causal machine learning to estimate the causal effect in our large-dimensional setting in a flexible way while considering potential effect heterogeneities. In particular, we apply the Modified Causal Forest (Lechner and Mareckova, 2022), an estimator that reams the concept of Causal Trees and Forests, by improving the splitting rule to account for selection bias, while allowing for multiple treatments, as applicable to our measure of sports frequency.
This paper contributes in several ways. First, it provides new insights into the literature on human mating by demonstrating that sports activity, a key behavioral trait, affects contact chances in online dating. Second, this paper supports social science research in estimating causal effects in large-dimensional data environments by showcasing an empirical approach, which allows for a very flexible estimation of average effects as well as a systematic assessment of underlying heterogeneity. Third, this paper helps individuals to increase their dating success by exhibiting how sports activity can contribute to the likelihood of being recognized by potential partners, highlighting the relevance of sports activity not only from health but also from a human mating perspective. In turn, this paper serves product developers to improve the architecture of online dating platforms by emphasizing the relevance of sports activity. Fourth, this research underscores the significance of physical health, enhanced through sports activity, in facilitating romantic relationships. Regular physical activity not only boosts one’s attractiveness and chances of matching with a potential partner but also contributes to better mental and physical health within the relationship, creating a positive feedback loop (Warburton et al. 2006). Finally, it provides an additional argument for the promotion of physical activity to support the World Health Organization’s (WHO) fight against obesity (James, 2008).
Literature
In what follows, we review the related theoretical and empirical work on sports activity and online dating.
Sports activity
Sports activity has been attributed with significant effects on various facets of human life, including physical and mental health as well as social outcomes, some of which are summarized below.
First, sports activity has been shown to positively affect health outcomes. For instance, Warburton et al. (2006), based on an extensive literature review, confirmed that sports activity helps prevent several chronic diseases, such as cardiovascular disease and diabetes. Similarly, Humphreys et al. (2014) found that sports activity reduces self-reported incidences of diabetes, high blood pressure, heart disease, asthma, and arthritis (for a review, see Eime et al. 2013; Penedo and Dahn, 2005).
Second, sports activity significantly affects mental health. For instance, Hillman et al. (2008) demonstrated that sports activity enhances cognition and brain function (for a review, see Janssen and LeBlanc, 2010; Strong et al. 2005). Additionally, sports activity has been shown to increase self-reported life satisfaction and happiness (Huang and Humphreys, 2012; Ruseski et al. 2014; Singh et al. 2023).
Third, sports activity impacts social outcomes. For instance, Caruso (2011) found that sports activity decreases property and juvenile crime among young adults. Furthermore, sports activity positively influences economic outcomes, such as wages and earnings (e.g. Lechner, 2009; Rooth, 2011), human capital (Lechner and Steckenleiter, 2019), and quality of work performance (Pronk et al. 2004). Sports activity is also linked to higher academic achievements (Felfe et al. 2016; Fox et al. 2010; Fricke et al. 2018; Lechner, 2017; Pfeifer and Cornelißen, 2010), improved concentration, memory, and classroom behavior (Trudeau and Shephard, 2008), and enhanced social relations (Eather et al. 2023; Stempel, 2005).
Online dating
In recent years, online dating has become a prominent topic in society as well as in academia (see e.g. Wu and Trottier, 2022, for a review). Human behavior and self-presentation are central to online dating, where individuals configure profiles to attract and engage with potential partners. Selective self-presentation allows daters to manage their image and communicate attributes linked to romantic compatibility (Appel et al. 2023).
Studies indicate that people often seek partners they perceive as desirable based on a hierarchy of attractiveness and compatibility, underpinned by demographic characteristics and profile management tactics (Bruch and Newman, 2018). For instance, Humberg et al. (2023) show that personality similarity alone may not drive initial attraction; rather, the emphasis on behavioral alignment and perception shapes desirability in these initial stages. In this context, sports-related self-presentation becomes significant, as displaying an active and sporty lifestyle aligns with attractiveness markers in both visual and behavioral terms, underlining societal ideals of health and vitality (Degen and Kleeberg-Niepage, 2021).
Additionally, matching algorithms amplify these dynamics by prioritizing users who reflect commonly desired traits, which can indirectly encourage users to present such characteristics on their profiles (Sharabi, 2022). Jung et al. (2022) highlight how online dating platforms design choice sets to maximize engagement and matching outcomes, noting that users strategically select and filter matches, adapting their profiles to increase compatibility likelihood within these limited choices.
In practice, dating app users may actively curate their profiles to appeal to this constructed hierarchy of desirability, which is shaped by both societal expectations and algorithmic suggestions. Consequently, investigating the role of individual-level characteristics, including the role of sports, in online dating provides insight into how users navigate these intersecting influences of self-presentation, desirability hierarchies, and compatibility algorithms to enhance their appeal and increase the likelihood of attracting desired matches.
In addition, both theoretical and empirical evidence highlight the importance of gender differences in online dating and the associated role of physical and socio-economic preferences (see e.g. Abramova et al. 2016, for a review). While physical attractiveness is a commonly desired feature for both male and female users (Whitty, 2008), female users tend to prioritize socio-economic attributes (McWilliams and Barrett, 2014; Ong and Wang, 2015). Moreover, recent evidence suggests that male and female users engage and process information in online dating context differently (Fink et al. 2023; Jiménez-Muro et al. 2024).
Sports activity and online dating
Sport, a common feature in online dating profiles, is often used to signal a healthy and active lifestyle that is considered attractive and desirable. For instance, Degen and Kleeberg-Niepage (2021) show that dating app users consciously curate their profiles to portray themselves as sporty and active. Wada et al. (2019) document that also older adults emphasize active lifestyles in their dating profiles. This aligns with societal ideals that associate physical fitness with health and vitality, which are important traits in the context of romantic attraction. Likewise, by incorporating sports-related imagery, individuals can signal their participation in outdoor or athletic activities, enhancing their profile’s appeal (Pleines et al. 2022).
