Video super resolution based on deformable 3D convolutional group fusion

Introduction
Super resolution refers to the restoration of corresponding high-resolution (HR) images from low-resolution (LR) images through software algorithms. The concrete is subdivided into single image super-resolution and video super-resolution (VSR). Along with the continuous renewal of the mobile Internet and communication technology, VSR has a broad application in remote sensing imaging, panoramic video, high-definition television, and other fields1,2,3,4,5,6. The pursuit of higher resolution video has attracted more and more attention.
VSR, to some extent, can be regarded as a single image super-resolution. A video can be divided into multiple frames using the principle of single image super-resolution one-on-one processing to get high resolution video frames. This method cannot utilize inter frame motion information and cannot preserve intra frame temporal correlation, resulting in artifacts and interference in video frames and poor reconstruction results. Therefore, the focus of recent VSR methods based on deep learning is how to explore efficient frame alignment methods by utilizing spatio-temporal information between video frames. Most current VSR methods consist of alignment module, feature extraction and reconstruction module. In the alignment module, the optical flow method7,8 is the most widely used. It found the corresponding relationship between the last frame and the current frame by using the changes of pixels in the time domain in the video sequence and the correlation between adjacent frames, so as to calculate the motion information of objects between adjacent frames. The method based on display motion compensation will cause large distortion and error when dealing with complex motion or occlusion, which will affect the super-resolution performance. The DUF method proposed by Jo et al.9 used a dynamic upsampling filter and utilizes implicit motion compensation to estimate the motion relationship between video frames, thereby reconstructing HR video frames. Although implicit methods improve the accuracy of estimating motion information between video frames, the size of the upsampling filter directly determines the reconstruction performance, so the computational speed is not ideal. To further utilize the spatiotemporal information between adjacent frames, TDAN10 and EDVR11 were proposed to make full use of deformable convolution for frame alignment. Xiang et al.12 proposed a deformable ConLSTM method, which has good reconstruction effect in processing large motion video frames. However, the above methods extract spatial features first and then perform time motion estimation, so the spatio-temporal correlation between adjacent frames cannot be fully utilized, affecting the reconstruction performance.
In this study, we propose a new feature fusion network based on deformable three-dimensional (3D) convolution, which hierarchically utilizes inter-frame motion information in an implicit way, makes full use of cross-frame complementary information, retains more inter-frame motion information of video, and restores missing details in reference frames. Specifically, the input video frames were divided into several groups for information integration. Each group first integrates information by itself, and then integrates information with other groups across groups. This grouping method produces subsequence groups of different frame rates, providing different types of complementary information for reference frames. Deformable 3D convolution13 was used for in-group feature fusion when each group integrates its own information. Different from the 3D convolution used in reference14, the deformable 3D used in this study was designed for low-order SR task and only performs kernel deformation in spatial dimension. For frames that are closer to the reference frame in time, shallow feature extraction and fusion were performed for each group of video frames with different frame rates after effective grouping, reducing computational cost. To aggregate information from different time groups and generate high-resolution residual maps, the subsequent inter group fusion module introduced temporal attention. By using the attention weighted features of time groups, the spatiotemporal information between video frames can be fully utilized, effectively integrating the temporal features between different groups, thereby preserving the high-frequency information between the original input video frames.
The main contributions of this study are as follows:
First, various motions between video frames were processed by implicit stratification, so that the missing details of reference frames can be recovered by using complementary information between different frame rates, and information can be borrowed adaptively from groups of different frame rates.
Second, deformable 3D convolution was realized by combining deformable convolution with 3D convolution, which is added into the inter-group fusion stage, so that motion compensation can be carried out adaptively and space-time information can be developed and utilized efficiently.
Third, time attention was applied to the deep intergroup fusion module to integrate the information of different time groups after feature extraction, to reserve more high-frequency information for the subsequent reconstruction module.
