Upper bounds on overshoot in SIR models with nonlinear incidence

Introduction
Compartmental models have been an invaluable tool for analyzing the dynamics of epidemics for the last century. In particular, the susceptible-infected-recovered (SIR) model has long been a workhorse compartmental model for describing transient epidemics due to its relative simplicity and has received a lot of attention in both the academic literature and the public-health arena1,2. The mechanism of transmission of a communicable disease underlying this model and a variety of other contagion models is contact between healthy and infectious individuals, which results in conversion of the healthy individuals into an infected state. Choosing how to precisely define the transmission interaction between healthy and infectious individuals leads to a variety of models depending on the assumptions made. For instance, in a spatially explicit model, one might represent the contact between individual members of the population as a network. Alternatively, if one is willing to assume all individuals within a compartment are identical, one can formulate a model using ordinary differential equations (ODEs) by assuming an incidence term for how the susceptible and infected compartments mix and generate newly infected individuals.
The quintessential SIR ODE model, known as the Kermack–McKendrick model, is shown in Eq. (1–3). The model assumes a bilinear incidence rate βSI for the growth term of the infected compartment, with transmissibility parameter β and first-order (i.e. linear) with respect to the fraction of the population that is susceptible (S) and infected (I).
While a bilinear incidence rate between healthy and infected individuals can be a reasonable first assumption, depending on the real-world situation being modeled and the level of precision required, the assumption can be insufficient or inaccurate. A significant body of work in the literature has been done to generalize this incidence term into more detailed forms3,4,5,6,7,8. Moving beyond bilinear forms towards nonlinear incidence allows for the consideration of models with more biological complexity and realism. Factors such as network effects, seasonality, and non-pharmaceutical interventions are known to give rise to more complex dynamics9,10,11,12. The studying of nonlinear transmission in the context of epidemiology here is a specific case of a larger growing interest across a range of fields in studying the effects of transmission dynamics in complex systems. The exploration of interactions beyond the bilinear form has taken place in contexts ranging from social dynamics13,14,15,16,17, ecology18,19,20,21, economics22,23, to molecular biology24. Significant effort has also been expended on synthesizing these ideas into a more general model of contagion that can be used in different domains25,26,27.
As the representation of transmission is arguably the most important aspect in setting up a model of communicable disease, the choice for the incidence rate has downstream consequences on many epidemiological quantities of interest. These include but are not limited to, the epidemic size, the herd immunity threshold, epidemic duration, and the epidemic overshoot. While features such as the epidemic size and the herd immunity threshold have been studied rather extensively in the literature, the behavior of overshoot remains relatively under explored, in particular for more general incidence rates.
Overshoot is a concept from mathematics and control theory that quantifies the amount of excess from when a function exceeds its target value28,29. This concept has been applied to a variety of contexts ranging from ecological and environmental problems that pertain to overconsumption and sustainability30,31,32,33 to biotechnology that controls blood flow34. In the epidemiological context, the overshoot quantifies the number of individuals that become infected after the prevalence peak of infections occurs (Fig. 1a). In simple epidemics, the peak of the epidemic coincides with the threshold at which transmission is sufficiently reduced so that the epidemic is no longer growing, the overshoot reflects the excess in cases beyond this minimal threshold of protection.

a In the context of an epidemic outbreak, the overshoot is given by the depletion of susceptibles from the peak of the infections until the end of the outbreak. b Nonlinear incidence can manifest in the form of a spatial proximity network.
While the terminology excess may give the connotation of a relatively small effect, in the the Kermack–McKendrick SIR model it can be shown that up to nearly 30% of the population can become infected in the overshoot phase of the epidemic35. This is also not a rare case, as large values of overshoot occur at rather common values for the basic reproduction (R0) of 1.5−4, which includes communicable diseases such as COVID-1936,37,38, HIV39, and influenza40. An analysis of data from the first wave of the COVID-19 pandemic in the urban city of Manaus, Brazil35,41, where disease spread went largely unmitigated, suggested that the dynamics could be reasonably approximated by the Kermack–McKendrick SIR model and that nearly 30% of the population became infected in the overshoot phase.