Men, in particular, are mindful of how they present themselves physically (Waling et al. 2023). Men may balance the desire to appear athletic and fit with the need to avoid seeming overly narcissistic or vain. This tension underscores how sport, as a marker of fitness, plays a significant role in shaping perceptions of masculinity and attractiveness. Indeed, sports and arts represent the most popular displayed hobbies in online dating as shown by DatingScout in an in-depth descriptive analysis of more than 22 million profile pictures from online daters (Pleines et al. 2022). Another descriptive analysis of 500,000 users from the online dating platform Zoosk shows that profiles mentioning “sports” have above-average messaging rates, suggesting that sport is a desirable characteristic (Zoosk Inc., 2023).
Selected research studies also consider sports activity as a potentially relevant factor in explaining human mating, going beyond socio-demographic and psychological characteristics to explain human mating (for a detailed review, see Eastwick et al. 2014).
Schulte-Hostedde et al. (2008) investigated the impact of males’ sports disciplines on females’ willingness to engage in a relationship using an experimental setting. Their findings revealed that “team sport athletes were perceived as being more desirable as potential mates than individual sport athletes and non-athletes” (p. 114). The authors suggested that “team sport athletes may have traits associated with good parenting such as cooperation, likability, and role acceptance” (p. 114), explaining the higher desirability of team sport participants. However, their study was limited to comparing team versus individual sports, hindering a comprehensive assessment of the general effect of sports activity on human mating.
Similarly, Farthing (2005) also used an experimental setting to demonstrate that “females and males preferred heroic sport risk takers as mates, with the preference being stronger for females” (p. 171), interpreting heroic versus non-heroic sport risks as engaging in risky versus non-risky sports. However, the concerns about limited scope apply equally to Farthing’s findings.
Further research has explored the potential indirect effects of sports activity on human mating. For instance, previous studies have indicated that sports activity enhances attractiveness (Park et al. 2007), health (Warburton et al. 2006), and income generation (Lechner, 2009), all of which influence human mating (e.g. Eastwick et al. 2014; Hitsch et al. 2010a, b). Nonetheless, these studies remain inconclusive regarding human mating due to the lack of integration of relevant contextual factors (e.g., additional personal or sports characteristics) that affect mating.
In summary, although sports activity seems to influence human mating, a comprehensive assessment is still missing. Previous research has either overlooked important socio-demographic factors or has taken a narrow view of sports activity. These limitations are surprising, given that information about sports activity is prominently displayed on online dating platforms (Pleines et al. 2022). Moreover, sports activity affects many aspects of life, including physical and mental health, as well as social and economic conditions. Therefore, this study aims to provide a thorough analysis of the effect of sports activity on human mating, addressing these gaps.
Hypotheses
Several studies document the positive effects of sports activity on human life, including health and socio-economic benefits, among others (Lechner and Steckenleiter, 2019; Penedo and Dahn, 2005; Singh et al. 2023). Concurrently, sports activity is a common feature on online dating platforms, often intended to enhance self-presentation (Degen and Kleeberg-Niepage, 2021). However, the effects of sports activity on mating success in online dating are largely unknown. While recent descriptive evidence suggests that sports activity is related to higher messaging rates (Zoosk Inc., 2023), conclusive causal evidence for the effect of sports activity on mating success in online dating that captures the possible confounding factors and uncovers potential effect heterogeneities is missing.
Based on these theoretical and empirical insights, we postulate the following main hypothesis:
Main Hypothesis: Sports activity increases contact chances in online dating.
As such, we hypothesize that sports activity contributes positively to online dating outcomes.
Given the well-documented gender differences in online dating (Abramova et al. 2016; Fink et al. 2023), we further aim to study the potential heterogeneity of the hypothesized positive effect with respect to gender. As such, we extend our main hypothesis as follows:
Sub-Hypothesis 1: The effect of sports activity on contact chances in online dating is not the same for men and women.
Accordingly, we hypothesize that sports activity has differential effects for male and female users.
In addition, previous work suggests that gender differences in online dating are often attributed to differential preferences related to socio-economic characteristics such as age, education, and income (Abramova et al. 2016; McWilliams and Barrett, 2014; Ong and Wang, 2015). Therefore, we further extend our main hypothesis to reflect on the effect heterogeneity:
Sub-Hypothesis 2: The effect of sports activity on contact chances in online dating differs based on socio-economic characteristics.
Thereby we hypothesize that the differential effects with respect to gender additionally vary with individual characteristics.
To empirically test the above hypotheses, we analyze rich data from an online dating platform by applying flexible causal machine learning methods.
Setup and data
We collaborated with a German online dating platform operator. The operator provided us both with information on the functionality as well as with data from the online dating platform.
Online dating
The online dating platform allows a user to virtually meet and communicate with other users via a web-based user interface, i.e. a website. The user has to pay a monthly fixed subscription fee to register and use the service. The registration at the platform is subdivided into three major sections. First, the user is requested to provide socio-demographic information (e.g., sex, age, education, and income). Second, the user is requested to specify search criteria for potential partners (e.g., sex, age, education, and income). Third, the user is requested to answer a personality test that relates to the user’s lifestyle, personality, attitudes and views (79 categories in total). Moreover, the user articulates the language preferences and may include one or more photos on the personal profile page. However, these photos remain fully blurred until the user decides to release the photo for the potential partner.Footnote 1 Most importantly, with specific regard to the intended analysis, a user articulates her/his sports frequencies, i.e. how often she/he actively practices sport. A detailed description of the survey questions and the corresponding variables, together with some descriptive statistics, is provided in Supplementary Material 3.