Methods
The goal of VSR is to reconstruct HR reference frames by making full use of the spatio-temporal information in the LR video frame sequence. The network structure in this study consists of shallow feature extraction module, deformable 3D convolutional in-group fusion module, intergroup attention fusion module and reconstruction module.
Firstly, we divided the input video frames into time groups, and made full use of the different frame rates of each group after grouping. Then we input the video frames of each group into a 3D convolution shallow feature extraction module for preliminary feature extraction, simulating the motion state of each group. The preliminary feature extracted video frames were input into the deformable 3D convolutional intra-group fusion module, and combined with the adaptive motion compensation feature of deformable 3D convolution to efficiently extract and fuse the features of video frames within each group. To integrate the inter group information of each group, an inter group temporal attention mechanism was introduced for cross group information fusion. Finally, the fused feature map was input into the reconstruction module composed of six cascaded residual blocks and sub-pixel layers, and the generated residual map was added to the feature map sampled by the bicubic interpolation of the input reference frame to obtain the high resolution reference frame ({mathop Ilimits^{ wedge } _t}). The overall network structure is shown in Fig. 1.

The proposed network structure.
Time grouping
In the past, the input of VSR method was mostly a sequence of continuous LR video frames composed of a reference frame (I_{t}^{L}) and 2 N adjacent frames ({ I_{{t – N}}^{L}:I_{{t – 1}}^{L},I_{{t+1}}^{L}:I_{{t+N}}^{L}}). This traditional way was mostly based on optical flow technology, which easily resulted in inefficient time fusion of adjacent frames and insufficient time information.
On this basis, we divided the adjacent 2 N frames into N groups according to the time distance from the reference frame. The original sequence was reordered as ({ G1, ldots Gn}),(n in [i:N]), where (Gn={ I_{{t – n}}^{L},I_{t}^{L},I_{{t+n}}^{L}}) is the subsequence composed of the previous frame (I_{{t – n}}^{L}), the reference frame (I_{t}^{L}) and the next frame (I_{{t+n}}^{L}). This module considered the input 7-frame video sequence as an example. (I_{4}^{L}) represents the reference frame and other frames are adjacent frames. Divide these 7 frames into three groups ({ I_{3}^{L},I_{4}^{L},I_{5}^{L}}), ({ I_{2}^{L},I_{4}^{L},I_{6}^{L}}), (:{I}_{1}^{L},:{I}_{4}^{L}{,:I}_{7}^{L}), depending on the frame rate. Because the motion information of adjacent frames at different time distances is different, the contribution is not equal. Therefore, such grouping method can explicitly and efficiently integrate adjacent frames of different time distances. The reference frames of each group can guide the network model to extract more beneficial information from adjacent frames, so that the information extraction and fusion of subsequent fusion modules within the group become more efficient.
Feature extraction and fusion module
In this module, the above time-grouped video frames were firstly extracted and time aligned by 3D convolution. Then, the extracted feature images were sent to the in-group fusion module. A deformable 3D convolution was used for feature fusion, and time alignment was further carried out before being input into the subsequent deep fusion module.
Deformable 3D Convolution
The 3D convolution first appeared in TDAN15, and its specific implementation can be divided into the following two steps – sampling input features by three-dimensional convolution kernel and the weighted summation of sampling values by functions. The features transferred through the convolution kernel with an expansion coefficient of 1 can be expressed as
Here a position in the output feature can be represented as ({p_0}). ({p_n}) represents the n-th value in the (3 times 3 times 3)convolutional sampling network. The deformable 3D convolution can be obtained by transforming 3D convolution. The spatial receptive field of the deformable 3D convolution can be expanded by the learnable offset, and the size of sampling network is N = 27. Input features of C × T × W × H size were first entered into 3D convolution to generate offset features of 2N ×T × W × H size. For two-dimensional spatial deformation, the number of channels with these offset features is generally set as 2N, and then the learned offset is used to guide the ordinary 3D sampling network to carry out spatial deformation. The deformable 3D sampling network was generated. Finally, the deformable 3D sampling network was used to generate output features. The above processes can be expressed by the following formula
where (Delta {p_n}) represents the offset corresponding to the n-th value in the 3 × 3 × 3 convolutional sampling network. Offsets are usually decimals, so more precise values need to be generated by bilinear interpolation. From the above process, the deformable 3D convolution can be used to integrate time and space information at the same time, so as to extract more specific information belonging to video sequence. The schematic diagram of the deformable 3D convolution is shown in Fig. 2. Because the offset vector layer can learn to obtain the offset vector from the current input feature graph, it is widely used in video super-resolution tasks with certain deformation or motion trend.