The overshoot highlights the potentially large public health risk that can be posed by allowing for unmitigated spread or reducing intervention measures prematurely. However, the transmission rates at which the overshoot poses the greatest risk depends on the form of the incidence rate, which drives the need to understand the behavior for incidence beyond the simple bilinear case. As the overshoot quantifies the excess number of cases that occur after the herd immunity threshold has been reached, it is also intimately connected with any potential interventions or mitigation strategies. A question of great concern to epidemiologists and public health officials is figuring out the optimal control strategies for reducing excess cases and mortality42,43,44,45. Any optimal strategy by design generally seeks to eliminate the overshoot. Thus, a better understanding of the behavior of overshoot under different model assumptions might allow for better control measures to be designed and developed.
While the overshoot within the SIR model has received some attention42,46,47,48, a detailed understanding of its full mathematical behavior within compartmental models remains incomplete. An observation that the overshoot is largest for intermediate basic reproduction numbers was first numerically observed by Zarnitsyna et al.49. An explanation for that phenomenon in the context of the Kermack–McKendrick model was recently discovered, showing that the overshoot is derived from a trade-off from the basic reproduction number in driving both the final epidemic size and how quickly the disease burns through the population35. Here we lay the foundation to calculate the upper bound for overshoot when considering incidence terms beyond the simple bilinear case. We will first derive the behavior of the overshoot for more general incidence rates within the context of ODE models, where the results and understanding can be analytical and precise. As nonlinear incidence can also arise through the connectivity structure of networks (Fig. 1b), we will then numerically explore the effect of network structure and changing network topologies on overshoot.
Results
Effect of nonlinear incidence on overshoot in SIR ODE models
We first examine the effect of nonlinear incidence on overshoot for ODE models, where the computations can be made analytical. Consider the following SIR ODE model as follows with generic incidence term βf(S)g(I), where f(S) and g(I) are functions of S and I respectively to be specified.
where S, I, R ∈ [0, 1] are the fractions of the population that are susceptible, infected, and recovered, respectively, (beta ,gamma in {{mathbb{R}}}_{ > 0}) are positive-definite parameters for transmission and recovery rate respectively.
For the SIR model, the overshoot is given by the following equation:
where ({S}_{{t}^{* }}) is the fraction of susceptibles at the time of the prevalence peak (i.e., when I is maximal in value), t*, and S∞ is the fraction of susceptibles at the end of the epidemic. To solve this equation, the easiest approach is to derive an equation for ({S}_{{t}^{* }}) in terms of only S∞ and parameters. We do this by first setting (5) equal to 0 and solving for the critical susceptible fraction ({S}_{{t}^{* }}).
By using the usual definition for the basic reproduction number, ({R}_{0}equiv frac{beta }{gamma }), we obtain the following equation for ({S}_{{t}^{* }}).
We can see from this equation that ({S}_{{t}^{* }}) will have I dependence unless (g({I}_{{t}^{* }})={I}_{{t}^{* }}). Thus to make what follows analytically tractable, let us assume (g({I}_{{t}^{* }})={I}_{{t}^{* }}). We will provide even stronger justification why g(I) must take this form later in the results. This assumption of (g({I}_{{t}^{* }})={I}_{{t}^{* }}) reduces the above equation to the following.
Taking this equation for ({S}_{{t}^{* }})(9) and the overshoot formula (7), we obtain:
Thus the main challenge now becomes a problem of finding an equation for R0 and the inverse function f−1. Building on previous results35, the following outlines the general steps for calculating the maximal overshoot for a SIR model:
-
A.
Take the ratio of (frac{dI}{dt}) and (frac{dS}{dt}). Integrate the resulting ratio. The indefinite integral requires a constant of integration, which is a conserved quantity that applies at every time point along the system’s trajectory in time.
-
B.
Evaluate the equation for the conserved quantity at the beginning of the epidemic (t = 0) and the end of the epidemic (t = ∞) using initial conditions and asymptotic values. Then, rearrange the resulting equation for (frac{1}{{R}_{0}}).
-
C.
Find the form for the inverse function, f−1.
-
D.
Combine the equations for (frac{1}{{R}_{0}}) and f−1 with the overshoot equation.
-
E.
Maximize the resulting overshoot equation by taking the derivative of the equation with respect to S∞ and setting the equation to 0 to find the extremal point ({S}_{infty }^{* }). This step usually leads to a transcendental equation for ({S}_{infty }^{* }), which can then be solved numerically.
-
F.
Use the maximizing ({S}_{infty }^{* }) value in the overshoot equation to calculate the corresponding maximal overshoot.
-
G.