Following the registration at the online dating platform, the user defines a query, indicating the preferred sex, age, and geographic location to explore potential partners, which returns a shortlist of such potential partners. The shortlist includes the potential partner’s username, age, a blurred version of the photo, and a matching score, which is computed by the online dating platform operator to support users in finding a potentially fitting partner.Footnote 2 The user can investigate the potential partner in detail by browsing the potential partner’s profile page, which displays a blurred version of the photo as well as information on the previously described survey. The user can then choose from multiple possible actions, of which a private text message is the most relevant one for the intended analysis. Further possible actions involve a ‘Smile’ icon, or a ‘Smile Back’ icon (if initially received a ‘Smile’ icon) to a potential partner. Additionally, a user may leave a ‘Like’ or a text note on a potential partner’s profile page. Moreover, the user can initiate a friendship with a potential partner by initiating a profile release or accepting an initial profile release by a potential partner. Furthermore, a user may request an ‘Applet’ (game with questions) to a potential partner, which works out similarities/differences between the user and the potential partner. Finally, a user may prevent unwanted users from contacting in any form.
In general, the here considered platform provides professional online dating services and is aimed at users who are in search of a serious relationship. This is reflected also in the demographics of the registered users. As such, based on the descriptive statistics of our sample, a typical user is approximately 40 years old, has an income level between 35,000 and 50,000 Euro, and has a high education level. The gender distribution is approximately balanced.
Data
The data consists of two samples. First, the user sample, contains personal information about the registered users on the platform. Second, the interaction sample, contains information about the users’ interactions on the platform.
The user sample includes 18,036 newly registered users who joined the platform between January 1, 2016 and April 30, 2016. For each registered user, we observe the full information filled in upon registration, which comprises 664 variables in total. For our intended analysis concerning the sports activity, we exclude the users with daily sports frequency, as these comprise only around 3% of all users, which would prevent a meaningful statistical analysis for this group. Furthermore, we restrict ourselves to the sample of users, whose residency is located in Germany, as only for these users we observe full location information, including the ZIP codes. This restriction affects only about 2% of the observations as the platform provider operates in the German market. Lastly, we exclude users with incomplete information (around 1% of the sample) and those with implausible and inconsistent values (<1% of the sample). This leaves us with an available sample consisting of 16,864 users for our analysis. A descriptive summary of selected variables for the user sample is presented in Supplementary Material 1.
The interaction sample includes 1,415,645 user actions among the population of newly registered users over the same time period. For each action, we observe the IDs of both users involved in the action, as well as the precise time stamp and the type of action. Each interaction between users must begin with a visit action (invisible to a user), upon which further types of actions are possible, such as a message, like, or smile (visible to a user). We refer to the user who initiates an interaction as a sender of an action, and the user who gets involved in an interaction as a recipient of an action. For the purposes of our analysis, we filter the interactions such that we consider only one-way interactions initiated by a visit action, with either no further action at all or immediately followed by any visible action from the sender, without considering any visible recipient’s response to the initial action from the sender. Thus, we select only unique interactions in the sense that the sender was visibly or invisibly active, while the recipient stayed visibly passive. Thereby, we restrict the interactions between the users until the point of a possible reciprocal interaction taking place. This selection of the sample will be later important for the validity of our identification strategy (see the section “Identification strategy” for details). This leaves us with a sample consisting of 178,372 valid unique interactions for our analysis.
To construct our final estimation sample, we merge the interaction sample with the user sample. As a result, each observation in our estimation sample represents a valid interaction between two users and consists of sender and recipient user IDs together with the sender’s actions from the interaction sample, and both the sender’s as well as recipient’s characteristics obtained from the user sample. Furthermore, as the data contains only heterosexual users based on a binary measure for gender, i.e. we never observe a sender and recipient of the same sex in our sample, we split the sample based on gender for a clearer interpretation of the results. Hence, we refer to the sample with only female recipients as the female sample (108,456 observations), as here the females are in the role of an approached user upon receiving a visit action, and possibly further actions, by a male sender of an action. Analogously, we refer to the sample with only male recipients as the male sample (69,916 observations), as in this case, the males are in the role of an approached user upon receiving a visit action, and possibly further actions, by a female sender of an action. The descriptive statistics of selected variables for the two samples are listed in Supplementary Material 1.
Sports activity of users
We leverage the rich information regarding the sports activities on the user profile. In particular, each profile includes a detailed statement of the user’s sports frequency. This information stems from the initial questionnaire filled out by the user upon registration. First, the user is asked about the sports types done actively, namely: ‘What sports do you do actively?’, with multiple options (mutually inclusive) such as basketball, fitness, hiking, soccer, tennis, etc., or specifying the option ’none’. Second, only if the user has not specified the option ‘none’, a further question regarding the particular sports frequency is asked: ‘How often do you practice sport?’. The possible values (mutually exclusive) include the following answers: ’every day’, ‘several times a week’, ‘several times a month’, or ’less common’. Thus, we not only observe the user’s binary indication of practicing sport or not, i.e. the extensive margin, but also the particular sports frequency, i.e. the intensive margin. Accordingly, we define the sports activity measure to be multi-valued with sports frequencies of weekly, monthly, rarely, and never.Footnote 3
Table 1 shows the descriptive statistics for the sports frequency shares in the user sample for males and females, respectively as well as the corresponding shares from the German socio-economic panel (SOEP; Goebel et al. 2019; Schupp, 2009; Wagner et al. 2008) for a comparison with a representative population sample.Footnote 4 First, we see that the sports frequency has a very similar distribution among males and females. Second, we observe that the shares of the sport frequencies are, in general, unevenly distributed with around half of the users practicing the sport on a weekly and almost a third of the users on a monthly basis, while the rest of the users are split between doing sport rarely or never. Additionally, we also observe that the subjective sports frequency of the users from the online dating platform is, in general, much higher than the one of the representative individuals from Germany.Footnote 5.