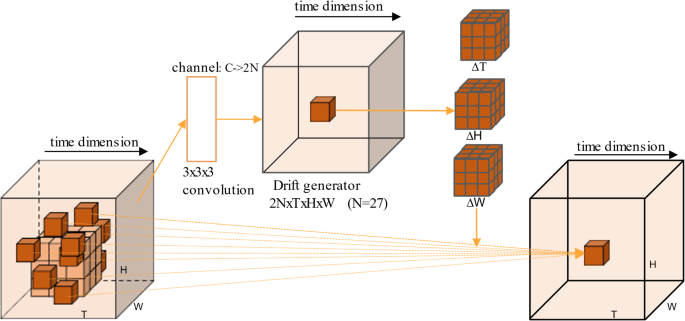
The schematic diagram of deformable 3D convolution.
Intra group fusion for deformable 3D Convolution
After 3D shallow feature extraction for each grouped video, further deeper feature extraction and fusion were required. An intra-group fusion module was deployed for each group. The module is composed of a spatial feature extractor and a deformable 3D convolutional layer. There were three units in the spatial feature extractor. Each unit consists of a 3 × 3 convolutional layer and a batch of normalized layer. The entire convolutional layer has suitable expansion rate to simulate each grouping unique interframe motion. Each group of frame rate determined the expansion rate of the convolutional layer. The motion level with a large time difference between frames is large, which is corresponding to a big expansion rate, and the motion level with a small difference is small, which is corresponding to a small expansion rate. Then, deformable 3D convolutional residual blocks with five 3 × 3 × 3 convolution kernels were used to fuse spatio-temporal features. Finally, the fused features were sent into a two-dimensional dense block, and 18 two-dimensional units were applied in the two-dimensional dense block to extract the in-group population features and generate feature (F_{n}^{g}). Inter-frame information within the group was deeply fused, and spatio-temporal information can be efficiently utilized, as shown in Fig. 3.
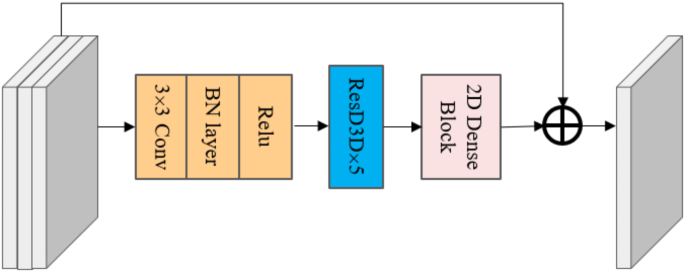
Intra group fusion for deformable 3D convolution.
Inter-group fusion module based on time attention mechanism
After intra group fusion was performed for each group, the population characteristics between the three groups needed to be integrated. An intergroup time attention mechanism was introduced. Time attention has been widely used in SR and image processing16,17,18,19. It was also beneficial to the VSR by giving different attention to the model at different times. In the previous time grouping, video frame sequences were classified into three groups according to different frame rates. Groups contain a lot of complementary information from one group to another. In general, a group with a slow frame rate is more informative because adjacent frames are more similar to the reference frame. At the same time, groups with fast frame rates may also capture details that are missing in nearby frames. Therefore, the time attention can be used to effectively integrate the characteristic information of different time interval groups.