Calculate the corresponding ({R}_{0}^{* }) using ({S}_{infty }^{* }) and the (frac{1}{{R}_{0}}) equation.
Thus, the analytical exploration of nonlinear incidence terms of the type βf(S)g(I) is reduced to exploring different forms of f(S).
Restrictions on g(I)
The first step is to rule out what forms for the incidence term will not work with the procedure outlined above.
We now show the principle reason why we require g(I) = I. We can see from calculating Step A in (11) that any incidence term that does not take the form (g(I)=aI,ain {mathbb{R}}), where a is a real scalar, retains I dependence upon simplification.
Any deviation from the form g(I) = aI results in I in the numerator and the denominator not completely canceling out, which will result in having to integrate I with respect to S, which we will not be able to do analytically. Therefore, I must enter linearly into the incidence term. Since a can be absorbed into the β parameter, all possible incidence terms for the purpose of calculating overshoot analytically will take the form β ⋅ f(S) ⋅ I.
Restrictions on f(S)
We now turn to what restrictions there are in the form of f(S). We start first with two conditions. First, we must enforce that when there are no susceptibles (S = 0), then the incidence rate must go to zero (βf(S)I = 0). Otherwise, since I do not have such a restriction, violating this condition would leave open the unrealistic possibility that the model can generate infected people when there are no susceptibles available. To ensure this condition is met, we need the function on S to output zero if the input is zero.
For the second condition, for an outbreak to occur in a SIR model, we must have a minimum value for the basic reproduction number, R0. Another way to view this condition is by inspecting (2) and recognizing that the incidence term (βf(S)I) needs to be greater than the recovery term (γI). Otherwise, the epidemic cannot grow in size. Comparing the two terms leaves an inequality (βf(S)I > γI) which can be rewritten as:
Beyond these conditions, an obvious requirement is that f(S) should be a continuous function. In order to be able to calculate the maximal overshoot analytically, the function should be integratable with respect to S and should also have a closed-form inverse f−1. As we will demonstrate, non-monotonic functions for f(S) are possible.
For f(S), the following examples are constructed using basic functions that satisfy the above criteria:
-
1.
(exp (S)-1)
-
2.
Invertible polynomials of S
-
3.
(sin (aS))
Conversely, there are many examples of functions that would not work. An example that satisfies the conditions above but that does not have a closed-form inverse is (f(S)=log (S+1)). While similar to examples listed that work, the following violate one of the conditions: (exp (S),log (S),cos (S)). Examples that violate conditions of continuity include step functions of S or f(S) with cusps.
Deriving maximal overshoot for various f(S)
As an example, we will now look at a model with nonlinear incidence and apply the whole procedure previously outlined for finding the maximal overshoot.
Example: (f(S)=exp (S)-1)
Let us consider an incidence rate that takes on an exponential form. This produces an incidence term that grows slightly faster than the original bilinear incidence term, and so might be relevant in situations where there are network effects. The phenomenon of superspreading occurs when some individuals infect many more people than the typical infected person would50. Superspreading allows for explosive outbreaks that exceed the growth rate of infections allowed by simple bilinear incidence and is enabled by inherent heterogeneity in contacts amongst the population, which makes it natural to occur in situations that are approximated by a network. Different models can be formulated to account for superspreading51,52. Here we have chosen the exponential as a qualitatively simple example that more closely resembles the growth rate on a heterogeneous network than standard bilinear incidence.
We start at Step A by solving for the rate of change of I as a function of S by taking the ratio of (frac{dI}{dt}) and (frac{dS}{dt}).
from which it follows on integration using the substitution u = eS and partial fractions (left(frac{1}{u-1}right)) and (left(frac{1}{u}right)) that (I+S+frac{S-,{{mbox{ln}}},| {e}^{S}-1| }{{R}_{0}}) is constant along all trajectories.
For Step B, consider the conserved quantity at both the beginning (t = 0) and end (t = ∞) of the epidemic.
hence
We use the initial conditions: S0 = 1 − ϵ and I0 = ϵ, where ϵ is the (infinitesimally small) fraction of initially infected individuals. We use the standard asymptotic of the SIR model that there are no infected individuals at the end of a SIR epidemic: I∞ = 0. This yields:
For Step C, we find the inverse of f.
For Step D, we substitute the expression for (frac{1}{{R}_{0}}) (16) and f−1 (17) into the overshoot equation (10).