Finally, given our definition, the impact of sports activity can be illustrated as follows. The user, here the sender, visits the profile of another user, here the recipient, and gets exposed to information revealed on the profile. Among other indicators, the sender observes the recipient’s indication of the sports frequency, i.e. the variable of interest. Based on the available information, the sender then decides to perform or not to perform a further action.
The interaction between users
In our analysis, we restrict ourselves to one-way user interactions. These interactions are always initiated by a visit from the sender, which is invisible to the recipient. The visit is then immediately followed by either a visible action from the sender or possibly no further action at all. However, in both cases, a visible reply of the recipient to this initial action by the sender is not permitted. In that sense, we retain only one-way interactions such that the sender is visibly or invisibly active while the recipient stays visibly passive. Hence, we do not allow for any visible reciprocal interaction between the sender and the recipient.
For instance, a sender’s visit followed by a sender’s message is a valid interaction. Also, two successive sender visits followed by a message is a valid interaction. A single sender’s visit is a valid interaction, too. Further notice that a sender’s visit followed by a recipient’s visit and afterward a sender’s message is a valid interaction as well, as the sender has not seen the recipient’s visit. However, a sender’s visit and sender’s like followed by a recipient’s visit and like back inducing a sender’s message is not a valid interaction anymore as the sender’s message has already been provoked by the recipient. Hence, we always restrict the interactions until the point a possible reciprocal interaction taking place.
As such, we are interested in the one-way actions of a sender upon visiting a recipient’s profile on the website. Even though there are multiple actions a sender can initiate, we focus explicitly on the action of sending a text message. First, a text message is the most evident action of showing a serious interest, as in order to compose a text message, the sender has to exhibit a substantial effort, in comparison to other available options, such as simply leaving a smile or like. Second, unlike the other generic options, by sending a text message, the sender directly approaches the recipient in an individualized manner. Third, an outcome measure of sending a text message has been previously used in the online dating literature under the assumption that users send a message if and only if the potential utility of the match exceeds some minimum threshold value (Bruch et al. 2016; Hitsch et al. 2010a). Hence, we define our action of interest as a binary measure of sending (1) or not sending (0) a text message upon a profile visit. Given the binary scale, the natural interpretation of contact chances in terms of message probabilities arises. The descriptive evidence in Fig. 1 unveils that women have unconditionally a higher message probability than men do, which is in line with previous evidence from online dating data (Bruch et al. 2016).
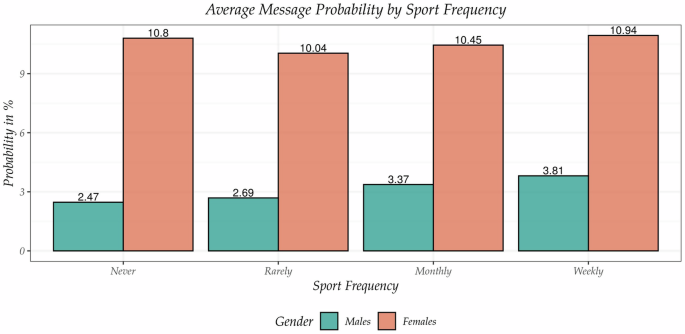
Unconditional probabilities in %.
Information about users
We have access to complete information filled in by the user upon registration. Thus, we effectively observe the very same information that a real user observes upon a profile visit of a potential partner. First, we observe the user’s demographic information such as gender, age, height, etc., the socio-demographic information such as education and income level, type of occupation, etc., as well as personal information such as place of residence, smoking habits, or even (self-judged) appearance. Second, we observe the user’s preferences for a potential partner in terms of the search criteria related to the above-mentioned socio-demographic information as well. Third, we furthermore observe the user’s information stemming from the detailed personality test, which reflects on the user’s lifestyle, personality, attitudes, and preferences. This includes extensive information on topics like religion, political views, music, travel preferences, or partner requirements. The aforementioned user information comprises an exhaustive list of 663 variables in total. Given the structure of our data, we consider the user information both for the recipient as well as for the sender, resulting in effectively more than a thousand variables. We additionally generate a variable measuring the distance between the recipient and the sender, based on the available ZIP codes.
We consider all the aforementioned variables as controls in the sense of potential confounders, excluding only endogenous variables. We thus remove variables that could be potentially influenced by the sports frequency such as variables indicating the specific sport type and other sport-related choices.Footnote 6 In total, we dismiss 38 endogenous variables. Lastly, we leave out 2 variables without any variation. As a result, we are left with 1247 covariates in total, reflecting the recipient’s and sender’s characteristics.
Apart from the confounding role, we pre-specify a small subset of variables, consisting of age, income, and education level together with the corresponding distance between the recipient and the sender, for effect heterogeneity analysis. We focus on these heterogeneity variables for two main reasons. First, this socio-demographic information is widely recognized in the literature as being the main determinant of partner choice (Eastwick et al. 2014; Hitsch et al. 2010a) and a driver of differential partner preferences (Abramova et al. 2016; Ong and Wang, 2015). Second, these variables are most visible to the user on the profile summary and thus can potentially impact effect heterogeneity. Additionally, we analyze the heterogeneity also along sports frequency itself.