For each grouping, a feature map (F_{n}^{a}) of a channel was calculated by applying a 3 × 3 convolutional layer to the corresponding feature map. These generated feature maps, (F_{1}^{a}), (F_{2}^{a}), and (F_{3}^{a}), were further connected. Softmax functions along the timeline were applied to each location across the channel to calculate the time attention feature map.
The intermediate graphs of each group were linked together and the attention feature graphs, (M(x,y)), were calculated by the softmax function along the timeline.
The attention-weighted feature (mathop {F{}_{n}^{g} }limits^{ sim }) for each group was calculated by
where ({M_n}{(x,y)_j}) represents the weight of time attention mask in ({(x,y)_j}) position, (F{}_{n}^{g}) represents the in-group features generated in the intra-group fusion module, and (odot) represents the multiplication of corresponding elements one by one.
The goal of the inter-group fusion module is to aggregate the information of different time groups and generate HR residual map. To make full use of the attention-weighted feature of the time group, after calculating the attention-weighted feature graphs, we connected these feature maps along the time axis and input them into a three-dimension dense block. Meanwhile, a convolutional layer containing a 1 × 3 × 3 convolutional kernel was inserted at the end of the three-dimensional dense block to reduce channels. A two-dimensional dense block was placed below for further fusion, as shown in Fig. 4.
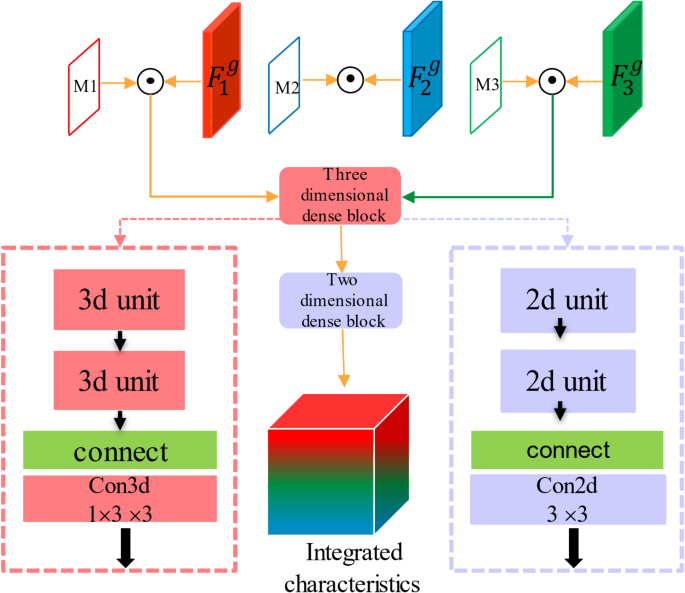
Time attention module.
Finally, a reconstruction module similar to single-image super-resolution upsamples the fully fused features through depth-to-space operation. The fused features were sent into six cascaded residual blocks and the sub-pixel convolutional layer for reconstruction, and the corresponding residual map was generated after processing. At the same time, the final HR video frames were generated by adding the original video residual map generated by sampling on bicubic interpolation.
Experimental results and discussion
Experiment settings
The CPU of our experimental platform is Intel Core I5-7500 and the GPU is NVIDIA RTX-2080. Use the deep learning framework Pytorch 1.2.0. Standard Vid420 data set was used for training and evaluation. The data set contained video frame sequences of four scenes: Calendar, City, Foliage, and Walk. Each scene contained 41, 34, 49, and 47 frames of images. High resolution video frames are sampled four times with Gaussian blur of (sigma =1.6) standard deviation to generate corresponding low resolution video frames.
During the training process, the training data were expanded by flipping and rotating with a probability of 0.5. The network used seven adjacent low-resolution frames as input. The model was supervised by pixel-level L1 losses and optimized using Adam21 optimizer, where β1 = 0.9 and β2 = 0.997. During the training, the weight attenuation was set to 5e10− 4. The learning rate was initially set to 10− 3, and then multiplied by 0.9 for every 10-iteration, up to 300 iterations. The mini-batch size is set to 64. Peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM), which are commonly used for image evaluation22,23,24,25,26, were used to quantitatively analyze the reconstructed images, to measure the reconstruction performance of VSR. In addition, we used parameter number, Params, network complexity, Flops, and runtime, Time, to measure the network performance.