For Step E, differentiation of both sides with respect to S∞ and setting the equation to zero to solve for the critical ({S}_{infty }^{* }) yields:
Since eS − 1 is positive semi-definite over the unit interval for S, dropping the absolute value symbols and simplifying yields:
which admits both a trivial solution (({S}_{infty }^{* }=1)) and the solution ({S}_{infty }^{* }=0.1663…).
For Step F, using the non-trivial solution ({S}_{infty }^{* }) in the overshoot equation (18) to obtain the value of the maximal overshoot for this model, (Overshoo{t}^{* }{| }_{beta ({e}^{S}-1)I}) yields:
Thus, the maximal overshoot for incidence functions of the form β(eS − 1)I is 0.296. . . .
For Step G, we can calculate the corresponding ({R}_{0}^{* }) using ({S}_{infty }^{* }) and (16).
This result is verified numerically in Fig. 2. Compared to the overshoot in the Kermack–McKendrick model with bilinear incidence35,49, we see that the maximal overshoot is also near 30%. However, we see that overshoot for exponential incidence has a much broader distribution over the domain of R0, suggesting that exponential incidence rates pose a public-health hazard for a greater range of communicable diseases over their bilinear counterparts.
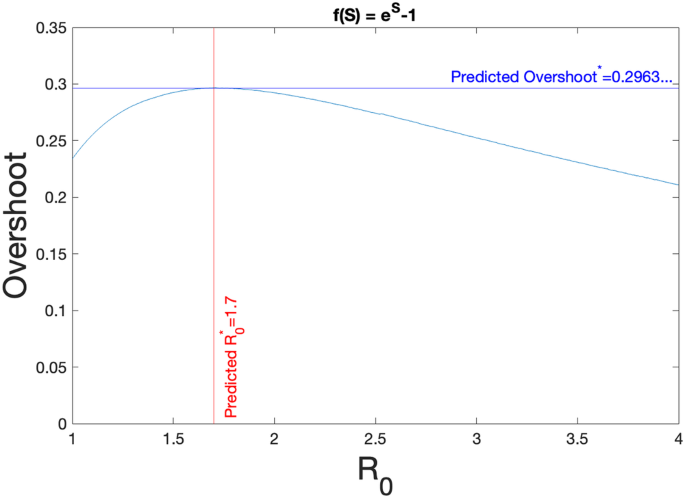
The overshoot as a function of R0 for an SIR model with nonlinear incidence term of β(eS − 1)I. The horizontal line for Overshoot* in dark blue and the vertical line in red given by ({R}_{0}^{* }=1.7) are the theoretical predictions given by the calculations in the text. The curve is obtained from numerical simulations.
Additional examples for incidence rates of a different mathematical form can be found in the Supplemental Information. One example considers when the form of f(S) is given by a polynomial, which can be used to model higher-order effects beyond a simple two-person interaction. Another example considers the consequence of having f(S) that is non-monotonic over the domain of S, which might reflect real scenarios where there are tipping points or seasonality in behavior.
Nonlinear incidence generated from dynamics on networks
In the previous sections, we focused on the nonlinear incidence that was generated from the introduction of nonlinearity in an ODE model. Importantly, this fundamentally assumes homogeneity in the transmission, in that all infected individuals are identical in their ability to spread the disease further. In contrast, network models allow for heterogeneous spreading, which depends on the local connectivity of each infected individual. This provides an entirely different mechanism through which nonlinear incidence can be generated compared to the ODE models. As many real-world complexities and details can be more easily captured and explored in a network model, the consequences of those heterogeneities on the overshoot become more transparent through the targeted and fully fleshed-out explorations that can be done through numerical experimentation in network simulations9,53,54,55,56. However, a trade-off for the increased realism is that it becomes more difficult to perform analytical calculations for a general network model, so here we conduct a numerical exploration of the behavior of the overshoot in network models across a range of network structures.