Empirical approach
Parameters of interest
We rely on the Rubin’s potential outcome framework (Rubin, 1974). We denote the treatment variable of a user i by Di, while Di ∈ {0, 1, 2, 3}, corresponding to sports frequencies of never, rarely, monthly, and weekly, respectively. According to the treatment status, d, we define the potential outcomes for the user i by ({Y}_{i}^{{d}}), with ({Y}_{i}^{d}in {0,1}), corresponding to receiving or not receiving a text message. However, we only observe the potential outcome under the treatment which the user i is associated with (Holland, 1986). Thus, the realized outcome can be defined through the observational rule as follows: ({Y}_{i}=mathop{sum }nolimits_{d = 0}^{3}{mathbb{I}}({D}_{i}=d)cdot {Y}_{i}^{d}), which implies that we observe user i receiving or not receiving the text message only for her/his particular sports frequency. Further, we denote the observed vector of covariates by Xi, which contains the recipient and sender characteristics, together with a subset of pre-specified heterogeneity variables Zi, such that Zi ⊂ Xi.
We are interested in the following causal parameters. First, the average treatment effect (ATE) of treatment Di = m compared to treatment Di = l is defined as
which provides us with an aggregated effect measure. Second, the group average treatment effect (GATE) is characterized as
and measures the dissagregated effects along the heterogeneity variables Zi. Third, the individualized average treatment effect (IATE) is denoted as
and describes the disaggregated effects based on the full set of observed covariates Xi, yielding the user-type specific effects.
Notice, that both the treatment variable, i.e. the sports frequency, as well as the outcome variable, i.e. receiving a text message, is measured on the recipient’s side, and hence, also the above-defined causal effects refer to the recipient.
Identification strategy
Given our observational study design, it is not possible to only compare the unconditional message probabilities for different sports frequencies, as displayed in Fig. 1, to infer the causal effects, since the user decision regarding the sports activity is not random. The level of sports frequency might be influenced by other variables representing socio-demographic information, which might also influence the potential outcome of receiving or not receiving a text message. For example, recipients with a higher level of education might have a higher probability of doing sports on a weekly basis, as well as a higher probability of getting messaged. This phenomenon is known as selection bias (Imbens and Wooldridge, 2009). In order to disentangle the causal effect from the selection effect, we need to eliminate such confounding with a credible identification strategy.
For the identification of the aforementioned parameters of interest in a multiple-treatment case, we rely on a selection-on-observables strategy (Imbens, 2000; Lechner, 2001). Such an identification approach assumes that all confounding variables jointly influencing both the treatment as well as the potential outcomes are observed and, thus, can be conditioned on. Given our rich data on user characteristics and the unique research design, we argue to capture all possible confounding effects for two main reasons. First, for both the recipient and the sender, we observe socio-demographic (e.g., age, education, income) and personal (e.g., family status, smoking habits, place of residence) characteristics, together with the preferences for a potential partner as well as the answers given in a detailed personality test. Thereby we have access to the same personal information as the actual users when browsing the profiles, and as such, we are able to control for confounding effects stemming from the user’s characteristics. Second, given our research design, focusing only on the very first one-way interactions between the recipient and the sender, we effectively eliminate any possible unobserved effects coming from the reciprocal interaction between the users, such as sympathy or other mutual feelings. By doing so, we explicitly focus only on situations in which the recipient’s profile gets visited by a sender, upon which the recipient does receive or does not receive the very first text message from the sender, without any visible encouragement to do so from the recipient her/him-self. In such a situation, the sender decides solely based on the information visible on the recipient’s profile, including the sports frequency, to send or not to send the message. Within our research design, we observe exactly the same information as the actual sender when facing the decision to send the first text message. For this reason, we are also able to control for confounding effects stemming from the user’s interaction.
Taken together, combining the highly-detailed user information, which equals the information directly observable by the actual users, with the unique research design, which eliminates any possible unobservable information, we are confident to capture all confounding effects. In particular, our selection-on-observables strategy relies on the following set of identification assumptions.
First, the so-called conditional independence assumption (CIA) states that the potential outcomes and the treatment are independent once conditioned on the covariates. This hinges on the availability of all covariates that jointly influence the potential outcome and the treatment. As we argue, we observe sufficiently rich information on both the recipient as well as the sender side to ensure the plausibility of the CIA. In addition, our research design eliminates any further influence from a possible reciprocal interaction between the users. Thus, we are confident about the validity of the CIA in this particular case. There are only two potential sources of vulnerability for the CIA in this case. First, it could be caused by the availability of the blurred photo of the user. Even though the photo remains blurred, as we do not allow interactions between the users, which would include the action to release the photo, we cannot rule out that information such as the shape of the face or the hair and skin color could be, nonetheless, to some extent inferred. However, despite the fact that the incomplete information inferred from the blurred photo might possibly affect the outcome, i.e., the message probability of the recipient, we argue that there is no clear channel to also affect the treatment itself, i.e. the recipient’s sports frequency. Thus, it arguably does not qualify as a potential confounder. Nevertheless, limitations in the availability of profile pictures, respectively, opportunities to represent the information in profile pictures, are common in the literature on online dating (Fiore et al. 2008). Second, the potential vulnerability could be caused by the availability of the matching score. However, despite the fact, that we do not observe the score directly, we know that we observe, and indeed condition on, all information which serves for its calculation. Moreover, even though we do not know the exact formula, by using a very flexible estimation approach, we are able to reproduce any arbitrary functional form of the matching score. Nonetheless, if the matching score would consist of the user’s sports frequency, the treatment would be indirectly observed as a part of the shortlist of potential partners even before actually visiting the user profile. However, this would not violate the CIA as such, it could rather potentially reduce the size of our effect estimates. For this reason, we conduct a placebo test to provide evidence that this is indeed not the case. We discuss the placebo test in more detail in the section “Placebo test”.
Second, the common support assumption ensures that for each value in the support of the covariates, there is a possibility to observe all treatments. This means that we find users with the same age, education, income, etc., for all sports frequency levels. Thus, we are able to check the validity of the common support assumption in the data directly but do not find any violations thereof (see Lechner and Strittmatter, 2019, for a discussion of common support issues).