Analysis of results
The SR performance of the proposed method in Y channel was compared with that of VSRnet27, VESPCN28, TOflow7, D3Dnet13, RBPN, and EDVR29. The quantitative analysis results are shown in Table 1. TOFlow used explicit pixel-level motion compensation with optical flow estimation and RBPN used pre-calculated optical flow as additional input. EDVR used implicit motion compensation for VSR. The experimental results show that on Vid4 data set, the PSNR and SSIM values of our proposed method in Y channel are 27.39 dB and 0.828, respectively. Our method can significantly improve the performance of image restoration. Compared with RBPN and EDVR, PSNRs are improved by 0.29 dB and 0.12 dB, respectively. Compared with D3Dnet using deformable 3D convolution, PSNR and SSIM are improved by 0.87 dB and 0.029, respectively.
In terms of measuring network performance, we compared our method with some algorithms used in quantitative analysis. The results are shown in Table 2. Although our method has more parameters, it is superior to D3Dnet in terms of network complexity. It achieved the optimal running time. Compared with TOFlow with the max running time in the compared methods, the running time of our method is reduced to only 14.1% of TOFlow. Compared with VESPCN with the min running time in the compared methods, the running time of our method is reduced to 83.9% of VESPCN.
According to the visualization results in Fig. 5, the images restored by VESPCN, Toflow and D3Dnet methods can only be seen roughly, with low definition and deep artifacts. For example, the windows of the building in the City figure and the human face in the Walk figure are almost indistinct, and details and edge information are obviously missing in the video image. However, the video image restored by our network model can display more texture information, and the edge information of the image can be clearly seen, and the image resolution is significantly improved. Compared with other methods, the proposed deformable 3D intra-group fusion based on time grouping and attention-based inter-group fusion methods make full use of the complementary information between frames at different frame rates, so it can produce clearer edges and finer textures.

Visualization results of video super-resolution on Vid4 data set at x4 scale.
Ablation experiments
Compared with 3D convolution, the deformable 3D convolution trained the offset vector layer separately. At the same time, the deformable 3D convolution can also maintain a good receptive field without the need for down-sampling modules.
To test the influence of fusion operation within the deformable 3D convolutional group on improving reconstruction performance, we changed the deformable 3D into 3D in the network, and changed the number of residual blocks. Vid4 data set was still used to compare the PSNR and SSIM values of 3D residual blocks and deformable 3D residual blocks with different numbers. It can be seen from Table 3 that no matter how many residual blocks are used, the video reconstruction effect of deformable 3D convolution is better than that of 3D convolution. Moreover, the network performance of in-group fusion using deformable 3D convolution is improved with the increase of the number of residual blocks, and its stability is better than that of 3D convolution. At the same time, compared with the network with five 3D convolutional residual blocks, the PSNR and SSIM values of deformable 3D convolutional network are increased by 0.22 dB and 0.016 respectively, which can achieve better visual effects. Therefore, the deformable 3D convolution is effective in the extraction of video time information in video super-resolution tasks.
Conclusions
In this study, we proposed a new deep neural network, which rearranges the input video sequence into several groups of sub-sequences with different frame rates, and integrates the inter-frame information of video sequences with different frame rates by time grouping hierarchically to complete shallow feature extraction. The intra-group fusion module with five deformable 3D convolutional residual blocks effectively utilized the extra time information of each group to maintain time consistency while modeling appearance and motion, to deeply extract and fuse the spatio-temporal feature information of each group, and generate feature maps and send them to the inter-group attention fusion module. This module can adaptively borrow complementary information from different groups, and finally complete the reconstruction of video super-resolution through the reconstruction module. Through the training and testing on Vid4 data set, experiments prove that the proposed network has good reconstruction performance.



Responses