The space of all possible network configurations is immense, so we must restrict ourselves to analyzing a particular subset of possible networks. Here we explore what happens to the overshoot when the contact structure of the population is given by a network graph that is roughly one giant component. While it is possible to construct pathological graphs that produce very complex dynamics, we consider more classical graphs here. Using a parameterization of heterogeneity (σ) given by Ozbay et al.57 and the configuration model of Newman58 to randomly construct networks (see Methods for details), we simulated epidemics on a spectrum of networks with structures ranging from the homogeneous limit (well-mixed, complete graph) to a heterogeneous limit (heavy-tailed degree distributions). The spectrum of distribution shapes across the space of σ used to generate the degree distributions can be seen in the supplement. As the dynamics of the epidemic on a network are stochastic and occur in discrete time here, they are not parameterized by R0 as in the ODE models. Instead, we use an analogous parameter that we will denote as a basic reproduction number for networks (R0,network) and is defined as follows:
The transmission probability (τ) and recovery probability (ρ) are directly analogous to their counterparts (β and γ, respectively) in R0 in that they correspond to transmission and recovery parameters, albeit for a stochastic model. The inclusion of the mean network degree (〈k〉) as a scalar makes intuitive sense as that represents the average number of potential neighbors an infected node could potentially infect at the beginning of the epidemic, which is analogous to the interpretation of R0 as the number of secondary infections. We observed what happens to the overshoot on these different graphs as we changed R0,network.
On a network model, where contact structure is made explicit, the homogeneous limit is a complete graph, which recapitulates the well-mixed assumption of the Kermack–McKendrick model. It is not surprising then that the overshoot in the homogeneous graphs (σ ≈ 0) peaks also around 0.3 (Fig. 3, purple and blue), which coincides with the analytical upper bound previously found in the ODE Kermack–McKendrick model35. However, while the homogeneous graphs shown here are highly regular (i.e., symmetric in the average number of contacts each node has), the network’s connectivity is not close to complete as the mean degree is significantly less than the network size. Thus, the average overshoot is lower than would be the case for a complete graph.

The overshoot for SIR epidemic simulations on networks with varying levels of heterogeneity (σ) as a function of R0,network. Each color shows simulations for networks of different contact heterogeneity as parameterized by σ. Larger σ corresponds to a graph with greater graph heterogeneity (i.e. increasingly heavy-tailed degree distribution). The solid lines represent the mean value of 100 simulation runs for a given R0,network and σ. The shaded areas indicate the 25th and 75th quartiles for those 100 simulations. The other simulation parameters are number of nodes (N) = 200, 〈k〉 = 7, and recovery probability (ρ) = 0.2.
We also see that increasing contact heterogeneity (i.e., σ→1) qualitatively suppresses the overshoot peak both in terms of the overshoot value and the corresponding R0,network. Furthermore, increased heterogeneity also flattens out the overshoot curve as a function of R0,network. We see that for more heterogeneous graphs, the overshoot is larger at very low R0,network. For some intermediate values of contact heterogeneity (Fig. 3, yellow and orange), the overshoot shows larger overshoot than the homogeneous case for large R0,network. This would suggest a larger public health hazard for a larger range of communicable diseases for networks with structure in this regime. The intuition for the larger overshoot at high R0,network in more heterogeneous networks is that both the peak occurs earlier and that a significant number of cases can occur in the periphery of a network (Supplemental Materials). The probability of being connected to a high-degree node increases as the heterogeneity of the network increases, which drives the peak of infections to occur sooner. In the second phase of the epidemic, as the epidemic expands out to the periphery, the epidemic burns more slowly as individuals in the periphery have fewer neighbors.
However, this trend of an overshoot distribution with a big right tail does not monotonically increase with the contact heterogeneity. We see that at very high amounts of contact heterogeneity, the overall area under this overshoot curve decreases. This can be partially explained by the fact that for very heterogeneous networks, a significant fraction of the population has no neighbors at all. This limits the number of people that can potentially be infected and caps the outbreak size and, subsequently, overshoot size.
Discussion
While the overshoot has received less attention and exploration than its epidemiological counterpart (the herd immunity threshold), the overshoot poses a significant potential public-health hazard for a large range of communicable diseases when there is no mitigation. Generalizing models to include nonlinear incidence terms allows for the consideration of more real-world effects such as higher-order transmission effects and network effects. Thus, to expand the scope of previous work, we have illustrated a general method to analytically find the maximal overshoot for generic nonlinear incidence terms.