Third, the stable unit treatment value assumption (see, e.g. Rubin, 1991) implies that for each user, we observe only one of the potential outcomes based on the treatment status. It further implies that there is no interference among users, hence ruling out any general equilibrium or spillover effects. This means that the sports frequency of one particular user does not affect the potential message probability of other users. We argue that the SUTVA is plausible in this case, as we analyze only a short time period after the user registration such that general equilibrium or learning effects would not yet emerge.
Fourth, the exogeneity of confounders assumption indicates that the values of the covariates are not influenced by the treatment. In other words, the user characteristics should not be impacted by the sports frequency. For this reason, we discard all potentially endogenous variables such as indicators of particular sports type, sporty clothing style, preferences for sports holidays, or sports club memberships. Therefore, we are confident that the exogeneity assumption holds.
Under the aforementioned assumptions, it can be shown that the above parameters of interest are identified at all levels of aggregation, i.e. not only for the ATE but also for GATEs and IATEs. For technical details, see Lechner and Mareckova (2022).
Estimation method
We take advantage of causal machine learning (Athey, 2018; Athey and Imbens, 2019) to estimate the causal effects without imposing functional form assumptions on the large conditioning set and to investigate potential effect heterogeneity. We rely on the developments of Causal Trees (Athey and Imbens, 2016) and Causal Forests (Wager and Athey, 2018), which inherit the flexibility of Regression Trees (Breiman et al. 1984) and Random Forests (Breiman, 2001), while being adapted towards causal inference and systematic heterogeneity analysis. Lechner and Mareckova (2022) extend the Causal Forest for the multiple treatment case and additionally improve the splitting rule. The resulting Modified Causal Forest furthermore allows for estimation as well as inference for the parameters of interest at all aggregation levels in one estimation step. Since our application involves multiple treatments with potential confounding, while analyzing various heterogeneity levels of the causal effects, we opt for the latter approach.
We rely on estimating an ‘honest’ forest, which has been shown to lower the bias of the causal effect estimates and to enable valid statistical inference (Lechner and Mareckova, 2022; Wager and Athey, 2018). We thus randomly split the sample into two equally sized parts and used one part, i.e. the training sample, to build the Modified Causal Forest and the other part, i.e., the honest sample, to estimate the causal effects. The estimator draws a random subsample s of the training sample and estimates a single Causal Tree. Herein, the subsample gets recursively partitioned into smaller subsets, i.e. the ‘leaves’ of the tree L(x). The partitioning follows a splitting rule which removes selection bias and reveals effect heterogeneity. As a result, the observations are homogeneous with regard to the covariate values within the leaf, while being heterogeneous across the leaves. The causal effect is estimated within each terminal leaf by subtracting the mean outcomes of the respective treatment levels Di = m and Di = l from the honest sample as
To stabilize the path-dependent tree, the forest estimates many such trees by drawing S random subsamples in total. The Causal Forest estimate of the IATE is given by the ensemble of Causal Trees as
The Modified Causal Forest estimates the GATEs by averaging the IATEs in the corresponding subsets defined by the heterogeneity variables Zi and the ATE by averaging the IATEs in the whole sample as follows:
and
As such, the forest explicitly takes the confounders into account in the effect estimation at all aggregation levels. Furthermore, as the forest can be described as an adaptive local weighting estimator (Athey et al. 2019), the Modified Causal Forest explicitly uses the weighted representation of the estimated effects for inference. Such weight-based inference can be applied to all aggregation levels to estimate sampling uncertainty (Lechner and Mareckova, 2022).
Results
Average effects
The results for the average effects of the sports activity on the contact chances are summarized in Table 2. In the case of the male sample, for increasing sports frequency, the results show a clear and increasing pattern of the potential outcomes, i.e. of the potential message probability. While it is on average only 2.50% for users who never practice sport, the chances to get messaged increase by more than 50% and amount to 3.82% for users doing sport on a weekly basis. Accordingly, all effects for all sports frequency comparisons are positive, providing support for our main hypothesis. The most sizeable and the most precise effects are estimated for the most distinct sports frequencies, as one would intuitively expect. Thus, the average effect of a weekly sports activity versus no sports activity at all is equal to a 1.32 percentage points increase. Similarly, the average effect of a weekly in comparison to only rare sports activity amounts to a 1.20 percentage points increase. Moreover, these effects are both substantively as well as statistically relevant. As such, a male user increasing his sports activity from no sport or only rare sports activity to doing sport on a weekly basis significantly increases the probability of getting messaged by 52.80% and 45.80%, respectively. In practice, this implies receiving 13, respectively, 12 extra messages out of 1000 profile visits. Hence, the contact chances of a male user can be substantially increased solely by becoming more sporty.
Regarding the female sample, the results do not suggest increasing contact chances with increasing frequency of sports activity, as the potential outcomes do not indicate any clear pattern. Accordingly, the effects do not show any explicit structure and lack statistical relevance, providing support for our sub-hypothesis 1. The only exception is the precise estimate of the effect of the weekly vs. rare sports activity, with a sizeable increase of a 1.61 percentage points, yet this represents only a minor relative increase of 17.18%, in comparison to the effects seen in the male sample. Taken together, based on the overall results, no substantial conclusions can be drawn.
Heterogeneous effects
While the average effects provide a general measure for the causal effects of sports activity, a more detailed description of the effect heterogeneity beyond gender, remains unknown. Therefore, we study the heterogeneous effects of sports activity on the contact chances among specific groups of users. For the sake of clarity, we focus on the effects comparing the most distinct cases, namely the weekly sports frequency with no sports activity.
To test for the presence of heterogeneity, we conduct the Wald test of equality of the estimated GATEs. Additionally, we conduct t-tests for differences in the estimated GATEs from the average effect. Rejection of both tests thus gives support for the existence of heterogeneity with respect to the particular variable.Footnote 7 The results of the Wald test suggest heterogeneous effects with regard to the income level for males, both for the recipient as well as the corresponding sender, however, there is no evidence of heterogeneity in the case of females. Furthermore, the heterogeneous effects for men are statistically different from the average effect as well, indicating an explicit pattern, while none of this is the case for women. The respective income level GATE estimates are depicted in Fig. 2 for the recipient and the sender in the male sample. The corresponding results for the female sample are presented in Fig. 1 in Supplementary Material 2.1.
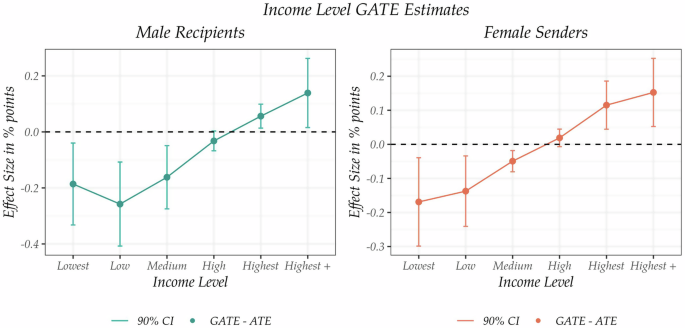
Effects in percentage points as GATE deviations from the ATE (zero dotted line) with 90% confidence intervals.
Concerning the male sample, we observe a clear increasing trend of the GATEs for increasing levels of income, providing support for our sub-hypothesis 2. As such, for a male recipient, the effect of weekly sports activity in contrast to no sport is greater, the higher the income level of the male recipient himself, and the higher the income level of the female sender, too. This relationship shows that male users with a higher income level benefit from regular sports activity on a weekly basis in comparison to no sport more than male users with a lower income level. As such, particularly wealthy men, who earn more than 100,000 EUR in a year are associated with the largest increase in their contact chances when practicing sport on a weekly basis. In a similar vein, male users having a potential female partner with a high income level are associated with larger benefits from the higher sports frequency than the male users, who have a potential female partner with a low income. This pattern suggests also that more wealthy female users seem to value the regular sports activity of male users more. In addition, not only are these heterogeneous effects statistically relevant, but the substantive relevance is documented, too, as the effect sizes are relatively large. As such, the magnitudes of the income level GATEs range from 1.06 percentage points to 1.46 percentage points with respect to the income level of a male recipient, and, similarly, from 1.15 percentage points to 1.47 percentage points with respect to the income level of a female sender, in reference to the average effect of 1.32 percentage points. This implies an increase in the message probability of at least 42.40% for the low-income users, up to an increase of 58.80% for the high-income users, respectively. This results in a 16.40% difference in message probability solely due to the user’s income. A simple back-of-the-envelope calculation reveals this difference in income levels to amount to 4 extra messages out of 1000 profile visits.
As opposed to the male sample, we do not find such evidence of heterogeneity, if we switch the roles of the recipient and the sender. As such, even though we observe a similar increasing pattern for female recipients associated with male senders, the estimated effects lack statistical precision. We find supportive evidence for heterogeneity for females only in terms of the sports activity of the male sender, with a clear increasing pattern. Nevertheless, despite the clear statistical pattern of the heterogeneity itself, in this case, the overall substantive implications remain rather limited as the effect sizes are only moderate, ranging from 0.08 percentage points to 0.41 percentage points, given the average effect of 0.31 percentage points. Additionally, neither for the average effect nor for the respective group effects the presence of an actual null effect can be ruled out.Footnote 8 Further results of the tests regarding the remaining heterogeneity variables do not support the evidence for heterogeneous effects for the female sample.Footnote 9
To gain more insight into the effect heterogeneity, we analyze the effects on the finest level possible and study the underlying individualized average treatment effects. Figure 3 provides the distribution of the IATEs for the weekly vs. never comparison for both men as well as women, respectively. In both cases, we observe that there is indeed substantial heterogeneity in the effects as the effect distributions are noticeably spread out around the mean, i.e. the realized ATE.Footnote 10 Additionally, we see that for men, virtually all effects are positive, while for women, about half of the effects are positive and half are negative. This further substantiates the findings on the aggregated levels in terms of the GATEs and the ATE. An additional descriptive analysis of the IATEs based on k-means++ clustering (Arthur and Vassilvitskii, 2006), supporting the evidence from the GATEs analysis, is provided in Supplementary Material 2.2.
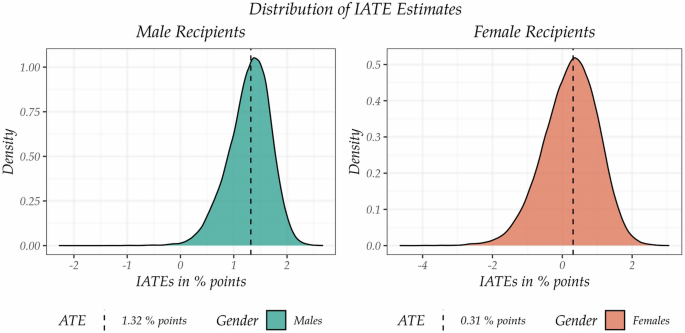
Distribution of IATEs smoothed with the Epanechnikov kernel using the Silverman’s bandwidth.