Starting with the general incidence term βf(S)g(I), we have deduced what restrictions must be placed on the form of f(S) and g(I) to make an analytical calculation possible. As long as the conditions for a suitable f(S) are satisfied, in principle the maximal overshoot can be derived. However, in the examples shown in both the main text and supplemental information, we have seen that even relatively simple forms for f(S) can quickly lead to complicated integrals and derivatives. For these examples, we have shown the predictions given by the theoretical calculations generally match the empirical results derived from numerical simulation. From a public-health perspective, we find that incidence rates that are steeper over the domain of S, such as the examples with the exponential or polynomial functions, show a smaller maximal overshoot, but importantly, a much broader range of R0’s at which the overshoot remains large. As interventions that seek optimal control try to minimize the overshoot, this highlights the need for even stronger interventions when the interactions and subsequent incidence between individuals are higher than a simple bilinear interaction. The example of (f(S)=sin (aS)) in the supplemental information is interesting because it can be used to probe the restrictions on the shape of f(S). The case demonstrated that f(S) no longer has to be monotonic over the domain of S, allowing for tipping point-like behavior.
Nonlinear incidence introduced through having a network structure showed that having network connectivity that was more heterogeneous resulted in a reduction in the upper bound on overshoot and a reduction of the dependence of overshoot on transmission overall. Numerically, the overshoot for a homogeneously connected network (i.e., a complete graph) well-approximates a Kermack–McKendrick ODE model. The ODE model makes a fundamental assumption of a well-mixed population, and similarly, a network with the highest mixing rate would be a complete graph, which a graph approaches as it becomes more homogeneous and the connectivity increases. Thus, an upper bound on the overshoot of approximately 0.3 in both models35 is perhaps unsurprising. It is interesting to note, though, that due to the stochastic nature of the network simulations, occasionally, an epidemic on a very homogeneous contact network will exceed the analytical bound in the ODE framework (see Fig. 3, the upper quartiles for blue and purple regions exceed 30%). While more heterogeneous networks did not have an overshoot larger than 0.3, the overshoot can be greater at larger R0,network than the homogeneous case. Future studies that incorporate more nuanced aspects of behavior, interventions, and time dynamics in the network model can further elucidate the complexities of epidemics on networks.
It will also be interesting to see if more complicated nonlinear interaction terms than the ones presented here can be derived. In addition, it will also be interesting to see how these nonlinear incidence terms interact when additional complexity is added to the SIR model, such as the addition of vaccinations or multiple subpopulations.
Methods
Generating graphs of differing heterogeneity
In Fig. 3, we presented the results of SIR simulations of epidemics run on graphs of size N = 200, and the mean degree is 7, where the parameter of interest is σ. Each curve represents a different value of the graph heterogeneity. We implemented the following procedure from57 for generating graphs as a function of a continuous parameter (σ):
The following simple procedure generates a graph that has the desired heterogeneity:
-
1.
Choose values of σ (heterogeneity), the mean node degree (which can be set through the relationship (,{{mbox{Mean}}},=lambda Gamma left(1-frac{1}{log (sigma )}right)) via σ and an appropriate scale parameter (λ)), and N (number of nodes).
-
2.
Draw N random samples from the following distribution using σ and λ, rounding these samples to the nearest integer, since the degree of a node can only take on integer values.
$$f(x;lambda ,sigma )=frac{-,{{mbox{ln}}},(sigma )}{lambda }{left(frac{x}{lambda }right)}^{-{{mbox{ln}}}(sigma )-1}{e}^{-{(x/lambda )}^{-{{mbox{ln}}}(sigma )}};xge 0;sigma in (0,1];lambda > {{mathbb{R}}}^{+}$$ -
3.
With the sampled degree distribution from the previous step, now use the configuration model method58 (which samples over the space of all possible graphs corresponding to a particular degree distribution) to generate a corresponding graph.
This yields a valid graph with the desired amount of heterogeneity as specified by σ.
Simulating epidemics on graphs of differing heterogeneity
We implemented the following simulation procedure from57 for implementing a SIR epidemic on a graph:
Given a graph G(σ) of heterogeneity σ, fix a transmission probability τ and recovery probability ρ:
-
1.
At time t0, fix a small fraction f of nodes to be chosen uniformly on the graph and assign them to the Infected state. The remaining (1 − f) fraction of nodes start as Susceptible.
-
2.
For each i ∈ [1, T], for each pair of adjacent S and I nodes, the susceptible node becomes infected with probability τ.
-
3.
For each i ∈ [1, T], each infected node recovers with probability ρ.
-
4.
For each simulation, record the overshoot as the difference between the number of susceptibles at the peak of infection prevalence and the end of the time dynamics.
-
5.
Repeat steps (1–4) n times for each value of τ.
-
6.
Repeat steps (1–5) for each value of σ.



Responses