Placebo test
To assess the validity of the CIA, due to the potential vulnerability given the availability of the blurred photo of the user, we conduct a placebo test inspired by Imbens and Wooldridge (2009) by testing for a zero effect on an outcome assumed to be unaffected by the treatment, i.e. the decision to visit the user profile. Accordingly, we redo our main analysis, while swapping the message outcome for a visit outcome. Thus, we estimate the average treatment effects of sports frequency on the visit probability, given the same conditioning set of potential confounders.
In our analysis, we also assume that the sports frequency is observed once a profile of a recipient has been visited by a sender. However, the sports frequency might potentially be entailed in the matching score, which is observable already before the actual profile visit as part of the shortlist of potential partners suggested by the online dating platform. If that were the case, the sports frequency could potentially indirectly influence already the decision to visit the profile, and not only the decision to send a text message after a profile visit. However, even under such circumstances, this would not violate the CIA per se but rather reduce the size of the estimated effect, which could be then interpreted as a lower bound of the true underlying effect. The particular design of the placebo test allows us to examine if such a mechanism takes place in our setting. As such, if the sports frequency is, as assumed, not part of the matching score, its effect on the probability of visiting a user profile should be equal to zero.
To implement such a placebo test, we first need to impute the ‘potential’ visits, as by construction, we only observe the realized visits. For a given user, we consider all registered user profiles with the opposite sex and within a specified distance radius as potential visits.Footnote 11 We end up with a sample consisting of 38,552,821 observations, out of which 178,372 represent the actual realized and the rest the imputed potential visits. Analogously as in the main analysis, we split the sample into a male and a female sample. Furthermore, due to the computational feasibility and general consistency of the analysis, we randomly draw an identically sized male and female sample as in the main estimation, such that we replicate the corresponding sports frequency shares, too. A similar approach to impute the potential visits has also been used in previous studies focusing on online dating platforms (see e.g. Bruch et al. 2016).
In Table 3, we observe that the potential outcomes for both males and females do not exhibit any particular upward or downward trend, which is in contrast to the main analysis. Furthermore, for neither the male nor the female sample, we find evidence for statistically relevant effects. Moreover, the effect sizes and the levels of potential outcomes are an order of magnitude lower than our main results, being effectively zero in terms of substantive relevance. Even though the results of such placebo tests do not completely rule out the possibility of the presence of an effect on the visit probability, they provide supportive evidence that this is, indeed, not the case. Hence, we conclude that our main analysis estimates the full causal effects of sports activity on contact chances, rather than only lower bounds thereof.
Limitations
The analyses presented in this study are constrained by three core limitations. Firstly, the limitations pertain to the data used. The unique dataset from the online dating platform dates back to 2016, which may not fully represent the current trends and behaviors in online dating. Furthermore, the analysis does not account for the blurred version of profile pictures. However, limitations regarding the availability and quality of profile pictures are common in online dating literature (Fiore et al. 2008). Secondly, restricting user interactions only to the very first one-way action of sending a private text message prevents further analysis of consequent outcomes. Nevertheless, such restriction is needed in order to eliminate any possible unobserved effects coming from the reciprocal interaction between the users to establish a credible identification strategy. Thirdly, as our sample is specific to a population of online users, the external validity of our results is likewise limited to such a population.
Discussion
We study the effect of sports activity on contact chances based on a unique dataset from an online dating platform by applying the Modified Causal Forest estimator (Lechner and Mareckova, 2022). We find that for male users, doing sport on a weekly basis increases the probability of receiving the first message by more than 50% relative to not doing sport at all, while for female users, we do not find evidence for such an effect.
In addition, we uncover important effect heterogeneity. In particular, the effect of sports frequency on message probability increases with higher income for male, but not for female users. This aligns with evolutionary perspectives on human mating, where resource availability often enhances male attractiveness and mating success. This effect suggests that sports activity, coupled with higher income, signals better resource acquisition capabilities and health, making these individuals more appealing as potential mates. Discussing this within the framework of sexual selection theories could provide deeper insights into how socio-economic factors interplay with behavioral traits in human mating dynamics (Buss, 1989; Trivers, 2017).
This paper offers notable implications for research and practice. First, this study contributes to the literature on human mating. In particular, we demonstrate that sports activity, as an essential behavioral trait and pivotal information on online dating platforms, enfolds a causal effect on contact chances. In turn, this paper expands previous work by demonstrating that sports activity does not only affect physical/mental health (Strong et al. 2005) and social/economic conditions (Lechner, 2009), but also one of the most decisive spheres of human existence, that is human mating. Acknowledging the relevance of different types of online dating platforms, future research could further analyze the effects of websites versus apps to understand how these mediums influence user behavior and contact chances using different mediums. Second, this paper advances empirical approaches for assessing causal effects in large-dimensional data environments. It applies a very flexible estimation procedure from causal machine learning, which enables a systematic analysis of the underlying effect heterogeneity on different levels of aggregation (Lechner and Mareckova, 2022). Future research might also investigate sports activity in conjunction with the profile pictures of the users to uncover further effect heterogeneities. Third, this study may support users to increase their chances of finding a mate on online dating platforms by demonstrating if and to what extent sports activity contributes to the likelihood of being recognized. Thus, it may incentivize individuals to increase the level of sports activity, not only because of the positive effects on, for example, health (Penedo and Dahn, 2005) but also due to higher chances of finding a mate. From a public health perspective, this paper provides additional empirical evidence for justifying public health promotion of sports due to the positive impact of sports activities on human mating.
Finally, this paper may serve practitioners, namely product developers and software engineers, as a foundation to improve the architecture of online dating platforms by explicitly recognizing the relevance of sports activity for mate evaluation and selection patterns. In turn, this research may help to customize the weighting of sports activity in matching algorithms or specific placement of information on sports activity on individual profile pages. In a similar vein, the insights of this research are applicable to engineer architectures of other platforms with a likewise high degree of interpersonal computer-mediated interaction, for example, social networks.

Responses